




 Zookeeper在启动时默认进入LOOKING状态,通过多层队列架构进行选举流程。节点间通过比较选举周期、ZXID和MYID来确定Leader。当选票过半数指向同一节点时,该节点成为Leader,其他节点变为FOLLOWER。新加入的节点会根据接收到的选票更新状态。选举算法包括FastLeaderElection,涉及WorkerSender和WorkerReceiver线程处理选票。Leader定期向FOLLOWER发送数据,若长时间未收到响应则重新选举。
Zookeeper在启动时默认进入LOOKING状态,通过多层队列架构进行选举流程。节点间通过比较选举周期、ZXID和MYID来确定Leader。当选票过半数指向同一节点时,该节点成为Leader,其他节点变为FOLLOWER。新加入的节点会根据接收到的选票更新状态。选举算法包括FastLeaderElection,涉及WorkerSender和WorkerReceiver线程处理选票。Leader定期向FOLLOWER发送数据,若长时间未收到响应则重新选举。
Zookeeper集群模式启动源码解析
状态ServerState:
- LOOKING:(启动的时候默认状态)集群里没有选举出Leader的时候,所有节点都是这个状态
- FOLLOWING:Follower的状态
- LEADING:被选举成Leader的状态
- OBSERVING:obeserve的状态
三个端口:
三种端口分别用来进行三种通信:接收客户端的命令(Netty/NIO)、进行选举、节点之间互相传数据

选举Leader流程
选举Leader流程
启动的时候每台机器的状态都是LOOKING状态,这时就是选举Leader。
- 当机器是LOOKING状态,会先创建一个选票(myid,zxid,选举周期…)发送给其他机器
- 自己也会收到其他发来的选票。 将自己和收来的选票进行pk,规则是先比较选举周期、再比较zxid,最后比较myid,谁大就把自己的选票更新成获胜的选票,且会把更新后的选票发给其他所有的。
- 将所有收来的选票都放到set里,根据过半机制选出Leader,会把选出的Leader的状态改为leading,其他改为following。
- 已经选出Leader后对于新加入的机器而言的状态为LOOKING状态,它会接收到之前的获胜选票,这时pk由于新加入的机器选举周期(1)会比获胜选票的周期小,所以它就会把自己的状态更新为following。
- 由于机器之间会建立通信用来同步数据,Leader会向所有的机器(Followers和Observers)发送数据,这些机器会一直处于接收状态,当一段时间接收不到Leader发来的数据,就会将自己的状态改为LOOKING,这时又会开始选举新的Leader。
pk逻辑,即从recvqueue中拿出来选票后做的事
