






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
介绍
本项目旨在通过深度Q网络(DQN)算法和PyTorch框架,实现无人机通信网络中的子带分配问题。在无人机辅助的通信系统中,合理分配频谱资源对于提高通信效率和覆盖范围至关重要。通过集中式DQN算法,可以优化无人机与地面用户的频谱分配策略,从而最大化网络的整体性能。
相关背景
在无人机通信网络中,频谱资源的分配是一个关键问题。传统的频谱分配方法往往难以适应动态的网络环境,而基于强化学习的DQN算法能够通过智能决策实现动态优化。PyTorch作为一种强大的深度学习框架,为DQN算法的实现提供了灵活的神经网络构建和高效的自动梯度计算。
实现方式
-
网络结构:使用PyTorch构建DQN网络,输入包括无人机的位置、用户分布和信道状态信息,输出为子带分配的决策。
-
集中式优化:通过集中式DQN算法,所有无人机共享全局信息,从而实现全局最优的频谱分配策略。
-
训练与优化:利用PyTorch的自动梯度计算和优化器,对DQN网络进行训练,以适应动态的网络环境。
应用场景
本项目适用于无人机辅助的无线通信网络,特别是需要动态频谱分配的场景。通过集中式DQN算法,可以有效提高频谱利用率,优化无人机与地面用户之间的通信。
基于DQN和PyTorch的无人机子带分配研究
一、无人机子带分配的定义与应用场景
无人机子带分配是指通过算法将有限的通信或任务资源(如频谱、功率、时隙等)动态分配给多架无人机,以优化系统整体性能。其核心目标包括最大化覆盖效率、最小化能耗与延迟,以及适应动态环境变化。
典型应用场景包括:
-
军事侦察与协同作战:在异构无人机群中,通过子带分配实现目标区域的高效覆盖与协同攻击。
-
城市物流配送:通过动态分配无人机配送路径与通信资源,优化中心选址与任务调度。
-
农业资源投放:将农药、种子等生产材料快速分配至分散农田区域.
二、DQN算法在资源分配中的技术优势
深度Q网络(DQN)结合了深度学习的特征提取能力与强化学习的动态决策能力,特别适用于无人机子带分配中的高维状态空间问题:
- 马尔可夫决策建模:将子带分配问题转化为状态(如无人机位置、信道质量)、动作(如功率分配、频段选择)、奖励(如吞吐量、能耗)的优化过程。
- 经验回放与目标网络:通过存储历史经验并随机采样,解决数据相关性导致的训练不稳定问题。
- 改进算法变体:
- Double DQN:减少Q值过高估计,提升收敛速度。
- Dueling DQN:分离状态价值与动作优势函数,提高策略评估精度。
案例对比:在电力传感网中,DDQN的收敛速度是DQN的2倍,丢包率降低90.16%;在V2V通信中,DQN优化传输功率后,总速率提升7.43%。
三、PyTorch框架在DQN实现中的核心优势
PyTorch因其动态计算图和灵活API设计,成为强化学习研究的首选框架:
- 动态网络构建:支持实时调整神经网络结构(如全连接层、卷积层),适应不同状态输入(如无人机坐标网格、信道矩阵)。
