







本文是《See Better Before Looking Closer: Weakly Supervised Data Augmentation Network for Fine-Grained Visual Classification》的论文阅读笔记
Q1:本文解决什么问题?
数据增强(Data augmentation)的传统手段:增加训练数据,防止过拟合,提升深度模型表现
随机数据增强(随机图像裁剪):效率低,带来不可控的背景噪声
Q2:本文通过什么模型/理论/方法来解决这个问题?
模型:1.弱监督学习生成注意力图像(表示目标区别部分)
2.注意力图像增强图像引导attention cropping and attention dropping(注意力裁剪、注意力下延)
理论:双线性注意力池化Bilinear Attention Pooling(BAP)
方法:1.图像seen better(注意力判别区域提取)2.注意力区域精确定位目标look closer
Q3:本文的结果
优于最先进的方法,且有效率。
1.训练部分
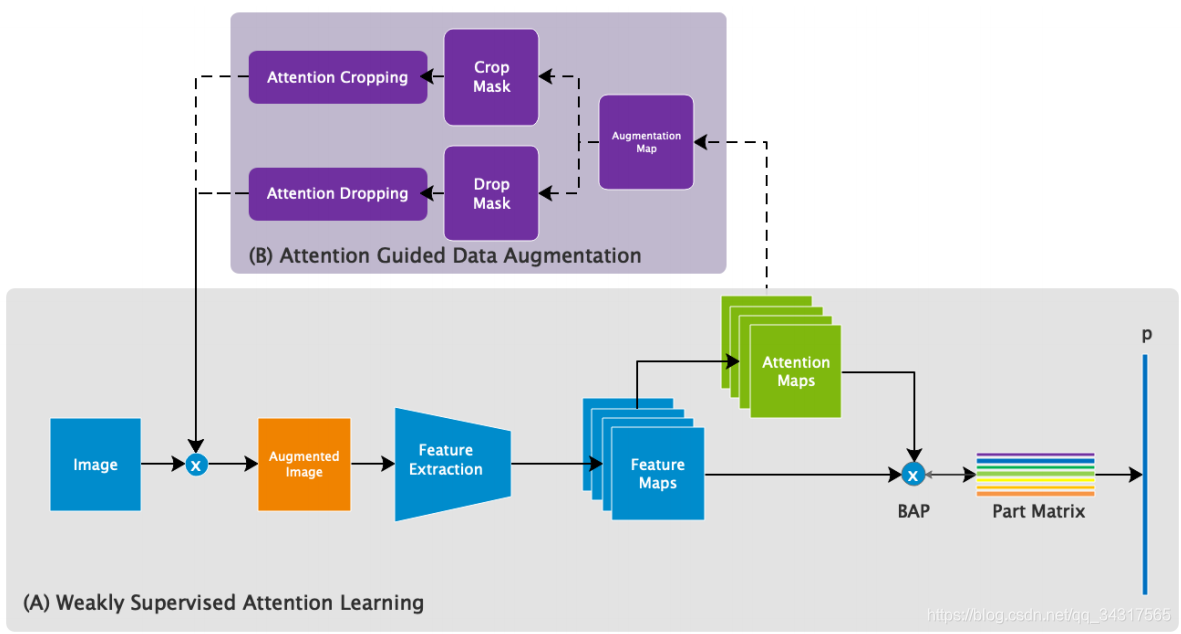
分为两个模块:(A)Weakly Supervised Attention Learning弱监督注意学习.(B) Attention-Guided Data Augmentation注意力引导数据增强.
