






本教程没有难懂的理论,全是实操的截图,非常通俗易懂。
能够帮你在最短的时间里,掌握Stable Diffusion的核心操作方法。真正有效地提高工作的效率。
教程主要是讲我们在工作中高频使用的4个功能模块:文生图、图生图、后期处理和标签器。如下图:
希望对你有所启发。
目录:
1. Stable Diffusion 高效工作流程
2. 大模型、外挂VAE模型、LORA模型、CLIP终止层数
3. 提示词
4. 采样迭代步数
5. 采样器
6.【重要】Controlnet
7. 放大功能
8. CFG scale(提示图相关性/提示词引导系统)
9. CFG scale和采样器的关系
10. Seed值
11. 标签器
1. Stable Diffusion 高效工作流程
1.1 创意阶段:
效率高:【草图 + ControlNet + 提示词】这个方法出图的确定性高,但要一定的美术基础。
效率高:【网图 + ControlNet + 提示词】根据需求找一些合适的网图,再用SD生图。
效率高:【复制C站的图片信息】这个方法比较省事,但是不太好找到和需求接近的图。
效率低:【提示词】这个方法比较费时间,要不断地调整提示词去跑图抽盲盒。
1.2 深入阶段:
效率高:【PS修型 + 局部重绘】这个方法出图的确定性高,但要一定的美术基础。
效率低:【提示词 + 局部重绘】这个方法比较费时间,要不断地跑图抽盲盒。
1.3 最后整理、交付阶段:
效率高:【后期处理】确定性最高,1:1放大原图。
效率低:【高分辨率修复(Hires.fix)】需要调参数,比较费时间。
效率低:【SD脚本放大功能(SD upscale)】需要调参数,比较费时间。
2 大模型、外挂VAE模型、LORA模型、CLIP终止层数

2.1 大模型:
大模型决定渲出来的风格。
用素材+SD底模(如SD1.5/SD1.4/SD2.1),深度学习之后炼制出的大模型,可以直接用来生图。
大模型决定了最终出图的大方向 。
2.2 外挂VAE模型:
这个模型类似于PS滤镜。
是对大模型的补充,稳定画面的色彩范围。
作用是:滤镜+微调。
系统自带的VAE是animevae,效果一般,建议可以使用kl-f8-anime2或者vae-ft-mse-840000-ema-pruned。
anime2适合画二次元。
840000适合画写实人物。
2.3 LORA模型:
它是加强某一种风格的模型。
大模型的低秩适应,可以理解为模型插件。
它是在基于某个大模型的基础上,深度学习之后炼制出的小模型。
需要搭配大模型使用,可以在中小范围内影响出图的风格,或是增加大模型所没有的东西。
如果分不清大模型、LORA模型、VAE模型,可以上这个网址查看:https://spell.novelai.dev/

2.4 CLIP终止层数:
它就是:对比(语言到图像)预训练。
CLIP终止层次越小,渲出的图越接近我们的提示词。数值越大越不像。


3 提示词
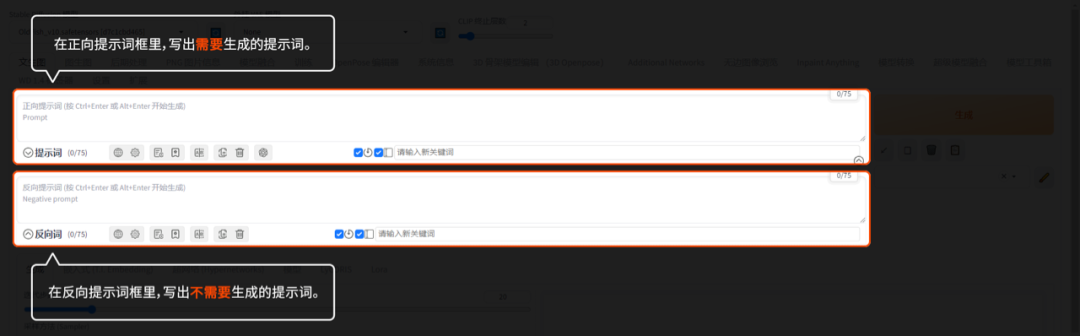
正向提示词:
在正向提示词框里,写出需要生成内容的提示词。
反向提示词:
在反向提示词框里,写出不需要生成内容的提示词。
3.1 提示词相关性:
关于人物类的提示词,一般将提示词相关性控制在 7-15 之间。
关于建筑等大场景类的提示词,一般控制在3-7左右。
3.2 正向提示词建议书写结构:
画面主要元素,画面细节描述,景别描述,风格描述,画面质量描述。

3.3 提示词的分隔与权重:
1. 提示词要用英文“ , ” 隔开。
2. SD的提示词是没有从左到右的权重的,也就是说提示词的排名不分先后。如要加减提示词的权重,可以通过括号和数字来实现。
3.4 正向质量提示词(通用)
3.4.1 清爽风格的质量正向提示词:
Highest quality, ultra high definition, masterpiece, 8k quality
这段质量提示词生出的造型准确率比较高。适合二次元的风格。

3.4.2 厚重风格的质量正向提示词:
{{masterpiece}},{best quality},{highres},original,reflection,unreal engine,body shadow,artstationextremely detailed CG unity 8K wallpaper
这段质量提示词生出来的全身图造型准确率比较低,主要是脸部和手部的造型有破坏。

3.5 反向提示词(通用):
NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs)))
3.6 提示词融合
3.6.1 “ _ ”:
在关键词和关键词之间加上“ _ ”,就可以把2种不同的东西融合在一起。如:man_chicken。

3.6.2 [cat🐶2]:
[cat🐶2]:中括号里的数字“2”是可以根据效果进行调整的。
这个数字代表的是渲染A到第几张时开始渲染B。
这个目前比较好用,就是在一只动物中,有猫和狗的特征,像猫又像狗。后面的数字,是控制像猫多点还是像狗多点,要根据渲图的效果不断调试。

3.6.3 [cat|dog]:
[cat|dog]:这个也是A和B融合的用法,一半是A一半是B。

3.6.4 “ and ”:
在2个或2个以上的词之间加上“and”,生出来的图就会出现这些元素。

3.6.5 “ / ”:
在2个关键词之间加“ / ”,是混合的用法。如:white/yellow flower,就是生成黄色和白色混合的花。

3.7 提示词隔开
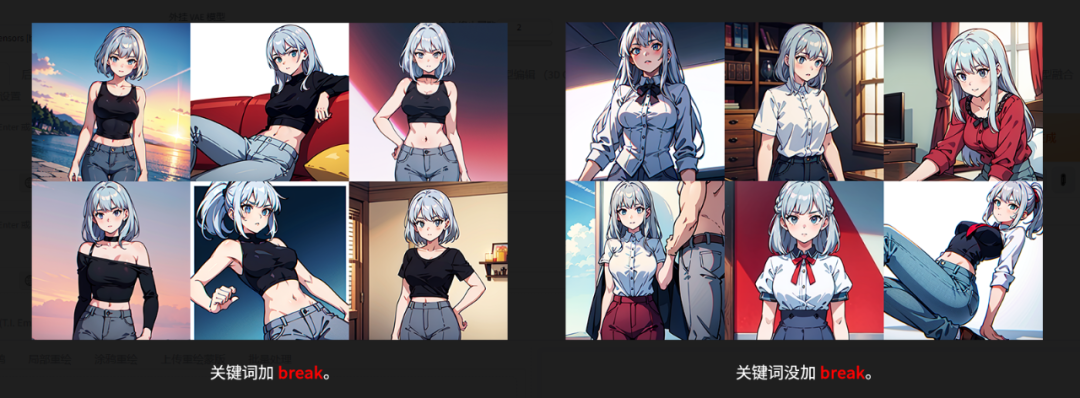
3.7.1 “ break ”:
在词与词之间,用“ break ”隔开,如:在银色头发、黑上衣、灰背带裤的女孩的关键词1girl,Silver hair break Black blouses break Gray pants中加入“ break ”,这样可以提高关键词的准确率。
3.8 提示词权重:
括号 | ()小括号 | []中括号 | { }大括号 |
简介 | ↑ 加权, 每加一层()加权0.1 | ↓ 降权, 每加一层[]降权0.1 | ↑ 加权, 每加一层 { } 加权0.05 |
权重值 (默认值:1) | Prompt = 1 (Prompt)=1.1 ((Prompt)) = 1.21 (((Prompt)))=1.33 | Prompt = 1 [Prompt]=0.9 [[Prompt]] =0.81 [[[Prompt]]]=0.729 | Prompt = 1 {Prompt}= 1.05 {{Prompt}}= 1.1025 {{{Prompt}}}=1.15 |
加权重的快捷键:Ctrl + 上/下箭头。
关键词的权重,一般在0.5~2之间。
注意:避免个别词条权重过高,安全范围在1上下0.5左右,如果想要强调一个词条可以多写几个类似词条。
括号加数字:
例1: (white flower:1.5),含义:调节白花(white flower)权重为原来的1.5倍(增强)。
例2: (white flower:0.8),含义:调节百花(white flower)的权重为原来的0.8倍(减弱)。
3.9 提示词人物特定视角用法:
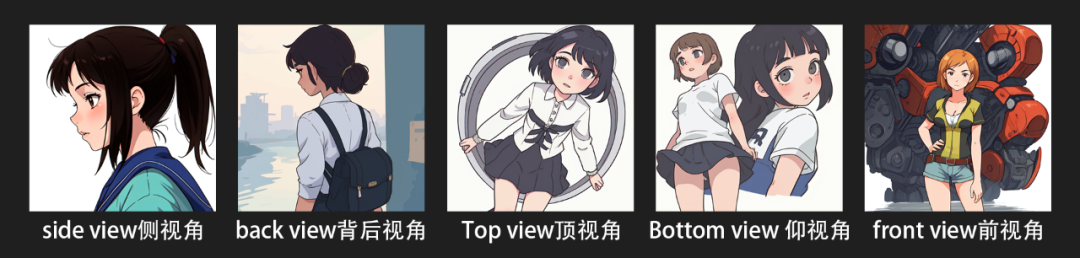
以下关键词可以控制人物的视角:
-
front view:前视角;
-
side view:侧视角;
-
back view:背后视角;
-
Top view:顶视角;
5. Bottom view:仰视角。
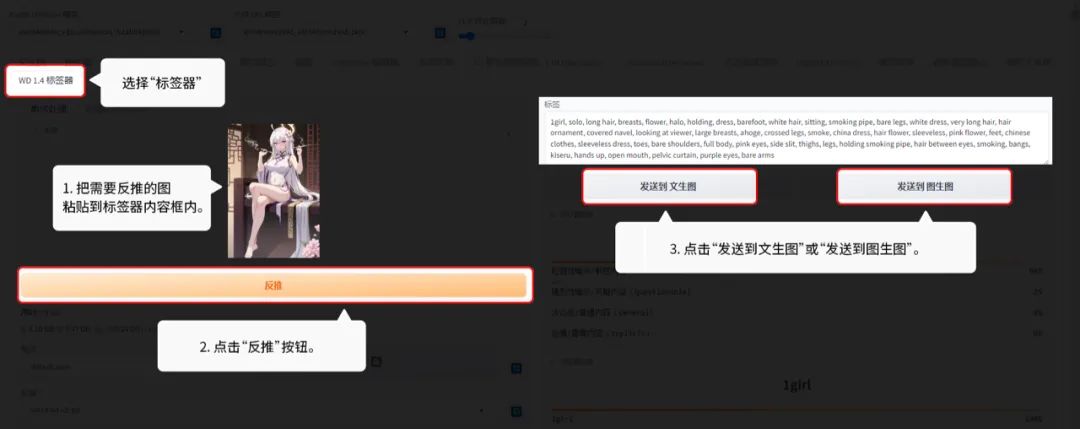
3.10 提示词反推(图生图里的选项):
【图生图】的功能展示:

CLIP反推:
反推出来的是自然语法的描述。也就是一句话。
DeepBooru反推:
反推出来的是标签语法。也就是一个一个词语。
3.11 复制来的模型信息的粘贴方法:
C站网址:https://civitai.com/
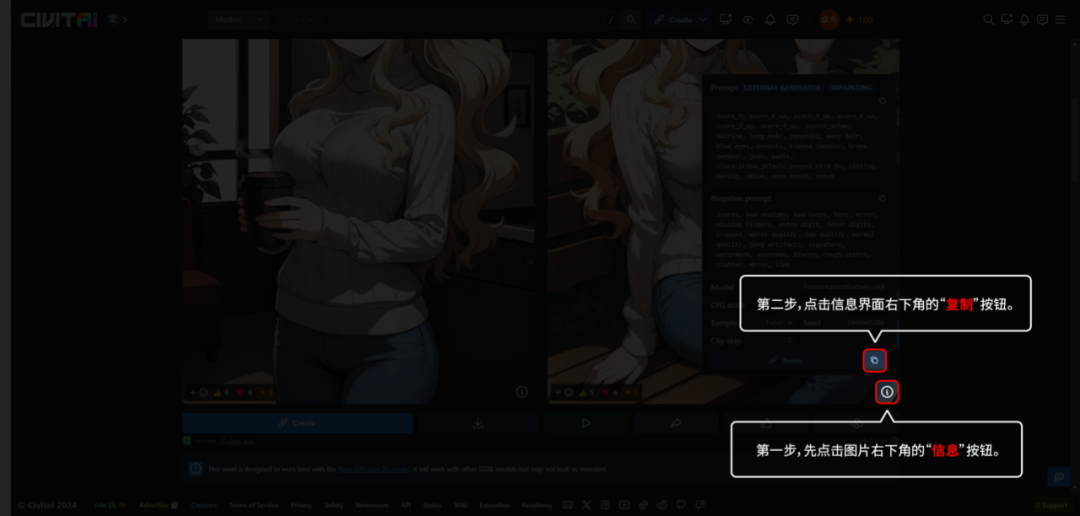
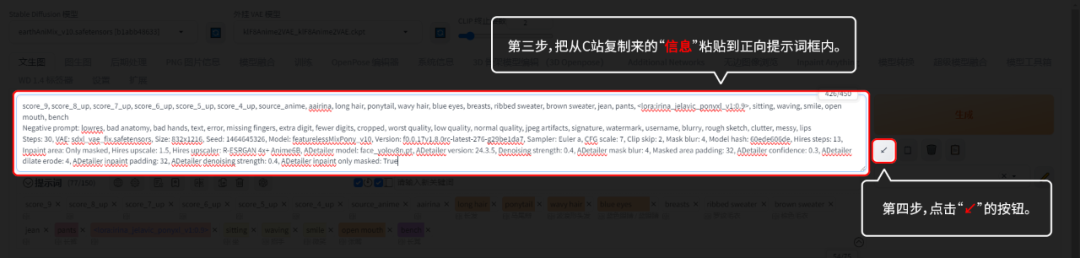
从C站复制来的模型信息,粘贴在“正向提示词”框里,然后点击“↙”,复制来的模型信息就自动分好。
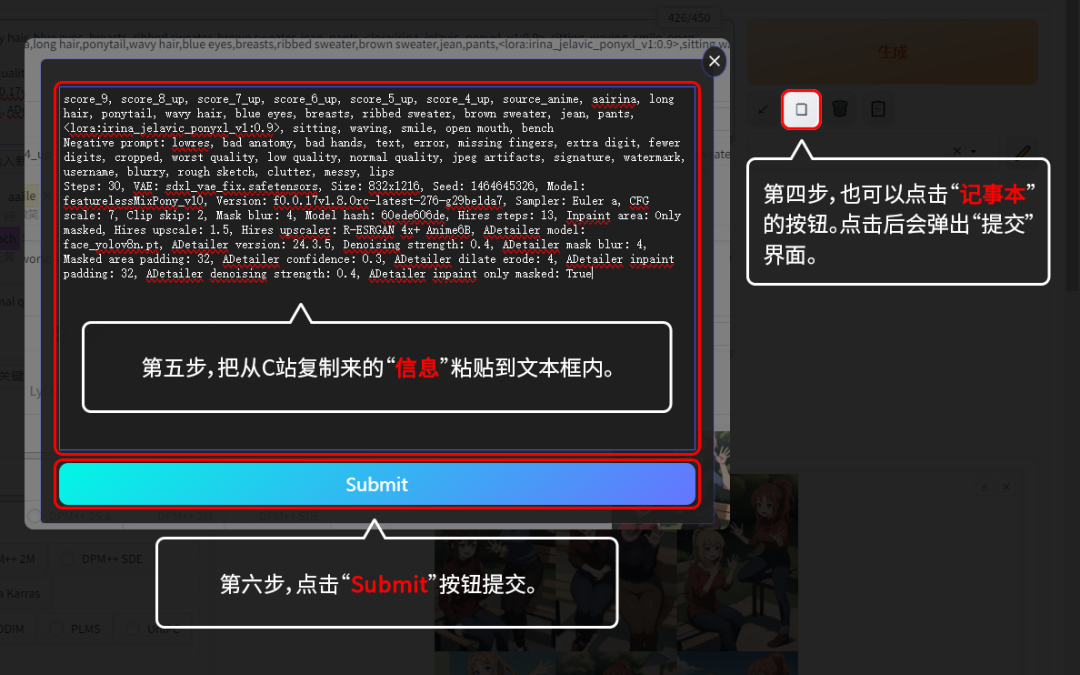
也可以点击“记事本”按钮,会弹出一个弹窗,把从C站复制来的模型信息粘贴到这个弹窗里,然后提交。复制来的模型信息就可以自动分好。
4 采样迭代步数:
控制降噪的轮次,选择50就是降噪50轮之后将图像经过解码器返回给用户。
5 采样器
5.1 不同采样器的渲染效果对比:
以下图片生成的正向提示词:cat
随机数种子(Seed):1242989826
6 Controlnet:
Control Net是一款可以对Stable Diffusion扩散模型进行精确控制的插件。能够获取参考图片的线条、法线、景深等等信息。由此,出图的确定性也较高。
6.1 人物姿势
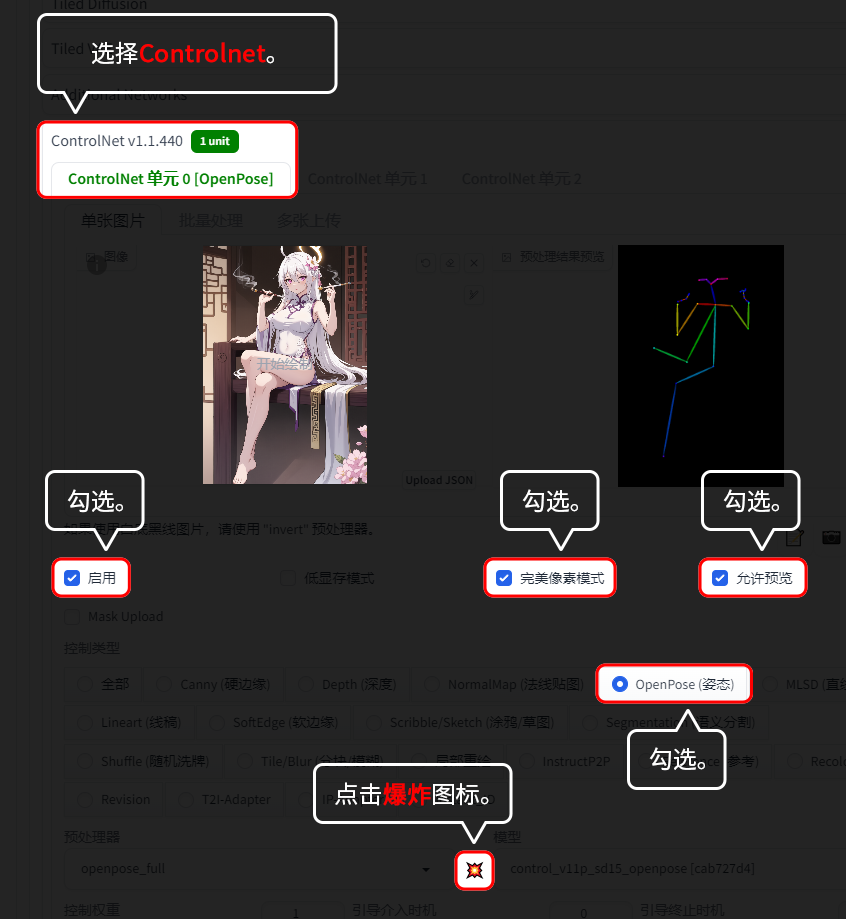
6.1.1 Openpose(姿态):
