






前言
在AI应用爆发式增长的今天,从ChatGPT类的大模型推理平台,到日活千万的智能客服,再到亿级数据规模的推荐系统,一个高可用、高性能、可扩展的系统架构是AI落地的基石。本文将系统性地拆解AI系统架构设计的核心原则、关键能力和实际场景,通过逐步构建,让你理解:一个真正支撑业务的AI系统架构该如何设计,如何优化,如何进化。
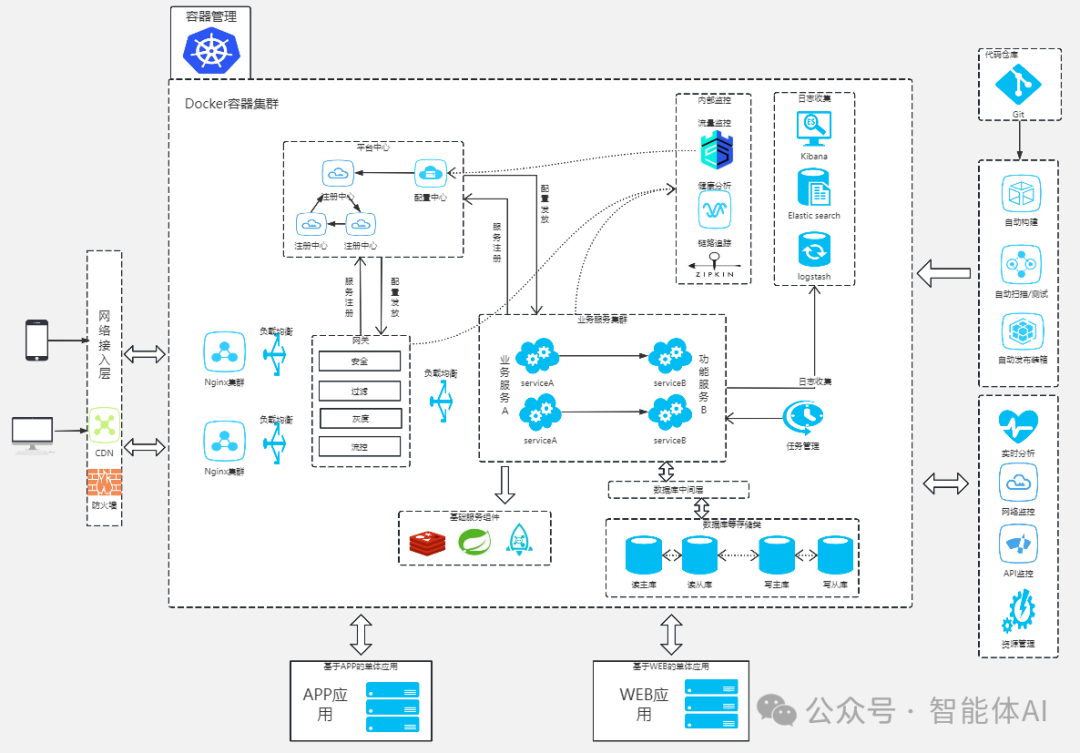
一、架构设计核心原则:为变化而生,为复杂而解
1.1 演进式法则:适应AI业务快速变化
AI系统的业务特性之一是快速变化。模型不断迭代,算法日新月异,业务场景频繁扩展。比如,从最初的文本问答扩展到语音识别、图像生成,甚至多模态融合。如果架构不具备良好的可演进性,每一次迭代都意味着大规模重构,技术债迅速累积,系统脆弱不堪。
因此,AI系统的架构设计需要充分考虑版本控制、模块热插拔、灰度发布、模型注册等机制,让每一个AI能力可以像“插件”一样灵活组合。
1.2 先进性法则:用前沿技术解决未来问题
在AI系统中,引入容器化部署、微服务架构、服务网格、模型加速(如TensorRT、ONNX)、低延迟通信协议(如gRPC)等先进技术,不是为了炫技,而是为了应对未来的高并发、高吞吐、多模型部署、多租户等挑战。
比如,部署一个千亿参数模型,需要合理规划A100 GPU资源池、RPC推理通道和异步队列调度。只有用前瞻性的技术手段,系统才能拥有“未雨绸缪”的能力。
1.3 SRP与松耦合原则:为重构和替换留出空间
单一责任原则(SRP)和松耦合设计是保障系统可维护性和可替换性的根本。例如,将“模型调用模块”从“数据预处理模块”中解耦,使得后期可以无缝更换推理框架、加载不同模型版本,避免牵一发而动全身。
1.4 领域驱动原则:以业务为中心组织系统
AI平台的底层能力(如模型服务、数据标注、评估监控)都应围绕具体业务构建。构建AI平台并非从技术出发堆叠模块,而是从业务出发建立“领域服务”模型:一个“客服意图识别”领域服务,就可能包含“语义分类模型 + 上下文管理器 + 多轮推理状态机”。
1.5 分层架构与CAP法则:为一致性与弹性定框架
架构分层是防止逻辑混乱和性能瓶颈的重要手段。在AI系统中,通常划分为:接入层(API网关)、服务层(NLP服务、推荐服务)、基础设施层(数据、模型、缓存)等。
在分布式部署中,必须权衡CAP原则:一致性(C)、可用性(A)、分区容错性(P)。AI平台往往偏向可用性与分区容错性,使用最终一致性策略来平衡复杂性与性能。
二、系统质量属性:稳如泰山的系统,从这五个维度筑基
2.1 高并发法则:扛得住亿级请求的AI系统
一个面向C端的AI写作工具,在爆款推广后用户激增,从百人日活飙升到百万级。后端若没有强大的高并发支撑,将瞬间被打垮。
如何支撑?关键在于:
- 利用Redis做模型调用结果缓存
- 使用分布式消息队列(如Kafka)削峰填谷
- 将长时间的生成任务异步处理、前端轮询返回
2.2 高可用法则:系统不挂,用户不慌
AI系统部署在多节点集群中,必须具备故障转移、实例重启、健康检查等高可用能力。K8s 的 pod 自愈机制、服务探针探活、SLB多可用区部署,这些能力缺一不可。
2.3 高性能法则:毫秒级响应的秘密
一个AI搜索引擎,必须在100ms内返回结果。系统需通过:模型加速、缓存预热、索引设计、批量合并请求等手段,将推理时延压缩到用户可接受的范围内。
2.4 高并发读写:读靠缓存,写靠异步
读请求多时,部署ElasticSearch做倒排索引;写请求激增时,采用“消息队列+批处理+分库分表”模型,实现并发控制与负载均衡。
这些设计不仅保障了高并发访问,更避免了数据库成为系统瓶颈。
三、可扩展性策略:从小模型到大平台的跃迁
3.1 垂直扩展:升级硬件,撑起初始版本
