







文章目录
这篇文章有点长,比较基础,笼统的串讲了许多基础知识。
1.进程的概念
进程是操作系统进行资源调度和分配的独立单位。线程是操作系统进行任务调度和执行的基本单位。
1.1程序和进程的区别
–程序是经过翻译环境生成的可执行文件,静态的,储存在磁盘,如硬盘(HDD),固态硬盘(SSD)等非易失性存储介质中。
–进程是在运行环境中运行的程序,动态的,数据保存在内存中。
2.并发与并行
2.1 并发
在某个t1~t2时间段内,多个运行程序在一个单核CPU上运行开始至结束,但是在该时间段的某个t0时刻,只有一个运行程序占用着这个CPU资源,其他运行程序处于等待状态。
并发不是真正意义上的同时运行,在一个单核CPU等待队列(run_queue)中,操作系统通过调度算法为CPU分配每个程序的运行时间,称为时间片,t1~t2时间段被分配为若干个时间片,由于CPU上下文切换非常快,我们肉眼难以观察,所以看起来跟同时运行没什么区别。
2.2 并行
并行才是真正在同一时刻有多个程序运行,但是在这一时刻,每个程序占用着一个CPU或者一个CPU核心资源
(多核CPU,四核、六核、八核······,说的就是CPU核心数)。
3.PCB(process control block)
3.1 定义
PCB不是我们常说的印刷电路板,而是进程控制块,在linux中是一个task_struct结构体,用于描述关于进程的相关信息。
3.2 task_struct结构体
3.2.1 位置
/user/src/linux-headers-3.16.0-30/include/linux/sched.h头文件中可以查看struct task_struct结构体定义。
3.2.2 内容
3.2.2.1 进程id(PID)
系统中每个进程有唯一的id,在C语言中用pit_t类型表示,进程id都是用非负整数表示。PPID表示某个进程的父进程,PGID表示进程组。
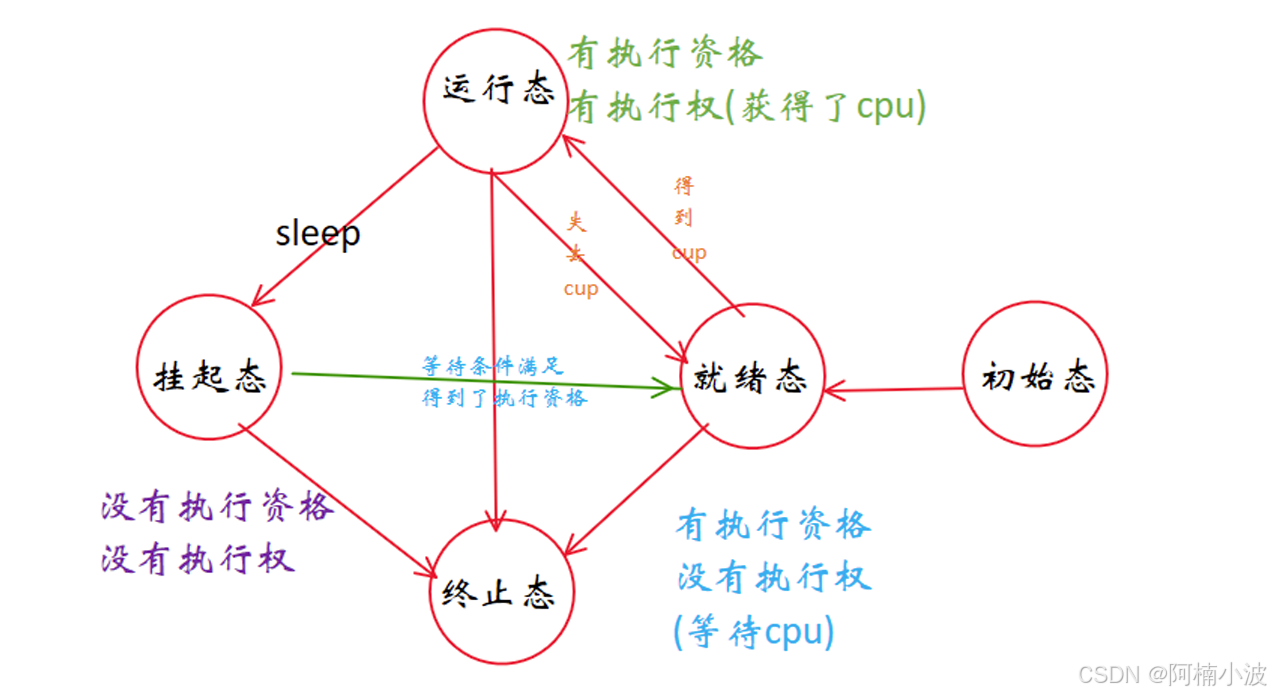
3.2.2.2 进程的状态信息(STAT)
运行状态:R-running,等待/挂起/阻塞状态/浅度睡眠状态:S-sleeping ,深度睡眠状态/不可中断状态,暂停状态:T-stopped,跟踪暂停状态:t-tracing stop,死亡状态:X-dead,僵尸状态:Z-zombie。
进程状态也算一种进程的分类信息!!!
