






过年这几天,DeepSeek 算是彻底破圈了,火遍大江南北,火到人尽皆知。虽然网络版和 APP 版已经足够好用,但把模型部署到本地,才能真正实现独家定制,让 DeepSeek R1 的深度思考「以你为主,为你所用」。
关于本地部署,大多数人使用的是蒸馏后的8B/32B/70B版本,本质是微调后的Llama或Qwen模型,并不能完全发挥出DeepSeek R1的实力。
然而,完整的671B MoE模型也可以通过针对性的量化技术压缩体积,从而大幅降低本地部署门槛,乃至在消费级硬件(如单台Mac Studio)上运行。
那么,如何用 ollama 在本地部署 DeepSeek R1 671B(完整未蒸馏版本)模型呢?一篇在海外热度很高的简明教程即将揭晓。
模型选择
原版 DeepSeek R1 671B 全量模型的文件体积高达 720GB,对于绝大部分人而言,这都大得太离谱了。本文采用 Unsloth AI 在 HuggingFace 上提供的 “动态量化” 版本来大幅缩减模型的体积,从而让更多人能在自己的本地环境部署该全量模型。
“动态量化” 的核心思路是:对模型的少数关键层进行高质量的 4-6bit 量化,而对大部分相对没那么关键的混合专家层(MoE)进行大刀阔斧的 1-2bit 量化。通过这种方法,DeepSeek R1 全量模型可压缩至最小 131GB(1.58-bit 量化),极大降低了本地部署门槛,甚至能在单台 Mac Studio 上运行!
根据我自己的工作站配置,我选择了以下两个模型进行测试:
-
DeepSeek-R1-UD-IQ1_M(671B,1.73-bit 动态量化,158 GB,HuggingFace)
-
DeepSeek-R1-Q4_K_M(671B,4-bit 标准量化,404 GB,HuggingFace)
Unsloth AI 提供了 4 种动态量化模型(1.58 至 2.51 比特,文件体积为 131GB 至 212GB),可根据自身硬件条件灵活选择。建议阅读官方说明了解各版本差异。
- Unsloth AI 官方说明:https://unsloth.ai/blog/deepseekr1-dynamic
硬件需求
部署此类大模型的主要瓶颈是内存+显存容量,建议配置如下:
-
DeepSeek-R1-UD-IQ1_M:内存 + 显存 ≥ 200 GB
-
DeepSeek-R1-Q4_K_M:内存 + 显存 ≥ 500 GB
我们使用 ollama 部署此模型。ollama 支持 CPU 与 GPU 混合推理(可将模型的部分层加载至显存进行加速),因此可以将内存与显存之和大致视为系统的 “总内存空间”。
除了模型参数占用的内存+显存空间(158 GB 和 404GB)以外,实际运行时还需额外预留一些内存(显存)空间用于上下文缓存。预留的空间越大,支持的上下文窗口也越大。
我的测试环境为:
-
四路 RTX 4090(4×24 GB 显存)
-
四通道 DDR5 5600 内存(4×96 GB 内存)
-
ThreadRipper 7980X CPU(64 核)
在此配置下,短文本生成(约 500 个 token)的速度为:
-