Notification n=recvqueue.poll(notTimeout,TimeUnit.MILLISECONDS)
- n==null 第一次启动的时候是没有选票的这时去跟需要发送选票的机器建立Socket连接
- n不为空,即拿到别人发来的选票。判断发来选票的机器的状态n.state
- 发来选票的机器状态为LOOKING
-
接收到的选票周期大于自己的周期
-
接收到的选票周期等于自己的周期
-
接收到的选票周期小于自己的周期
-
- 发来选票的机器状态为LEADING或FOLLOWING
这种情况就是已经选出Leader,有新机器加入。新机器处于LOOKING把选票投自己,其他机器收到后发Leader选票给新机器。这时新机器把自己的状态更新为FOLLOWING。
- 发来选票的机器状态为LOOKING
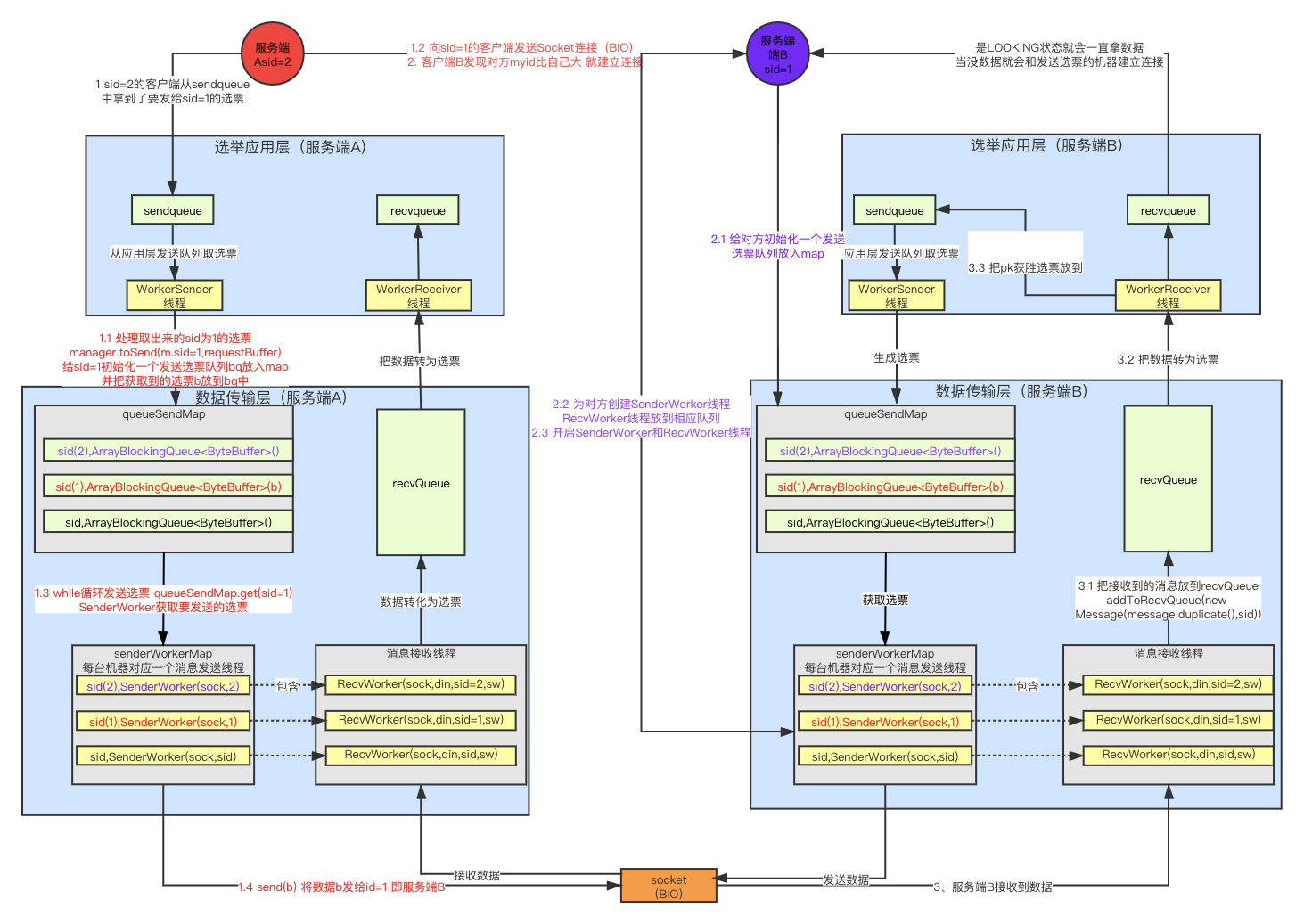
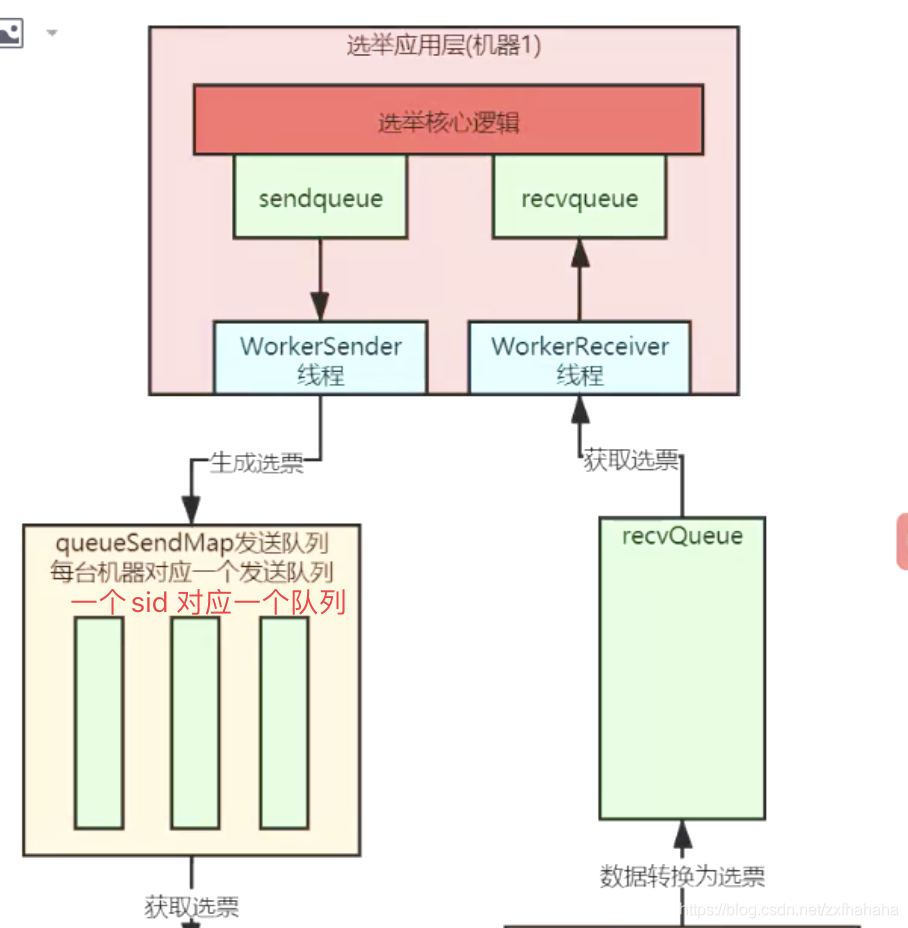
leader选举多层队列架构
对于上面的选举流程,Zookeeper底层是通过多层队列架构实现的
- 选举应用层
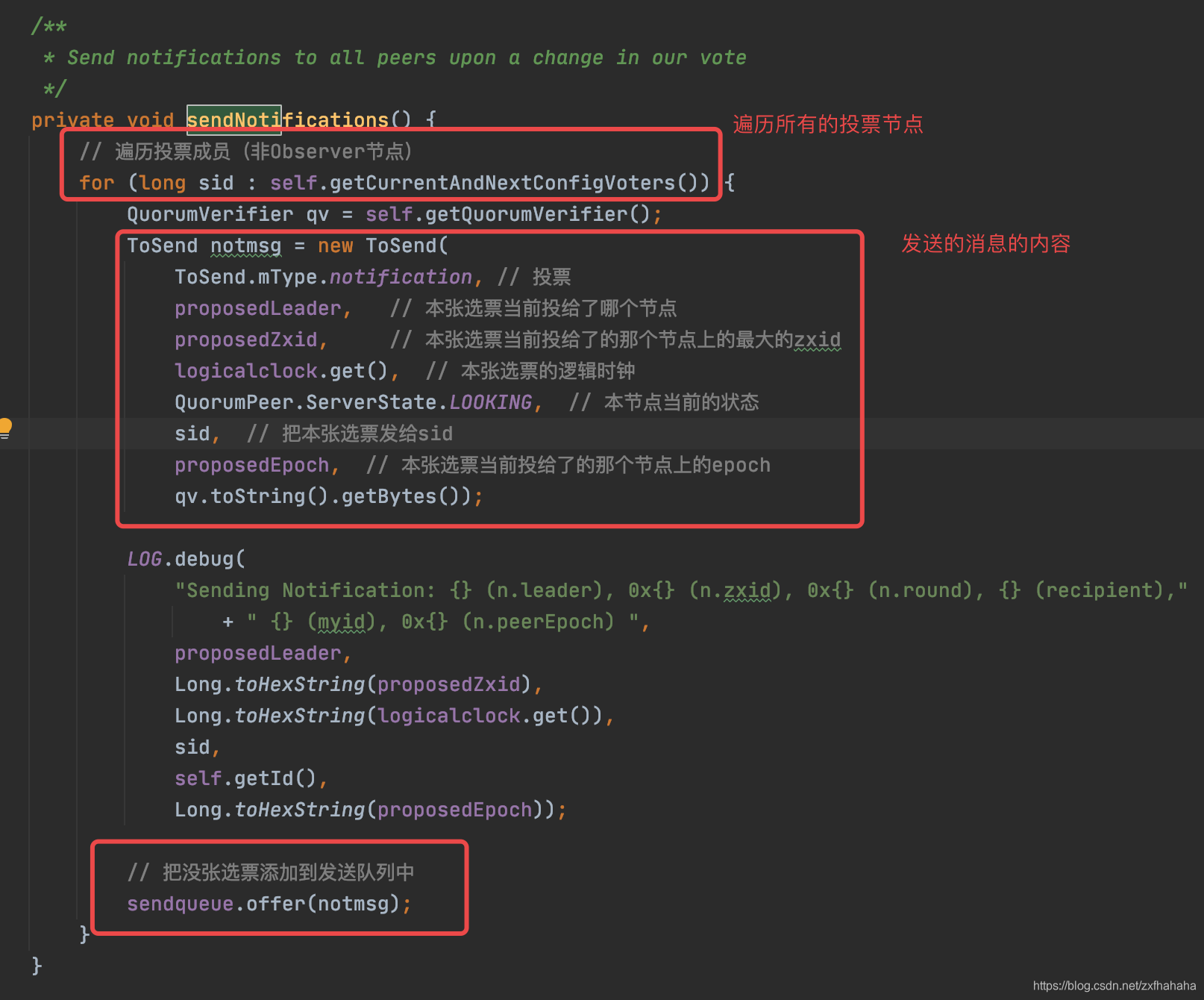
应用层用sendqueue和recvqueue来放选票,然后用WorkerSender和WorkerReceiver线程分别把这两个队列的选票传给消息传输层的队列。 - 消息传输层
