




RAG技术在24年开始火起来,所谓RAG就是增强检索,使得我们自己的数据内容挂载到LLM上,这样LLM可以基于我们的内部知识以及其自有知识来对话。使用RAG后我们的内部知识不需要出局,本地部署的RAG系统即可带来LLM+自有知识库的新体验。正如下面的这张图所示,RAG技术使得我们结合了自有的知识库以及LLM的知识库。

这样带来了两个非常显著优点:
1)安全性,不用担心自己的数据为LLM厂家获取;
2)时效性,上传后即可使用数据,不需要等LLM厂家更新模型;
从我们24年的工作来说,在企业内部的销售材料+RAG使得分布在全国的销售通过对话即可了解公司的新品、新品特性等。企业内部的投标文件编写,很多技术部分都是重复的,标书+RAG使得复用历史知识,不受人员的流失的影响。LLM在处理这类文本类的工作时表显相当不错,但在处理财务数字类的业务,还有一些不足。LLM天然的无法处理要求100%准确的业务场景。
当然从入门到精通这个话说得有一些大了,但我相信,接下来的这几期内容,会让你了解RagFlow的能力、核心流程、主要代码模块。我们选择RagFlow也是对比多个项目以及与原生的RAG基础工作流的使用效果进行了对比。本文适合企业IT部门、产品经理、研发一起来交流讨论。
1)安装部署运行RagFlow;
2)RagFlow应用场景体验;
3)RagFlow核心流程;
4)简单改造RagFLow。
欢迎加微信,建立联系:xingzhedanqing。
如果需要查看本期套的其它内容,请关注公号:AIGC中文站
在今天的分享中,我们的目标是在本地完成RagFlow的部署,对接QWEN大模型,解决部署过程中常见的各种问题,完测试性的进行一次对话。
目录
快速了解RagFlow
获取RagFlow
做好准备工作
开始安装依赖
运行
测试对话
-
快速了解一下RagFlow
当你已经在看我这篇内容时,我默认你至少已经知道什么是RAG了,我将不再对此概念作过多的解释。你可以看一下我的相关内容:
RagFlow是infinite团队的一个开源项目,是我使用下来比较符合我的期望的一个项目,先看一下其整体的工作流图,从左到右分为两个过程,第一个是对Document的处理,建立我们的数据库;第二步是面向Custom的一个检索过程,以及将检索的内容投喂给LLM进行生成。
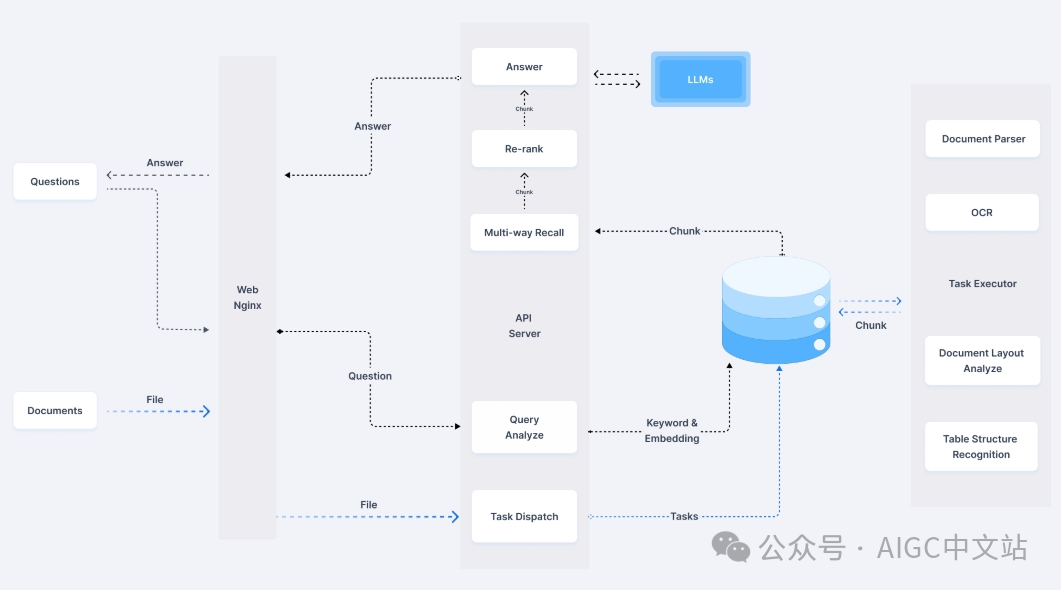
(RagFlow工作流图)
为什么我们选择RagFLow,因为他的一些特性:
多种输入知识处理方式:我们知道RAG有文本处理,和对话检索生成两个过程,在文本处理时,RagFlow有法律、论文、专利等多种处理模板,其OCR也是基于infinite团的深度识别框架完成,效果相当的出色;
检索过程的增强:使用了ES+向量库的方式混合检索,对两种方式的结果进行评分加权处理,这对比单一向量库检索的方式,结果的准确率高了不是太多;
权限角色:RagFlow自带了一个团队概念,团队可以邀请成员,对于一些简单的应用场景,这样的管理已经足够。当然,如果需要更复杂的权限管理,可以联系我们;
对话超长延迟加载:减少token的消耗;
检索结果带来源:可以查看来自那些文档,自
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1730
1730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