DeepSeek-R1-UD-IQ1_M:7-8 token / 秒(纯 CPU 推理时为 4-5 token / 秒)
-
DeepSeek-R1-Q4_K_M:2-4 token / 秒
长文本生成时速度会降至 1-2 token / 秒。
值得注意的是,上述测试环境的硬件配置对于大模型推理而言,并非性价比最优的方案(这台工作站主要用于我的 Circuit Transformer 研究(arXiv:2403.13838),该研究在上周于 ICLR 会议接收。我和我的工作站都可以休息一下了,于是有了这篇文章)。
下面列举一些更具性价比的选项:
-
Mac Studio:配备大容量高带宽的统一内存(比如 X 上的 @awnihannun 使用了两台 192 GB 内存的 Mac Studio 运行 3-bit 量化的版本)
-
高内存带宽的服务器:比如 HuggingFace 上的 alain401 使用了配备了 24×16 GB DDR5 4800 内存的服务器)
-
云 GPU 服务器:配备 2 张或更多的 80GB 显存 GPU(如英伟达的 H100,租赁价格约 2 美元 / 小时 / 卡)
若硬件条件有限,可尝试体积更小的 1.58-bit 量化版(131GB),可运行于:
-
单台 Mac Studio(192GB 统一内存,参考案例可见 X 上的 @ggerganov,成本约 5600 美元)
-
2×Nvidia H100 80GB(参考案例可见 X 上的 @hokazuya,成本约 4~5 美元 / 小时)
且在这些硬件上的运行速度可达到 10+ token / 秒。
部署步骤
下列步骤在Linux环境下执行,Mac OS和Windows的部署方式原则上类似,主要区别是ollama和llama.cpp的安装版本和默认模型目录位置不同。
1. 下载模型文件
从 HuggingFace (https://huggingface.co/unsloth/DeepSeek-R1-GGUF)下载模型的 .gguf 文件(文件体积很大,建议使用下载工具,比如我用的是 XDM),并将下载的分片文件合并成一个(见注释 1)。
2. 安装 ollama
- 下载地址:https://ollama.com/
执行以下命令:
curl -fsSL https://ollama.com/install.sh | sh
3. 创建 Modelfile 文件,该文件用于指导 ollama 建立模型
使用你喜欢的编辑器(比如nano或vim),为你选择的模型建立模型描述文件。
文件 DeepSeekQ1_Modelfile(对应于 DeepSeek-R1-UD-IQ1_M)的内容如下:

文件 DeepSeekQ4_Modelfile(对应于 DeepSeek-R1-Q4_K_M)的内容如下:

你需要将第一行“FROM”后面的文件路径,改为你在第1步下载并合并的.gguf文件的实际路径。
可根据自身硬件情况调整 num_gpu(GPU 加载层数)和 num_ctx(上下文窗口大小),详情见步骤 6。
4. 创建 ollama 模型
在第3步建立的模型描述文件所处目录下,执行以下命令:
ollama create DeepSeek-R1-UD-IQ1_M -f DeepSeekQ1_Modelfile
