 目标检测与边界框绘制
目标检测与边界框绘制




 本文介绍了目标检测的基础概念,并详细讲解了如何在图像中绘制边界框来定位目标物体,如猫和狗,通过matplotlib库实现边界框的可视化。
本文介绍了目标检测的基础概念,并详细讲解了如何在图像中绘制边界框来定位目标物体,如猫和狗,通过matplotlib库实现边界框的可视化。
一、目标检测基础
9.3 目标检测和边界框¶
%matplotlib inline
from PIL import Image
import sys
sys.path.append('/home/kesci/input/')
import d2lzh1981 as d2l# 展示用于目标检测的图
d2l.set_figsize()
img = Image.open('/home/kesci/input/img2083/img/catdog.jpg')
d2l.plt.imshow(img); # 加分号只显示图 
9.3.1 边界框
# bbox是bounding box的缩写
dog_bbox, cat_bbox = [60, 45, 378, 516], [400, 112, 655, 493]def bbox_to_rect(bbox, color): # 本函数已保存在d2lzh_pytorch中方便以后使用
# 将边界框(左上x, 左上y, 右下x, 右下y)格式转换成matplotlib格式:
# ((左上x, 左上y), 宽, 高)
return d2l.plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'));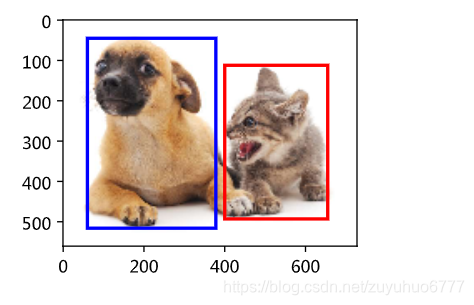

















 2650
2650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









