






RAG标准化流程
| 阶段 | 步骤 | 技术方法 |
|---|---|---|
| 索引构建(Indexing) | 文档分割 | 采用滑动窗口(Sliding Window)或语义分割算法(如Sentence-BERT)进行文本切分,确保每个文本块(Chunk)具有连贯的语义,同时避免信息缺失;结合层次分割(Hierarchical Chunking)优化不同粒度的索引结构,提高检索匹配度 |
| 向量编码 | 使用高效嵌入模型(如OpenAI text-embedding-3-small、BGE、E5-Large)将文本块转换为高维向量,确保向量表示具有足够的语义区分度;可结合多视角嵌入(Multi-View Embedding)或知识增强嵌入(Knowledge-Enhanced Embedding)提升文本理解能力 | |
| 存储优化 | 采用层次化索引结构(如HNSW、FAISS IVF+PQ),利用近邻搜索加速向量检索;结合离线批量索引构建与增量索引更新策略,支持海量数据高效存储与动态更新。 | |
| 语义检索(Retrieval) | 混合检索 | 结合稀疏检索(BM25、TF-IDF)与密集检索(DPR、ColBERT、Contriever);采用查询扩展(Query Expansion)技术,如伪相关反馈(Pseudo-Relevance Feedback, PRF)或基于知识图谱的扩展,提高召回率 |
| 重排序(Rerank) | 采用交叉编码器(Cross-Encoder,如MonoT5、RankGPT)计算用户查询与候选文档的相关性,进行精细排序;结合融合排序(Fusion-in-Decoder, FiD)或基于RL的优化(如Reward Model)提升排序质量 | |
| 上下文生成(Generation) | 提示工程(Prompt Engineering) | 采用结构化提示模板(如“基于以下证据回答问题:[检索内容]”)增强模型的事实一致性;结合动态检索增强提示(Retrieval-Augmented Prompting, RAP)优化上下文组合方式;可结合自适应提示(Adaptive Prompting)自动调整提示格式 |
| 可控生成 | 采用约束解码(Constrained Decoding)或检索增强对抗训练(RAT, Retrieval-Augmented Training)确保输出符合事实逻辑;结合置信度评分(Confidence Scoring)或一致性检查(Self-Consistency Checking)提升生成文本的可靠性 |
例如,某大型商业银行引入企业级RAG系统优化智能客服,以提升客户服务效率并确保回答准确。首先,银行业务文档(如贷款条款、信用卡权益)被语义分割并向量编码,存入高效索引(HNSW)中。客户咨询“我最近换了工作,还能申请房贷吗?”时,系统混合检索相关政策(BM25+DPR),并通过交叉编码器重排序筛选最匹配内容。最终,基于结构化提示生成合规答案,如“银行要求申请人当前单位连续工作满6个月”。同时,约束解码确保答案准确无误,若置信度低则转接人工客服。RAG系统的引入使银行智能客服的响应更精准,客户满意度提升30%,客服成本降低40%。
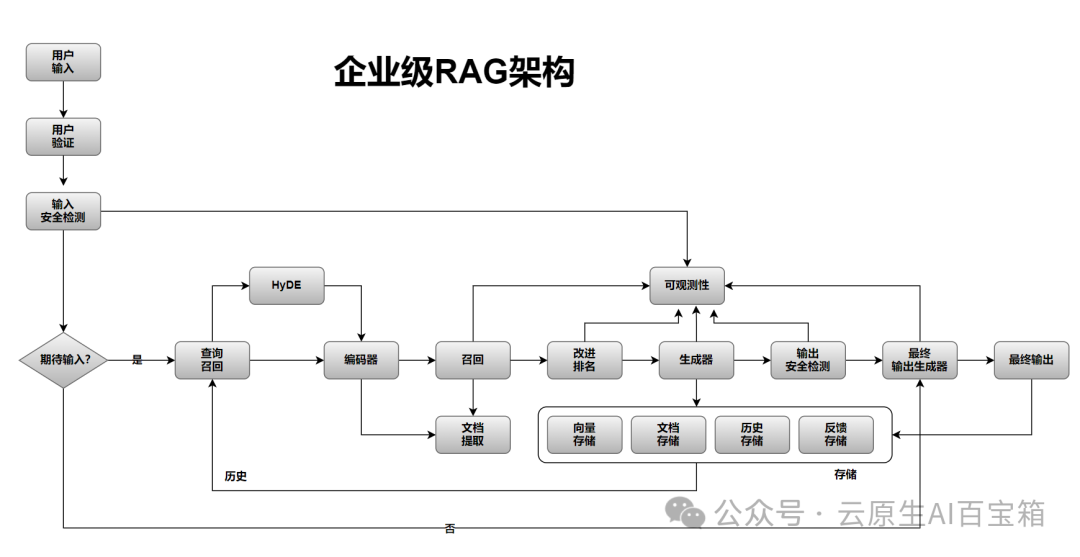
企业级RAG系统工作流程详解
企业级RAG架构结合检索(Retrieval)和生成(Generation)能力,以提升生成式AI在企业环境中的精准度、安全性和可控性。