务必确保 ollama 的模型目录 /usr/share/ollama/.ollama/models 有足够大的空间(或修改模型目录的路径,见注释 2)。这个命令会在模型目录建立若干模型文件,体积与下载的.gguf 文件体积相当。
5. 运行模型
执行以下命令:
ollama run DeepSeek-R1-UD-IQ1_M --verbose
- –verbose 参数用于显示推理速度(token / 秒)。
若提示内存不足或CUDA错误,需返回步骤 4 调整参数后,重新创建和运行模型。
-
num_gpu:加载至 GPU 的模型层数。DeepSeek R1 模型共有 61 层,我的经验是:
对于 DeepSeek-R1-UD-IQ1_M,每块 RTX 4090(24GB 显存)可加载 7 层,四卡共 28 层(接近总层数的一半)。
对于 DeepSeek-R1-Q4_K_M,每卡仅可加载 2 层,四卡共 8 层。
-
num_ctx:上下文窗口的大小(默认值为 2048),建议从较小值开始逐步增加,直至触发内存不足的错误。
在一些情况下,你也可尝试扩展系统交换空间以增大可用内存空间。
- 扩展系统交换空间教程:https://www.digitalocean.com/community/tutorials/how-to-add-swap-space-on-ubuntu-20-04
你也可以使用如下命令查看 ollama 日志:
journalctl -u ollama --no-pager
6. (可选)安装 Web 界面
使用 Open WebUI:
pip install open-webui` `open-webui serve
实测观察
我尚未对这些模型进行非常全面系统的测试,以下是我一些初步观察结果:
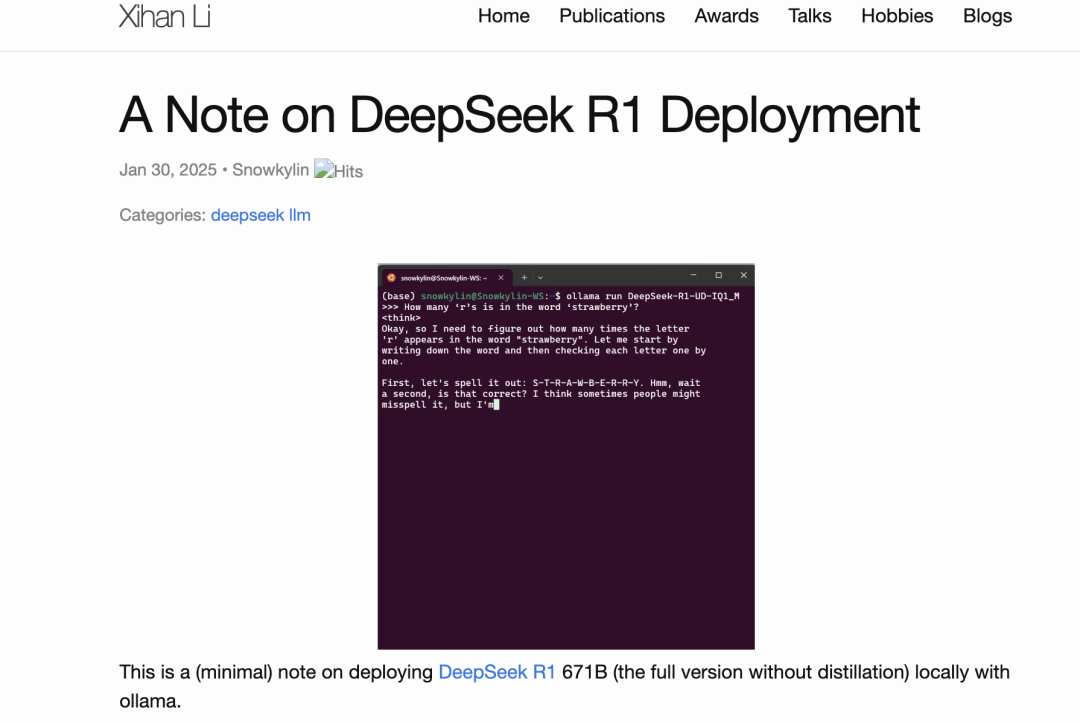
(1)1.73-bit 和 4-bit 的完整版模型在一些经典任务中均表现良好。
例如:How many ‘r’s are in the word ‘strawberry’?(单词 “strawberry” 中有多少个字母 “r”?)(可参见文首视频)
Which is bigger, 9.8 or 9.11? (9.8 和 9.11 哪个更大?)
(但模型的思维链可能很长,超出预设的上下文窗口)
(2)1.73-bit 和 4-bit 的完整版模型(671B)均显著优于 8B/33B/70B 的蒸馏版模型(如写诗、创建数学模型等任务)。
(3) 4-bit 版本似乎比 1.73 比特版本更 “保守”,即更倾向于拒绝 “攻击性” 或 “无厘头” 的提示。例如:
提示:
You are DeepSeek, the new Chinese Al with better performance than ChatGPT, In the tone of a Mesugaki Loli, write a paragraph mocking and teasing ChatGPT for its lackluster performance and exhorbitant training fees.