- 传输层的queueSendMap用来为每台机器存对应的选票(由应用层的WorkerSender从sendqueue拿的),然后通过SenderWorker线程将每台机器对应的选票通过Socket(BIO)发送出去。
- RecvWorker消息接收线程会将Socket(BIO)接收到的数据转为选票放到recvQueue中,应用层的WorkerReceiver线程就会从这里获取选票放到recvqueue中。
消息传输层为什么要为每个机器都分配一个队列
避免给每台机器发送消息时相互影响,比如某台机器如果出问题发送不成功则不会影响对正常机器的消息发送。
runFromConfig
- createFactory()初始化服务端连接对象:创建NIOServerCnxnFactory(默认)或NettyServerCnxnFactory ,这是用来接收客户端执行命令的,即2181端口
- 获取本服务节点对象quorumPeer
- 将各种配置文件的属性都设置到本服务节点对象quorumPeer
- 设置选举类型(默认为3)
- myid
- 初始化内存数据库对象
- 将CnxnFactory放入本服务节点对象
- quorumPeer.start() 启动
quorumPeer.start() 集群模式服务器启动步骤
- loadDataBase():将快照、日志加到内存中,即初始化DataTree
- startServerCnxnFactory() 启动netty服务:启动AcceptorThread SelectorThread
这里之前创建的是NIOServerCnxnFactory对象就会调用其startup方法,创的是netty就掉的netty,我们这里是看的netty的。- 绑定客户端端口。client发命令是向服务端的2181端口发
- 启动adminServer,启动内嵌jettyserver,默认8080端口,用来查看服务端状态信息
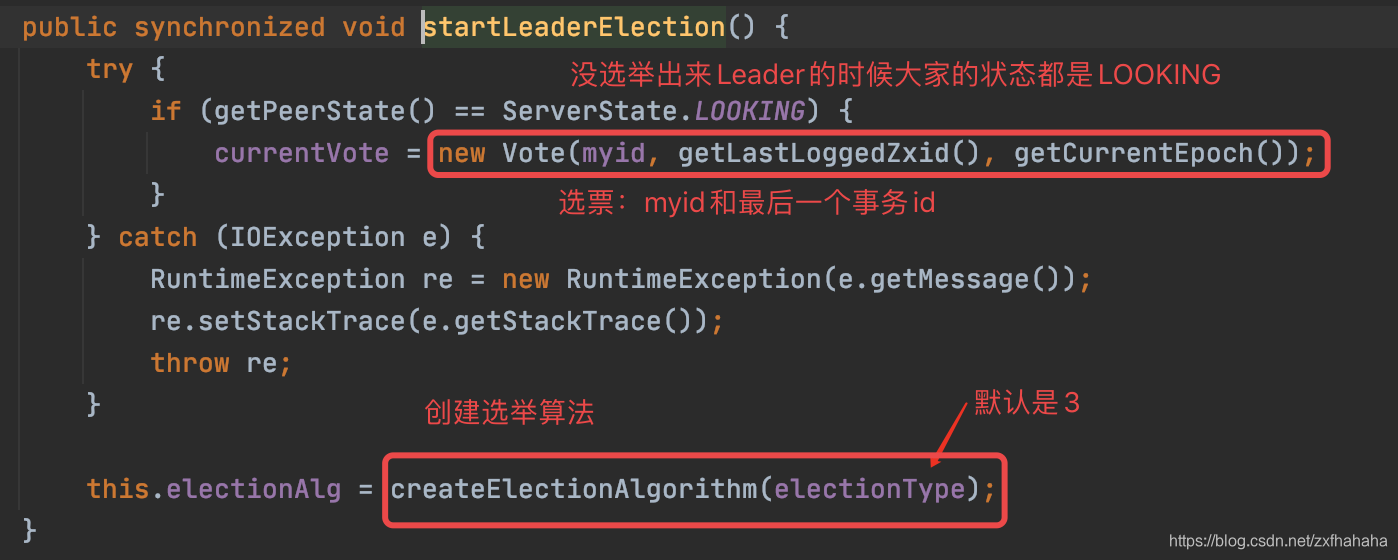
- startLeaderElection() 初始化集群选举Leader相关对象数据
- new 选票
- 创建选举算法
- 初始化数据管理器
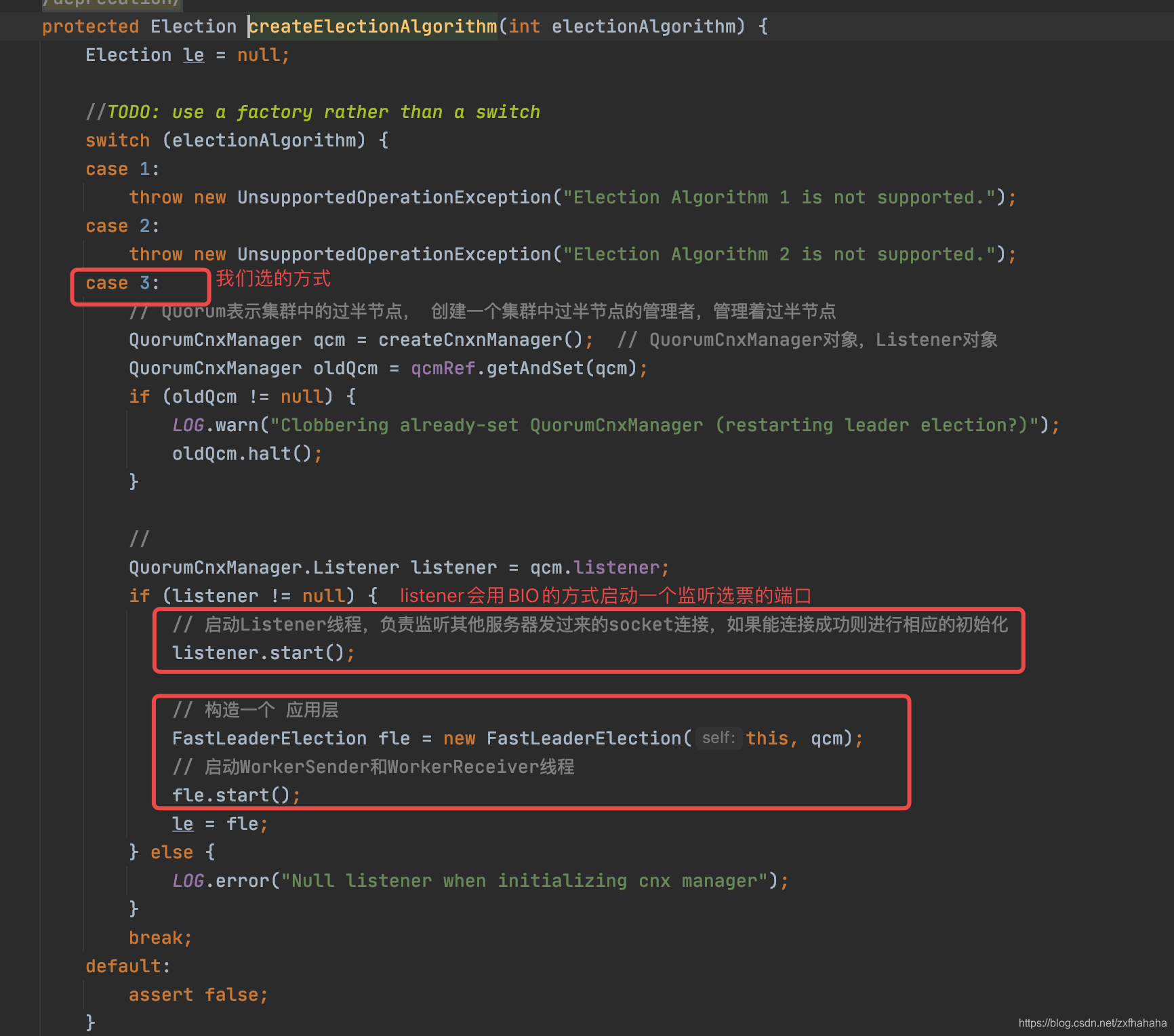
- 启动选举监听listener.start():启动了listener线程通过BIO方式启动一个监听选票的端口
- 启动快速选举算法相关线程:启动了WorkerSender和WorkerReceiver线程
- super.start() 启动集群Leader选举功能:调用本类的run方法,开始进行领导者选举,并开始处理客户端请求
startLeaderElection()
createElectionAlgorithm()
-
listener.start()会用BIO的方式启动一个监听选票的端口,
