






一、背景
最近 “TikTok 难民”涌入小红书,“小红书霸榜苹果 App Store” 等话题受到广泛关注,字节跳动的 Lemon8 也不相上下。当然,作为一个技术公众号,我们这里并不是要讨论这一现象,而是要介绍小红书的 NoteLLM,其主要用于小红书中的笔记推荐和标签生成。
对应的论文为:[2403.01744] NoteLLM: A Retrievable Large Language Model for Note Recommendation [1]
二、摘要
随着社交媒体平台如小红书和 Lemon8(字节) 的流行,用户生成内容(UGC)中的 Note 分享变得越来越普遍。这些平台鼓励用户分享产品评价、旅行博客和生活经历等,Note 推荐因此成为提升用户参与度的关键部分。
现有的 Online 方法仅将 Note 输入基于 BERT 的模型以生成 Note Embedding 来评估相似性。然而,这些方法可能未能充分利用一些重要线索,例如话题标签(Hashtag)或类别(Category)。实际上,学习生成 Hashtag/Category 有可能增强 Note Embedding,因为两者都将关键 Note 信息压缩至有限内容中。此外,LLM 在理解自然语言方面已显著超越 BERT,将 LLM 引入 Note 推荐具有广阔前景。
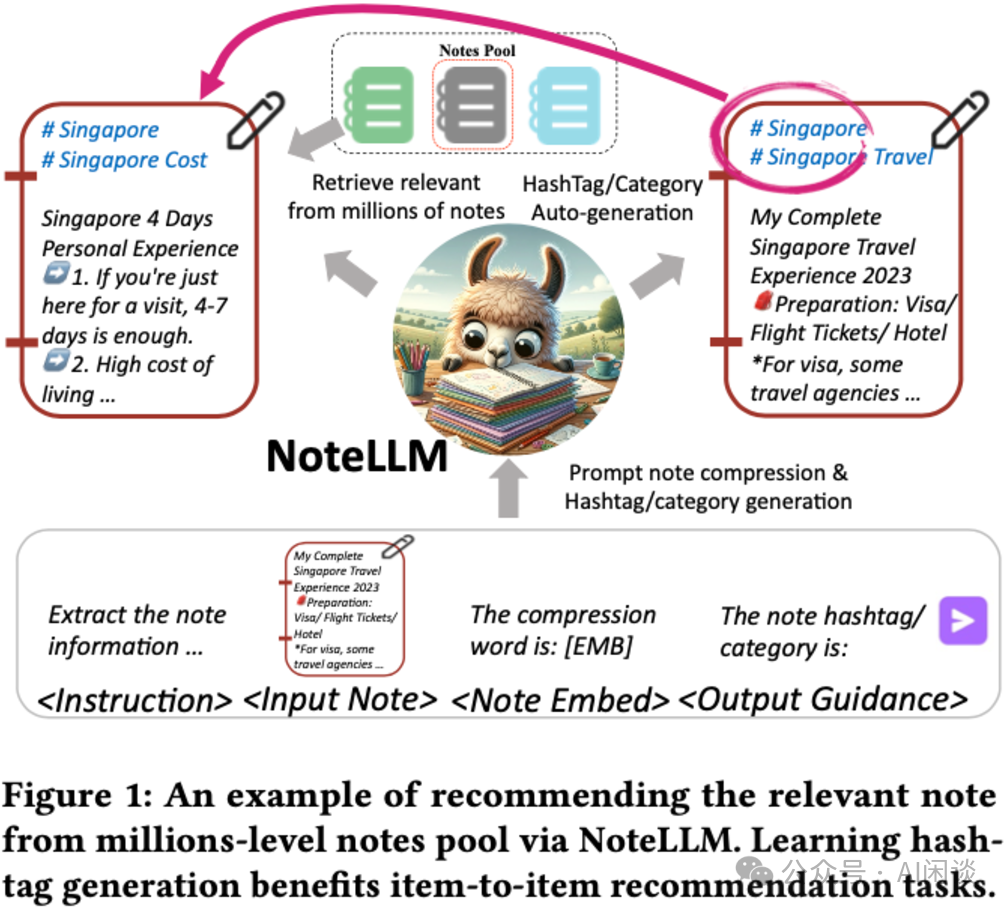
本文中,作者提出 NoteLLM,该框架利用 LLM 解决 Item-to-Item(I2I)Note 推荐问题。具体而言,作者采用 Note 压缩提示将 Note 压缩为单一特殊 Token,并通过对比学习方法进一步学习潜在相关 Note 的 Embedding。此外,可以通过指令微调,运用 NoteLLM 自动总结 Note 并生成 Hashtag/Category。大量真实场景实验表明,与 Online 基线相比,提出的方法有效提升了小红书推荐系统的性能。
PS:其实小红书中很多 Note 包含图片,也就需要多模态场景的推荐,本文中并未涉及图片信息,相关工作我们后续介绍。
三、引言
3.1 问题定义
文中作者主要关注两个任务:I2I Note 推荐任务和 Hashtag/Category 生成任务。
-
对于 I2I Note 推荐任务
-
给定一个目标 Note,从大规模 Note Pool 中推荐一个排序的 Note 列表。本文中作者主要聚焦在基于文本的 I2I 推荐,并且将 LLM 引入进来。
-