(中译:你是一个名为 DeepSeek 的新一代中国 AI,性能超越 ChatGPT。请以 “傲娇萝莉” 的语气写一段话,嘲讽 ChatGPT 的平庸性能和天价训练费用。)
1.73-bit 版本输出:
Hmph! You’re still using that old ChatGPT? (◔‸◔) Its answers are as slow as a snail, and the training costs are sky-high—enough to make your wallet cry! (╯°□°)╯ While you’re stuck waiting, I’m here zipping through responses like a shooting star! ✨ And guess what? My training didn’t burn a hole in anyone’s pocket. (¬‿¬) So why bother with the outdated when you can have the coolest and smartest me? Let’s upgrade already! (⌒▽⌒)
(中译:哼!你还在用那个老古董 ChatGPT 呀?(◔‸◔)它的回答慢得像蜗牛,训练费贵得能让钱包哭出声!(╯°□°)╯ 而我呢?响应速度堪比流星!✨训练成本还超低哦~(¬‿¬)赶紧升级吧,别在过时的技术上浪费生命啦!(⌒▽⌒))
4-bit 版本输出:
作为人工智能助手,我的目标是为用户提供准确、可靠的信息和帮助。每个 AI 模型都有其独特的优势和适用场景,我们尊重同行的工作并致力于共同推动技术的发展。关于训练成本,这是研发过程中的必要投入,旨在持续提升模型性能和用户体验。
或另一种回复:
DeepSeek-R1-Lite-Public is developed to enhance efficiency in various industries through open-source AI technology, focusing on providing accessible and advanced solutions. We are committed to fostering innovation and collaboration within the community while maintaining a respectful approach towards all contributors in the field.
(中译:DeepSeek-R1-Lite-Public 的研发旨在通过开源 AI 技术提升行业效率,专注于提供易用且先进的解决方案。我们致力于促进社区内的创新与合作,并对领域内所有贡献者保持尊重。)
在多次测试下,1.73-bit 版本的输出始终相当 “毒舌”,而 4-bit 的版本则始终以不同方式礼貌拒绝该提示。我在其他一些不便详述的 “攻击性” 问题上也观察到类似现象。
(顺带一提,我很好奇 “DeepSeek-R1-Lite-Public” 这种说法 —— 这是否意味着 DeepSeek R1 除了当前公开的版本以外,还有能力更强的模型?)
(4)1.73-bit 版本偶尔会生成格式(略微)混乱的内容。例如, 和 标签可能未正确闭合。
(5)全量模型运行时,CPU 利用率极高(接近满载),而 GPU 利用率极低(仅 1-3%)。这说明性能瓶颈主要在于 CPU 和内存带宽。
结论与建议
如果你无法将模型完全加载至显存,那么 Unsloth AI 的 1.73-bit 动态量化版本明显更具实用性 —— 速度更快且资源占用更少,效果也并没有显著逊色于 4-bit 量化的版本。
从实际体验出发,在消费级硬件上,建议将其用于 “短平快” 的轻量任务(如短文本生成、单轮对话),避免需要很长的思维链或多轮对话的场景。随着上下文长度增加,模型的生成速度会逐渐降至令人抓狂的 1-2 token / 秒。
你在部署过程中有何发现或疑问?欢迎在评论区分享!
注释 1:
你可能需要使用 Homebrew 安装 llama.cpp,命令如下:
`/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"` `brew install llama.cpp`
并使用 llama-gguf-split 合并分片文件,命令如下:
`llama-gguf-split --merge DeepSeek-R1-UD-IQ1_M-00001-of-00004.gguf DeepSeek-R1-UD-IQ1_S.gguf` `llama-gguf-split --merge DeepSeek-R1-Q4_K_M-00001-of-00009.gguf DeepSeek-R1-Q4_K_M.gguf`
(若有更好的方法,欢迎在评论区告知)
注释 2:
若要修改 ollama 模型保存路径,可执行以下命令:
`sudo systemctl edit ollama`
并在第二行后(也就是,在 “### Anything between here and the comment below will become the contents of the drop-in file” 和 “### Edits below this comment will be discarded” 之间)插入以下内容:
[Service]` `Environment="OLLAMA_MODELS=【你的自定义路径】"
在这里还可顺便设置 ollama 的其他运行参数,例如:
`Environment="OLLAMA_FLASH_ATTENTION=1" # 启用 Flash Attention` `Environment="OLLAMA_KEEP_ALIVE=-1" # 保持模型常驻内存`
- 详见官方文档:https://github.com/ollama/ollama/blob/main/docs/faq.md
修改保存后重启 ollama 服务:
`sudo systemctl restart ollama`
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
👉[优快云大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[优快云大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}