- GPU加速与并行训练:通过CUDA加速大规模状态空间计算,结合Ray库实现多智能体异步更新。
- 生态系统兼容性:与OpenAI Gym、DeepMind Lab等仿真平台无缝对接,简化环境交互设计。
开源实现:
- PyTorch-RL框架:提供DQN、Dueling DQN等算法的标准化实现。
- Cherry库:支持自定义策略梯度与经验回放机制,适用于多无人机协作场景。
四、无人机子带分配与DQN结合的研究现状
-
动态资源分配:
- 时隙与功率控制:在定向无人机网络中,DQN通过优化时隙复用和功率分配,使网络容量提升显著。
- 频谱分配:结合NOMA技术,DQN实现多用户信道资源动态分配,最大化频谱效率。
-
轨迹与资源联合优化:
- 在无人机辅助的URLLC系统中,DQN联合优化飞行轨迹与块长度分配,总速率提升14.8%。
- 山西大学团队利用C-DQN算法,联合优化功率分配与飞行路径,信息传输量较传统DQN提升20%。
-
多智能体协作:
- 独立DQN与DRQN结合,实现多无人机分布式决策,支持组内协调与组间合作。
- 使用共享特征提取层的多Q网络架构,减少参数冗余。
五、基于PyTorch的DQN实现方案(以子带分配为例)
-
状态空间设计:
- 输入特征:无人机位置、信道状态信息(CSI)、子带占用情况、任务队列长度。
- 数据预处理:归一化处理,通过卷积层提取空间特征。
-
动作空间定义:
- 离散动作:子带选择(如6个子带对应6个动作)、功率等级(高/中/低)。
- 混合动作:结合连续动作(如功率调整)需引入DDPG扩展。
-
奖励函数设计:
- 正向奖励:吞吐量提升、任务完成率、能效比。
- 负向惩罚:通信干扰、能源超限、任务超时。
-
网络架构示例:
import torch.nn as nn
class DQN(nn.Module):
def __init__(self, input_dim, output_dim):
super(DQN, self).__init__()
self.fc1 = nn.Linear(input_dim, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, output_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
- 训练流程:
- 经验回放:存储状态转移元组(s, a, r, s'),批量采样更新。
- 目标网络同步:定期复制主网络参数,稳定Q值估计。
六、挑战与未来方向
- 动作空间离散化限制:连续控制(如精确功率调整)需结合DDPG或SAC算法。
- 多目标优化冲突:引入加权奖励函数或分层强化学习,平衡吞吐量与能耗。
- 环境动态性:使用LSTM或注意力机制建模时变信道条件。
- 安全与鲁棒性:对抗样本攻击下,需增强网络容错能力。
📚2 运行结果
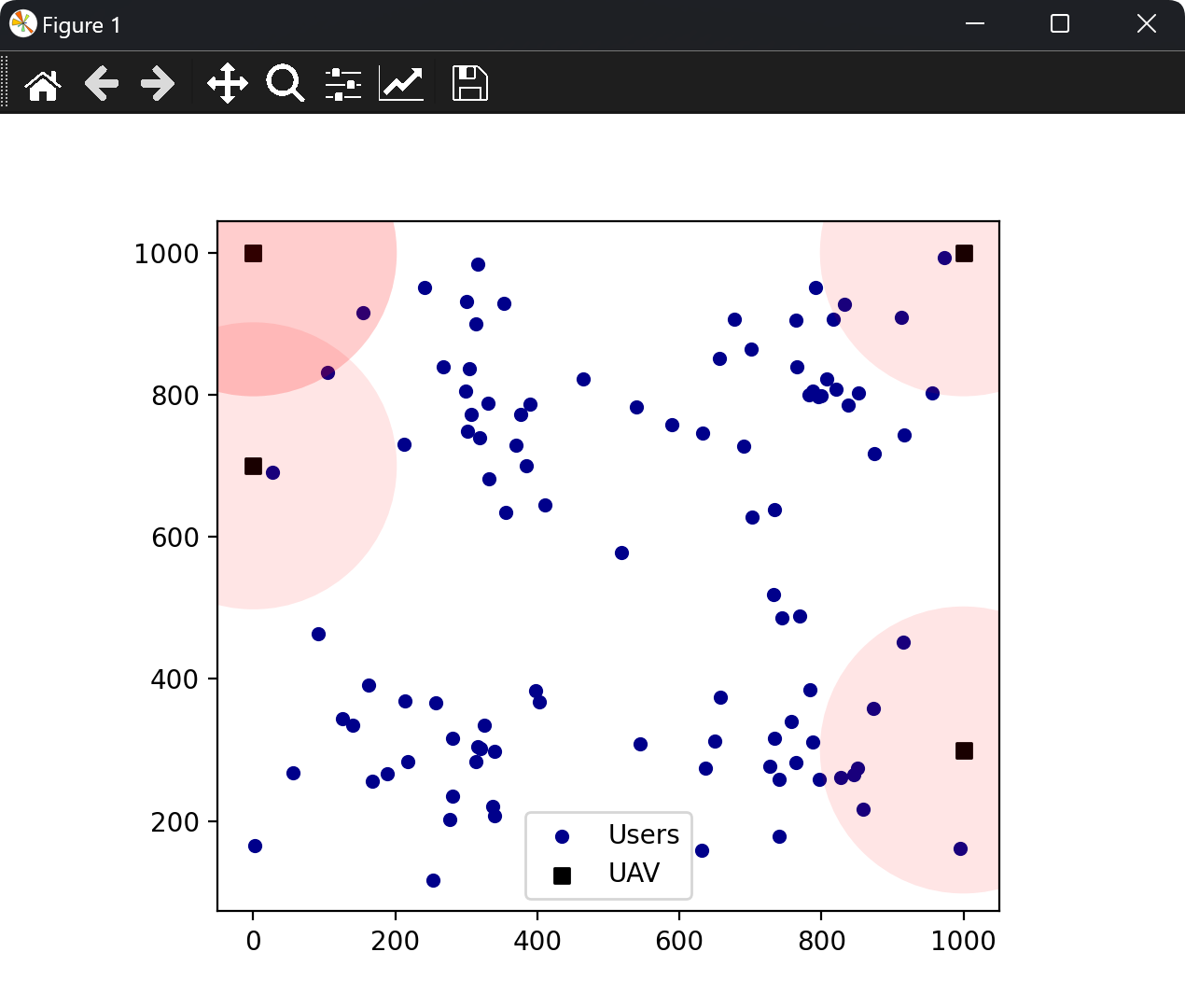
