




 博客提出弱监督数据增强网络WS - DAN,以解决随机数据增强效率低和产生背景噪声的问题。通过弱监督学习产生注意力图,进行注意力裁剪和下降的数据增强方式。实验表明,该网络能提高分类精度,且性能优于随机数据增强和SOTA方法。
博客提出弱监督数据增强网络WS - DAN,以解决随机数据增强效率低和产生背景噪声的问题。通过弱监督学习产生注意力图,进行注意力裁剪和下降的数据增强方式。实验表明,该网络能提高分类精度,且性能优于随机数据增强和SOTA方法。
文章目录
0 摘要
- 随机数据增强效率低,而且可能产生许多不可控的背景噪声
- 提出了弱监督数据增强网络WS-DAN探索数据增强的潜能:
- 对每张训练图像,通过弱监督学习产生若干注意力图
- 以注意力图为指导,进行数据增强(注意力裁剪和注意力下降)
- WS-DAN提高分类精度在于两方面原因:
- 由于更判别性的部件特征能够提取,图像能看的更仔细(see better)
- 注意力区域提供对象更精确的位置,帮助模型更近地看对象(look closer),提高性能
1 引言
- 数据增强策略很常用,随机数据增强效果可能不好。模型应能意识到目标对象的空间信息
- 细粒度视觉分类困难重重
- FGVC任务的关键步骤是从多个目标的部分中提取更具判别性的局部特征。本文使用弱监督学习定位判别性部分,用卷积生成的注意力图表示对象的部分视觉模式,而不是使用区域边界框。提出得双线性注意力集中和注意力正则化损失来作为注意力生成过程的弱监督信息。 模型可以更轻松定位大量对象零件,获得更好性能。
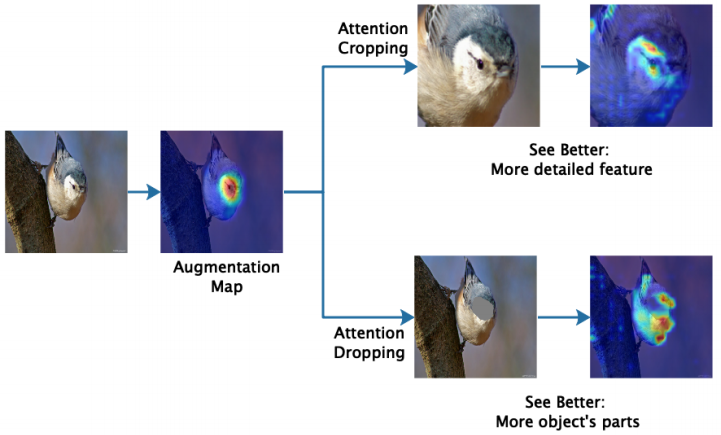
- 提出以注意力为导向的数据增强方法:注意力裁剪(裁剪局部区域特征,看得更好)和注意力下降(删除某个区域,看的更多)。测试阶段,精确定位目标位置(看的更近)。
文本贡献:
- 提出弱监督注意力学习生成注意力图代表判别性对象部分的空间分布,提取一系列局部特征
- 提出注意力导向的数据增强提高数据增强的效率
