







 本文深入探讨了Spark中distinct算子的工作原理,通过源码分析揭示了其如何去除重复元素,提供了具体示例代码,展示了如何使用distinct算子进行数据去重。
本文深入探讨了Spark中distinct算子的工作原理,通过源码分析揭示了其如何去除重复元素,提供了具体示例代码,展示了如何使用distinct算子进行数据去重。
distinct算子原理:
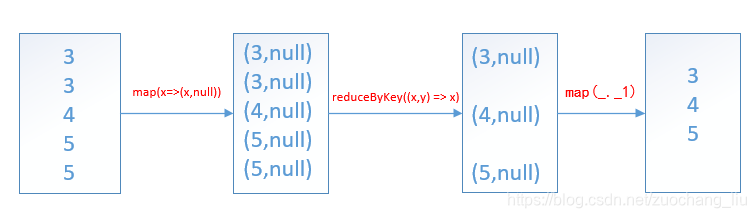
贴上spark源码:
/**
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
}
示例代码:
package com.wedoctor.utils.test
import org.apache.log4j.{Level, Logger}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object Test {
Logger.getLogger("org").setLevel(Level.ERROR)
def main(args: Array[String]): Unit = {
//本地环境需要加上
System.setProperty("HADOOP_USER_NAME", "root")
val session: SparkSession = SparkSession.builder()
.master("local[*]")
.appName(this.getClass.getSimpleName)
.getOrCreate()
val value: RDD[Int] = session.sparkContext.makeRDD(Array(3,3,4,5,5))
value.distinct().foreach(println)
//等价于
value.map(x=>(x,null)).reduceByKey((x,y) => x).map(_._1).foreach(println)
session.close()
}
}
===============================================================================================
以后博客的内容都是通过微信公众号链接的形式发布,之后迁移到公众号的文章都会重新修正,也更加详细,对于以前博客内容里面的错误或者理解不当的地方都会在公众号里面修正。
欢迎关注我的微信公众号,以后我会发布更多工作中总结的技术内容。



















 2866
2866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