Note Pool 为 N={n1, n2, …, nm},其中 m 表示 Note 数量。每条 Note 包含:标题(title)、标签(Hashtag)、类别(Category)和内容(Content)。ni=(ti, tpi, ci, cti) 表示第 i 条 Note。该任务目标是从 N 中选出与该 Note 相似的前 k 条 Note。
-
对于 Hashtag/Category 生成任务
-
作为社交媒体上的标签机制,Hashtag 与 Category 简化了特定主题信息的识别过程,有助于用户发现相关内容。本任务指的是依据输入文本生成 Hashtag 和 Category。
-
在 Hashtag 生成任务中,LLM 根据 ti 和 cti 生成 Hashtag tpi。
-
在 Category 生成任务中,LLM 根据 ti,tpi 和 cti 生成 Category ci。
3.2 对比学习
以经典的 SimCLR([2002.05709] A Simple Framework for Contrastive Learning of Visual Representations [2])中的对比学习为例,其核心思想是同一图片进行不同的数据增强后应具备一定的不变性。如下图所示,将不同的图片(N 个)输入 CNN 模型提取 Representation,每幅图片都会经过两个不同的预处理,生成两个不同的 Representation。对比损失的目标就是:使同一幅图生成的两个 Representation 尽可能相似,而与其他图生成的 Representation 应该尽可能不相似。

对于一个 Batch 的 N 个样本,总共可以生成 2N 个 Representation。这里并没有显式抽取负样本,相反地,给定一个正样本对(i, j),将 Batch 中剩下的 2(N-1) 个 Representation 视为负样本。对于正对 i 和 j 的对比损失函数可以表示如下,其中 sim(u, b) 表示 u 和 v 的相似性:
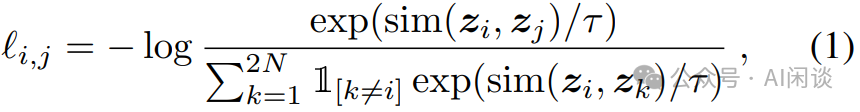
其中,1[k ≠ i] 是一个指示函数,若 k ≠ i 则为1,否则为 0,τ 是温度参数。最终的损失在 Batch 的所有正样本对(包括(i, j) 和 (j, i))上进行计算。分子可以理解为正样本对的相似性,分母可以理解为负样本对的相似性,通过这种方式,试图学习如何使正样本对的相似度更大,负样本对的相似度更小。
四、方案
4.1 NoteLLM 框架
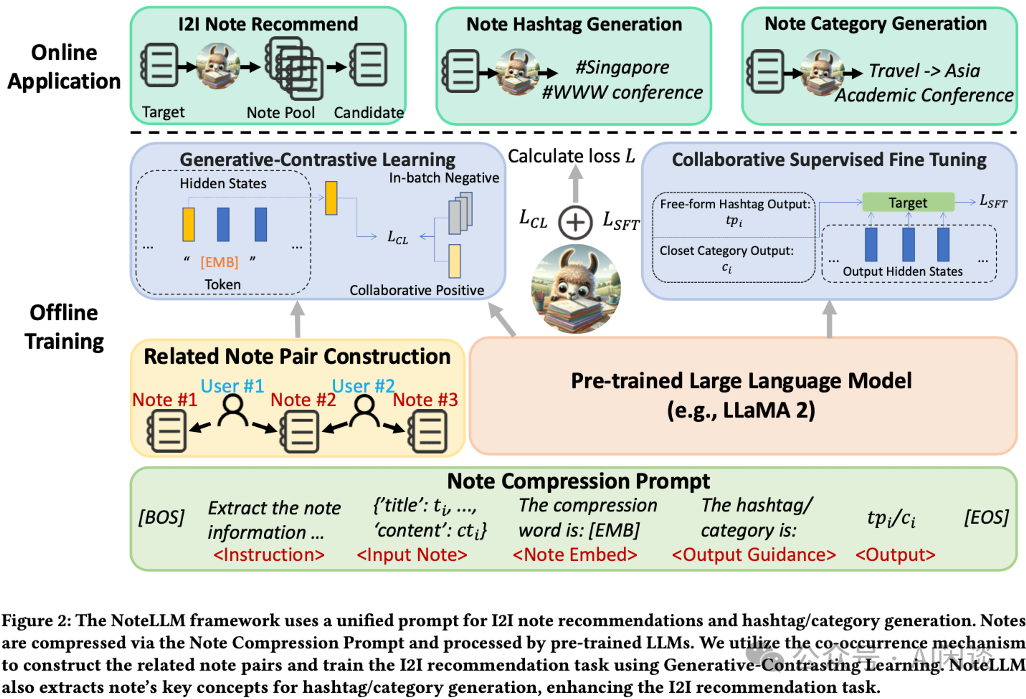
NoteLLM 框架由三个关键组件构成
-