(A)Weakly Supervised Attention Learning
Bilinear Attention Pooling
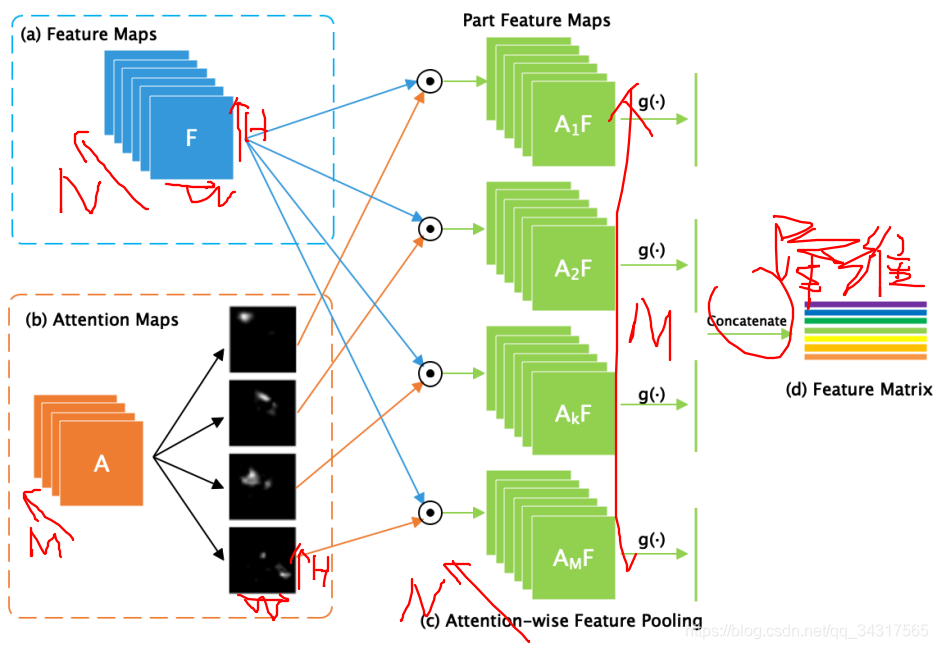
Bilinear Attention Pooling的过程。
网络骨干(如Inception v3)首先分别生成特征图feature maps(a)和注意图attention maps(b)。每个注意图代表一个特定对象的部分;
有公式得到Attention Maps A
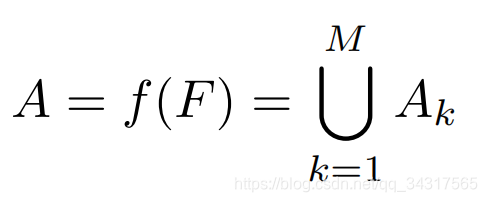
F是由CNN对图像I提取出来的特征图feature maps,具有H高度、W宽度及N个维度的张量,Attention Maps A表示具有H高度、W宽度及M个维度的张量。f(.)是卷积操作,Ak表示第k个注意力映射。
©通过将每个注意力图与特征地图相乘,按元素顺序element-wise生成部分特征图。然后通过卷积或池化操作提取部分特征;element-wise乘积表示如下
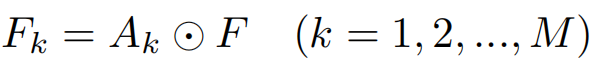
(d)最终的特征矩阵由所有这些部分特征组成
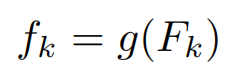
对Fk进行池化操作g(.)降维,得到部分特征。
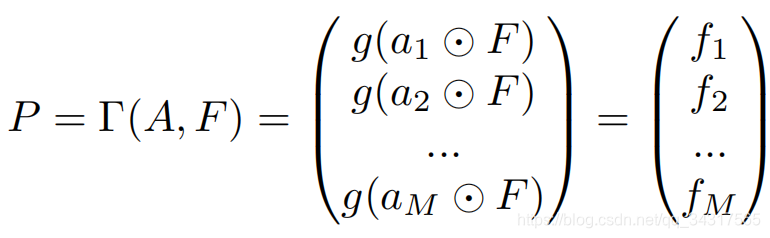
最终的特征矩阵由M个Fk组成。
Attention Regularization注意力机制
类似center loss的方法
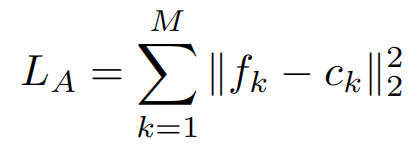
