







环境准备
显卡: NVIDIA GeForce RTX 4090/48G
内存:32GB+
操作系统:Ubuntu22.04
Python:3.12
部署:
下载源码:
cd /data/
git clone https://github.com/QwenLM/Qwen2.5-Omni.git
cd Qwen2.5-Omni
下载模型文件:
modelscope download --model Qwen/Qwen2.5-Omni-7B --local_dir ./Qwen2.5-Omni-7B创建虚拟环境:
pip3 install virtualenv
cd /data/Qwen2.5-Omni
python3.12 -m venv qwen-omni
激活虚拟环境:
source qwen-omni/bin/activate下载安装依赖:
pip install accelerate -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install qwen-omni-utils[decord] -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install git+https://github.com/huggingface/transformers@3a1ead0aabed473eafe527915eea8c197d424356 #必须从源码下载安装
pip install -r requirements_web_demo.txt
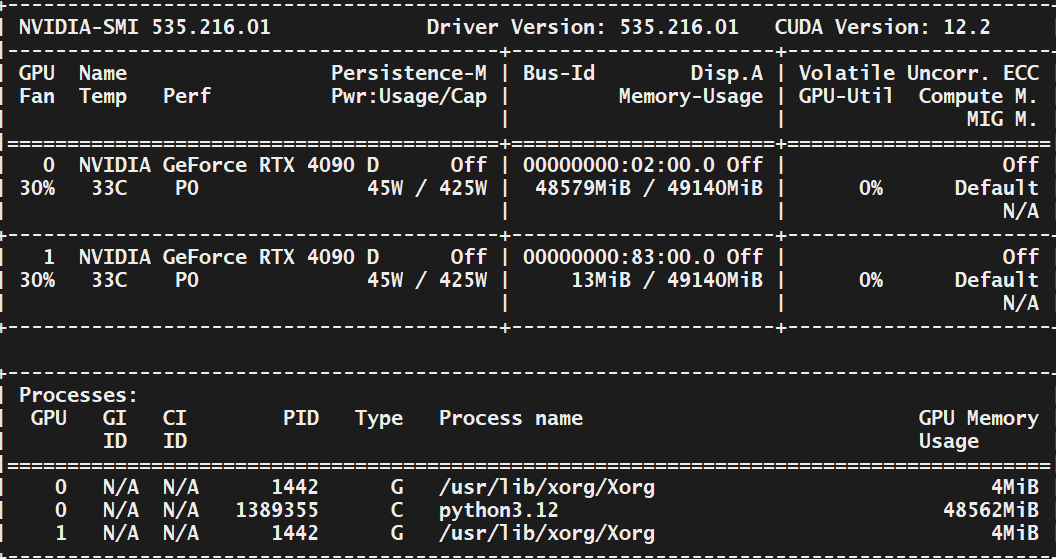
使用须知:两张卡会报错
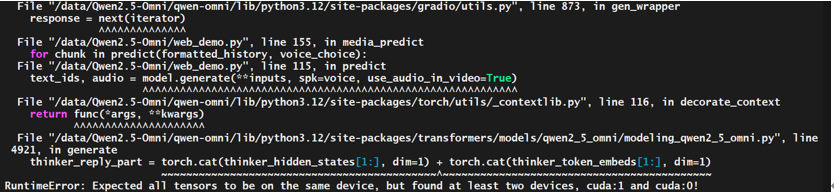
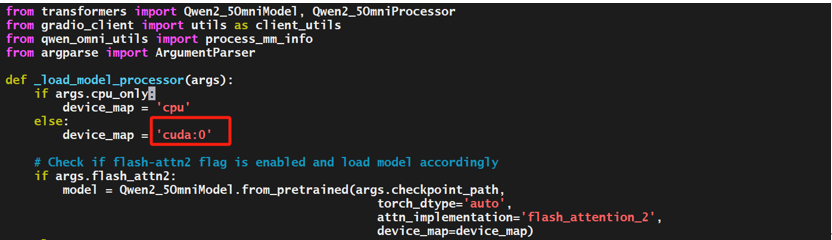
解决:vim web_demo.py
auto 改为:cuda:0
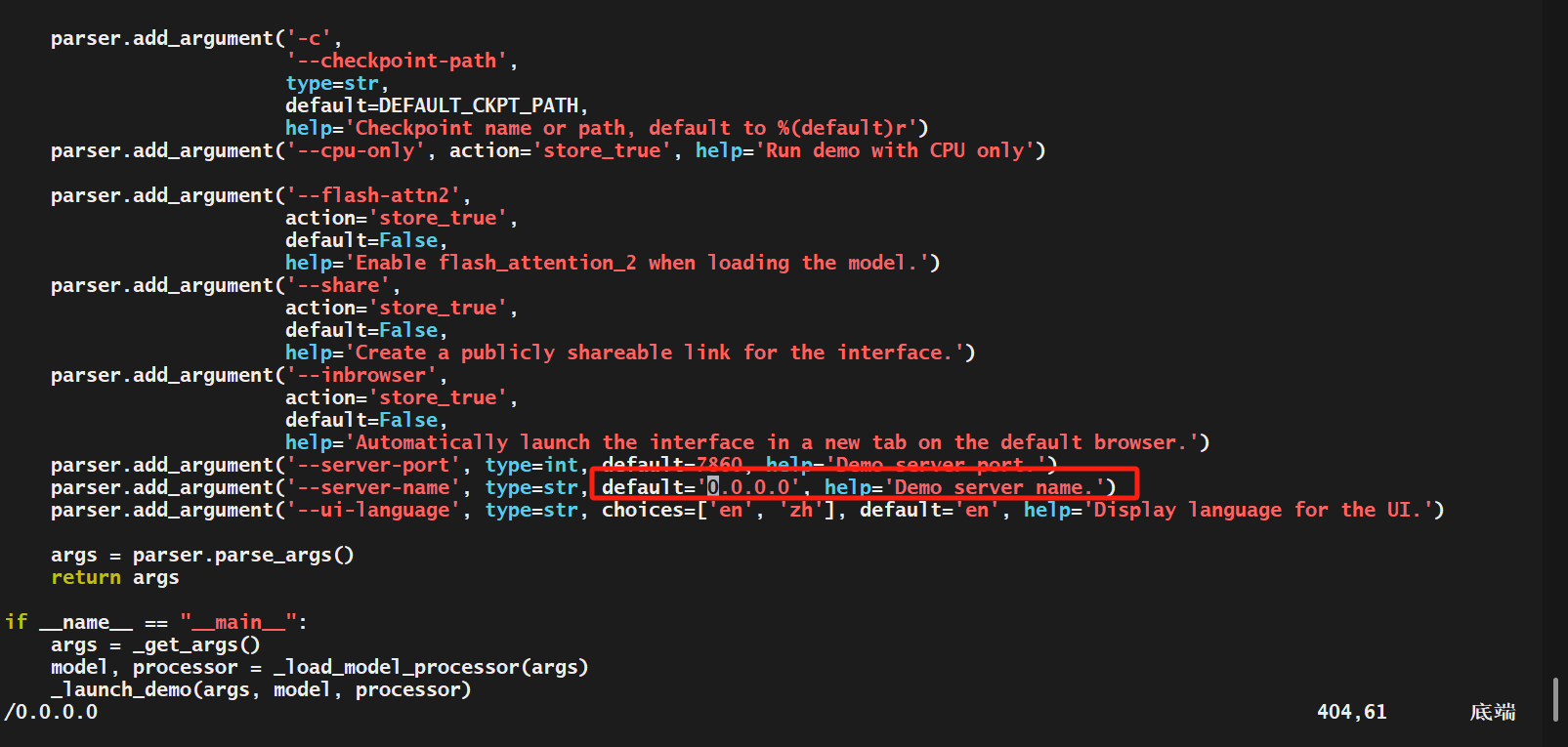
将监听地址改为0.0.0.0,端口也可以自行更改
启动:
python3.12 web_demo.py --checkpoint /data/Qwen2.5-Omni-7B/


















 1563
1563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