3.2.2.3 进程切换时需要保存和恢复一些寄存器信息
这就是上面提到的在并发中切换时的上下文,并发进行的时候子在进程被抢占资源或者时间片到的时候当再次运行到该进程,CPU是如何知道该进程运行到哪一步了,就是通过记录一些寄存器的值。
程序计数器:指示下一条要执行的指令在内存中的地址。
通用寄存器组:CPU提供临时存储数据的空间,提高运算速度。
······
跟进程运行状态描述有关的信息会被存储到task_struct中。
3.2.2.4 存储一些其他重要信息
描述虚拟地址空间的信息
描述控制终端的信息
当前工作目录(Cueernt Working Directory)
umask掩码
文件描述符,包含很多指向file结构体的指针
和信号相关的信息
进程可以适用的资源上线(Resource Limit),ulimit -a
······
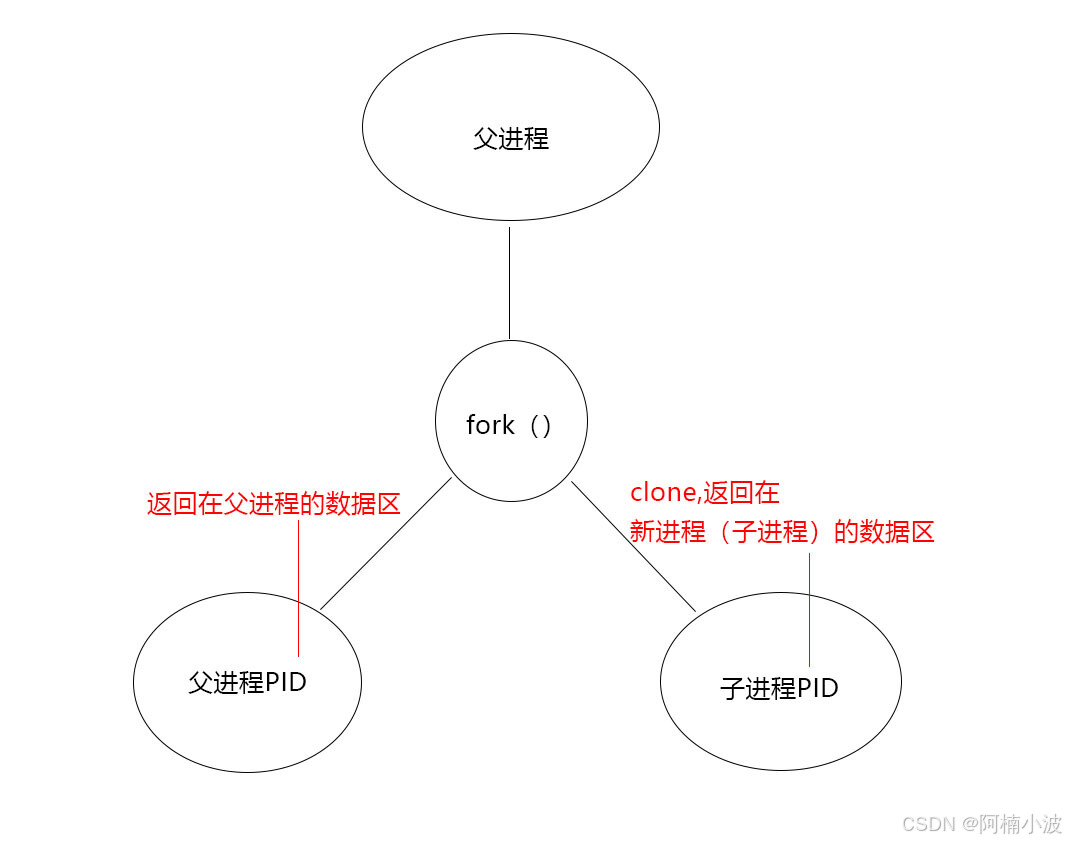
4.fork函数
fork函数是一个在进程运行过程中创建进程的函数,被创建的进程叫做子进程,创建进程的进程叫做父进程,子进程复制了父进程的代码和数据还有部分PCB数据,进程=PCB+代码+数据,这就相当于子进程和父进程能实现同样的功能,根据参数的不同也可以实现不同的功能。
4.1 函数信息
#include <sys/types.h> //包含了pid_t的类型定义
#include <unistd.h>
pid_t fork(void);
=0:当前进程为子进程
>0:当前进程为父进程
‐1:出错
4.2 子进程复制内容

我不懂进程的时候,刚开始接触fork函数有点懵*,一个运行程序中,一个函数执行一次返回值只能有一个,但是却两个if判断条件都执行了,但是懂了一些进程之后迎刃而解。
4.3 fork创建子进程实例
4.3.1 代码
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
#define PRINT(str,x) printf("%s ,%s: %10d, %s: %p\n", str,#x,x,#x,&x) //使用宏定义,简化printf统一格式的输出
int b; //b全局变量
int main()
{
pid_t pid;
int a; //a局部变量
pid = fork();
if(pid<0)
{
perror("fork");
exit(1);
}
if(pid>0)
{
a = 1;
PRINT("f",a);
PRINT("f",b);
//printf("f, a: %10d, &a: %p\n", a, &a);
//printf("f, b: %10d, &b: %p\n", b, &b);
}
else if(pid==0)
{
b = 1;
PRINT("c",a);