由上述部分特征fk与全局中心特征ck做平方差之和,这样可以attention到相同的特征部分,而ck由滑动平均公式更新。
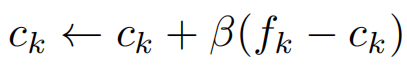
(B) Attention-Guided Data Augmentation
通过注意力引导的方式来增强数据
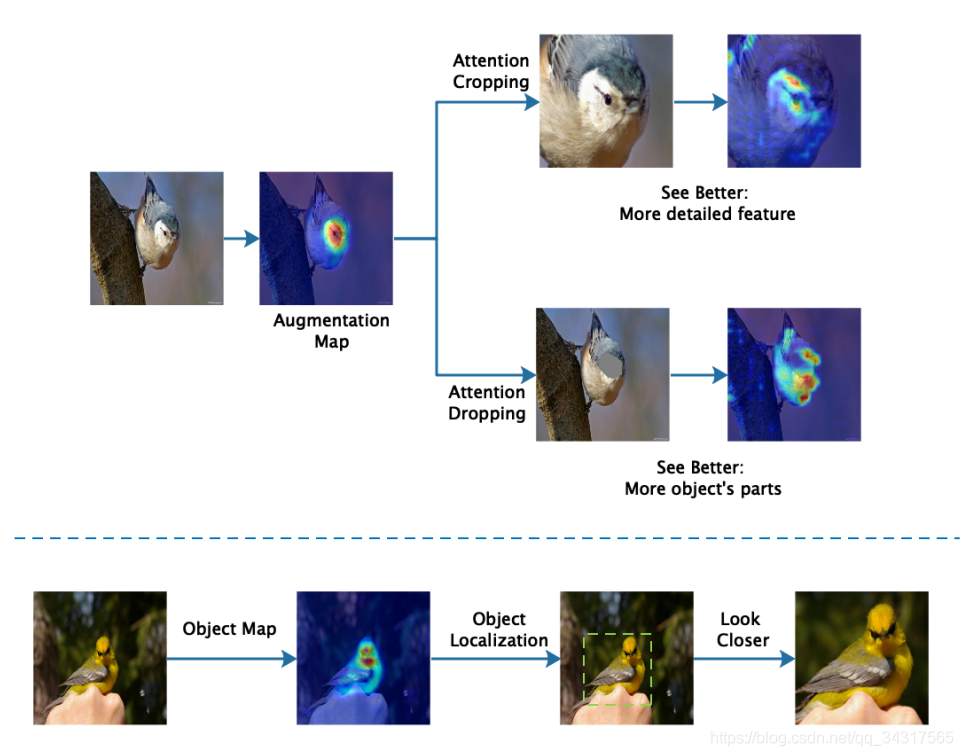
see better:注意力区域代表了图片中对象的具有辨识度的部分,论文中随机选取其中一个,通过attention cropping,裁剪注意力区域并放大可以看到更多细节特征,或者通过attention dropping,对所选的注意力区域向周围其他区域延伸注意力,这样能够关注到对象的其他部位特征。
look closer:通过图上的注意力区域定位到目标对象主体并放大
Augmentation Map
为了避免数据增强方法的背景干扰,随机选取Augmentation Map中的Ak引导数据增强。Ak作归一化处理如下:
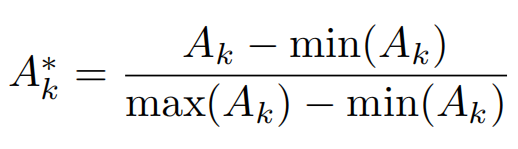
Augmentation Cropping
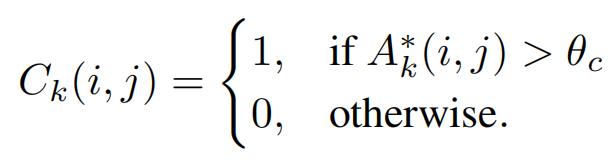
crop mask 当A*k大于阈值θc∈[0,1]时,Ck=1; 反之为0;找出最小的bounding box来截取注意力区域 , 作为训练数据,并放大至原图大小, 细节信息会更清晰. 该过程称为attention crop. 如果当 小于阈值 时, 否则 , 该过程称为attention drop. Attention drop操作可缓解多个attention map关注物体同一部位的问题.