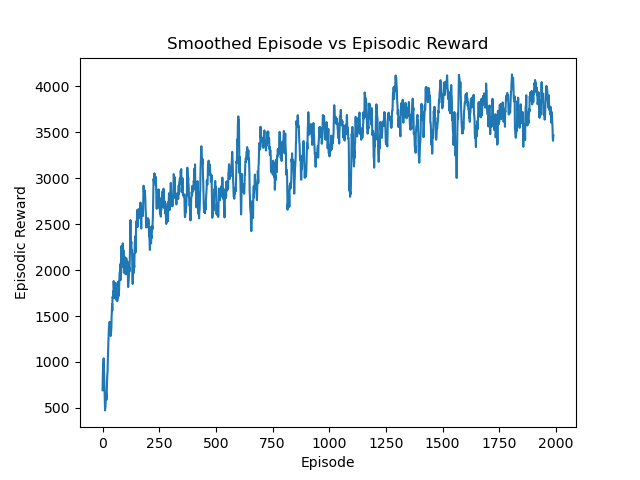
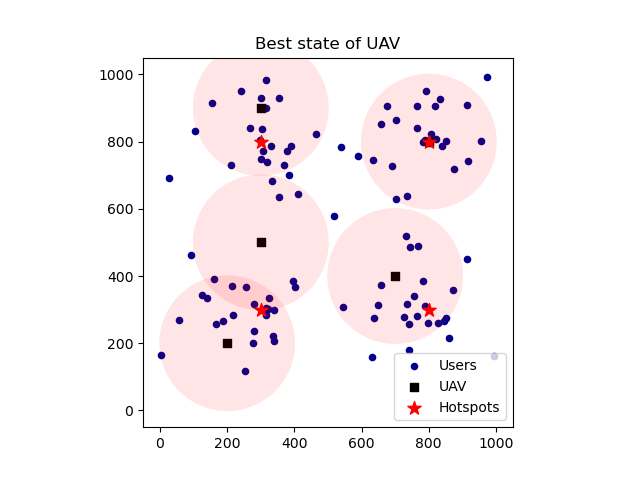
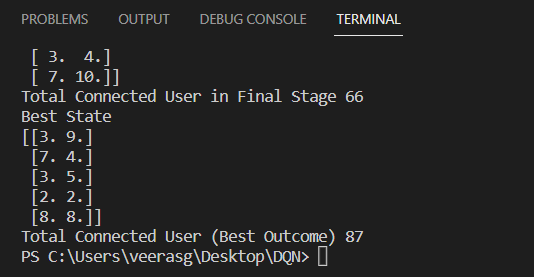
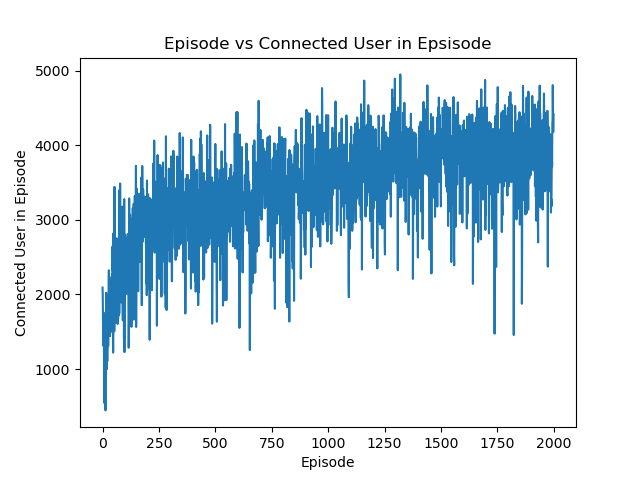
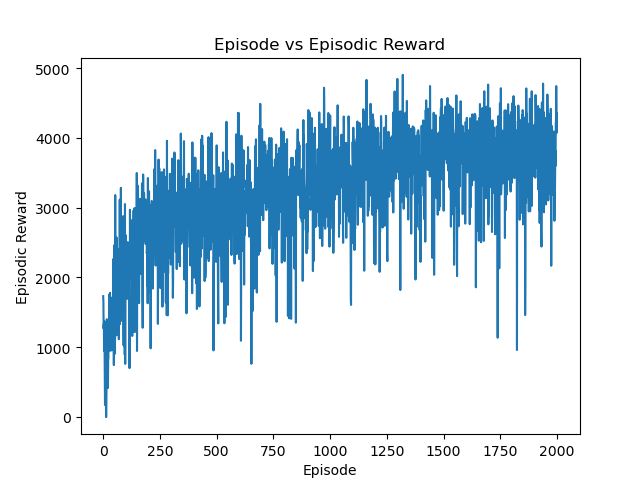
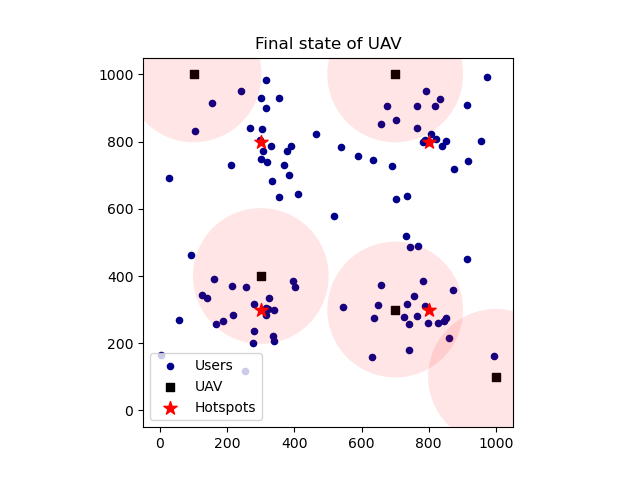
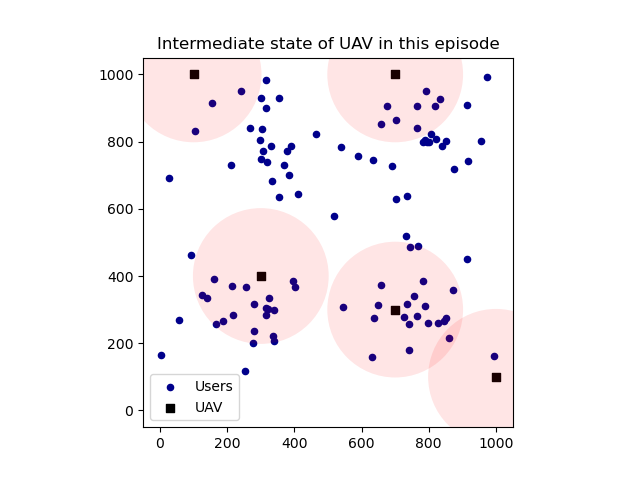
部分代码:
from ast import Num
import random
import numpy as np
import math
from matplotlib.gridspec import GridSpec
import matplotlib.pyplot as plt
from Centralized_UAV_environment import UAVenv
from misc import final_render
from collections import deque
import torch
from torch import Tensor, nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms as T
from torch.utils.data import DataLoader
from torch.utils.data.dataset import IterableDataset
import os
from scipy.io import savemat
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
PATH_DATASETS = os.environ.get("PATH_DATASETS", ".")
SEED = 1
torch.manual_seed(SEED)
np.random.seed(SEED)
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
# Define a neural network class for reinforcement learning
class NeuralNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(NeuralNetwork, self).__init__()
# Save state and action sizes as instance variables
self.state_size = state_size
self.action_size = action_size