- 使用注意力图精确定位整个目标
2 相关工作
细粒度分类
使用位置或属性等注释信息:Part R-CNN、Deep LAC 、VLF;
不使用注释信息:BCNN、MPN-COV(矩阵平方二阶合并),ST-CNN、RA-CNN、MA-CNN,MAMC损失,PC
数据增强
随机空间图像增强:图像裁剪和图像下降:
- Max-drop的目的是删除最大激活特征,以鼓励网络考虑激活稍差的特征。 缺点是Max-drop只能移除每个图像的一个区分区域,限制性能。
- Cutout和Hide-and-Seek通过从训练图像中随机遮掩许多正方形区域来提高CNN的鲁棒性,但是许多被删除的区域都是不相关的背景,或者整个目标被擦除尤其是小目标
将数据分布考虑进来解决随机数据增强的缺点:
- Au-to-Augmentation:创建了一种数据增强策略的搜索空间,可以自动设计特定策略,获得目标数据集的最好验证集准确性。
- 对抗性数据增强:将数据增强和深度模型联合起来优化。增强网络在线生成硬数据并提高深度模型的鲁棒性。 但其特定于数据的增强比随机增强要复杂得多。
本文方法关注的图像的空间增强,以注意力为导向的数据增强更简单,可以生成部件级的扩充以提高性能。
弱监督定位
早期工作通常通过**全局平均池(GAP)**生成特定于类的定位特征图,激活区域可以反映对象的位置。 但通过交叉熵损失进行训练通常会使模型注意最有区别的位置,其输出边界框仅覆盖对象的一部分。
为了定位整个对象:
- 随机隐藏输入图像的补丁,以迫使网络找到其他可辨别的部分。 但由于缺少高级指导,效率很低。
- 对抗互补学习(ACoL) 通过训练两个对手互补分类器来发现整个对象,该分类器可以定位不同对象的组成部分并发现属于同一对象的互补区域。 然而,在其实施中只有两个互补区域,这限制了准确性。
以注意力为导向的数据增强鼓励模型关注对象的多部分,提取更多特征,在目标定位方面取得显着性能。
3 方法
训练阶段: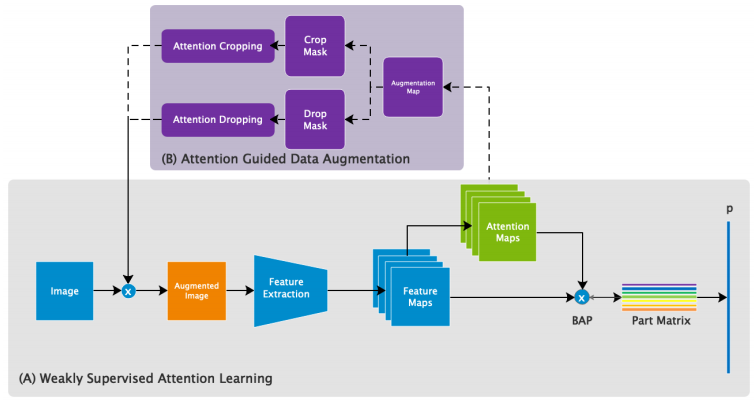
