




Linux内存管理14(基于6.1内核)---alloc_page分配内存空间
一、内存分配API
1.1 内存分配器API
就伙伴系统的接口而言, NUMA或UMA体系结构是没有差别的, 二者的调用语法都是相同的.
所有函数的一个共同点是 : 只能分配2的整数幂个页.
因此,接口中不像C标准库的malloc函数或bootmem和memblock分配器那样指定了所需内存大小作为参数. 相反, 必须指定的是分配阶, 伙伴系统将在内存中分配2order2order页. 内核中细粒度的分配只能借助于slab分配器(或者slub、slob分配器), 后者基于伙伴系统。
|
内存分配函数 |
功能 |
|
alloc_pages(mask, order) |
分配2order2order页并返回一个struct page的实例,表示分配的内存块的起始页 |
|
alloc_page(mask) |
是前者在order = 0情况下的简化形式,只分配一页 |
|
get_zeroed_page(mask) |
分配一页并返回一个page实例,页对应的内存填充0(所有其他函数,分配之后页的内容是未定义的) |
|
__get_free_pages(mask, order) |
工作方式与上述函数相同,但返回分配内存块的虚拟地址,而不是page实例 |
|
get_dma_pages(gfp_mask, order) |
用来获得适用于DMA的页. |
在空闲内存无法满足请求以至于分配失败的情况下,所有上述函数都返回空指针(比如alloc_pages和alloc_page)或者0(比如get_zeroed_page、__get_free_pages和__get_free_page).
因此内核在各次分配之后都必须检查返回的结果. 这种惯例与设计得很好的用户层应用程序没什么不同, 但在内核中忽略检查会导致严重得多的故障。
内核除了伙伴系统函数之外, 还提供了其他内存管理函数. 它们以伙伴系统为基础, 但并不属于伙伴分配器自身. 这些函数包括vmalloc和vmalloc_32, 使用页表将不连续的内存映射到内核地址空间中, 使之看上去是连续的。
还有一组kmalloc类型的函数, 用于分配小于一整页的内存区. 其实现将在以后分别讨论。
1.2 内存分配API统一到alloc_pages接口
通过使用标志、内存域修饰符和各个分配函数,内核提供了一种非常灵活的内存分配体系.尽管如此, 所有接口函数都可以追溯到一个简单的基本函数(alloc_pages_node)
分配单页的函数include/linux/gfp.h
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
#define __get_free_page(gfp_mask) \
__get_free_pages((gfp_mask), 0)`
#define __get_dma_pages(gfp_mask, order) \
__get_free_pages((gfp_mask) | GFP_DMA, (order))
get_zeroed_page实现也没什么困难, 对__get_free_pages使用__GFP_ZERO标志,即可分配填充字节0的页. 再返回与页关联的内存区地址即可.mm/page_alloc.c
unsigned long get_zeroed_page(gfp_t gfp_mask)
{
return __get_free_pages(gfp_mask | __GFP_ZERO, 0);
}
EXPORT_SYMBOL(get_zeroed_page);
__get_free_pages调用alloc_pages完成内存分配, 而alloc_pages又借助于alloc_pages_node
__get_free_pages函数的定义.mm/page_alloc.c
/*
* Common helper functions. Never use with __GFP_HIGHMEM because the returned
* address cannot represent highmem pages. Use alloc_pages and then kmap if
* you need to access high mem.
*/
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
page = alloc_pages(gfp_mask & ~__GFP_HIGHMEM, order);
if (!page)
return 0;
return (unsigned long) page_address(page);
}
EXPORT_SYMBOL(__get_free_pages);
在这种情况下, 使用了一个普通函数而不是宏, 因为alloc_pages返回的page实例需要使用辅助函数page_address转换为内存地址. 在这里,只要知道该函数可根据page实例计算相关页的线性内存地址即可. 对高端内存页这是有问题的。这样, 就完成了所有分配内存的API函数到公共的基础函数alloc_pages的统一。
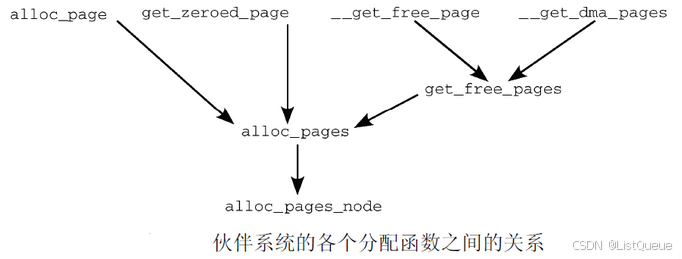
1.2 alloc_pages函数分配页
既然所有的内存分配API函数都可以追溯掉alloc_page函数, 从某种意义上说,该函数是伙伴系统主要实现的”发射台”.
alloc_pages函数的定义是依赖于NUMA或者UMA架构的, 定义如下:
#ifdef CONFIG_NUMA
...
static inline struct page *
alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}
#else
...