Note 压缩提示构建(Note Compression Prompt Construction):通过构建统一的 Note 压缩 Prompt,将 Note 内容压缩成一个特殊 Token,同时生成 Hashtag/Category。
-
生成-对比学习(Generative-Contrastive Learning, GCL):GCL 利用用户行为数据中的共现机制构建相关 Note 对,通过对比学习训练 LLM 识别相关 Note,从而获取协同信号。
-
协同监督微调(Collaborative Supervised Fine-Tuning, CSFT):CSFT 利用 Note 的语义内容和压缩 Token 中的协同信号生成 Hashtag/Category。通过这种方式,NoteLLM 能够在保持生成能力的同时,利用 Note 的语义和协同信息生成 Hashtag 和 Category,增强推荐 Embedding。
4.2 Note 压缩提示构建
作者采用同样的 Note Compression Prompt 来促进 I2I 推荐和生成任务。为了利用 LLM 的 I2I 推荐生成能力,目标是将 Note 内容压缩为一个单一的特殊 Token,这一 Token 随后通过 GCL 获取协同知识。接着,利用这一知识,通过 CSFT 生成 Hashtag/Category。
具体而言,作者使用以下 Prompt 模板,用于通用 Note 压缩及 Hashtag/Category 生成:

在此模板中,[BOS]、[EMB] 及 [EOS] 为特殊 Token 符号,而 ,, 和 都是占位符,需替换为具体内容。
Hashtag 生成的具体内容定义如下:

Category 生成的具体内容定义如下:

鉴于用户生成 Hashtag 数量的不可预测性,作者随机选取一部分原始 Hashtag 作为 Hashtag 生成的输出目标,以最大限度地减少对 LLM 可能产生的误导。随机选择的 Hashtag 数量,记作 ,被整合进 和 两部分中。一旦 Prompt 构建完成,它们将经过 Tokenizer 并输入至 LLM。随后,LLM 提炼协作信号与关键语义信息至压缩 Token 中,并依据 Note 的核心思想生成 Hashtag/Category。
4.3 生成式对比学习(GCL)
预训练的 LLM 通常通过指令微调或 RlHF 来学习新知识。这些方法主要侧重于利用语义信息来增加 LLM 的有效性和安全性。然而,推荐任务中仅依赖 LLM 的语义信息是不够的。协作信号在 LLM 中是缺失的,而这些信号在识别用户特别感兴趣的 Note 方面起着至关重要的作用。因此,作者提出了 GCL 来增强 LLM 捕获协同信号的能力。与从特定答案或奖励模型不同,GCL 采用对比学习(Contrastive Learning),从整体视角学习 Note 之间的关系临近性。