测试阶段: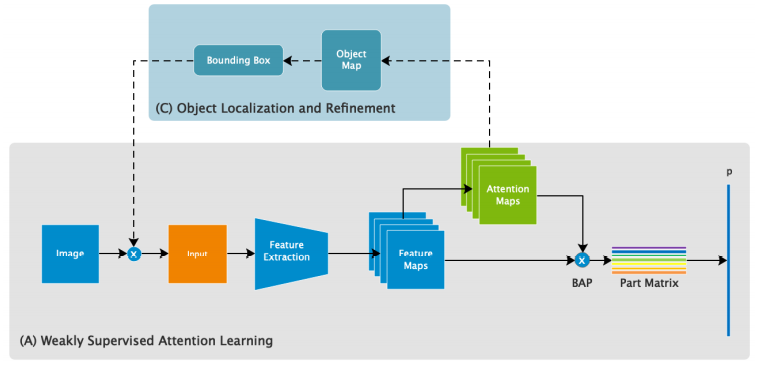
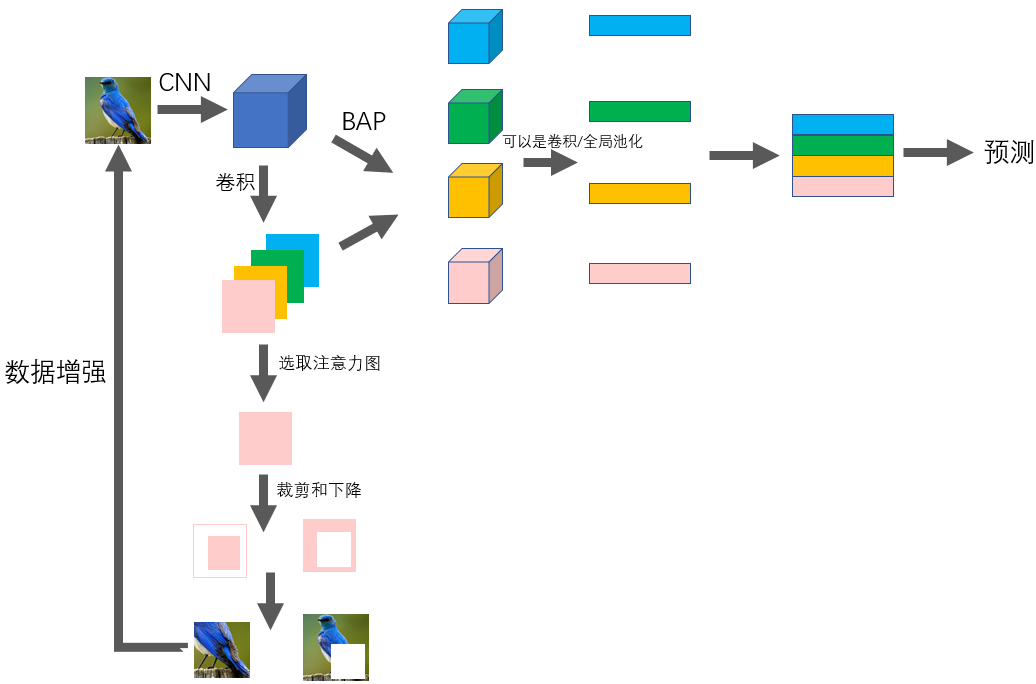
3.1 弱监督注意力学习
-
空间表示
训练、测试都只使用类别信息,没有任何注释信息。图像 I I I,特征图 F ∈ R H × W × N F\in R^{H\times W\times N} F∈RH×W×N,注意力图 A ∈ R H × W × M A\in R^{H\times W\times M} A∈RH×W×M, f f f是卷积函数, A k ∈ R H × W A_k\in R^{H\times W} Ak∈RH×W代表了某个部分。 N N N是特征图通道数, M M M是注意力图的数量。
A = f ( F ) = ⋃ k = 1 M A k A=f(F)=\bigcup_{k=1}^{M}A_k A=f(F)=k=1⋃MAk -
双线性注意力合并BAP
注意力图和特征图逐元素相乘,生成 M M M个部分特征图。特征图通过函数 g g g(全局均值池化、全局最大池化或者卷积)生成注意力特征 f k ∈ R 1 × N f_k\in R^{1\times N} fk∈R1×N。
F k = A k ⊙ F ( k = 1 , 2 , . . . , M ) f k = g ( F k ) F_k=A_k\odot F \quad (k=1,2,...,M)\\ f_k=g(F_k) Fk=Ak⊙F(k=1,2,...,M)fk=g(Fk)
各个注意力特征堆叠形成部分特征矩阵
P
∈
R
M
×
N
P\in R^{M\times N}
P∈RM×N,
Γ
(
A
,
F
)
\Gamma(A,F)
Γ(A,F)代表BAP:
P
=
Γ
(
A
,
F
)
=
(
g
(
a
1
⊙
F
)
g
(
a
2
⊙
F
)
.
.
.
g
(
a
M
⊙
F
)
)
=
(
f
1
f
2
.
.
.
