



决策树简介
在分类问题中,表示基于特征对实例进行分类,即定义在特征空间与类空间上的条件概率分布。
**优点:**决策树模型具有可读性,分类速度快,学习时,利用训练数据,根据损失函数最小化的原则。决策树的学习步骤分为:特征选择,决策树的生成,决策树的剪枝。本文主要针对特征选择和决策树的生成展开叙述。
决策树学习的思想主要来源于由Quinlan在1986年提出的ID3和1993年提出的C4.5算法,以及有Breiman等人在1984年提出的CART算法。
**决策树模型:**决策树由节点和有向边组成。内部结点表示一个特征或属性,叶结点表示一个类。、
下图即为决策树模型的示意图。
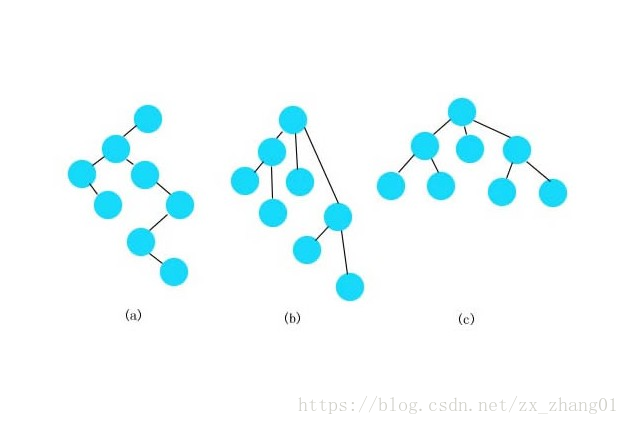
决策树与条件概率分布
假设X为表示特征的随机变量,Y为表示类的随机变量,那么这个条件概率分布可以表示为
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X). X 取值于给定划分下的单元的集合,Y表示取值类的集合,各个叶结点上的取值会偏向某一个概率较大的类,决策树分类是将该结点的样本计算强行分到条件概率较大的那一边。
决策树学习
决策树学习,假定给定训练数据集:
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
,
(
x
N
,
y
N
)
}
D=\left \{ (x_{1},y_{1}),(x_{2},y_{2}),\cdots ,(x_{N},y_{N})\right \}
D={(x1,y1),(x2,y2),⋯,(xN,yN)},其中
x
i
=
(
x
i
1
,
x
i
2
,
⋯
,
x
i
n
)
T
x_{i}=\left ( x_{i}^{1} ,x_{i}^{2},\cdots ,x_{i}^{n}\right )^{T}
xi=(xi1,xi2,⋯,xin)T为输入的样本,n代表特征的个数,
y
i
ϵ
{
1
,
2
,
⋯
,
K
}
y_{i}\epsilon \left \{ 1,2,\cdots ,K \right \}
yiϵ{1,2,⋯,K}为类的标记,
i
=
1
,
2
,
⋯
,
N
i=1,2,\cdots ,N
i=1,2,⋯,N,N为样本的容量,学习的目标是根据使决策树的损失函数为目标函数使其最小化,利用给定的训练集建一个决策树模型,使它能够对测试数据进行较好的分类。对未知的数据可能不会有较好的分类能力,最大可能就是发生过拟合(即受测试数据的“异常数据”的影响较大),在决策树中可以对其进行自下而上进行剪枝,本文不对此进行讨论,如诺感兴,敬请等待后续文章。
决策树是一个基于条件概率的分类模型,所以决策树的复杂度直接受决策树的大小影响,且对应局部最优解,决策树的剪枝对应全局最优解。
特征的选择
特征的选择在某种程度上直接决定着决策树的泛化能力,通常在决策树中的特征选择主要依靠于信息增益或者信息增益比(C4.5算法)
信息增益
再介绍信息增益之前,先简单的介绍一下熵和条件熵。
熵:表示随机变量不确定性,设x是一个取有限个值得离散随机变量其概率分布为
=p_{i}, i=1,2,\cdots ,n")
则随机变量的熵定义为
=-\sum_{i=1}^{n}p_{i}\log p_{i}")
\leq \log n") 。 条件熵:
。 条件熵:
") 表示在已知随机变量X的情况下随机变量Y的不确定性。定义为X给定条件下Y的条件概率分布分熵对X的数学期望:
表示在已知随机变量X的情况下随机变量Y的不确定性。定义为X给定条件下Y的条件概率分布分熵对X的数学期望:
=\sum_{i=1}^{n}p_{i}H\left ( Y|X=x_{i} \right )")
,i=1,2,\cdots ,n.") . 信息增益表示得知特征X的信息后降低类别Y的信息的不确定性。 定义:信息增益:特征A对训练数据集D的信息增益