当系统初期请求量有限,可以选择A100服务器、扩充内存、GPU加速库优化等方式提升性能。但这终将触及单机瓶颈。
3.2 水平扩展:模块化部署,集群调度
随着接入客户数量增长,服务横向扩展是必然选择。利用Kubernetes部署多个副本服务,结合服务注册与发现、灰度发布、负载均衡策略,实现多租户隔离与资源分配。
一个典型场景是:“将客服模型和文档问答模型部署为两个微服务”,通过路由控制分发流量,各自独立扩容。
四、数据架构与存储:数据即燃料,结构即效率
4.1 多类型数据存储:适配多模态AI业务
一个AI教育平台同时处理文本问答、教学视频、语音评分等任务。需使用:
- MySQL 存储结构化事务数据
- MongoDB 存储复杂JSON配置
- MinIO 存储音视频大文件
- Milvus 存储向量数据用于相似度检索
4.2 数据索引与检索优化:为每一次查询节省毫秒
构建向量检索时,采用倒排索引与分片机制结合,可显著提升召回效率。使用Elasticsearch搜索大文本,使用Annoy或FAISS加速向量检索,是AI系统必备能力。
4.3 分片策略:灵活扩容的保证
常用策略包括:
-
Range分片(适合时间序列)
-
Hash取模分片(适合均匀分布)
-
一致性哈希(适合动态扩容)
五、性能优化技术:在毫秒与算力之间博弈
5.1 缓存:快速响应的秘密武器
使用CDN缓存模型前端资源,浏览器本地缓存用户配置,Redis缓存热门问题的推理结果,可以将请求延迟降低90%。
5.2 队列+批处理:应对突发写入压力
在大模型训练平台上,大量数据标签、样本上传写入集中发生时,采用“写入队列+定时批处理+分区提交”架构,有效避免数据库写入拥堵。
5.3 内存池与对象池:减少重复开销
模型调用涉及大量临时对象(如Tokenizer、Context对象),使用对象池技术可避免GC抖动。
六、容错与容灾设计:系统出问题时用户无感
6.1 冗余机制:关键服务至少双活
AI平台中,推理服务必须多活部署,并结合健康探针做流量剔除,实现请求的自动转移。
6.2 数据容灾:不能丢的模型与日志
使用多地S3同步备份模型、使用异地数据库灾备策略,确保即使主机房断电,模型服务仍可迁移启动。
6.3 健康检查与心跳监控:实时掌控状态
服务节点间使用Gossip协议同步健康状态,节点下线可自动摘除;同时结合Prometheus + Grafana实现全链路可视化监控。
七、系统稳定性设计:未雨绸缪,抵御故障雪崩
7.1 熔断机制:快速失败避免系统拖垮
当模型推理服务超时率超过阈值,自动熔断,短暂拒绝请求,保护系统不被压垮。
7.2 隔离机制:资源分域、流量分层
将AI模型分租户隔离运行,每个模型有独立的GPU Queue、独立缓存,避免一个模型影响全局。
八、运维与监控:让AI系统自我感知、自我恢复
8.1 全链路监控体系
监控指标应包括:请求QPS、推理耗时、GPU使用率、服务错误码、数据库慢查询日志等。结合链路追踪(如Jaeger),定位每一次性能抖动。
8.2 DevOps与CI/CD
模型部署流程从模型注册、模型验签、上线发布全部自动化,让模型迭代速度跟得上业务。
8.3 API网关与限流控制
通过API网关聚合入口,设置QPS限制、认证策略、动态配置,实现灵活、安全的服务访问控制。
九、总结
AI系统架构不是冷冰冰的技术堆叠,而是对业务节奏、技术趋势、用户体验的深度回应。只有真正理解业务发展背后的节奏变化,洞察架构各层之间的动态关系,系统才能具备持久的生命力。在每一次并发暴涨、模型热更、异常故障、业务爆发的背后,都是架构设计者一次次为系统筑牢的“隐形护城河”。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1185
1185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