f
M
)
P=\Gamma(A,F)= \begin{pmatrix} g(a_1\odot F)\\ g(a_2\odot F)\\ ...\\ g(a_M\odot F)\\ \end{pmatrix} = \begin{pmatrix} f_1\\ f_2\\ ...\\ f_M\\ \end{pmatrix}
P=Γ(A,F)=⎝⎜⎜⎛g(a1⊙F)g(a2⊙F)...g(aM⊙F)⎠⎟⎟⎞=⎝⎜⎜⎛f1f2...fM⎠⎟⎟⎞
-
注意力中心损失
引入注意力正则化损失,部分特征 f k f_k fk将接近全局特征中心 c k ∈ R 1 × N c_k\in R^{1\times N} ck∈R1×N,注意力图 A k A_k Ak将在第 k k k个相同对象的部分中被激活,损失函数如下:
L A = ∑ k = 1 M ∣ ∣ f k − c k ∣ ∣ 2 2 L_A=\sum_{k=1}^M||f_k-c_k||^2_2 LA=k=1∑M∣∣fk−ck∣∣22
c k c_k ck是部分的特征中心, c k c_k ck从初始化为 0 0 0,训练过程中更新: c k ← c k + β ( f k − c k ) c_k\gets c_k+\beta(f_k-c_k) ck←ck+β(fk−ck)
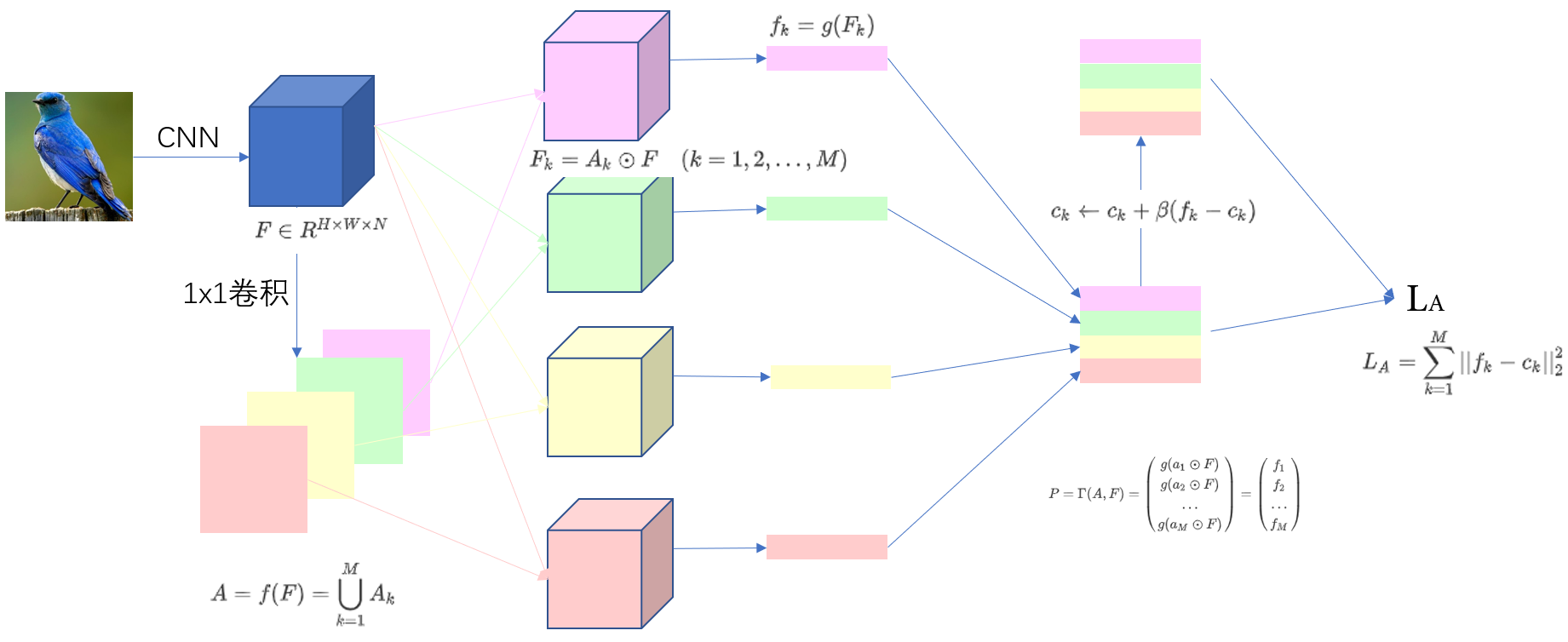
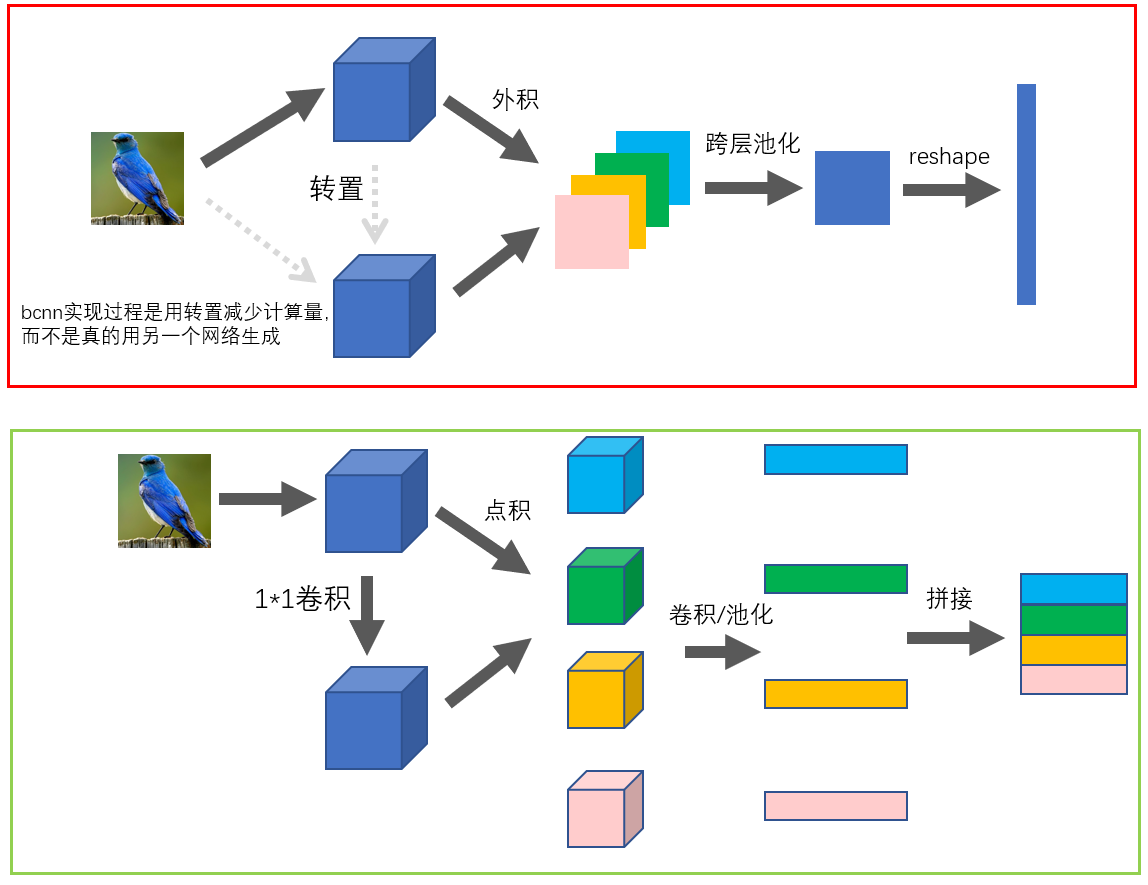
这一块和BCNN得逻辑很相像,如下图:
3.2 注意力导向的数据增强
-
增强图
每个训练图像,随机选择注意力图之一 A k A_k Ak指导数据增强过程,将其标准化为第 k k k个增强图 A k ∗ ∈ R H × W A_k^*\in R^{H\times W} Ak∗∈RH×W。
A k ∗ = A k − min ( A k ) max ( A k ) − min ( A k ) A_k^*=\frac{A_k-\min(A_k)}{\max(A_k)-\min(A_k)} Ak∗=max(Ak)−min(Ak)Ak−min(Ak)
这样增强图的每个元素值都在 [ 0 , 1 ] [0,1] [0,1]之间。 -
注意力裁剪
对于增强图 A k ∗ A^∗_k Ak∗,将大于阈值 θ c ∈ [ 0 , 1 ] θc∈[0,1] θc∈[0,1]的元素设置为1,其他为0,从 A k ∗ A^∗_k Ak∗获得裁剪掩模 C k C_k Ck。