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order)
#endif
UMA结构下的alloc_pages是通过alloc_pages_node函数实现的, 下面我们看看alloc_pages_node函数的定义include/linux/gfp.h
/*
* Allocate pages, preferring the node given as nid. When nid == NUMA_NO_NODE,
* prefer the current CPU's closest node. Otherwise node must be valid and
* online.
*/
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
if (nid == NUMA_NO_NODE)
nid = numa_mem_id();
return __alloc_pages_node(nid, gfp_mask, order);
}
它只是执行了一个简单的检查, 如果指定负的结点ID(不存在, NUMA_NO_NODE = -1), 内核自动地使用当前执行CPU对应的结点nid =numa_mem_id()然后调用__alloc_pages_node函数进行了内存分配
__alloc_pages_node函数定义include/linux/gfp.h
/*
* Allocate pages, preferring the node given as nid. The node must be valid and
* online. For more general interface, see alloc_pages_node().
*/
static inline struct page *
__alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order)
{
VM_BUG_ON(nid < 0 || nid >= MAX_NUMNODES);
warn_if_node_offline(nid, gfp_mask);
return __alloc_pages(gfp_mask, order, nid, NULL);
}
内核假定传递给改alloc_pages_node函数的结点nid是被激活, 即online的.但是为了安全它还是检查并警告内存结点不存在的情况. 接下来的工作委托给__alloc_pages, 只需传递一组适当的参数, 其中包括节点nid的备用内存域列表zonelist。
现在__alloc_pages函数没什么特别的, 它直接将自己的所有信息传递给。__alloc_pages_nodemask来完成内存的分配。
struct page *__alloc_pages(gfp_t gfp, unsigned int order, int preferred_nid,
nodemask_t *nodemask);
1.3 伙伴系统的心脏__alloc_pages_nodemask
内核源代码将__alloc_pages_nodemask称之为”伙伴系统的心脏”(`the ‘heart’ of the zoned buddy allocator“), 因为它处理的是实质性的内存分配.
由于”心脏”的重要性, __alloc_pages函数定义mm/page_alloc.c
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *__alloc_pages(gfp_t gfp, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
struct page *page;
unsigned int alloc_flags = ALLOC_WMARK_LOW;
gfp_t alloc_gfp; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = { };
/*
* There are several places where we assume that the order value is sane
* so bail out early if the request is out of bound.
*/
if (WARN_ON_ONCE_GFP(order > MAX_ORDER, gfp))
return NULL;
gfp &= gfp_allowed_mask;
/*
* Apply scoped allocation constraints. This is mainly about GFP_NOFS
* resp. GFP_NOIO which has to be inherited for all allocation requests
* from a particular context which has been marked by
* memalloc_no{fs,io}_{save,restore}. And PF_MEMALLOC_PIN which ensures
* movable zones are not used during allocation.
*/
gfp = current_gfp_context(gfp);
alloc_gfp = gfp;
if (!prepare_alloc_pages(gfp, order, preferred_nid, nodemask, &ac,
&alloc_gfp, &alloc_flags))
return NULL;
/*
* Forbid the first pass from falling back to types that fragment
* memory until all local zones are considered.
*/
alloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp);
/* First allocation attempt */
page = get_page_from_freelist(alloc_gfp, order, alloc_flags, &ac);
if (likely(page))
goto out;
alloc_gfp = gfp;
ac.spread_dirty_pages = false;
/*
* Restore the original nodemask if it was potentially replaced with
* &cpuset_current_mems_allowed to optimize the fast-path attempt.