. 信息增益表示得知特征X的信息后降低类别Y的信息的不确定性。 定义:信息增益:特征A对训练数据集D的信息增益
") ,定义为集合D的经验熵
,定义为集合D的经验熵
") 与特征A给定条件下的经验条件熵
与特征A给定条件下的经验条件熵
") 之差,即
之差,即
=H\left ( D \right )-H\left ( D|A \right )")
 ,
,
 ,
,
 表示属于第k类的样本个数,其中
表示属于第k类的样本个数,其中
 , 设特征A有n个不同的取值
, 设特征A有n个不同的取值
 ,根据特征A的取值将D划分为n个子集
,根据特征A的取值将D划分为n个子集
 ,
,
 表示属于第i个特征的样本个数,其中
表示属于第i个特征的样本个数,其中
 ,子集
,子集
 中属于第k类的样本表示为
中属于第k类的样本表示为
 , 即
, 即
 ,
,
 表示为
的样本个数。 **信息增益的计算:** (1) 计算机数据集D的经验熵
表示为
的样本个数。 **信息增益的计算:** (1) 计算机数据集D的经验熵
=-\sum_{k=1}^{K}\frac{|C_{k}|}{|D|}\log \frac{|C_{k}|}{|D|}")
\sum_{i=1}^{n}\frac{|D_{i}|}{|D|}H\left ( D_{i} \right )=-\sum_{i=1}^{n}\frac{|D_{i}|}{|D|}\sum_{k=1}^{K}\frac{|D_{ik}|}{|D_{i}|}\log _{2}\frac{|D_{ik}|}{|D_{i}|}")
讲过原理之后,我们就拿身边的一些事情开刀喽!
下表是一个有12个样本组成的逃课样本数据
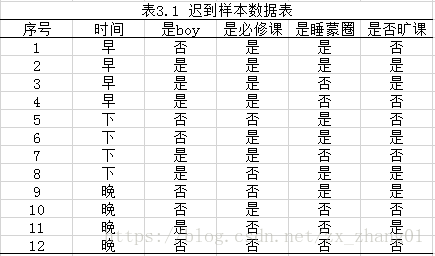
对表所给出的数据集D,根据信息增益的原则选择出特征最优
计算信息熵:
=1")
 表示时间,是否是boy,是主修课,是睡蒙圈4个特征 (1)
表示时间,是否是boy,是主修课,是睡蒙圈4个特征 (1)
=H\left ( D \right )-\frac{1}{3}\left ( -\frac{1}{2}\log _{2}\frac{1}{2}-\frac{1}{2}\log _{2}\frac{1}{2} \right )")
")
 分别是D取值为早,中,晚的样本的子集。 (2)
分别是D取值为早,中,晚的样本的子集。 (2)
=H\left ( D \right )-\frac{7}{12}\left ( -\frac{4}{7}\log _{2}\frac{3}{7}-\frac{3}{7}\log _{2}\frac{3}{7} \right )")
")
=H\left ( D \right )-\frac{7}{12}\left ( -\frac{4}{7}\log _{2}\frac{4}{7}-\frac{4}{7}\log _{2}\frac{4}{7} \right )")
")
=H\left ( D \right )-H\left ( D|A_{4} \right )=1-0.0918=0.082") 最后比较各特征的信息增益的大小,由于特征
最后比较各特征的信息增益的大小,由于特征
 (代表是否睡蒙圈)的信息增值最大,所以选择其作为最优特征,由此可见在是否是必修课的情况下,睡蒙圈占有了主导地位,所以希望老师可以体谅我们一下,不是我们不爱学习。
(代表是否睡蒙圈)的信息增值最大,所以选择其作为最优特征,由此可见在是否是必修课的情况下,睡蒙圈占有了主导地位,所以希望老师可以体谅我们一下,不是我们不爱学习。

















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