Augmentation Dropping
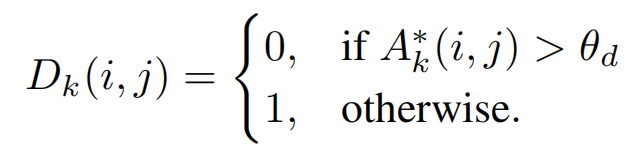
drop mask 当A*k大于阈值θd∈[0,1]时,Dk=0; 反之为1;这样做防止过多的attention map只关注同一部位
2.测试部分
Object Localization and Refinement
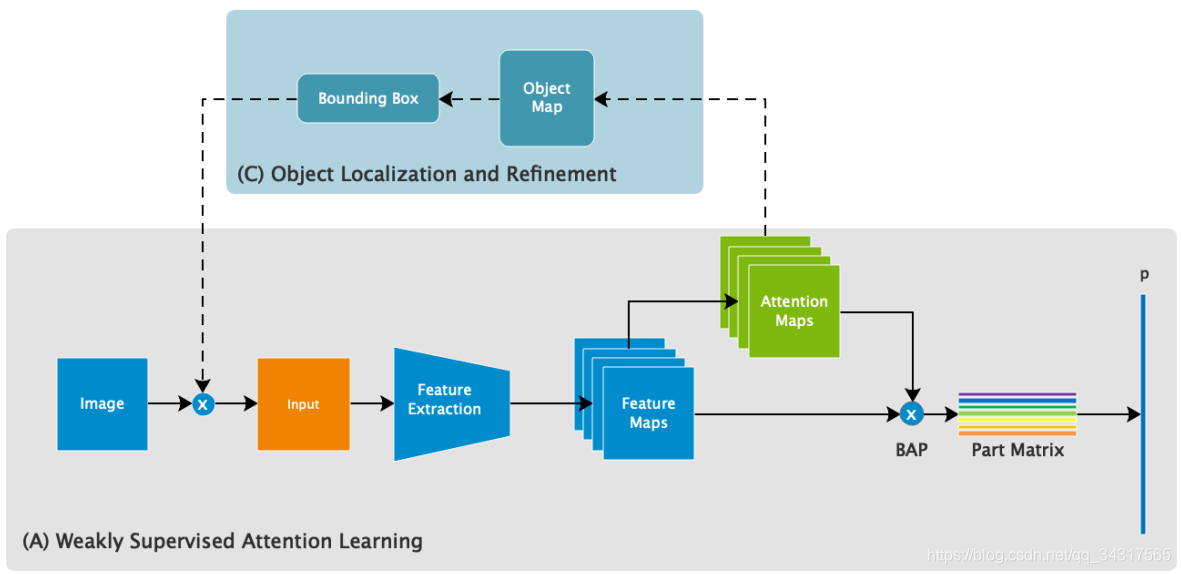