*/
ac.nodemask = nodemask;
page = __alloc_pages_slowpath(alloc_gfp, order, &ac);
out:
if (memcg_kmem_online() && (gfp & __GFP_ACCOUNT) && page &&
unlikely(__memcg_kmem_charge_page(page, gfp, order) != 0)) {
__free_pages(page, order);
page = NULL;
}
trace_mm_page_alloc(page, order, alloc_gfp, ac.migratetype);
kmsan_alloc_page(page, order, alloc_gfp);
return page;
}
EXPORT_SYMBOL(__alloc_pages);
二、选择页
页面选择是如何工作的?
2.1 内存水印标志
还记得之前讲过的内存水印么
enum zone_watermarks {
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
WMARK_PROMO,
NR_WMARK
};
/*
* One per migratetype for each PAGE_ALLOC_COSTLY_ORDER. One additional list
* for THP which will usually be GFP_MOVABLE. Even if it is another type,
* it should not contribute to serious fragmentation causing THP allocation
* failures.
*/
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
#define NR_PCP_THP 1
#else
#define NR_PCP_THP 0
#endif
#define NR_LOWORDER_PCP_LISTS (MIGRATE_PCPTYPES * (PAGE_ALLOC_COSTLY_ORDER + 1))
#define NR_PCP_LISTS (NR_LOWORDER_PCP_LISTS + NR_PCP_THP)
#define min_wmark_pages(z) (z->_watermark[WMARK_MIN] + z->watermark_boost)
#define low_wmark_pages(z) (z->_watermark[WMARK_LOW] + z->watermark_boost)
#define high_wmark_pages(z) (z->_watermark[WMARK_HIGH] + z->watermark_boost)
#define wmark_pages(z, i) (z->_watermark[i] + z->watermark_boost)
内核需要定义一些函数使用的标志,用于控制到达各个水印指定的临界状态时的行为, 这些标志用宏来定义, include/linux/mmzone.h
2.2 zone_watermark_ok函数检查标志
设置的标志在zone_watermark_ok函数中检查, 该函数根据设置的标志判断是否能从给定的内存域分配内存. mm/page_alloc.c
bool zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,
int highest_zoneidx, unsigned int alloc_flags)
{
return __zone_watermark_ok(z, order, mark, highest_zoneidx, alloc_flags,
zone_page_state(z, NR_FREE_PAGES));
}
而__zone_watermark_ok函数则完成了检查的工作, 该函数定义在mm/page_alloc.c
/*
* Return true if free base pages are above 'mark'. For high-order checks it
* will return true of the order-0 watermark is reached and there is at least
* one free page of a suitable size. Checking now avoids taking the zone lock
* to check in the allocation paths if no pages are free.
*/
bool __zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,
int highest_zoneidx, unsigned int alloc_flags,
long free_pages)
{
long min = mark;
int o;
/* free_pages may go negative - that's OK */
free_pages -= __zone_watermark_unusable_free(z, order, alloc_flags);
if (unlikely(alloc_flags & ALLOC_RESERVES)) {
/*
* __GFP_HIGH allows access to 50% of the min reserve as well
* as OOM.
*/
if (alloc_flags & ALLOC_MIN_RESERVE) {
min -= min / 2;
/*
* Non-blocking allocations (e.g. GFP_ATOMIC) can
* access more reserves than just __GFP_HIGH. Other
* non-blocking allocations requests such as GFP_NOWAIT
* or (GFP_KERNEL & ~__GFP_DIRECT_RECLAIM) do not get
* access to the min reserve.
*/
if (alloc_flags & ALLOC_NON_BLOCK)
min -= min / 4;
}
/*
* OOM victims can try even harder than the normal reserve
* users on the grounds that it's definitely going to be in
* the exit path shortly and free memory. Any allocation it
* makes during the free path will be small and short-lived.
*/
if (alloc_flags & ALLOC_OOM)
min -= min / 2;
}
/*
* Check watermarks for an order-0 allocation request. If these
* are not met, then a high-order request also cannot go ahead
* even if a suitable page happened to be free.
