




 本文深入解析ParseNet,一个采用全局上下文的端到端语义分割卷积神经网络。研究发现,CNN的实际感受野远小于理论值,通过全局平均池化、早期融合和晚期融合引入全局信息,提升分割性能。正常化过程中,通过可学习的尺度参数解决特征尺度差异,以优化训练。实验表明,ParseNet在语义分割任务上达到当时最优水平。
本文深入解析ParseNet,一个采用全局上下文的端到端语义分割卷积神经网络。研究发现,CNN的实际感受野远小于理论值,通过全局平均池化、早期融合和晚期融合引入全局信息,提升分割性能。正常化过程中,通过可学习的尺度参数解决特征尺度差异,以优化训练。实验表明,ParseNet在语义分割任务上达到当时最优水平。
Introduction
这篇文章提出了ParseNet,一个端到端的用于语义分割的卷及神经网络,这篇文章最大的贡献在于使用了全局语义信息(Global Context)来做分割,ParseNet可以直接对网络中任意一层进行全局池化得到一个代表全图特征的特征图,并利用这个特征图进行分割。
可是为什么加入了全局信息就会改善分割的结果呢?
对于CNN来说,由于池化层的存在,卷积核的感受野(Receptive Field)可以迅速地扩大,对于最顶层的神经元,其感受野通常能够覆盖整个图片。例如对于VGG的fc7层,其理论上的感受野有404*404大小,而输入的图像也不过224*224,似乎底层的神经元是完全有能力去感知到整个图像的全部信息。但事实却并不是这样的。文章通过实验证明了神经网络实际的感受野要远小于其理论上的感受野,并不足以捕捉到全局语义信息。
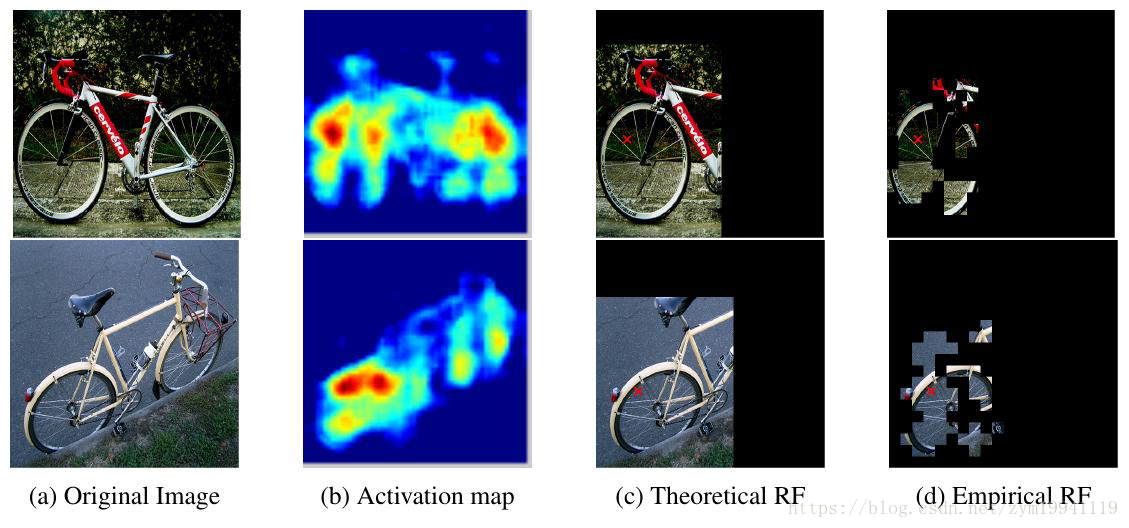
如上图所示,(a)是原图,(b)是某个神经元输出的Activation map,文章对原图上滑动一个窗口,对这个窗口内部的图像加入随机噪声并观察加噪声后该神经元的输出是否有较大的变化,当产生较大变化时,代表这个神经元可以感受到这部分图像,并由此得到实际的感受野,如图(d)所示。经过实验发现,实际感受野只有原图的约1*/4大小。在另一篇名为
Object detectors emerge in deep scene cnns
的论文中也得到了类似的结论。
既然有了这样的现象,那很自然得就会想到加入全局信息去提升神经网络分割的能力。人们常说,窥一斑而知全豹,但这句话并不总是成立的,如果说你盯着一根杆子使劲看而不去关注它的环境位置顶部底座等信息,同样难以判断出来这根杆子是电线杆还是标志牌或者红绿灯。就如同以下FCN的输出一样,充满了错误的分类结果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1286
1286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