Openpose(姿态)可以提取图片中角色【身体】、【身体+手指】、【身体+表情】、【表情】、【身体+手指+表情】的信息。
用【文生图】的功能演示。【图生图】模块的话,是没有“爆炸”图标的,所以不用点“爆炸”图标。
6.2 线条
6.2.1 Canny(硬边缘):
Canny(硬边缘)识别出来的线条最多,更好地还原原图,对二次元风格比较适用。
用【文生图】的功能演示。【图生图】模块的话,是没有“爆炸”图标的,所以不用点“爆炸”图标。
6.2.2 MLSD(直线):
MLSD(直线)只能识别直线,常用于建筑设计方面。
用【文生图】的功能演示。【图生图】模块的话,是没有“爆炸”图标的,所以不用点“爆炸”图标。
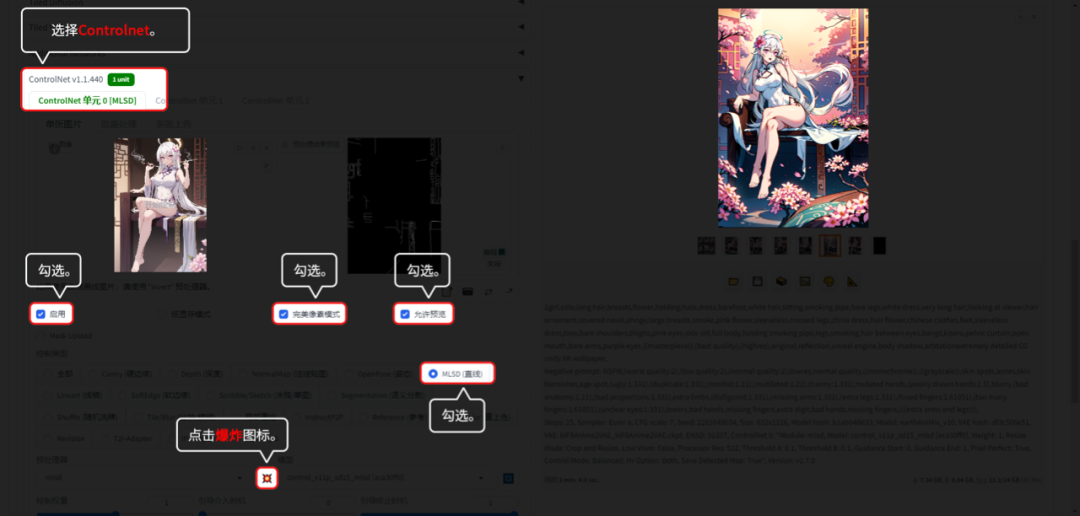
6.2.3 Lineaet(线稿):
Lineaet(线稿)可以针对不同风格的图片提取线稿。
用【文生图】的功能演示。【图生图】模块的话,是没有“爆炸”图标的,所以不用点“爆炸”图标。
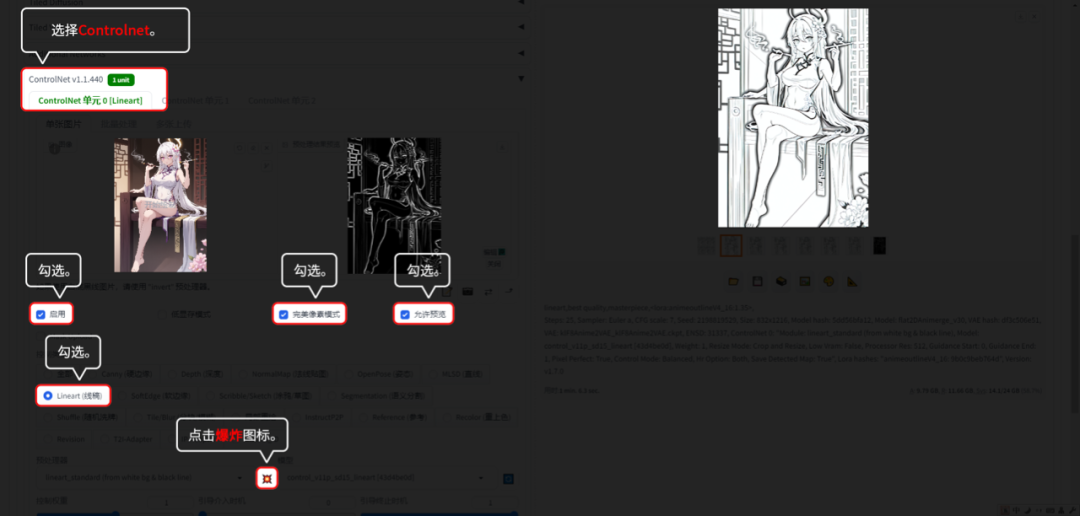
1、 在文生图正向提示词框中输入:lineart,best quality,masterpiece
2、 然后选择模型和线稿Lora。
3、 在ControlNet里的ControlNet Unit 0里放入需求提取线稿的原图。