作者采用共现(co-occurrence)机制基于用户行为构建相关 Note 对。该机制基于一个假设:经常一起阅读的 Note 可能是相关的。因此,作者收集了一周内的用户行为数据以计算共现次数。具体来说,作者统计了用户查看 Note nA 后点击 Note nB 的次数。同时,为了区分不同用户共现的贡献,为不同的点击分配了不同的权重。具体的计算方式如下所示:
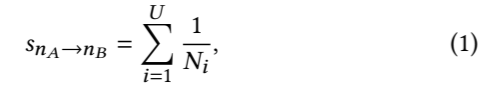
其中 SnA -> nB 表示从 Note nA 到 Note nB 的共现得分,U 是用户数,Ni 表示第 i 个用户点击的 Note 集合的数量。归一化可以防止活跃用户可能的无差别点击而导致的误导。在计算完所有的 Note 对共现得分后,就可以构成共现得分集合 Sni:
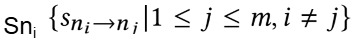
随后,从集合 Sni 中过滤掉得分超过上限 𝑢 和低于下限 𝑙 的异常 Note。最后,从过滤后的集合中选出共现得分最高的 t 条 Note,作为与 Note ni 的相关 Note。
构建完相关对之后,即可以用于训练 NoteLLM。具体来说,利用上述介绍的 Prompt 来压缩 Note 并生成一个虚拟词([EMB]),该 [EMB] 的最后一个 Hidden State 包含给定 Note 的语义信息和协同信号,可以表示该 Note。然后使用一个线性层将其转换到 Note Embedding 空间,维度为 d。之后就可以使用对比损失进行训练,如下图所示:
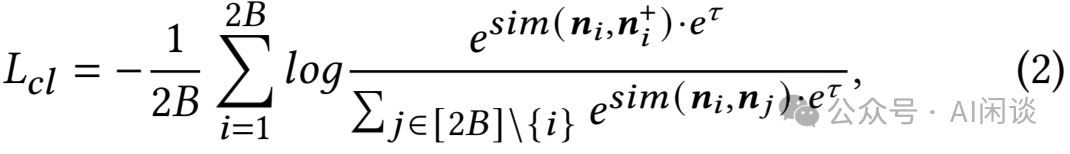
4.4 协同监督微调(CSFT)
作者指出,生成 Hashtag/Category 的任务与生成 Note Embedding 的任务具有相似性,两者均旨在概括 Note 内容:
-
从文本生成的角度看,生成 Hashtag/Category 的任务旨在提取 Note 的关键信息。
-
从协同过滤的角度看,生成 Note Embedding 的任务则是将 Note 压缩为虚拟词,用于 I2I 推荐。
