






目录
在构建决策树时,我们需要决定在每个节点上根据什么特性进行拆分,以便最大化减少熵或不纯度,从而在决策树中最大化纯度。学习熵的减少称为信息增益,因此,选择在决策树中的每一个节点上使用什么特性进行拆分是基于信息增益的考量。
如何选择信息增益?
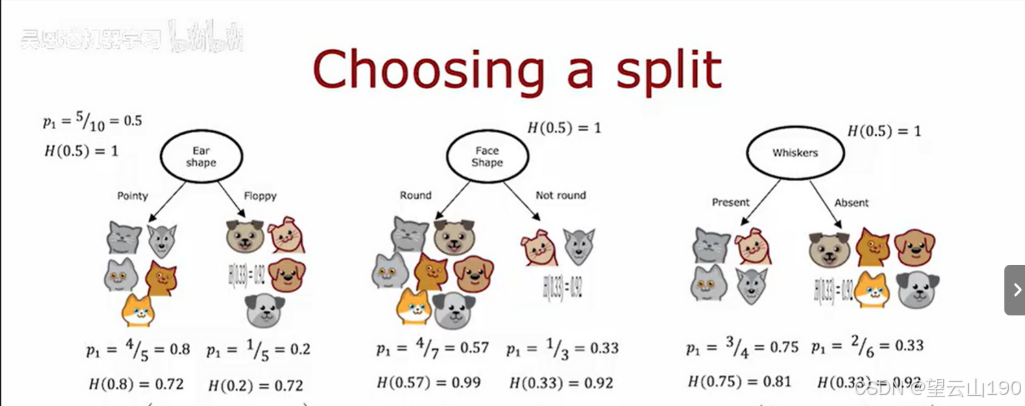
在决策树的根节点上,我们需要建立识别猫和非猫的能力。如果我们使用耳朵形状特征进行分类,我们可以得到五个左边例子和五个右边例子。在左边,我们有四只猫,所以 p1=4/5=0.8,在右边,只有一只猫,p1=1/5=0.2。如果将熵公式应用于数据的左侧子集和右侧子集,将会发现左边的杂质程度 H(0.8)=0.72,在右边 H(0.2)=0.72,这就是左右分支的熵。
如果在脸型上进行分类,圆脸的数据有七个,其中有四只猫,所以 p1=4/7=0.57,右边 p1=1/3=0.33,所以 H(0.57)=0.99,H(0.33)=0.92,所以左右两侧的杂质程度似乎要高得多。
最后,在根节点上使用第三个可能的特性选择,胡须的特征,在这种情况下,根据胡须是否存在来分类,左边的 p1=3/4=0.75,右边的 p1=2/6=0.33,熵值如下 H(0.75)=0.81,H(0.33)=0.92。
如何计算熵:

信息增益的计算
在根节点使用的特性的这三个选项中,哪一种更有效?我们可以通过计算加权平均熵来决定。加权平均熵考虑了左右分支中低熵的重要性,也取决于有多少例子进入了左右分支。例如,如果有很多例子进入了左分支,那么确保左分支的熵值低就更重要。
我们可以通过计算加权平均数来选择拆分的方法,例如 (5/10)H(0.8)+(5/10)H(0.2),对于中间和右边例子也是同样的计算方法。我们选择拆分的方法是通过计算这三个数字哪个最低,得出哪个杂质最少,纯度最高,因为这给了我们平均加权熵最低的左右分支。
在构建决策树的过程中,我们实际上要对这些公式再做一个修改,与其计算加权平均熵,我们要计算熵的减少,所以,如果我们去根节点,在根节点上,已经从所有十个示例开始,有五只猫和五只狗,所以在根节点,我们得到 p1=5/10=0.5,所以根节点的熵值 H(0.5)=1,这是最大的纯度。
我们实际上要用来选择分类的公式不是左右分支的加权熵,而是根节点的熵,计算得到三个数字:0.28、0.03、0.12,这些被称为信息增益。它测量的是你通过分类在树上得到的熵的减少,因为熵原本是在根节点通过分类,最终得到的熵值较低,这两个值之间的差异是熵的减少。在耳朵形状分类的情况下,信息增益为0.28。

为什么计算信息增益?
信息增益帮助我们决定在决策树的每个节点上选择哪个特征进行拆分。通过计算每个特征的信息增益,我们可以选择信息增益最大的特征,从而最大化地减少数据集的熵,提高子集的纯度。如果熵的减少量太小,我们可能会决定不再继续拆分,以避免过度拟合。

这张图片展示了在构建决策树时,如何根据不同的特征(耳朵形状、脸型、胡须)来选择最佳的拆分点,以减少数据集的熵并提高纯度。图片中通过计算信息增益来比较不同特征的效果。
总体信息
-
初始数据集有10个样本,其中5个是猫(p1=5/10=0.5),熵 H(0.5)=1,表示初始数据集的不纯度最高。
耳朵形状(Ear shape)
-
尖耳朵(Pointy):5个样本中有4个是猫(p1=4/5=0.8),熵 H(0.8)=0.72。
-
软耳朵(Floppy):5个样本中有1个是猫(p1=1/5=0.2),熵 H(0.2)=0.72。
-
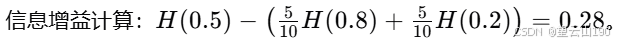
脸型(Face Shape)
-
圆形(Round):7个样本中有4个是猫(p1=4/7=0.57),熵 H(0.57)=0.99。
-
非圆形(Not round):3个样本中有1个是猫(p1=1/3=0.33),熵 H(0.33)=0.92。
-
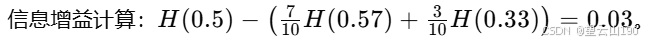
胡须(Whiskers)
-
有胡须(Present):4个样本中有3个是猫(p1=3/4=0.75),熵 H(0.75)=0.81。
-
无胡须(Absent):6个样本中有2个是猫(p1=2/6=0.33),熵 H(0.33)=0.92。
-
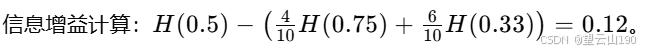
结论
通过比较不同特征的信息增益,我们可以看到耳朵形状特征的信息增益最大(0.28),这意味着使用耳朵形状作为拆分特征可以最大程度地减少数据集的熵,从而提高数据集的纯度。因此,在构建决策树时,我们会选择耳朵形状作为根节点的拆分特征。

这张图片解释了信息增益(Information Gain)的概念,这是决策树算法中用于选择最佳特征拆分点的方法。信息增益通过计算使用某一特征拆分数据后熵的减少量来确定。

总结
通过计算不同特征的信息增益,我们可以确定哪个特征对于提高数据集纯度最有效。在决策树算法中,我们会选择信息增益最大的特征作为当前节点的拆分特征,以此来构建决策树。这种方法有助于减少数据集的熵,从而提高分类的准确性。

















 1877
1877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