整个流程包括用户输入、身份验证、输入安全检测,并判断是否需要检索外部信息;若需检索,则通过HyDE或其他方法,利用编码器、向量存储和文档存储进行高效搜索、改进排名和文档提取;若不需检索,则直接进入生成器。
生成器结合企业知识库和大模型能力生成回答,并通过可观测性机制进行监控,随后经过输出安全检测,最终由输出生成器提供高质量的企业级答案。
此外,该架构具备向量存储、文档存储、历史存储和反馈存储功能,以优化查询体验和提升系统性能,确保企业级AI应用的高效、安全与合规。
企业级RAG流程
随着金融行业数字化转型的加速,银行需要高效处理海量非结构化数据(如合同、政策文件、客户咨询记录等),同时确保服务的安全性、合规性与智能化。基于RAG技术构建的企业级系统,能够将传统检索与生成式AI结合,为银行提供精准、安全的智能服务。 以下结合银行业务场景,详解其核心流程与技术实现。
一、前端处理与安全控制
1. 用户身份验证与权限管理
技术实现:
- 采用OAuth 2.0协议(开放授权协议)与JSON网络令牌(JSON Web Token,JWT)实现多端统一认证。 例如,客户登录手机银行App时,系统调用AWS Cognito服务生成JWT令牌,绑定用户角色(如普通客户)及权限标签(如
view_account、edit_transfer)。 - 基于角色的访问控制(Role-Based Access Control,RBAC)模型限制操作权限。 例如,普通客户仅能查询账户余额,而理财经理可访问投资产品详情。
银行案例:
某银行在手机App中集成人脸识别(Face ID)与短信验证码双重认证,确保登录安全。若客户尝试越权操作(如普通用户访问后台管理界面),系统立即拦截并触发告警日志,记录至MongoDB数据库,支持GDPR(通用数据保护条例)合规审计。
2. 输入安全检测与敏感信息过滤
技术实现:
- 正则表达式实时检测并匿名化PII(Personally Identifiable Information,个人身份信息)。 例如,客户输入“我的身份证号是510xxx19900101xxxx”时,系统自动替换为“***”。
- 集成Meta Llama Guard(Llama安全防护模型)识别毒性内容。 例如,客户输入“如何破解他人网银密码?”时,系统根据置信度阈值(>0.8)拦截该请求,并返回提示:“您的问题涉及违规操作,请重新输入”。
- 防御SQL注入(如
'; DROP TABLE users)与XSS攻击(如<script>alert('attack')</script>),禁止特殊字符提交。
银行案例:
某银行客服系统中,客户咨询“如何转账到6228****1234账户?”时,系统自动屏蔽银行卡号,仅保留后四位,并通过会话水印(用户ID+时间戳哈希)追踪潜在数据泄露风险。
二、后端检索与生成优化
1. 文档解析与智能分块
技术实现:
- 多格式解析: 使用Apache Tika解析PDF贷款合同,PDFPlumber提取表格中的利率数据,Tesseract OCR(光学字符识别)识别客户上传的身份证扫描件。
- 语义分块: 通过BERT模型识别文档主题边界。例如,贷款合同中的“还款条款”与“违约责任”章节自动分块,确保检索时精准定位。
- 元数据增强: 提取文档发布日期、产品类型等标签。例如,优先返回2023年更新的信用卡权益政策。
银行案例:
某银行将历史客户投诉记录(Word文档)解析为结构化数据,分块存储为“问题描述”、“处理结果”、“责任部门”等字段,支持客服快速检索相似案例。
2. 混合检索与结果优化
技术实现:
- 混合索引: 在Elasticsearch中集成关键词检索算法BM25与分层可导航小世界(Hierarchical Navigable Small World,HNSW)向量索引。例如,客户查询“信用卡年费减免政策”时,系统优先匹配“年费”、“减免”等关键词,同时通过语义搜索关联“首年免年费”、“消费达标返现”等条款。
- 重排序: 使用BGE-Reranker模型对Top 100结果重新排序,综合语义相关性(70%)与时效性权重(30%)。例如,2024年最新政策排名高于2019年旧版文件。
银行案例:
某银行理财顾问查询“低风险短期理财产品”时,系统自动排除已下架产品,并优先推荐当前在售的货币基金(近3日收益率>2.5%),提升客户转化率。
3. 生成响应与合规输出
技术实现:
- 模型选型: 自托管Mixtral 8x7B模型(混合专家模型),支持动态批处理。例如,并发处理100个客户的“贷款利率查询”请求,响应延迟<500ms。
- 幻觉抑制: 集成FactScore算法(事实性评分模型),丢弃与检索文档一致性<0.7的内容。例如,若生成内容包含“本行提供比特币交易服务”(与政策文件冲突),系统自动替换为“暂不支持加密货币相关业务”。
- 品牌保护: 预设禁用词库,替换绝对化表述。例如,将“最佳理财产品”改为“热销理财产品”。
银行案例:
某银行智能客服回答“如何申请房贷?”时,系统结合最新政策生成分步指南,并附加在线申请链接与客服电话,同时嵌入不可见水印(用户ID+会话ID),防止信息泄露后恶意篡改。
三、系统监控与持续优化
1. 全链路可观测性
技术实现:
- 核心指标监控: 通过Prometheus(开源监控系统)跟踪检索延迟、生成幻觉率、GPU利用率等指标。例如,若检索延迟>500ms,系统自动关闭重排序模块,降级至BM25检索。
- 根因分析: 集成Datadog APM(应用性能管理)追踪模块级性能。例如,定位向量数据库Qdrant超时问题后,优化索引分片策略,吞吐量提升40%。
银行案例:
某银行在“双十一”促销期间,监控到生成模块GPU利用率>95%,触发Kubernetes HPA(水平自动扩缩容),自动扩容2个GPU节点,保障服务稳定性。
2. 数据驱动迭代
技术实现:
- 显式反馈: 客户对回答评分(1-5星),存储至MongoDB数据库。例如,低分回答(≤2星)自动加入标注队列,用于微调生成模型。
- 隐式反馈: 分析用户行为日志。例如,客户多次搜索“跨行转账手续费”后,系统优化检索策略,优先展示手机银行免费政策。
银行案例:
某银行根据客户点击数据优化语义编码器,使“基金定投”相关查询的召回率(Recall@5)从75%提升至92%,减少重复提问率30%。
总结
企业级RAG系统在银行业的落地,通过安全闭环设计(身份认证→输入过滤→输出合规)与智能检索生成(混合索引→动态优化→事实性校验),实现了从“数据管理”到“智能决策”的跨越。其核心价值在于:
- 效率提升:客服响应速度提高50%,减少人工介入;
- 风险可控:敏感信息泄露率降低90%,符合金融监管要求;
- 体验优化:个性化回答准确率>85%,增强客户粘性。
未来,随着多模态检索(如图表解析)与边缘计算(本地化部署)技术的成熟,RAG系统将进一步赋能银行智能风控、财富管理、合规审查等场景,推动金融服务的全面智能化。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 869
869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