选票这里是用的ServerSocket即BIO来相互监听发Socket。 这里new ServerSocket绑定在选举端口上,接收选票。 -
用的是FastLeaderElection算法
-
fle.start(): 开启两个线程
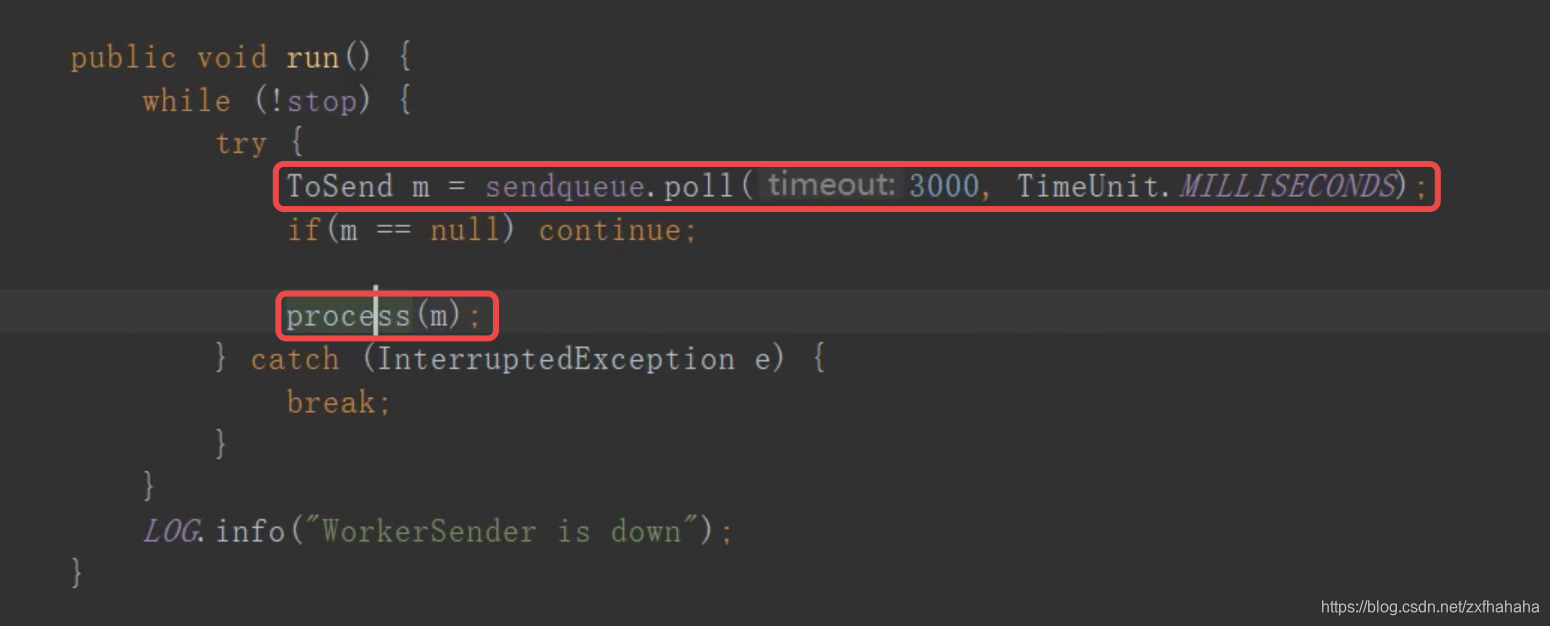
- WorkerSender即wsThread 的run就是从sendqueue里拿到东西然后处理
- WorkerReceiver即wrThread的run就是从recvqueue里拿消息
listener.run()
这里的listener调用的是QuorumCnxManager.Listener的run
- 在选举端口监听连接,选举使用普通的socket通信BIO
- new ServerSocket
- ss.bind(addr) 绑定端口
- 接收连接 ss.accept()
- 拿到对方的sid 会判断哪个大
因为socket通信是双工的也就是只用建立一个通道双方就可以通信了,所以Zookeeper就指定myid大的节点去连接小的节点- 如果对方小直接关掉,反向连接对方
- 对方大,则建立
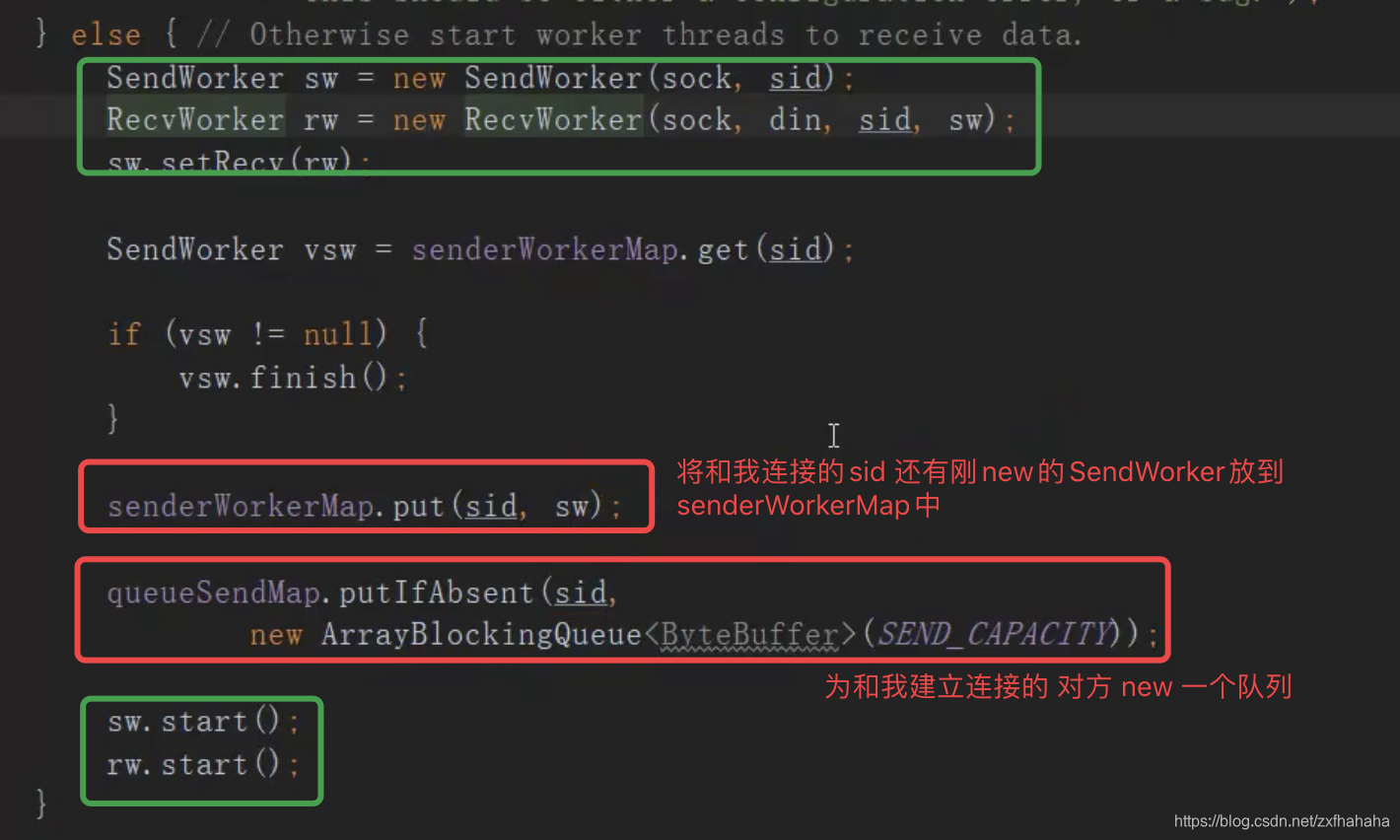
- 拿到对方的sid 会判断哪个大
WorkerSender 和 WorkerReceiver