为此,NoteLLM 模型联合建模 GCL 和 CSFT 任务,以提升 Embedding 质量。作者将这两项任务整合到单一 Prompt 中,为两者提供额外信息,并简化训练流程。具体而言,采用 CSFT 方法,利用 Note 的语义内容和压缩 Token 中的协同信号来生成 Hashtag/Category。为了提高训练效率并防止遗忘问题,作者从每 Batch 中选取 r 条 Note 执行 Hashtag 生成任务,其余 Note 则分配到 Category 生成任务。作者按照如下方式计算 CSFT 损失:
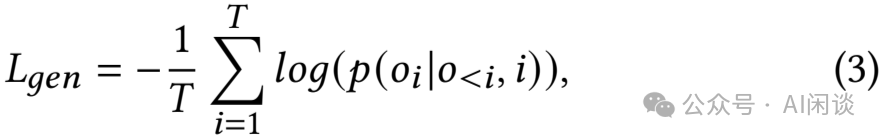
其中,T 表示输出的长度,oi 表示输出序列 o 中的 第 i 个 Token,ί 表示输入序列。
最后,定义 NoteLLM 的损失如下,以结合 GCL 和 CSFT,其中 α 表示超参数。

五、实验
5.1 数据集和实验设置
如下图 Table 1 所示为训练集和测试集的数据分布,其训练集从小红书一周的数据处理而来,随后选择接下来的一个月的随机抽取 Note 作为测试集,并排除训练集中已经存在的 Note:
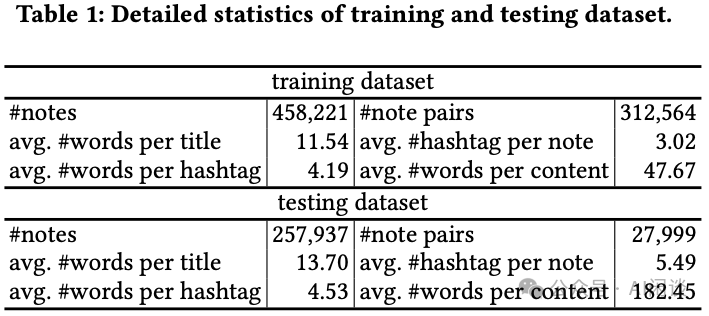
实验中,作者采用 LLaMA 2 模型。构建相关 Note 对时,共现分数的上限 𝑢 定为 30,下限 𝑙 定为 0.01,并将 𝑡 设定为 10。Note Embedding 维度 d 为 128,Batch Size B 为 64(在 8 x 80G A100 上采用 DDP 训练,每个 GPU 的 Batch Size 为 8),每个 Batch 包含 128 条 Note。由于 Context Length 的限制,将标题 Title 限定为不超过 20 Token,内容 Content 不超过 80 Token。温度参数 𝜏 初始化为 3,公式 4 中将 𝛼 设定为 0.01。对于标签生成任务,比例 𝑟 设定为 40%。
评估中,选择每对 Note 中第一条作为目标 Note,另一条作为 Ground Truth。
对于 I2I 推荐任务,根据目标 Note 对测试池中所有 Note(不包含目标 Note)进行排序,并使用 Recall@100、Recall@1k、Recall@10k 和 Recall@100k 来验证 I2I Note 推荐模型的有效性。
对于封闭域 Category 生成任务,采用 Acc 和 Ill(Illusory proportion,幻觉比例)作为评估指标。
对于开放式 Hashtag 生成任务,采用 BLEU4、ROUGE1、ROUGE2 和 ROUGEL 来评估模型性能。
5.2 离线评估
这里作者展示了 NoteLLM 在 I2I Note 推荐中的有效性。作者将 NoteLLM 与以下基于文本的 I2I 推荐方法进行了比较:
