




本文出自于 Human-level control through deep reinforcement learning,主要提出了DQN:深度神经网络和强化学习的结合技术。
我们利用最近在训练深度神经网络方面的相关进展,开发出一种新的人工智能代理,被称为深度Q-network,它可以使用端到端的强化学习,直接从高维度传感输入中学习到成功的策略。本文在经典的Atari 2600游戏挑战性领域中测试了这个代理,深度Q-network代理只接收到像素和游戏分数作为输入,使用相同的算法、网络架构和超参数,在49款游戏中超越之前所有算法的性能,并能达到与专业游戏测试人员相当的水平。这项工作弥合了高维度传感输入和动作之间的鸿沟,从而产生了第一个能够在各种挑战性任务中进行学习优异的人工智能。
一、简介
- Deep Q-network:能够将深度神经网络与强化学习进行结合。我们考虑一类任务,代理可以通过一系列观察、行动和奖励来进行交互,代理的目标是以某种方式选择actions,来最大化累积未来reward。我们使用深度卷积神经网络来接近最优 action-value函数,在做过一个observation(s)和采取一个action(a)后,由一个行为策略 π = P ( a ∣ s ) \pi=P(a|s) π=P(a∣s)来实现每个时间戳t的最大化奖赏累积。
Q ∗ ( s , a ) = max π Ξ [ r t + γ r t + 1 + γ 2 r t + 2 + . . . ∣ s t = s , a t = a , π ] , Q^*(s,a)=\max \limits_\pi \Xi[r_t+\gamma r_{t+1}+\gamma ^2 r_{t+2}+...|s_t=s,a_t=a,\pi], Q∗(s,a)=πmaxΞ[rt+γrt+1+γ2rt+2+...∣st=s,at=a,π],
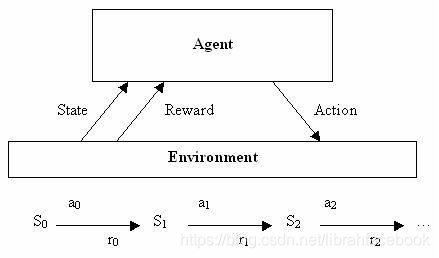
2. 当一个非线性函数逼近器例如一个神经网络被用来表示action-value函数(也称作Q函数)时,强化学习被认为是不稳定的甚至是发散的。这种不稳定性有几个原因:在观察序列中所出现的相关性,对Q的小部分更新可能会显著改变策略从而改变数据分布,在action-values(Q)和目标值中的相关性。我们使用一种新的Q-learning变体来解决这些不稳定性,它使用了两个关键思想。首先我们使用一种受生物学启发的机制 experience replay 来随机化数据,从而消除观察序列中的相关性,平滑数据分布的变化。其次,我们使用一种迭代式更新来调整 action-values(Q)为只定期更新的目标值,从而降低了与目标的相关性。
3. 我们使用一个深度卷积神经网络来参数化一个近似值函数 Q ( s , a ; θ i ) Q(s,a;\theta_{i}) Q(s,a;θi),其中 θ i \theta_i θi是第i次迭代中Q-network的参数。为了更好地执行experience replay,我们存储了在每个时间戳t的数据集 D t = { e 1 , . . . , e t } D_t=\left \{\ e_1,...,e_t \right \} Dt={
e1,...,et}中代理的经验 e t = ( s t , a t , r t , s t + 1 ) e_t=(s_t,a_t,r_t,s_{t+1}) et=(st,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1787
1787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









