







引子
在多模态人工智能领域,边缘计算解决方案正变得越来越重要。之前关注这一块的内容比较少,感觉大模型这一块,最终还是要和之前AI模型一样的,云端+边端,两条腿走路,OK,那就让我们开始吧。
一、模型介绍
这一领域最新的突破之一是OmniVision-968M,这是一个紧凑且高效的视觉-语言模型,有望彻底改变边缘AI应用。Omnivision-968M是由NexaAI创业公司推出。Nexa AI的愿景是打造先进的端侧AI模型,让AI技术不再局限于云端,而是能够直接在本地设备上运行。这不仅意味着成本的降低,更重要的是,它能够更好地保护用户的隐私安全。
Omnivision-968M由于体积较小,所以模型在推理速度上,有着非常不错的表现。在Apple最新M4 Pro处理器的MacBook上,它能够以不到2秒的惊人速度,生成一张1046×1568像素图像的语言描述。它在处理过程中仅占用988MB的统一内存空间。OmniVision-968M通过减少模型大小而不牺牲性能来解决这一差距,其参数规模小于10亿(968M),却具备强大的视觉和文本处理能力。模型在LLaVA架构的基础上进行了改进,带来了以下两大改进:
(1)9倍Token缩减:Omnivision将图像Token从729减少到81,这一改进大幅降低了延迟和计算成本,让模型运行更加高效。
(2)更少幻觉:通过使用来自可信数据的DPO训练,Omnivision减少了幻觉现象,提高了结果的可靠性。
模型架构
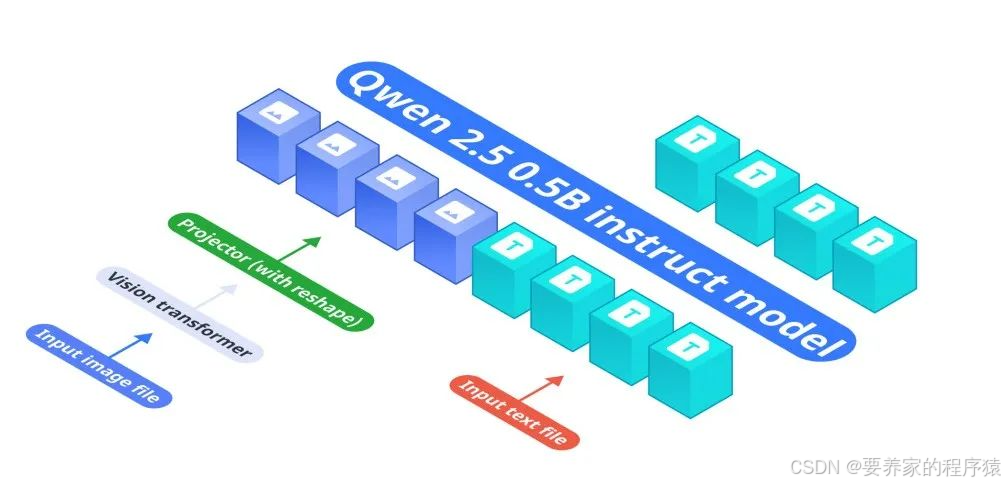
最先进的架构:OmniVision的架构由三个核心组件组成:
基础语言模型:Qwen2.5–0.5B-Instruct,优化了高效的文本处理。
视觉编码器:SigLIP-400M,以384分辨率和14×14的补丁大小运行,以生成详细的图像嵌入。
投影层:一个复杂的多层感知器(MLP),将视觉编码器的输出与语言模型的令牌空间对齐。这种设计不仅改善了视觉和文本输入之间的对齐,还确保了压缩图像令牌的无缝集成。
二、环境搭建
环境安装
docker run -it -v /datas/work/zzq/:/workspace --gpus=all pytorch/pytorch:2.4.0-cuda12.4-cudnn9-devel bash
1、安装python包
pip install torch torchvision torchaudio einops timm pillow transformers accelerate diffusers huggingface_hub sentencepiece bitsandbytes protobuf record -i Simple Index
2、安装Nexa SDK
CMAKE_ARGS="-DGGML_CUDA=ON -DSD_CUBLAS=ON" pip install nexaai --prefer-binary --index-url https://github.nexa.ai/whl/cu124 --extra-index-url Simple index --no-cache-dir
3、nexa run omniVLM

三、测试
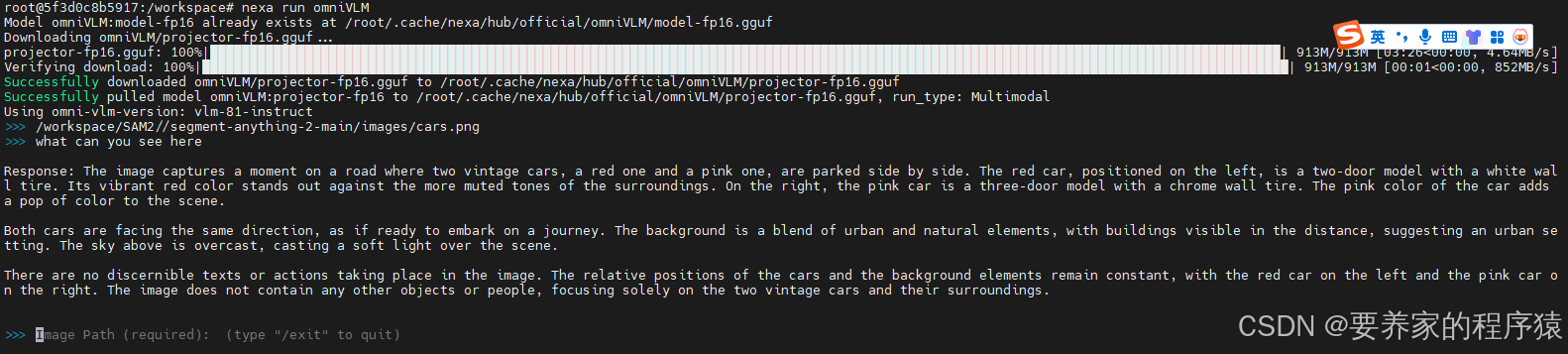
1、测试图片

2、输入图片和描述



















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