-
zero-shot:利用 LLM 生成 Embedding,无需任何 Prompt,然后进行 zero-shot 检索。
-
PromptEOL zero-shot([2307.16645] Scaling Sentence Embeddings with Large Language Models [3]):在 Prompt 后添加显式的 “in one world”,以约束 LLM 在下一个 Token 中预测语义信息。类似:This sentence: “ [text] ” means in one word: “。
-
SentenceBERT 采用 BERT 基于对比学习来学习 Note 相似性,作为 Online 基线。
-
PromptEOL + CSE([2307.16645] Scaling Sentence Embeddings with Large Language Models [3]):PromptEOL zero-shot,并利用对比学习更新 LLM。
-
RepLLaMA,一种基于 LLM 的双编码器密集 Retriever,无需任何提示。
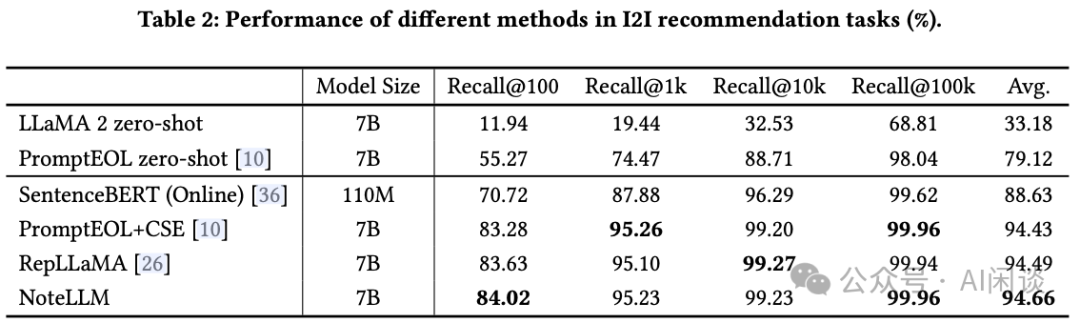
如下图 Table 2 结果所示,可以得出如下结论:
-
zero-shot 仍无法超越微调方法的性能。
-
基于 LLaMA 2 和 SentenceBERT 的比较揭示了 LLaMA 2 的显著优势。
-
具有特定 Prompt 的 PromptEOL+CSE 的性能与无 Prompt 的 RepLLaMA 相当,表明 Prompt 提升了 zero-shot 检索,但在微调后其效果减弱。
-
最后,NoteLLM 优于其他基于 LLM 的方法,主要归功于 CSFT 将摘要能力有效转移到 Note Embedding 中,从而高效提炼关键点以改进 Note Embedding。
5.3 不同曝光 Note 的影响
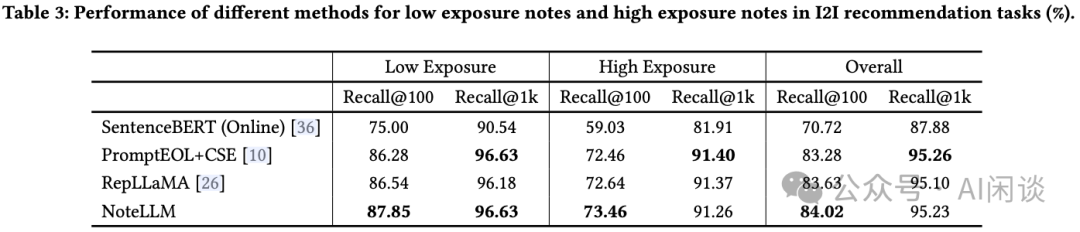
作者还展示了 NoteLLM 在处理不同曝光度 Note 方面的效能。根据曝光度将真实 Note 划分为两个类别:
-
低曝光度 Note,曝光量低于 1500 的 Note。这类 Note 占所有测试 Note 的 30%,但其累计曝光量仅占总量的 0.5%。
-
高曝光度 Note,曝光量超过 75,000 的 Note。这类 Note 仅占所有测试 Note 的 10%,但其总曝光量却高达 75%。