4、 控制类型选 Lineart (线稿) ,记得点“爆炸”图标。
5、 最后点“生成”图片。
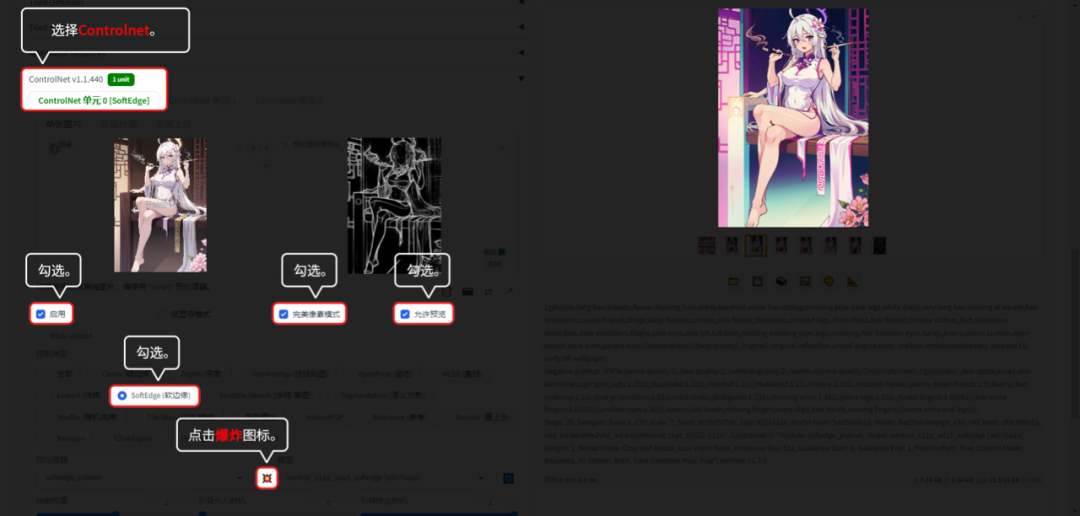
6.2.4 SoftEdge(软边缘):
SoftEdge(软边缘)只识别大概的轮廓,给SD更大的发挥空间。
用【文生图】的功能演示。【图生图】模块的话,是没有“爆炸”图标的,所以不用点“爆炸”图标。
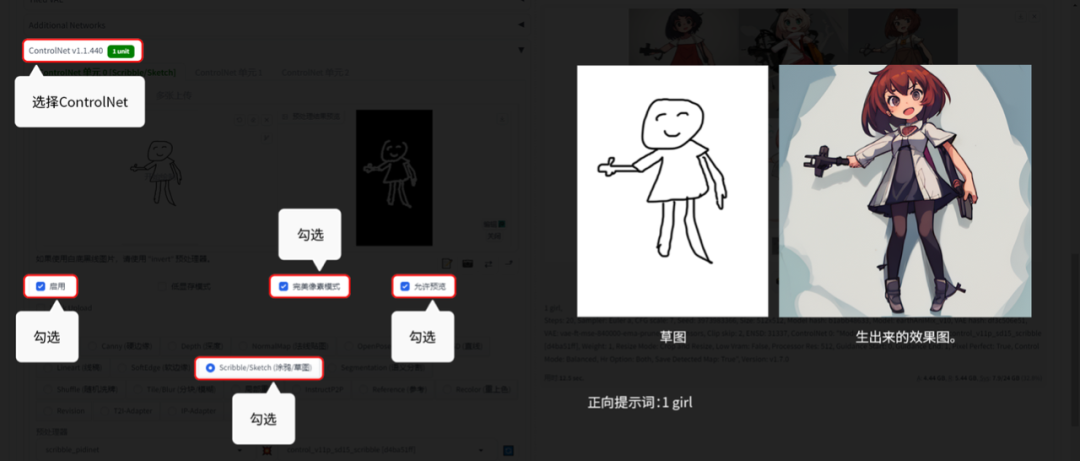
6.2.5 Scribble/Sketch(涂鸦/草图):
Scribble/Sketch(涂鸦/草图)就是涂鸦,适合在前期用草图去生图。
用【文生图】的功能演示。【图生图】模块的话,是没有“爆炸”图标的,所以不用点“爆炸”图标。
6.3 空间深度
6.3.1 Depth(深度):
Depth(深度)可以很好地还原物体的前后关系。
用【文生图】的功能演示。【图生图】模块的话,是没有“爆炸”图标的,所以不用点“爆炸”图标。
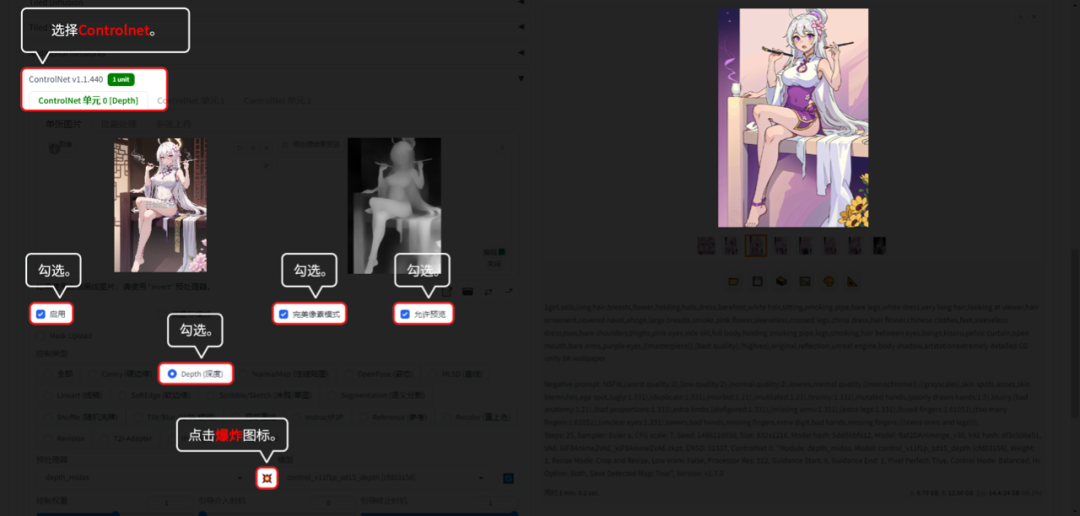
6.4 物品种类
6.4.1 Segmentation(语义分割):
Segmentation(语义分割)是通过不同的颜色控制不同的物品。
用【文生图】的功能演示。【图生图】模块的话,是没有“爆炸”图标的,所以不用点“爆炸”图标。
Stable Diffusion_T2i_Seg颜色对照表,