*/
if (free_pages <= min + z->lowmem_reserve[highest_zoneidx])
return false;
/* If this is an order-0 request then the watermark is fine */
if (!order)
return true;
/* For a high-order request, check at least one suitable page is free */
for (o = order; o <= MAX_ORDER; o++) {
struct free_area *area = &z->free_area[o];
int mt;
if (!area->nr_free)
continue;
for (mt = 0; mt < MIGRATE_PCPTYPES; mt++) {
if (!free_area_empty(area, mt))
return true;
}
#ifdef CONFIG_CMA
if ((alloc_flags & ALLOC_CMA) &&
!free_area_empty(area, MIGRATE_CMA)) {
return true;
}
#endif
if ((alloc_flags & (ALLOC_HIGHATOMIC|ALLOC_OOM)) &&
!free_area_empty(area, MIGRATE_HIGHATOMIC)) {
return true;
}
}
return false;
}
zone_page_state来访问每个内存域的统计量. 在上述代码中, 得到的是空闲页的数目。
free_pages -= zone_page_state(z, NR_FREE_CMA_PAGES);
在解释了ALLOC_HIGH和ALLOC_HARDER标志之后(将最小值标记降低到当前值的一半或四分之一,使得分配过程努力或更加努力)。
if (alloc_flags & ALLOC_HIGH)
min -= min / 2;
if (likely(!alloc_harder))
free_pages -= z->nr_reserved_highatomic;
else
min -= min / 4;
该函数会检查空闲页的数目free_pages是否小于最小值lowmem_reserve指定的紧急分配值min之和。
if (free_pages <= min + z->lowmem_reserve[classzone_idx])
return false;
如果不小于, 则代码遍历所有小于当前阶的分配阶, 其中nr_free记载的是当前分配阶的空闲页块数目。
/* For a high-order request, check at least one suitable page is free */
for (o = order; o < MAX_ORDER; o++) {
struct free_area *area = &z->free_area[o];
int mt;
if (!area->nr_free)
continue;
if (alloc_harder)
return true;
for (mt = 0; mt < MIGRATE_PCPTYPES; mt++) {
if (!list_empty(&area->free_list[mt]))
return true;
}
#ifdef CONFIG_CMA
if ((alloc_flags & ALLOC_CMA) &&
!list_empty(&area->free_list[MIGRATE_CMA])) {
return true;
}
#endif
}
如果内核遍历所有的低端内存域之后,发现内存不足, 则不进行内存分配.
2.3 get_page_from_freelist函数
get_page_from_freelist是伙伴系统使用的另一个重要的辅助函数. 它通过标志集和分配阶来判断是否能进行分配。如果可以,则发起实际的分配操作. 该函数定义mm/page_alloc.c
这个函数的参数很有意思, 之前的时候这个函数的参数只能用复杂来形容
static struct page *
get_page_from_freelist(gfp_t gfp_mask, nodemask_t *nodemask, unsigned int order,
struct zonelist *zonelist, int high_zoneidx, int alloc_flags,
struct zone *preferred_zone, int migratetype)
但是这仍然不够, 随着内核的不段改进, 所支持的特性也越多, 分配内存时需要参照的标识也越来越多, 那难道看着这个函数的参数不断膨胀么, 这个不是内核黑客们所能容忍的, 于是大家想出了一个解决方案, 把那些相关联的参数封装成一个结构
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags, const struct alloc_context *ac)
这个封装好的结构struct alloc_context mm/internal.h
/*
* Structure for holding the mostly immutable allocation parameters passed
* between functions involved in allocations, including the alloc_pages*
* family of functions.
*
* nodemask, migratetype and high_zoneidx are initialized only once in
* __alloc_pages_nodemask() and then never change.
*
* zonelist, preferred_zone and classzone_idx are set first in
* __alloc_pages_nodemask() for the fast path, and might be later changed
* in __alloc_pages_slowpath(). All other functions pass the whole strucure
* by a const pointer.