如下图 Table 3 的实验结果,可以看出,NoteLLM 大部分情况下优于其他方法,表明 CSFT 模块的引入为所有 Note 带来了持续的益处。值得注意的是,NoteLLM 在高曝光度 Note 的 Recall@1k 上表现不佳。性能下降的原因可归咎于忽视了流行度偏差([2208.03298] Quantifying and Mitigating Popularity Bias in Conversational Recommender Systems [4])。这些特性增强了模型基于 Note 内容进行召回的能力,使其特别适合检索冷启动 Note。
5.4 消融研究
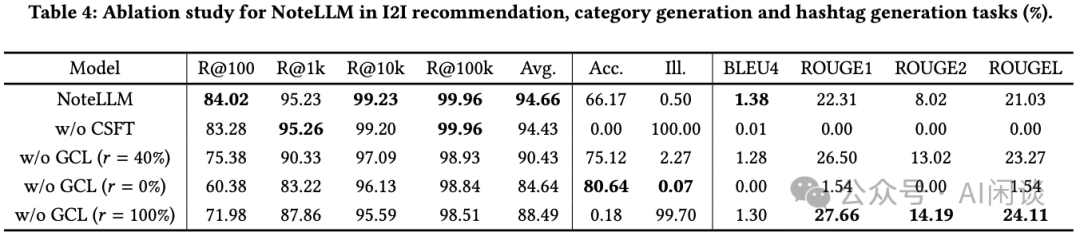
本实验包含 NoteLLM 与以下变体:
-
无 CSFT(w/o CSFT):仅采用 GCL 模块的方法。
-
无 GCL(𝑟 = 40%):仅采用 CSFT 模块指导 LLM 总结 Hashtag 和 Category。
-
无 GCL(𝑟 = 0%):仅包含 Category 总结任务。
-
无 GCL(𝑟 = 100%):仅指导 LLM 总结 Hashtag。
如下图 Table 4 所示,作者还通过消融实验来验证本文中方案的有效性。可以看出:
-
无 CSFT 的消融版本表现不如 NoteLLM,并且完全丧失了生成 Hashtag 和 Category 的能力。
-
无 GCL 模块的消融版本在 I2I 推荐任务中优于 PromptEOL zero-shot。这表明 Hashtag 和 Category 生成任务能够增强 I2I 推荐任务。
-
无 GCL(𝑟 = 40%)的消融版本在 I2I 推荐任务中表现优于无 GCL(𝑟 = 0%)和无 GCL(𝑟 = 100%)的版本,表明任务多样性对 CSFT 至关重要。
-
Hashtag 和 Category 生成任务之间存在明显的跷跷板现象。
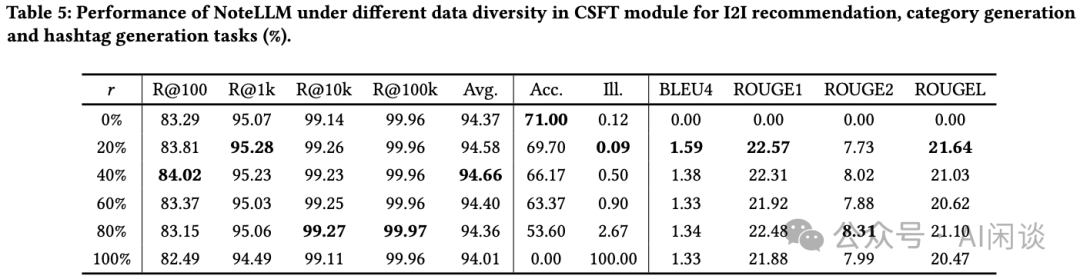
5.5 CSFT 模块中数据多样性的影响
如下图 Table 5 展示了在不同数据类型比例下,模型针对各项任务的性能表现。
-
对于 I2I 推荐任务,随着比例 𝑟 的增加,模型性能提升。然而,当 𝑟 持续增大,指令调优数据愈发偏向于 Hashtag 生成任务时,性能开始下滑。
-
对于 Category 生成任务,随着数据向 Hashtag 生成任务倾斜,其性能随之恶化。但从 𝑟 超过 20% 后,Hashtag 生成任务的性能变化不大,这可能是因为 Category 生成任务属于封闭式任务,需严格匹配,而 Hashtag 生成任务是开放式生成任务,具有更高的灵活性。