网址:https://docs.qq.com/doc/DTFVMdUdkQXRVaXJX
6.5 风格
6.5.1 T2l-Adapter:
T2l-Adapter就是还原原图的颜色。
【图生图】的功能演示:
正向提示词:1 girl,Highest quality,ultra high definition,masterpiece,8k quality
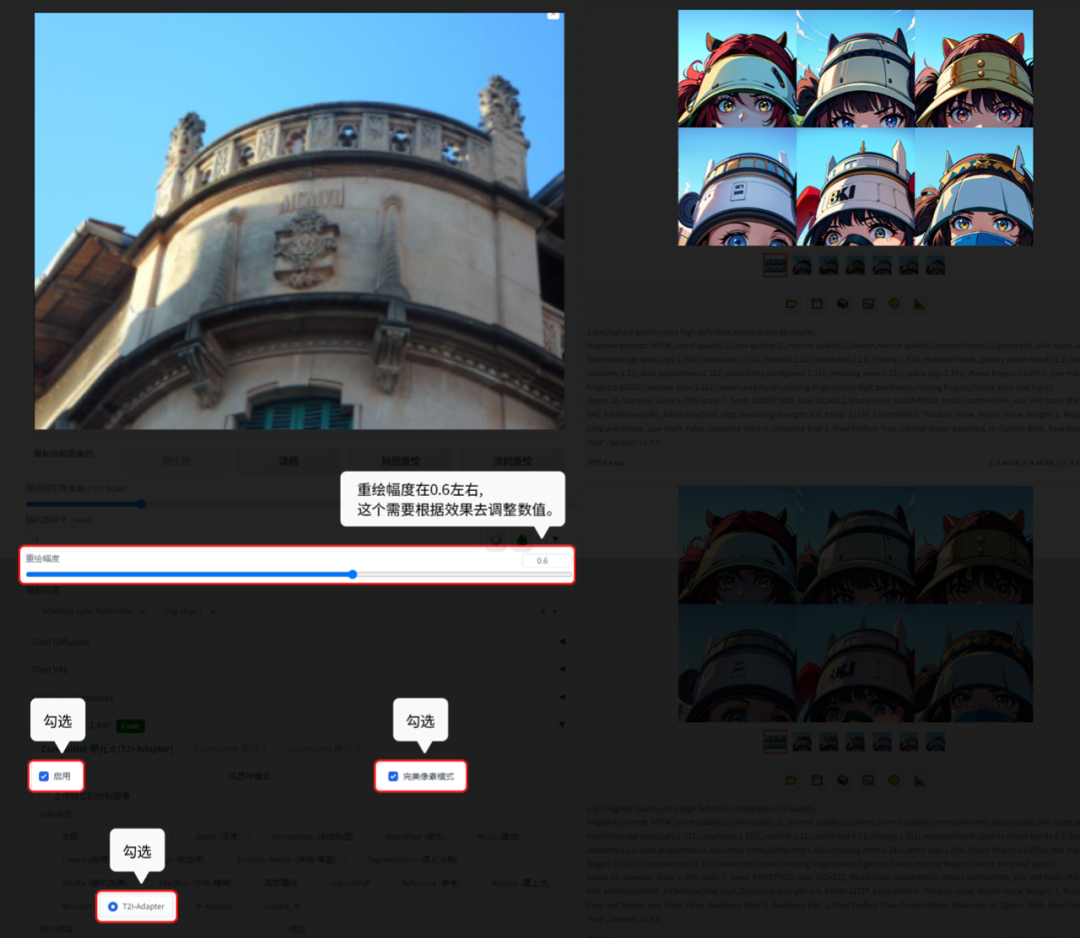
6.5.2 IP-Adapter:
IP-Adapter就是参考整张图。
【图生图】的功能演示:
正向提示词:1 girl,Highest quality,ultra high definition,masterpiece,8k quality
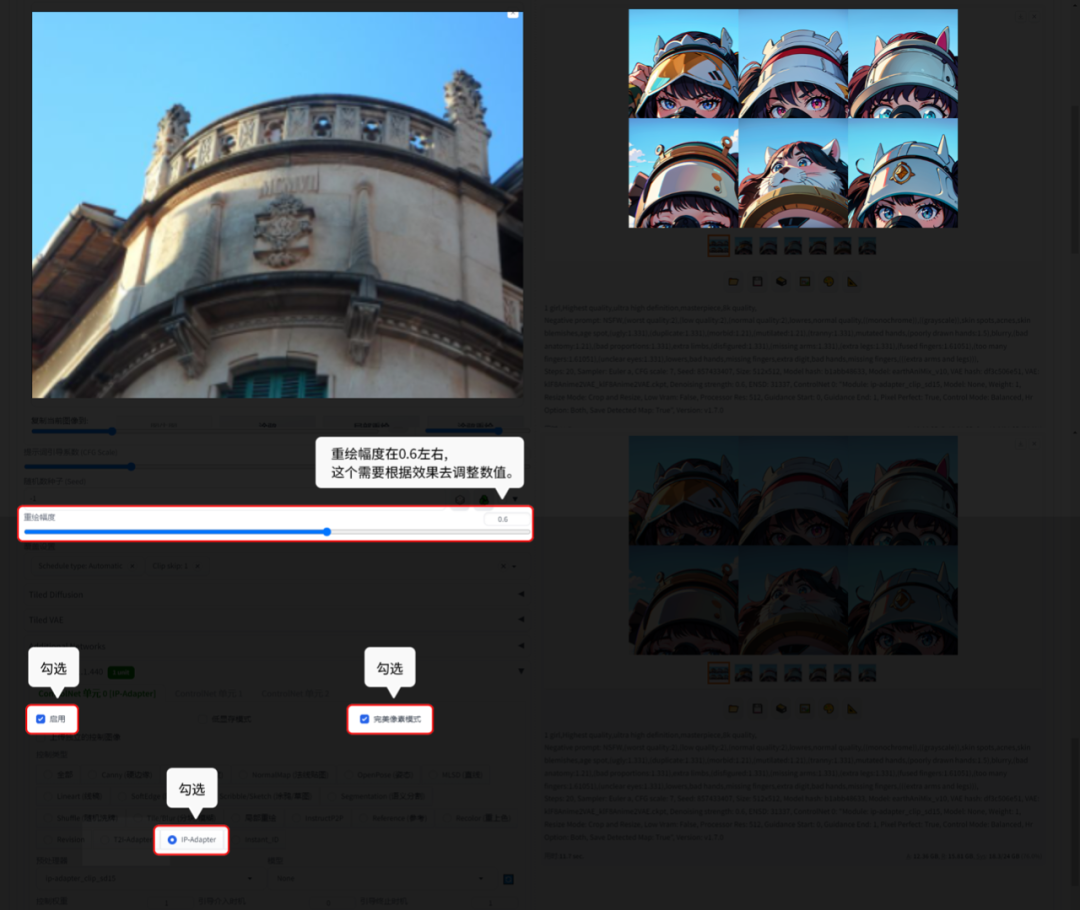
6.5.3 Reference(参考):
Reference(参考)就是参考原图的颜色或角色。
【图生图】的功能演示:
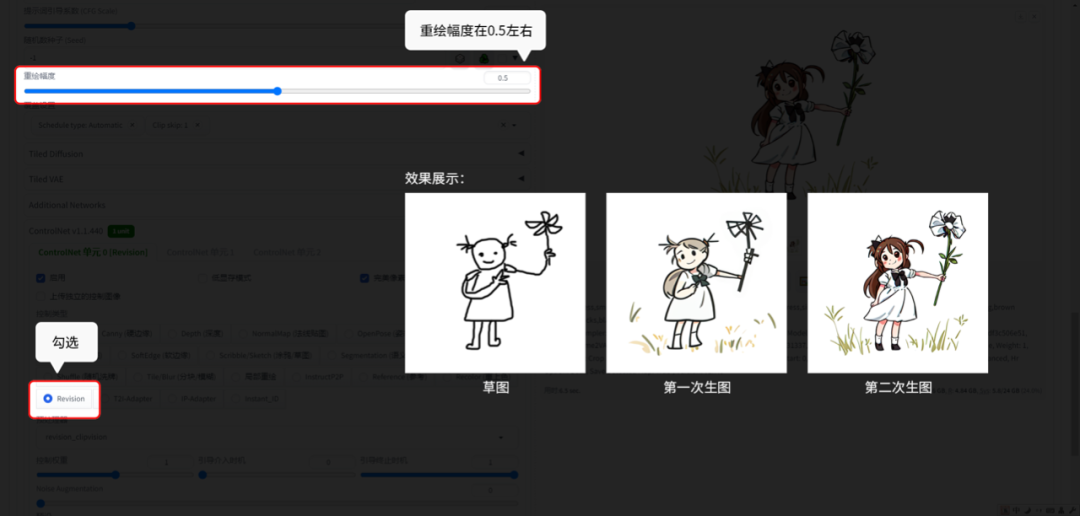
6.5.4 Normalmap(法线贴图):
Normalmap(法线贴图)就是参考原图的光影和姿势。
这个我常用于风格转换。【重绘幅度:0.5】。
【图生图】的功能演示:
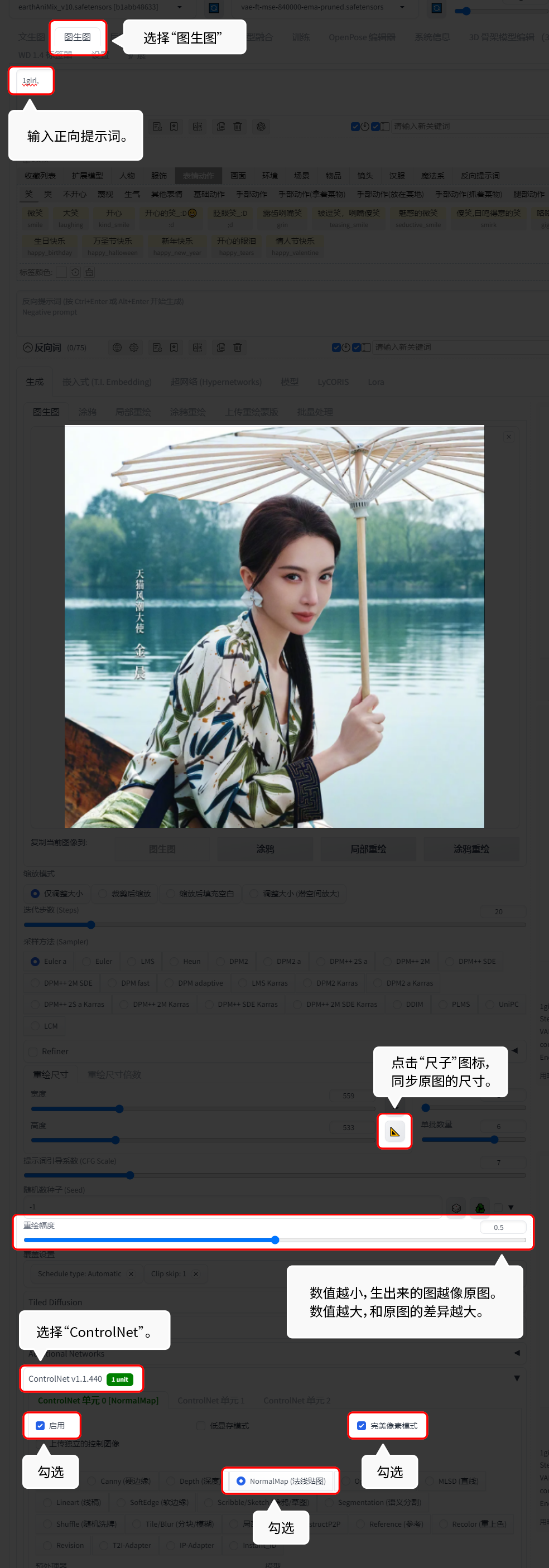