C k ( i , j ) = { 1 , A k ∗ ( i , j ) > θ c 0 , . o . w C_k(i,j)= \begin{cases} 1,&A_k^*(i,j)>\theta_c \\ 0,&.o.w \end{cases} Ck(i,j)={1,0,Ak∗(i,j)>θc.o.w寻找可以覆盖 C k C_k Ck的整个选定区域的边界框 B k B_k Bk,并将原始图像中的对应区域放大作为扩展的输入数据
-
注意力下降
为了鼓励注意力图代表区分对象的多个部分,需要降低注意力。将大于阈值 θ d ∈ [ 0 , 1 ] θ_d\in[0,1] θd∈[0,1]的元素设置为0,其他设置为1,我们获得注意力下降掩模 D k D_k Dk。
D k ( i , j ) = { 0 , A k ∗ ( i , j ) > θ d 1 , . o . w D_k(i,j)= \begin{cases} 0,&A_k^*(i,j)>\theta_d \\ 1,&.o.w \end{cases} Dk(i,j)={0,1,Ak∗(i,j)>θd.o.w
通过用 D k D_k Dk掩盖图像I将删除第 k k k部分区域。
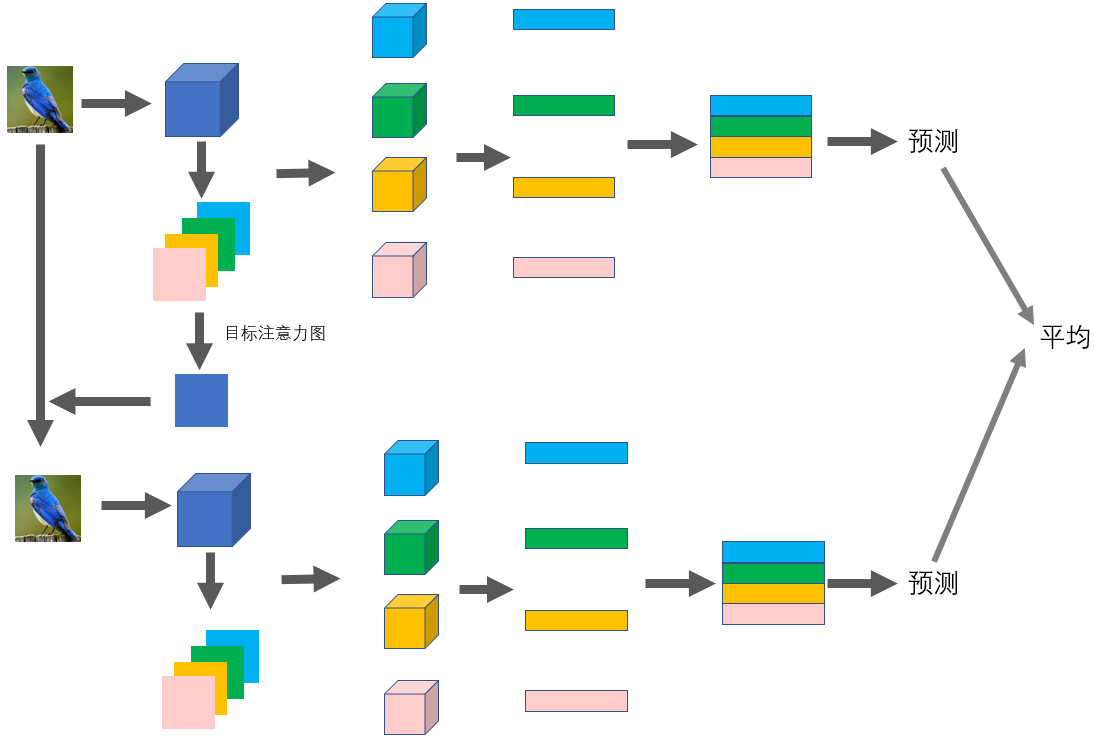
3.3 目标定位和细化
测试过程中,模型输出原始图像的粗略分类结果和相应的注意图后,根据注意力图生成表示对象位置的对象图 A m = 1 M ∑ k = 1 M A k A_m=\frac{1}{M}\sum_{k=1}^MA_k Am=M1∑k=1MAk,再通过网络对其进行放大预测(生成边界框 B B B,得到放大图像 I o I_o Io)。

4 实验
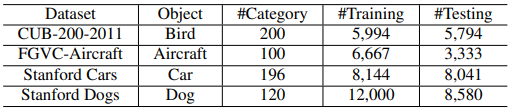
4.1 数据集
4.2 实现细节
Inception v3做主干特征提取网络,Mix6e层作特征图,注意力图通过 1 × 1 1\times1 1×1卷积获得,GAP(全局池化)作特征池化函数, θ c \theta_c θc和 θ d \theta_d θd都是 0.5 0.5 0.5。SGD、momentum =0.9、weight decay = 0.00001、mini-batch size =16、P100 GPU、 初始学习率0.001,每2个周期后参数为0.9的指数衰减。
4.3 精度分布
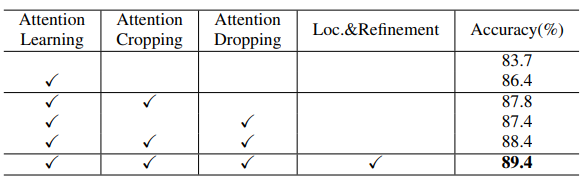
WS-DAN主要包括四部分:
- 弱监督注意力学习
- 注意力裁剪
- 注意力下降
- 目标定位和细化