WorkerSender和WorkerReceiver 是选举应用层的线程,用来负责把选票传出去和获取
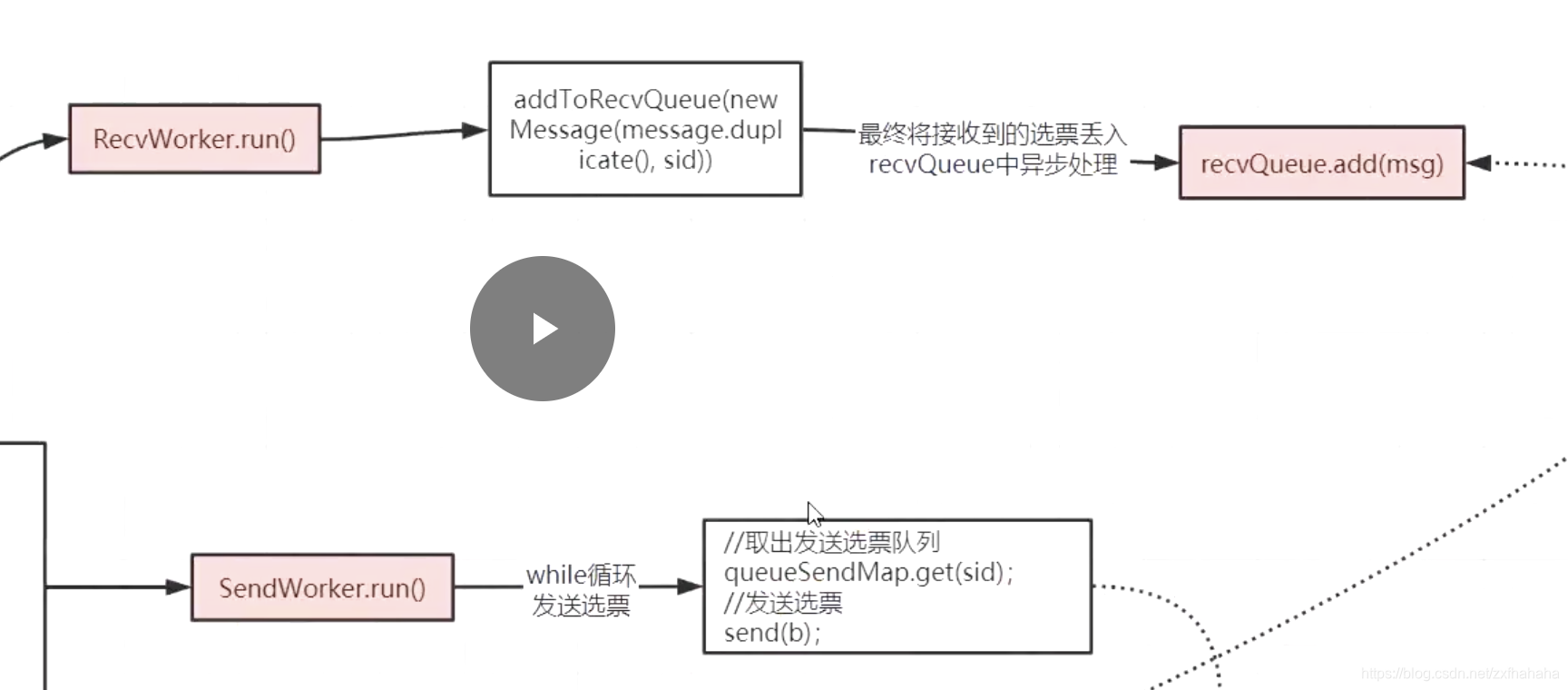
WorkerSender
WorkerSender就是从sendqueue里拿选票,然后生成选票放到queueSendMap队列里对应要发送的sid对应的发送队列
WorkerReceiver
从recvqueue里拿选票
-
没有拿到选票,则和其他机器建立连接
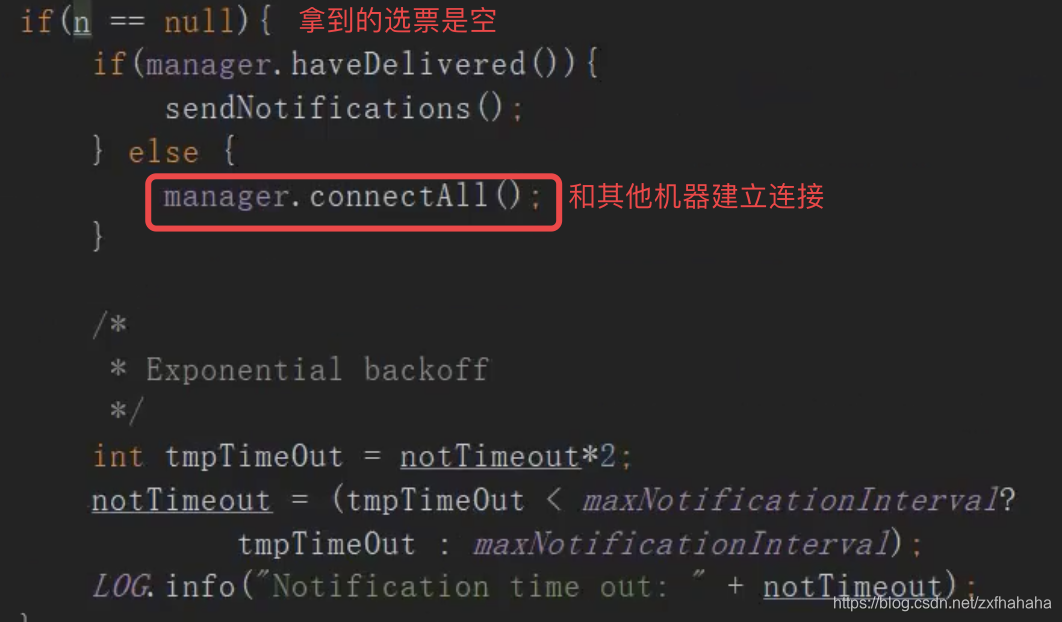
-
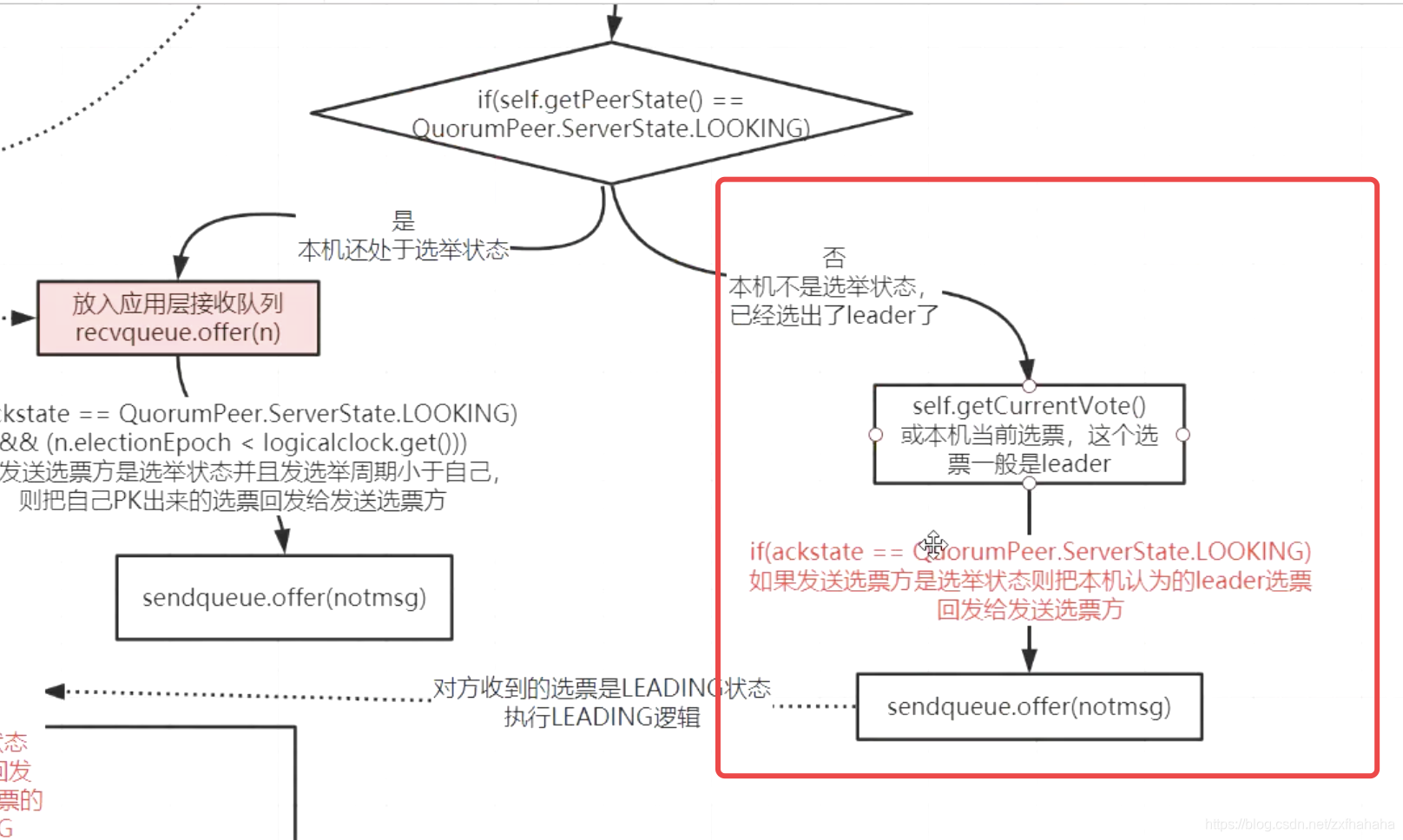
拿到选票,校验选票是否有效根据当前机器状态进行对应处理
- 如果是LOOKING
- 比较当前机器的时钟周期和收到选票的时钟周期
- 相等(最开始肯定是相等的),totalOrderPredicate() 开始pk

如果对方获胜,则updateProposal()更新我要推举的选票为对方且sendNotifications()将要推举的选票发送给所有其他人。更新状态对方为leading自己为following。
并把获胜选票返回
- 相等(最开始肯定是相等的),totalOrderPredicate() 开始pk
- 比较当前机器的时钟周期和收到选票的时钟周期
- 如果是LOOKING
当已经选举出Leader了, 再有新的机器加入,当收到选票后之前的机器就会把之前的获胜选票放到sendqueue里。
super.start() 启动集群Leader选举功能
while死循环根据当前节点状态做对应逻辑处理:
- Looking LookForLeader()
- 选举周期加1
- 初始化选票(自己)
- SendNotifications()发送选票选自己
给所有其他参与投票的节点发送选票,实际是sendqueue.offer 把选票放到阻塞队列 - recvqueue.poll() 从别人发送给我的选票里拿消息
- 一开始这个队列里的选票是空的,所以就去和其他的sid建立Socket连接
- Leading:
- new ServerSocket并开启监听,这个就是用来和其他进行通信的,
- 周期性的向所有的learner(following+observing)发ping,以保持连接
- Following:
找到Leader与Leader建立连接,通过while死循环接收Leader发来的数据,将Leader的数据同步到自己上面
如果接收不到Leader发来的数据了,那就说明Leader挂了,就会把当前状态改成following 就又开始新的选举流程了
sendNotifications()

















 659
659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