图片风格生成后的效果 ↑↑↑
6.5.5 Shuffle(随机洗牌):
Shuffle(随机洗牌)就是将图片的颜色混合融到新图里。
【图生图】的功能演示:
正向提示词:1 girl,Highest quality,ultra high definition,masterpiece,8k quality
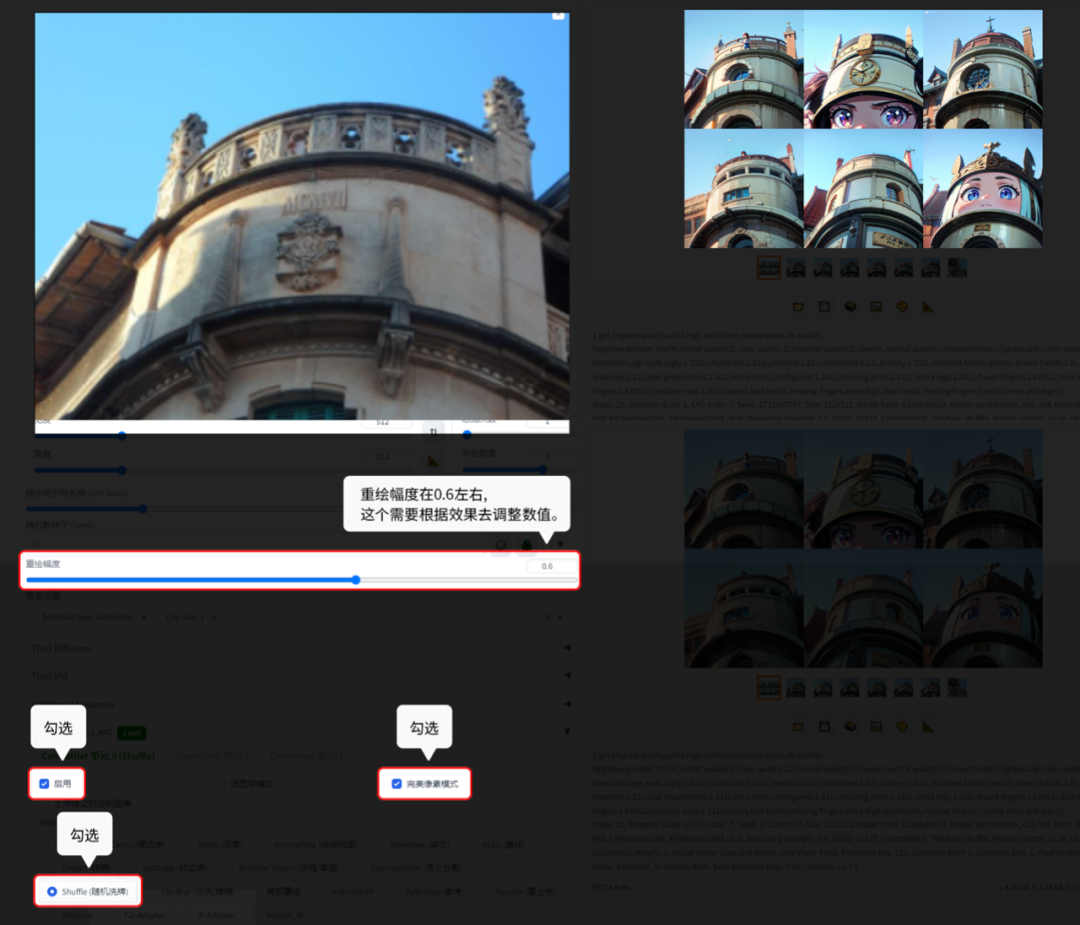
6.6 模糊处理
6.6.1 Tile/Blur(分块/模糊):
Tile/Blur(分块/模糊)就是把画面风格块面化,有点像艺考时画的水粉画。
【图生图】的功能演示:
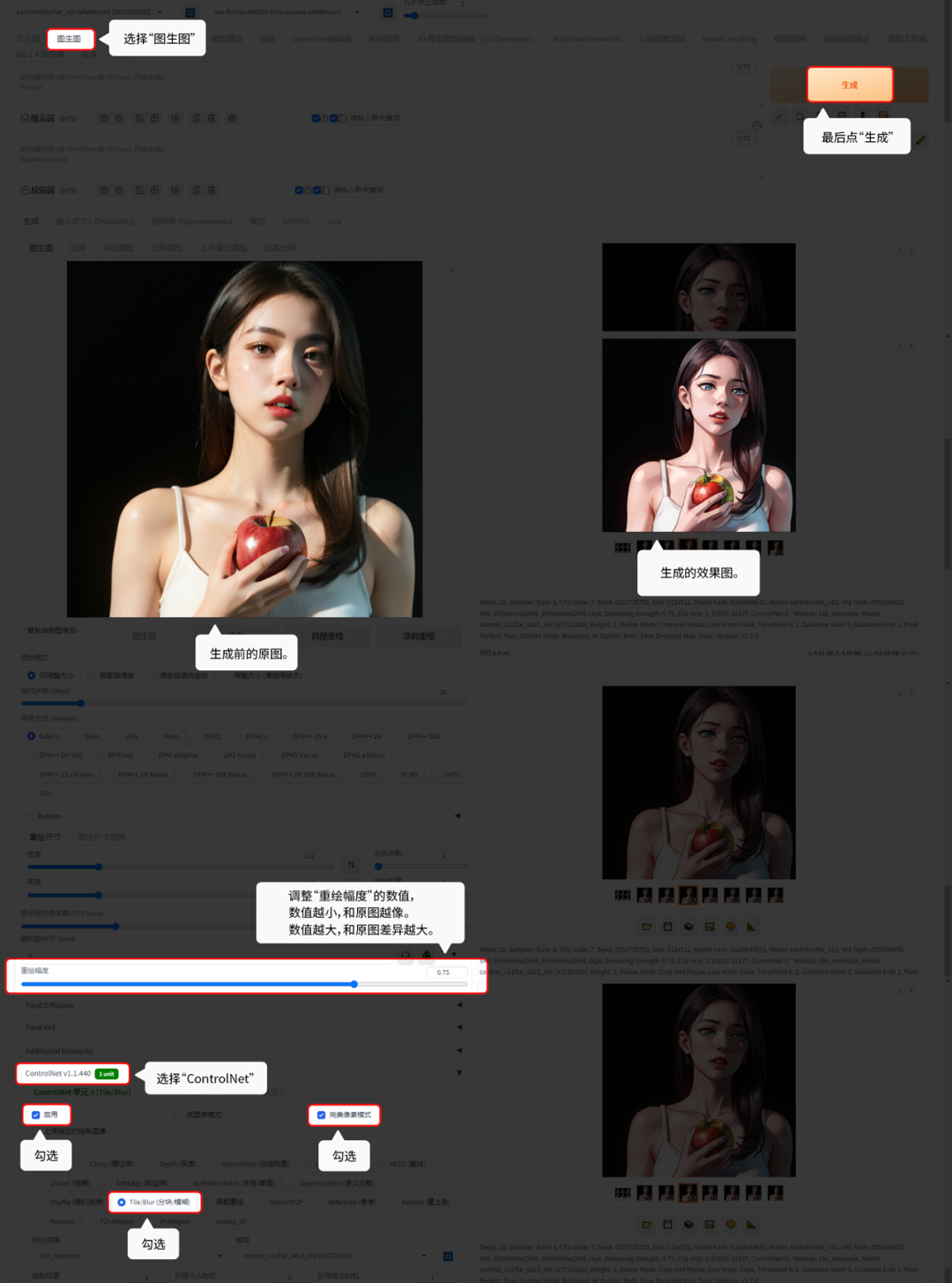