*/
struct alloc_context {
struct zonelist *zonelist;
nodemask_t *nodemask;
struct zoneref *preferred_zoneref;
int migratetype;
enum zone_type high_zoneidx;
bool spread_dirty_pages;
};
| 字段 | 描述 |
|---|---|
| zonelist | 当perferred_zone上没有合适的页可以分配时,就要按zonelist中的顺序扫描该zonelist中备用zone列表,一个个的试用 |
| nodemask | 表示节点的mask,就是是否能在该节点上分配内存,这是个bit位数组 |
| preferred_zone | 表示从high_zoneidx后找到的合适的zone,一般会从该zone分配;分配失败的话,就会在zonelist再找一个preferred_zone = 合适的zone |
| migratetype | 迁移类型,在zone->free_area.free_list[XXX] 作为分配下标使用,这个是用来反碎片化的,修改了以前的free_area结构体,在该结构体中再添加了一个数组,该数组以迁移类型为下标,每个数组元素都挂了对应迁移类型的页链表 |
| high_zoneidx | 是表示该分配时,所能分配的最高zone,一般从high–>normal–>dma 内存越来越昂贵,所以一般从high到dma分配依次分配 |
| spread_dirty_pages |
zonelist是指向备用列表的指针. 在预期内存域没有空闲空间的情况下, 该列表确定了扫描系统其他内存域(和结点)的顺序。
随后的for循环所作的基本上与直觉一致, 遍历备用列表的所有内存域,用最简单的方式查找一个适当的空闲内存块。
-
首先,解释ALLOC_*标志(__cpuset_zone_allowed_softwall是另一个辅助函数, 用于检查给定内存域是否属于该进程允许运行的CPU)。
-
zone_watermark_ok接下来检查所遍历到的内存域是否有足够的空闲页,并试图分配一个连续内存块。如果两个条件之一不能满足,即或者没有足够的空闲页,或者没有连续内存块可满足分配请求,则循环进行到备用列表中的下一个内存域,作同样的检查. 直到找到一个合适的页面, 在进行try_this_node进行内存分配。
-
如果内存域适用于当前的分配请求, 那么buffered_rmqueue试图从中分配所需数目的页。
/*
* get_page_from_freelist goes through the zonelist trying to allocate
* a page.
*/
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z;
struct zone *zone;
struct pglist_data *last_pgdat = NULL;
bool last_pgdat_dirty_ok = false;
bool no_fallback;
retry:
/*
* Scan zonelist, looking for a zone with enough free.
* See also cpuset_node_allowed() comment in kernel/cgroup/cpuset.c.
*/
no_fallback = alloc_flags & ALLOC_NOFRAGMENT;
z = ac->preferred_zoneref;
for_next_zone_zonelist_nodemask(zone, z, ac->highest_zoneidx,
ac->nodemask) {
struct page *page;
unsigned long mark;
if (cpusets_enabled() &&
(alloc_flags & ALLOC_CPUSET) &&
!__cpuset_zone_allowed(zone, gfp_mask))
continue;
/*
* When allocating a page cache page for writing, we
* want to get it from a node that is within its dirty
* limit, such that no single node holds more than its
* proportional share of globally allowed dirty pages.
* The dirty limits take into account the node's
* lowmem reserves and high watermark so that kswapd
* should be able to balance it without having to
* write pages from its LRU list.
*
* XXX: For now, allow allocations to potentially
* exceed the per-node dirty limit in the slowpath
* (spread_dirty_pages unset) before going into reclaim,
* which is important when on a NUMA setup the allowed
* nodes are together not big enough to reach the
* global limit. The proper fix for these situations
* will require awareness of nodes in the
* dirty-throttling and the flusher threads.
*/
if (ac->spread_dirty_pages) {
if (last_pgdat != zone->zone_pgdat) {
last_pgdat = zone->zone_pgdat;
last_pgdat_dirty_ok = node_dirty_ok(zone->zone_pgdat);
}
if (!last_pgdat_dirty_ok)
continue;
}
if (no_fallback && nr_online_nodes > 1 &&
zone != ac->preferred_zoneref->zone) {
int local_nid;
/*
* If moving to a remote node, retry but allow
* fragmenting fallbacks. Locality is more important
* than fragmentation avoidance.
*/
local_nid = zone_to_nid(ac->preferred_zoneref->zone);
if (zone_to_nid(zone) != local_nid) {
alloc_flags &= ~ALLOC_NOFRAGMENT;
goto retry;
}
}
mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK);
if (!zone_watermark_fast(zone, order, mark,
ac->highest_zoneidx, alloc_flags,
gfp_mask)) {
int ret;
if (has_unaccepted_memory()) {
if (try_to_accept_memory(zone, order))
goto try_this_zone;
}
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* Watermark failed for this zone, but see if we can
* grow this zone if it contains deferred pages.