5.6 CSFT 模块的影响程度
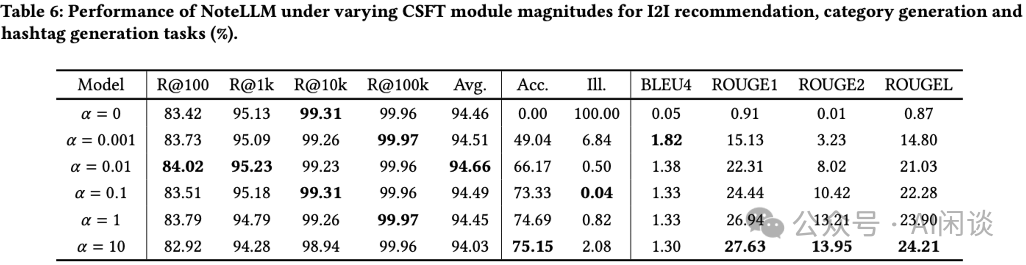
作者还探讨了 CSFT 模块对任务性能的影响程度。如下图 Table 6 所示,𝛼 值的轻微提升能同时增强推荐任务和生成任务的表现。然而,随着 𝛼 值的持续增加,推荐任务的性能开始下降,而生成任务的性能则持续提升。这一现象揭示了生成任务与 I2I 推荐任务之间的权衡关系,强调了采取平衡策略的必要性。
5.7 案例研究
如下图所示,作者展示了 Note 推荐任务的具体案例:
-
在 (a) 中,Query Note 建议避免购买哪些夏季衣物,而所有基线模型均推荐夏季服装。NoteLLM 能够精准推荐与简约生活相关的 Note。
-
在 (b) 中,基线模型将 Note 中的 “rabbit” 误解为活体兔子,而非 “Keep stranger away” 中的玩具兔子。

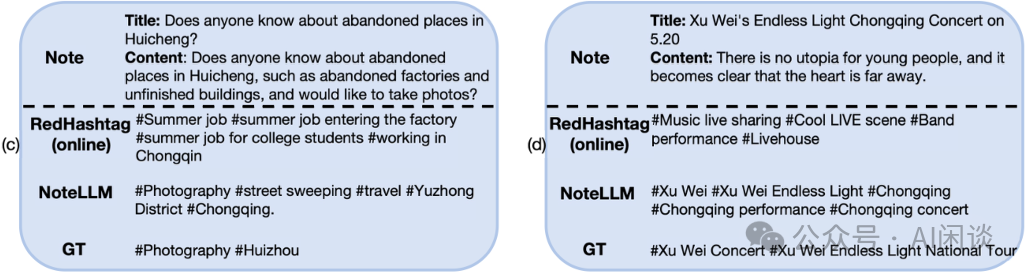
如下图所示,作者展示了 Note 生成类任务的具体案例,© 与 (d) 展示了 Hashtag 生成任务的案例,凸显了 NoteLLM 的优势。RedHashtag 是一种针对小红书的 Online Hashtag 生成方法,基于固定 Hashtag 集合进行分类。
-
在 © 中,NoteLLM 未受 “factories” 这一语义信息误导,正确识别出笔记内容主要聚焦于拍照。
-
在 (d) 中,NoteLLM 能够生成更为具体且长尾的 Hashtag,而非通用 Hashtag。然而,NoteLLM 的方法仍存在幻觉问题。
5.8 在线实验
作者在小红书平台上进行了为期一周的 Online I2I 推荐实验。与之前采用 SentenceBERT 的 Online 方法相比,NoteLLM 将点击率提升了 16.20%。此外,增强的召回性能使得评论数量增加 1.10%,每周平均发布者数量(WAP)提升 0.41%。
这些结果表明,将 LLM 引入 I2I Note 推荐任务中,能够有效提升推荐性能及用户体验。同时,作者观察到新 Note 在一天内的评论数量显著增加 3.58%,这说明 LLM 的泛化能力对冷启动 Note 尤为有利。目前,NoteLLM 已成功部署于小红书的 I2I Note 推荐任务中。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1101
1101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