原图和生成后的对比 ↑↑↑
6.7 重绘
6.7.1 局部重绘:
局部重绘就是类似图生图的局部重绘,重绘画面的内容。
在文生图的正向提示词框中输入提示词:(white cat:1.8)
用【文生图】的功能演示。【图生图】模块的话,是没有“爆炸”图标的,所以不用点“爆炸”图标。
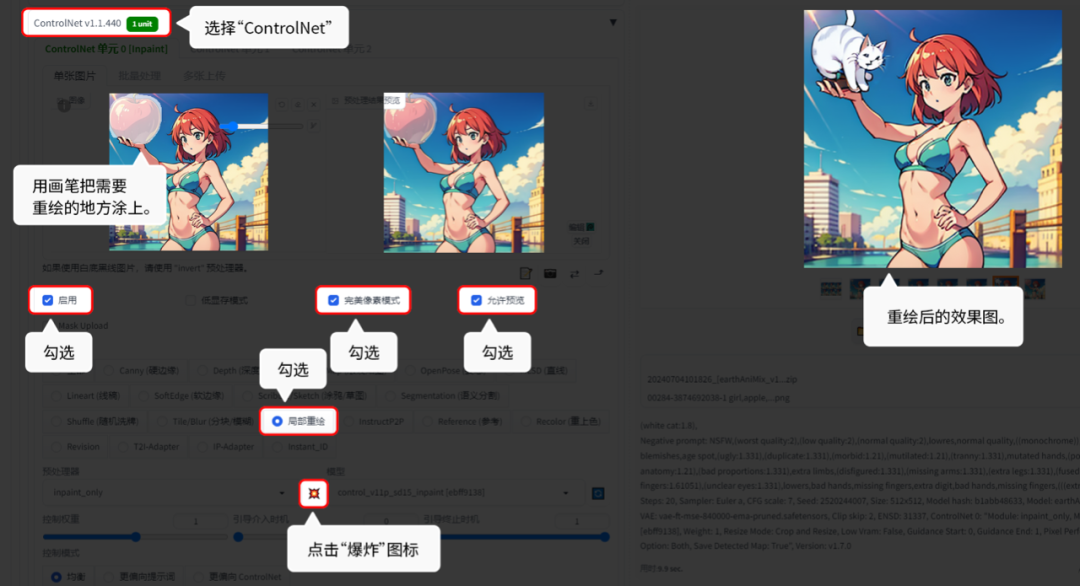
这个方法还可以用在去除不要的东西,如下面实例:
【图生图】的功能演示:
正向提示词:remove hands
局部重绘前和局部重绘后的对比 ↑↑↑
6.7.2 Recolor(重上色):
Recolor(重上色)就是给照片上色。
在文生图的正向提示词中输入提示词:1girl,solo,long hair,flower,halo,dress,barefoot,dark red hair,sitting,pipe,bare legs,white dress,very long hair,hair accessory,covering navel,looking at viewer,crossed legs,smoke,Chinese clothing,hair flower,sleeveless,pink flower,feet,Hanfu,sleeveless dress,toes,bare shoulders,whole body,pink eyes,side seams,thighs,beautiful legs,holding a pipe,bangs,raising hands,open mouth,purple eyes,Highest quality,ultra high definition,masterpiece,8k quality
用【图生图】的功能演示:
原图和生成后的对比 ↑↑↑
6.8 特效
6.8.1 Revision:
Revision就是修正原图中的物体。
用【图生图】的功能演示:
输入正向提示词:Shape your face
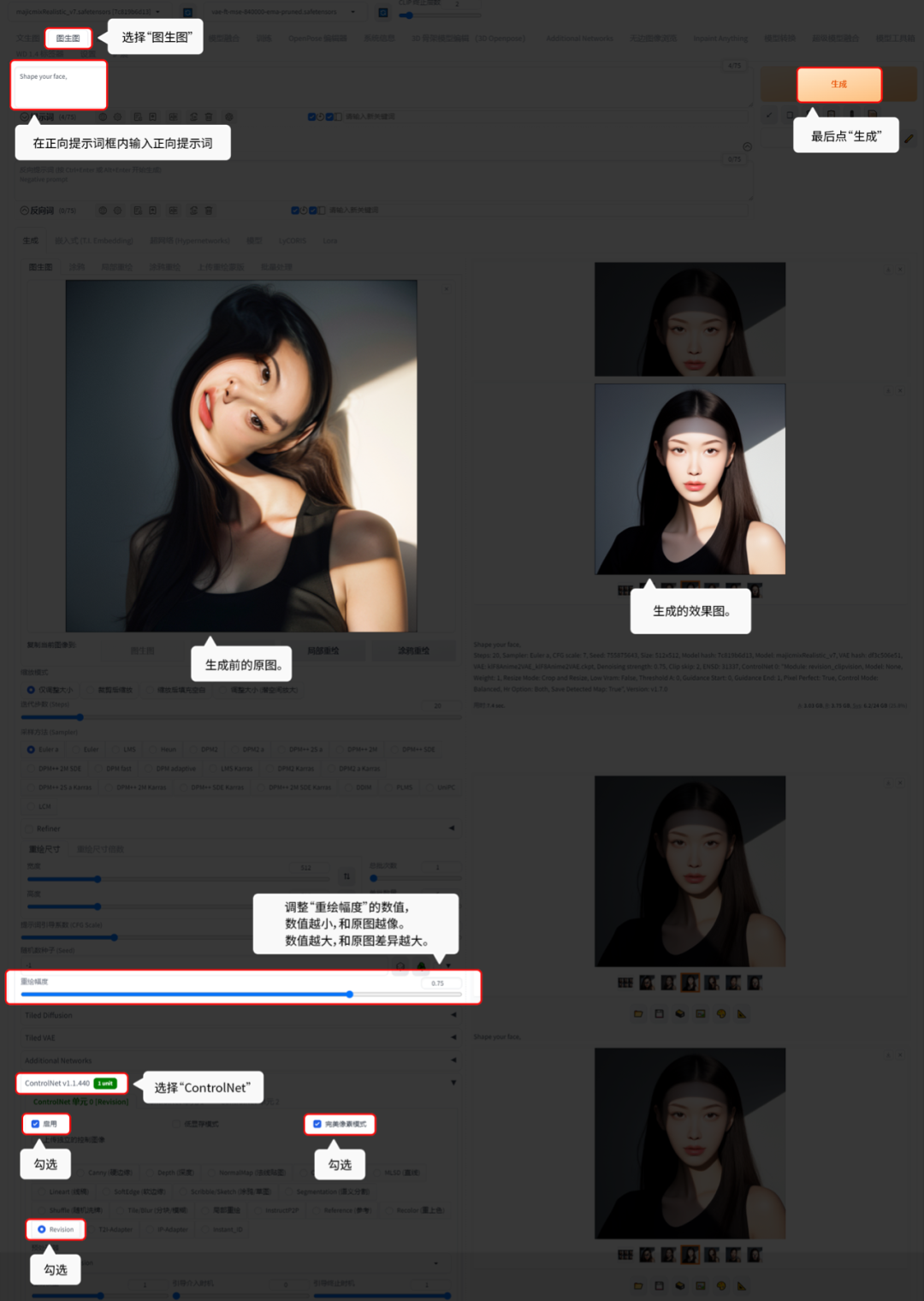
 原图和生成后的对比 ↑↑↑
原图和生成后的对比 ↑↑↑
6.9 ControlNet 混合用法:
用【 文生图】的功能演示,具体操作如下:
操作要点:在ControlNet里的ControlNet Unit 0里放入要参考的角色,控制类型选 Reference (参考) ,记得点爆炸图标。在ControlNet Unit 1里放入要参考的动态,控制类型选 Openpose(姿态) ,记得点爆炸图标 。
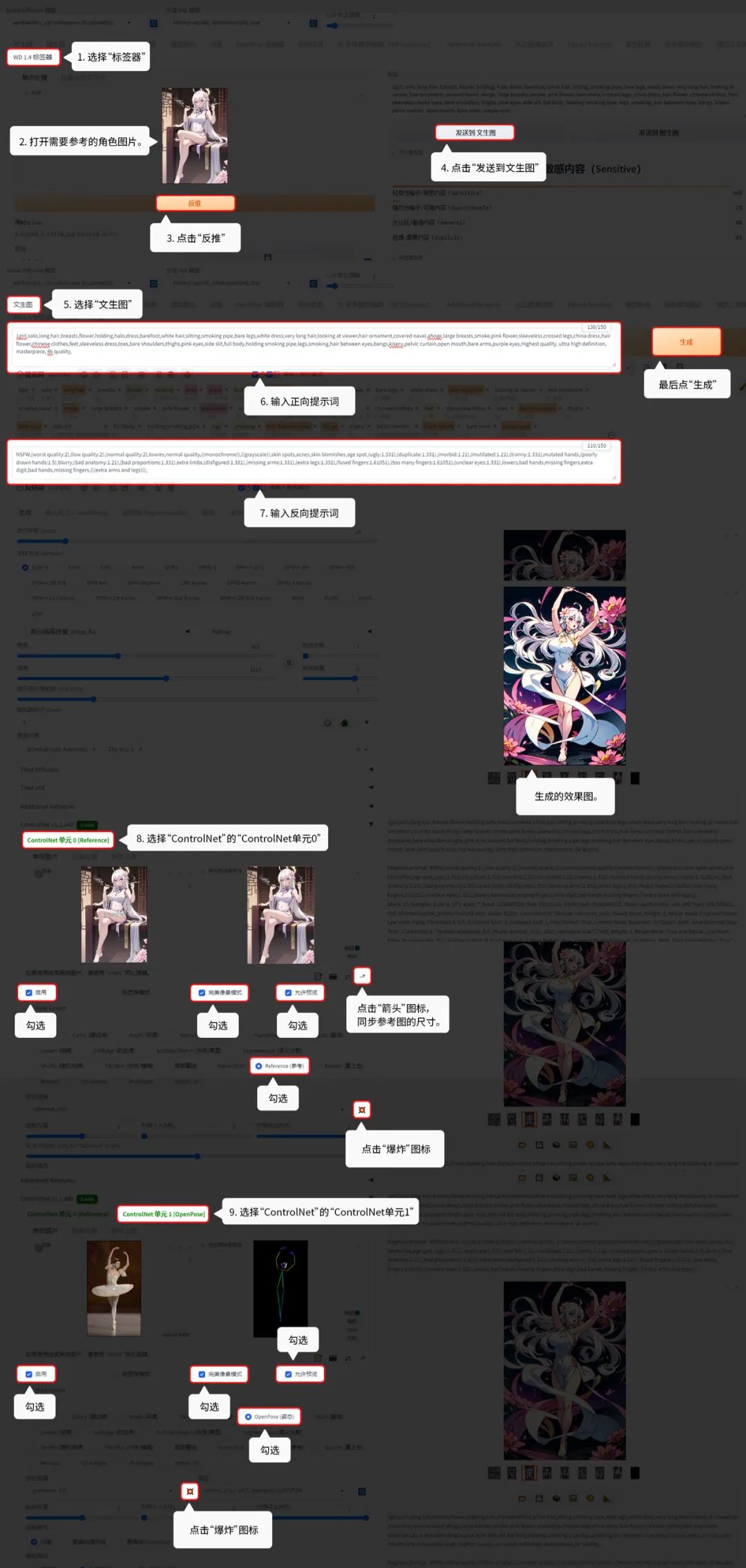
参考角色和生成后的效果对比 ↑↑↑
7 放大功能
7.1 高分辨率修复(Hires.fix)(文生图功能):
【文生图】的功能演示:

可以简单理解为,生成一张图后,又以图生图的方式将图放大,增加细节。所以,它拥有自己的【放大算法】【迭代步数】【重绘幅度】等。
放大算法:与采样方法概念类似。
迭代步数:就是采样步数。
重绘幅度:重绘幅度数值越大,生出来的图就和原图的差异越大,数值越小和原图差异越小。
1、 0:等于完全不重画。
2、 0.2~0.45:生出来的图与原图相似度高,变化幅度小。
3、 0.45~0.75:生成更高精度的图,和原图差异大。
7.2 后期处理(高清修复):
【后期处理】的功能演示:
原图和生成后的对比 ↑↑↑
7.3 SD脚本放大功能(SD upscale):
【图生图】的功能演示:
放大功能特点对比:
文生图:高清修复 | 图生图:SD放大 | 后期处理:附加功能 |
“打回重画,再来一幅” | “分几块画,拼在一起” | “简单放大,随时可用” |
分两步,第一步生成低分辨率的图画,第二步使用它指定的高清算法,生成一个高分辨率的版本,在不改变构图的情况下丰富细节。 | 根据指定的放大倍数,将图生图的图像拆解成若干小块按照固定逻辑重绘,再合并成一张大图,可以实现在低显存的条件下生成大尺寸的图片。 | 利用各种放大算法,在图像生成后再对它进行单独处理,使之拥有更高的分辨率尺寸。 |
优势: 1. 不会改变画面的构图(因为随机种子固定)。 2. 稳定克服多人、多头有分辨率产生的问题。 3. 操作简便、清晰、直观。 | 优势: 1. 可以突破内存限制获得更大分辨率。 2. 画面精细度更高,对于细节的丰富更加出色。 | 优势: 1. 使用方便,操作简单,随时可以调用。 2. 计算速度快,没有重绘压力。 3. 完全不改变图片内容。 |
缺点: 1. 仍然受到最大显存的影响。 2. 计算速度相对较慢。 3. 偶尔”加戏“,出现莫名其妙的额外元素。 比较难生出和原画一样的图。 | 缺点: 1. 分割重乎的过程不可控(语义误导格分界线割裂)。 2. 操作繁琐且相对不直观。 3. 偶尔加戏,出现莫名的额外元素。 对于缺点解决方法:增加缓冲带,重绘幅度降低为0.4。 | 缺点: 1. 放大功能的效果不太显著。 简单,高效地生出和原图一样的图。 |
8 CFG scale(提示图相关性/提示词引导系统):
1、 CFG scale的数值越高,渲出的图和提示词越接近,数值越低越不像。
2、 CFG scale的默认值是7,数值范围值是1~30。
【文生图】和【图生图】的功能:
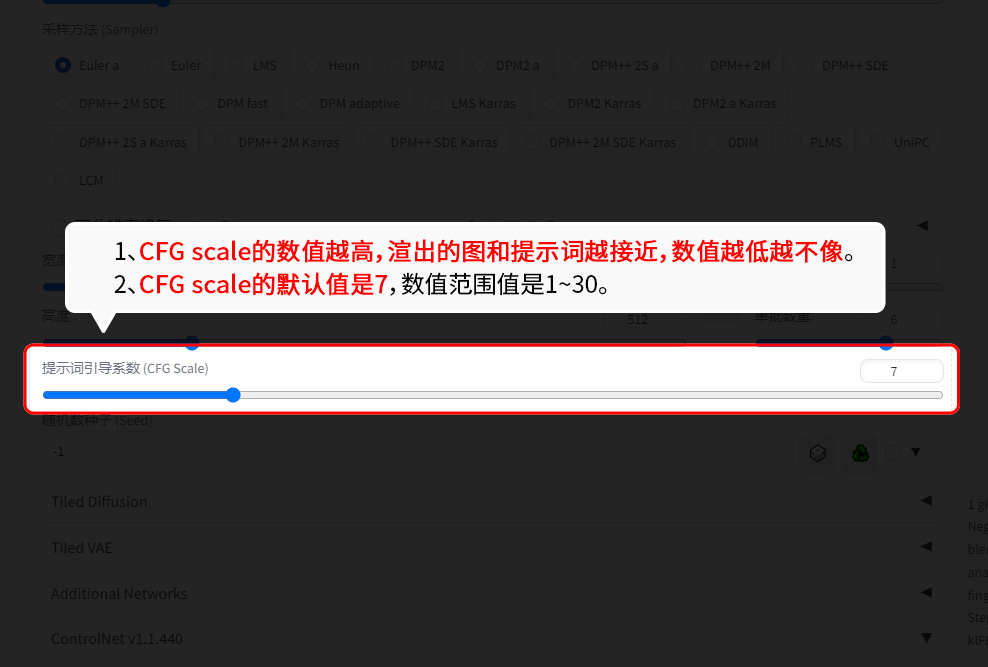
1、 自由度:由高到低。
2、 饱和度:由低到高。
3、 对比度:由低到高。
4、 在不同的采样器下,当CFG scale值高于某个数值时,图片质量会严重下降。(不是越高越好。)
10 Seed值:
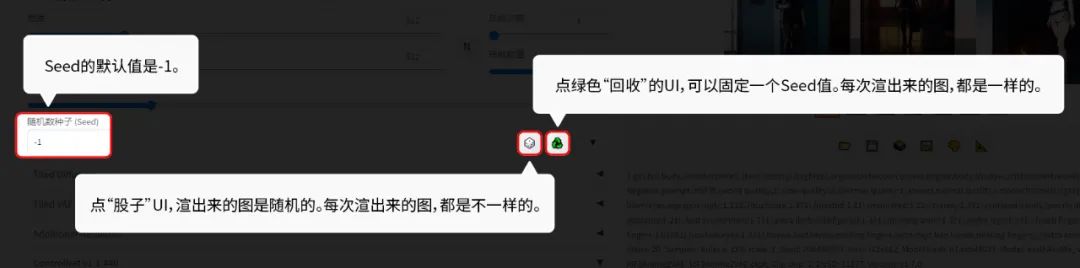
Seed值我们可以简单地把它理解为图片的ID值。
1、 Seed的默认值是-1。
2、 点“股子”UI,Seed的值是-1,渲出来的图是随机的。每次渲出来的图,都是不一样的。
3、 点绿色“回收”的UI,可以固定一个Seed值。每次渲出来的图,都是一样的。
11 标签器:
标签器的作用是高效地提取图片里的关键词。
如何学习Stable Diffusion ?
2023年,AIGC绘画元年,从年初以来,以Midjourney和Stable Diffusion 为代表的AIGC绘画迎来春天,掀起了一场生产力革命。
Stable diffuson最大的优势在于它的可控性以及免费开源。很多人想学习和使用stable diffusion,网上一搜,往往在安装这一步就劝退了很多人。
也因为Stable diffusion中的参数非常非常多,极其容易劝退,但事实是,对于我们来说,只需要熟练使用即可,并不需要深入的去研究它的原理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的StableDiffusion学习资料包括:StableDiffusion学习思维导图、StableDiffusion必备模型,精品AI学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天)Stable Diffusion初始入门
该阶段让大家对StableDiffusion有一个最前沿的认识,规避碎片化学习,对SD的理解将超过 95% 的人。可以在相关讨论发表高级、不跟风、又接地气的见解,成为AI艺术创作领域的佼佼者。
-
1.Stable Diffusion的起源及工作原理
-
2.Midjourney跟Stable Diffusion之间的的区分指南
-
3.Stable Diffusion一键包快速实现部署
-
4.Stable Diffusion启动器参数
-
5.Stable Diffusion的“Settings”页面高效配置Al模型
-
6.Stable Diffusion的插件安装指南
-
7.汉化Stable Diffusion界面实操
-
8.Stable Diffusion中的大模型使用指南
-
9.Stable Diffusion VAE模型
-
10.txt2img文本提示转换成图像实操
-
11.生成(Generate)功能相关的系列按钮
-
12.单批跟总批的配比选择指南
-
13.采样方法
-
14.生成图像的引导迭代步数
-
…
第二阶段(30天)Stable Diffusion进阶应用
该阶段我们正式进入StableDiffusion进阶实战学习,学会构造私有知识库,扩展不同的艺术风格。快速根据甲方的要求改动高效出图。掌握智能绘图最强的AI软件,抓住最新的技术进展,适合所有需出图行业。真·生产力大爆发!!!
-
1.涂鸦Sketch功能
-
2.涂重绘鸦Inpainting Sketch功能
-
3.局部重绘Inpainting功能详解
-
4.上传蒙版Inpainting upload功能
-
5.segment anything辅助抠图功能
-
6.inpaint anything蒙版获取功能
-
7.ControlNet的起源及工作原理
-
8.ControlNet插件扩展功能
-
9.ControlNet基础界面使用指南
-
10.ControlNet五种线稿模型
-
11…ControlNet重绘修复模型
-
12.ControlNet 图像提示迁移模型实战
-
…
第三阶段(30天)专属Lora模型训练
恭喜你,如果学到这里,所有设计类岗位你将拥有优先选择权,自己也能训练Lora 了!通过对模型进行微调有效减少模型的参数量和计算量,以生成特定的人物、物品或画风,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
-
1.定制个人的LORA模型适配个性化需求
-
2.高质量素材过程中的重要事项收集指南
-
3.birme工具批量化的处理图片实战
-
4.BooruDatasetTagManager工具打标图片实战
-
5.正则化训练集使用指南
-
6.SD-tainerLORA训练工具
-
7.SD-tainer工具训练自己的Lora操作
-
8.LORA模型测试指南
-
…
第四阶段(20天):商业闭环
对氛围性场景,关键词技巧,图生图实操流程等方面有一定的认知,教你「精准控制」所有图片细节,可以在云端和本地等多种环境下部署StableDiffusion,找到适合自己的项目/创业方向,做一名被 AI 武装的社会主义接班人。
-
1.CodeFomer模型实战
-
2.固定同一人物形象IP实战
-
3.广告设计
-
4.电商海报设计
-
5.制作3D质感
-
6.室内设计全案例流程
-
7.AI赋能电商新视觉
-
8.老照片修复
-
9.小说推文
-
10.影视游戏制作
-
11.游戏开发设计
-
12.三维软件去精准辅助SD出高质量图实战
-
13.GFPGAN模型实战
-
…
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名AI绘图大神的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 4381
4381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