首先,由(A)弱监督注意学习从原始图像中输出目标的类别、概率和注意图(粗分类)
其次,目标将定位根据©然后加以扩大,公式如下M个attention map取平均
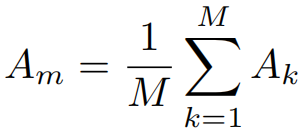
以改进类别的概率。最后,将以上两种概率合并(取平均)为最终预测
在测试过程中,模型输出原始图像的粗级分类结果和相应的注意图后,对对象的整个区域进行预测,并通过相同的网络模型将其放大以预测细粒度的结果。
3.实验结果
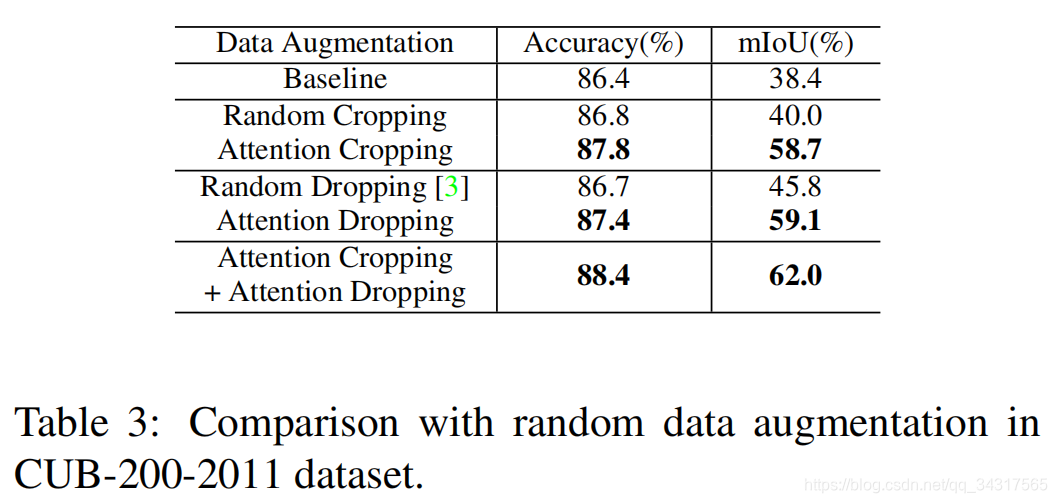
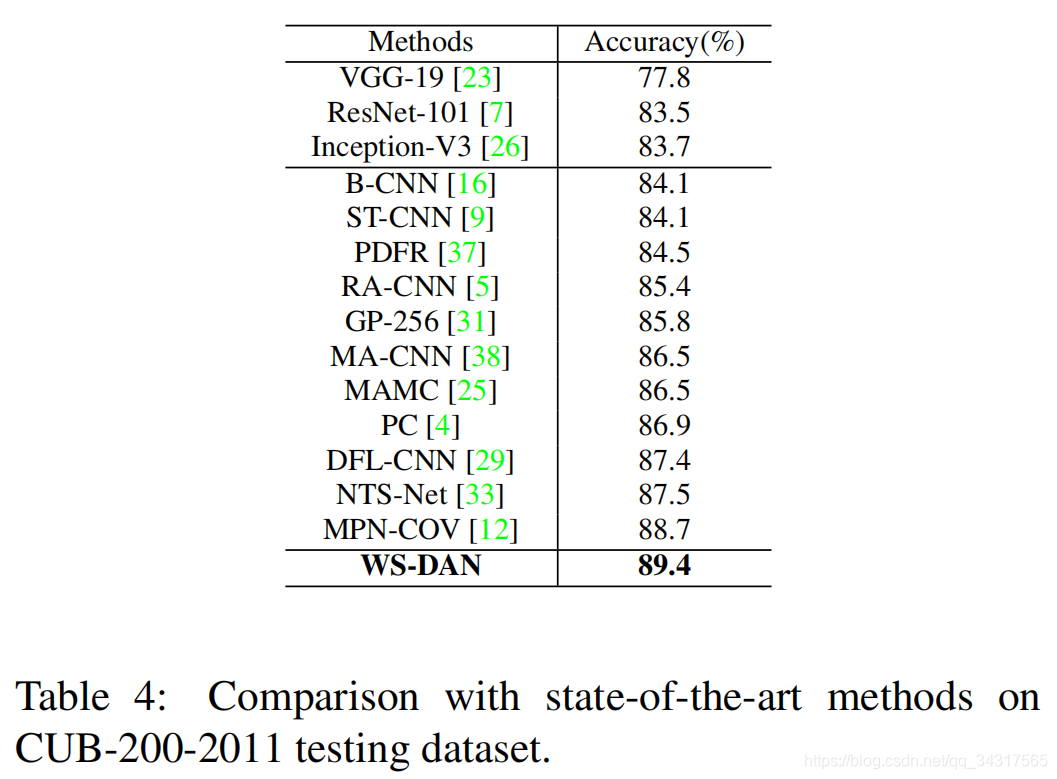
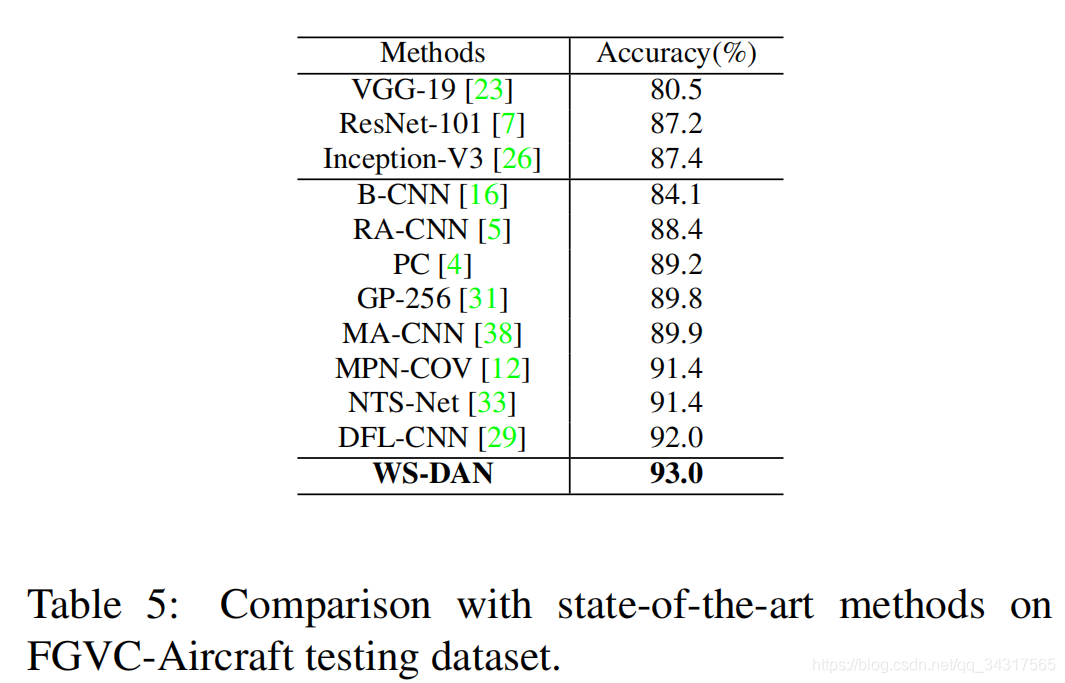
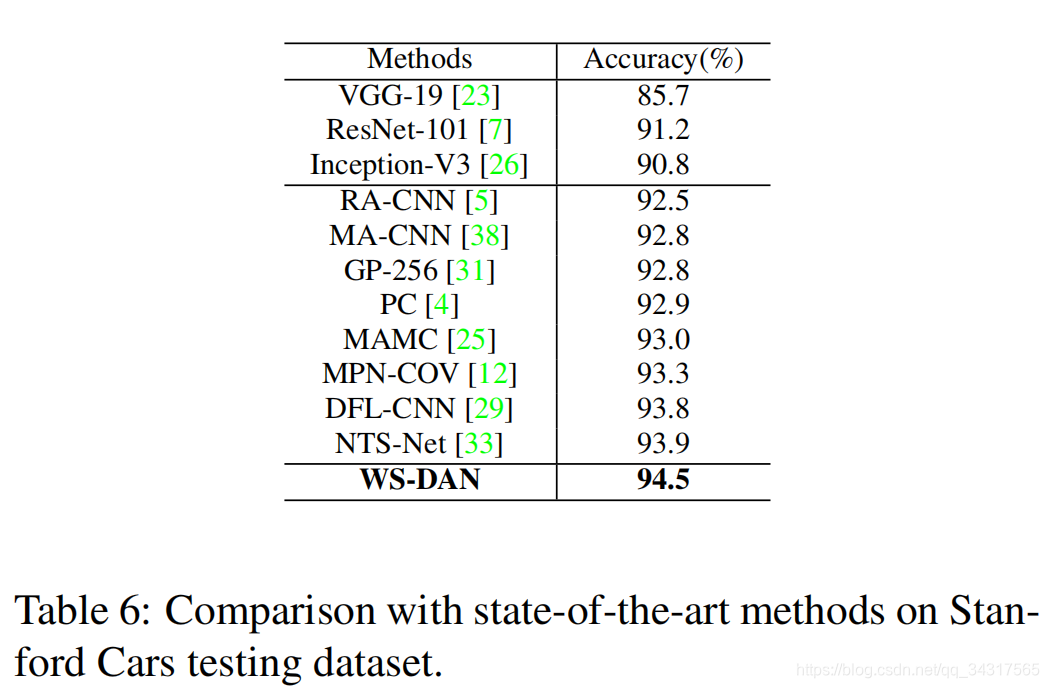
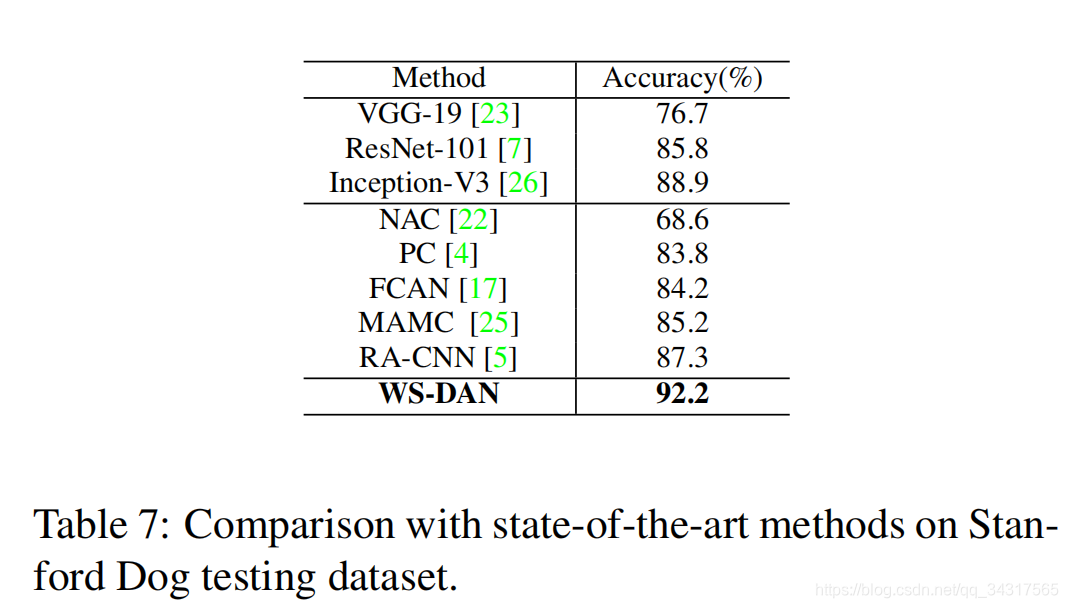