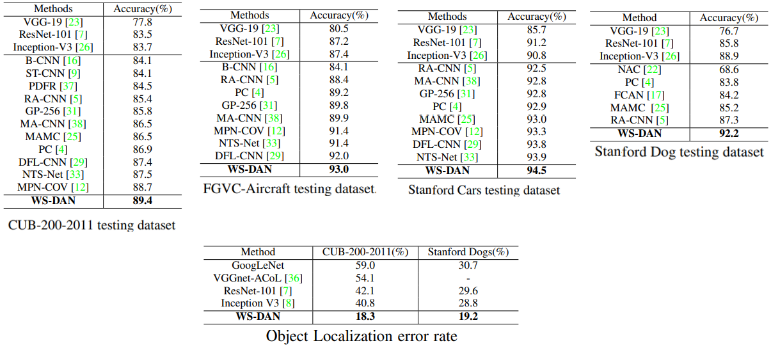
CUB数据集上的结果:
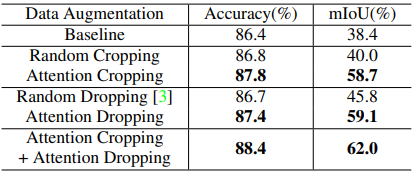
4.4 与随机数据增强比较
注意力导向的数据性能比随机数据增强更高效:
4.5 与SOTA比较
WS-DAN取得了最好的正确率:
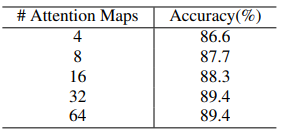
4.6 注意力图数量的影响
随注意图数目增多,正确率得到了提升,到32时性能达到稳定(饱和):
4.7 数据增强可视化
可视化发现的现象:
- 随机裁剪很大可能包含大面积的背景,注意力裁剪裁剪效果更好
- 随机下降可能擦除整个目标或仅仅擦除背景,注意力下降能隐藏对象判别性部分保证多注意力
5 结论
弱监督数据增强网络WS-DAN:将弱监督学习WSL和数据增强DA结合起来,二者共同进步。
6 其他
6.1 网络结构图
训练:
测试:
6.2 代码
官方代码是tensorflow,但是Pytorch(github地址)更简单。
-
BAP时,虽然说是特征矩阵,但是实际上还是一个向量
feature_matrix = [] for i in range(M): feature_k = features * attentions[:, i:i + 1, ...] F_k = nn.AdaptiveAvgPool2d(1)(feature_k) # 或nn.AdaptiveMaxPool2d(1)(feature_k) F_k = F_k.view(B, -1) feature_matrix.append(F_k) feature_matrix = torch.cat(feature_matrix, dim=1) # GAP可用以下方式:feature_matrix = (torch.einsum('bmhw,bchw->bmc', attentions, features) / float(H * W)).view(B, -1)。h和w的两维做点积形成一个数字,再除以总数H*W求平均,和上面完全等价求出特征矩阵之后,还有BCNN的后续操作(符号函数 s i g n ( x ) x \newcommand{\sign}[1]{\mathrm{sign}(#1)}\sign x\sqrt x sign(x)x、正则化 y / ∣ ∣ y ∣ ∣ 2 y/||y||_2 y/∣∣y∣∣2):