# Define a sequential stack of linear and ReLU layers
self.linear_stack = nn.Sequential(
nn.Linear(self.state_size, 400),
nn.ReLU(),
nn.Linear(400, 400),
nn.ReLU(),
nn.Linear(400, 400),
nn.ReLU(),
nn.Linear(400, self.action_size)
)
# Move the model to the appropriate device (GPU or CPU)
self.linear_stack.to(device)
def forward(self, x):
# Move the input tensor to the appropriate device
x = x.to(device)
# Pass the input tensor through the network's layers
Q_values = self.linear_stack(x)
# Return the Q-values
return Q_values
# Define a Deep Q-Network class for reinforcement learning
class DQL:
def __init__(self, state_size=10, action_size=5**5, discount_factor=0.95, epsilon=0.1, alpha=0.25e-4):
# Initialize instance variables
self.state_size = state_size
self.action_size = action_size
self.replay_buffer = deque(maxlen=125000)
self.gamma = discount_factor
self.epsilon = epsilon
#self.epsilon_decay = epsilon_decay🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
[1]王冰晨,连晓峰,颜湘,等.基于深度Q网络和人工势场的移动机器人路径规划研究[J].计算机测量与控制, 2022, 30(11):226-232.
[2]王锦,张新有.基于DQN的无人驾驶任务卸载策略[J].计算机应用研究, 2022, 39(9):7.
[3]池浩宇.基于深度强化学习的机械臂自主轨迹规划研究[D].西安科技大学,2022.
🌈4 Python代码实现
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取


















 928
928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