PRINT("c",b);
}
return 0;
}
4.3.2 终端输出结果

最后输出的结果,先看打印出来的值,因为b是全局变量,在堆区会被初始化为0,所以在父进程中会输出0,在子进程初始化后输出1;a是局部变量,在栈区不会被初始化,所以在子进程中显示随机值,在父进程中初始化输出1,不要看打印出来的父进程都在前,父进程就一定在子进程之前运行,虽说叫父子, 那也有可能儿子比爸爸牛X,实际上两者没有先后关系,要看两者谁先抢到CPU资源。
4.4 虚拟地址空间
上面代码后面的地址搞得人有点懵X, 同一个地址装的变量, 值竟然不相同? 这就是内存管理一种方式的牛X之处, 虚拟地址空间,同一变量对应的地址一样,这是因为子进程复制了父进程的堆栈,但是地址映射到的物理内存是分隔的。虚拟地址空间的出现······
不装了, 懂得不多, 推荐两篇文章
虚拟地址空间
虚拟地址空间【详解】 虚拟地址空间是什么 | 为什么要有虚拟地址空间
每个进程都会有4GB的虚拟地址空间(32位), 64位的不清楚(2^64得多大~),每个进程给4GB的虚拟地址空间,这给用户进程一个拥有大内存的假象,不至于在进行数据操作的时候很拘束,一直向内核申请数据,浪费时间和资源。
虚拟地址空间对应的地址不是真正的物理内存,是根据使用多少在程序运行的时候映射到物理内存的。
4.5 父子进程数据共享
fork函数创建子进程的时候,只是复制了数据区,代码区仍然是共享的。这里通过写时拷贝机制进行拷贝的。当有数据写入的时候不管父进程还是子进程谁先写入,谁就进行复制,在fork函数返回值的时候就已经发生了数据写入,所以在fork函数返回值之后就发生了数据区复制,代码区在未修改之前也是共享的,修改也会触发写时拷贝机制。这里推荐一篇文章,对fork写的很好
[入门篇]Linux操作系统fork子进程的创建以及进程的状态 超超超详解!!!我不允许有人错过!!!
5. getpid,getppid函数
pid_t getpid(void); //得到该进程的PID
pid_t getppid(void); //得到父进程的PID
5.1 代码实例
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
pid_t pid;
pid = fork();
if(pid==-1)
{
perror("fork");
exit(1);
}
printf("-------------\n");
if(pid==0)
{
printf("the child process, PID: %d, PPID: %d\n", getpid(), getppid 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