# sign-sqrt feature_matrix = torch.sign(feature_matrix) * torch.sqrt(torch.abs(feature_matrix) + EPSILON) # 2 normalization along dimension M and C feature_matrix = F.normalize(feature_matrix, dim=-1) # -1为最后一个维度 -
数据增强,训练和测试的不同:
if self.training: # 训练过程,进行数据增强,拿到掩模 attention_map = [] for i in range(batch_size): attention_weights = torch.sqrt(attention_maps[i].sum(dim=(1, 2)).detach() + EPSILON) attention_weights = F.normalize(attention_weights, p=1, dim=0) k_index = np.random.choice(self.M, 2, p=attention_weights.cpu().numpy()) attention_map.append(attention_maps[i, k_index, ...]) attention_map = torch.stack(attention_map) # (B, 2, H, W) - one for cropping, the other for dropping else: # 测试过程,加上目标对象放大 attention_map = torch.mean(attention_maps, dim=1, keepdim=True) # (B, 1, H, W) -
特征中心计算:
- 每一个类别的每一个部分/视觉模式都有一个特征中心,所以特征中心的维度应该是:(分类数目,部分数*特征向量大小)
- 训练时,对特征中心的更新也要根据类别标签
# num_classes:种类数 # num_attentions:关注的部分数,论文是32 # num_features:特征向量大小,根据主干网络而异,Inception_mixed_6e是768 feature_center = torch.zeros(num_classes, num_attentions * num_features) # 更新中心,y是标签 feature_center_batch = F.normalize(feature_center[y], dim=-1) feature_center[y] += config.beta * (feature_matrix - feature_center_batch) -
训练过的损失是:(原始图像分类损失+裁剪分类损失+下降分类损失)的平均+特征中心损失;
测试是(原始图像分数+裁剪分数)的平均的损失
batch_loss = criterion(y_pred_raw, y) / 3. + criterion(y_pred_crop, y) / 3. + criterion(y_pred_drop, y) / 3. + center_loss(feature_matrix, feature_center_batch) # 训练 batch_loss = cross_entropy_loss((y_pred_raw + y_pred_crop) / 2., y) # 测试 -
根据注意力图生成热力图(可视化技巧):
def generate_heatmap(attention_maps): """ :param attention_maps: (batch_size,1,image_height. image_width) :return: tensor(batch_size,3,image_height. image_width) """ heat_attention_maps = list() heat_attention_maps.append(attention_maps[:, 0, ...]) # R heat_attention_maps.append(attention_maps[:, 0, ...] * (attention_maps[:, 0, ...] < 0.5).float() + \ (1. - attention_maps[:, 0, ...]) * (attention_maps[:, 0, ...] >= 0.5).float()) # G heat_attention_maps.append(1. - attention_maps[:, 0, ...]) # B return torch.stack(heat_attention_maps, dim=1) heat_attention_maps = generate_heatmap(attention_maps) heat_attention_image = raw_image * 0.5 + heat_attention_maps * 0.5效果:


















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