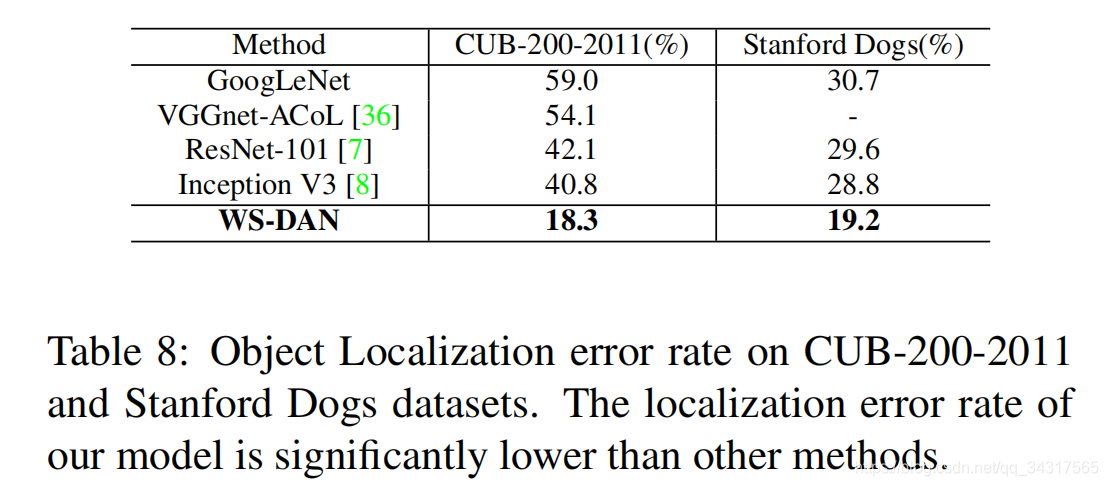
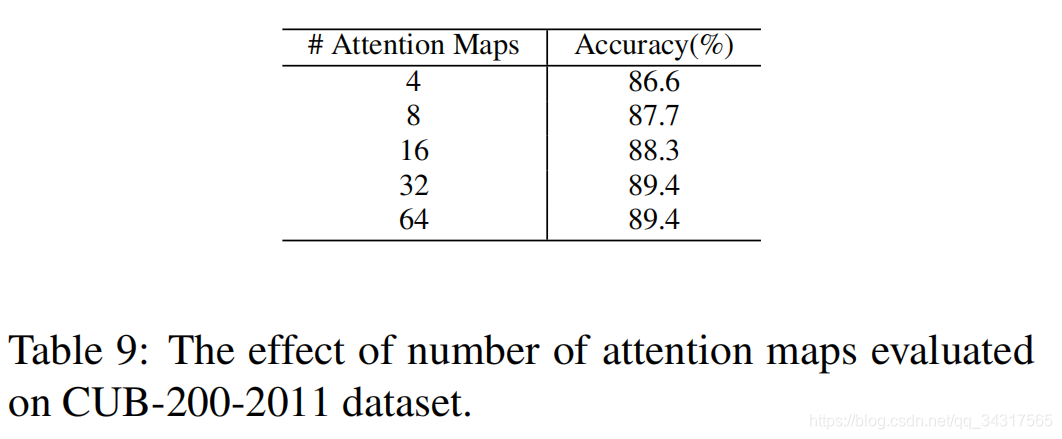
4总结
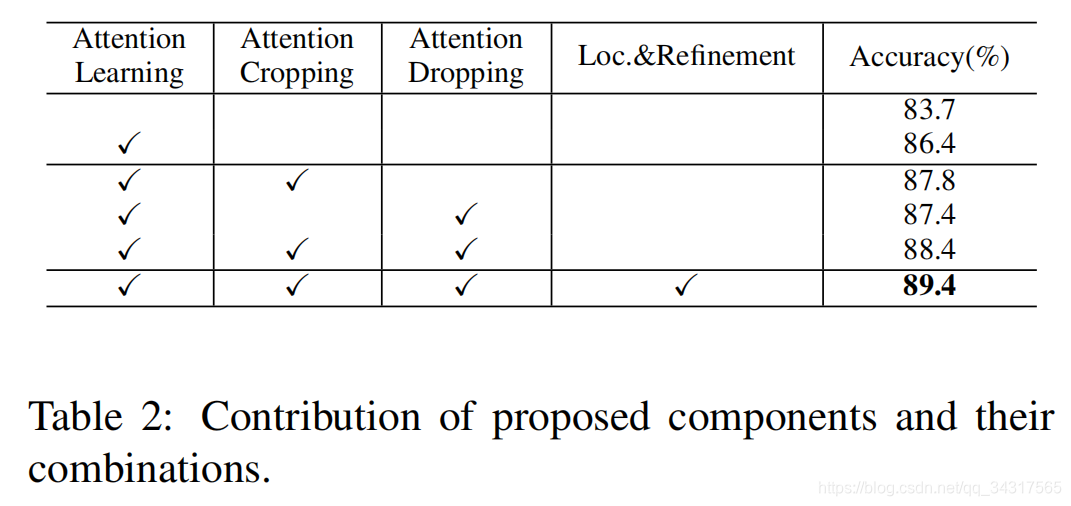
1.论文提出了弱监督注意学习来生成注意图来表示区分对象部分的空间分布,并提取连续的局部特征来解决细粒度的视觉分类问题
2.基于注意图,论文提出了基于注意引导的数据增强,以提高数据增强的效率,包括注意裁剪和注意下延。attention cropping注意裁剪采用随机裁剪,调整其中一个注意部分的大小,以增强局部特征表示。attention dropping为了鼓励模型从多个鉴别部分中提取特征,在图像中随机删除一个注意区域。
3.论文利用attention map来准确定位整个物体,并扩大它以进一步提高分类精度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