*/
if (deferred_pages_enabled()) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
/* Checked here to keep the fast path fast */
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
if (!node_reclaim_enabled() ||
!zone_allows_reclaim(ac->preferred_zoneref->zone, zone))
continue;
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
switch (ret) {
case NODE_RECLAIM_NOSCAN:
/* did not scan */
continue;
case NODE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
if (zone_watermark_ok(zone, order, mark,
ac->highest_zoneidx, alloc_flags))
goto try_this_zone;
continue;
}
}
try_this_zone:
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
if (page) {
prep_new_page(page, order, gfp_mask, alloc_flags);
/*
* If this is a high-order atomic allocation then check
* if the pageblock should be reserved for the future
*/
if (unlikely(alloc_flags & ALLOC_HIGHATOMIC))
reserve_highatomic_pageblock(page, zone);
return page;
} else {
if (has_unaccepted_memory()) {
if (try_to_accept_memory(zone, order))
goto try_this_zone;
}
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/* Try again if zone has deferred pages */
if (deferred_pages_enabled()) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
}
}
/*
* It's possible on a UMA machine to get through all zones that are
* fragmented. If avoiding fragmentation, reset and try again.
*/
if (no_fallback) {
alloc_flags &= ~ALLOC_NOFRAGMENT;
goto retry;
}
return NULL;
}
三、分配控制总结
在 Linux 6.1 内核 中,伙伴系统(Buddy System)负责内存分配和回收的控制,主要通过 page allocator(页分配器)管理。以下是关于 伙伴系统分配控制函数 的总结,涵盖其核心函数和它们在内存分配中的作用。
伙伴系统内存分配的核心函数
Linux 6.1 内核中的伙伴系统函数分为几个主要部分,主要用于内存的分配、释放和合并操作。以下是关键的控制函数:
__alloc_pages()
这是内核中分配页面的核心函数,负责根据请求分配一定数量的页面,并返回相应的页面指针。
- 功能:从伙伴系统中分配一组连续的页面(通常是2的幂次方大小的页面)。
- 参数:
gfp_mask:用于指定内存分配的标志,控制内存分配的行为,如是否允许阻塞、是否允许访问低内存等。order:指定请求的页面块的“订单”,即需要的页面块大小是 2 的order次方(例如,order = 0对应一个页面,order = 1对应两个页面,依此类推)。
- 内部实现:
- 查找合适大小的空闲块;
- 如果没有找到,则递归地向上查找更大的空闲块;
- 如果找到合适的块,则进行分配。
alloc_pages()
alloc_pages() 是 __alloc_pages() 的封装函数,提供更高层的接口供内核模块调用。
- 功能:提供用户级的内存分配接口,允许指定内存分配的标志和大小。
- 常见用法:在内核中用于分配内存页,传递
GFP_KERNEL标志来进行常规内存分配。
free_pages()
free_pages() 用于释放之前通过 alloc_pages() 或 __alloc_pages() 分配的页面。
- 功能:将一组页面释放回伙伴系统,以便后续的内存请求复用。
- 参数:
addr:要释放的页面的起始地址。order:释放的内存块的大小,与alloc_pages()中的order参数一致。
__free_pages()
这是 free_pages() 的底层实现,直接与伙伴系统的空闲块进行交互,处理合并空闲块等操作。
- 功能:将释放的页面合并回空闲链表,并在需要时尝试合并相邻的空闲块。
- 内部实现:检查释放页面的伙伴是否为空闲状态,如果是则合并这些块,直至无法合并为止。
split_page()
在内存分配时,如果请求的内存比现有空闲块大,就会触发块的拆分。split_page() 用于拆分内存块。
- 功能:将大块内存分割成两个小块,以适应内存请求。
- 内部实现:递归拆分大块,直到找到合适大小的块。
try_to_free_pages()
try_to_free_pages() 尝试通过回收页帧来满足内存分配请求,通常在内存不足时调用。
- 功能:释放空闲页框来满足内存请求,如果当前没有足够的空闲页,调用此函数尝试清理缓存、回收页帧。
伙伴系统的内存分配与释放
伙伴系统的核心思想是管理内存页的分配和释放。内核通过 page allocator 来分配和回收页面,并通过 order 来控制分配页面的大小。
内存分配(Allocation)
内存分配的关键步骤包括:
- 查找合适的空闲块:通过
__alloc_pages()或alloc_pages()查找合适大小的内存块。分配时会选择合适的order(页面块大小),在伙伴系统中逐级查找更大块的空闲内存,直到找到合适的块。 - 分割大块内存:如果请求的内存较小,但只有更大的内存块可用,系统会通过
split_page()将大的内存块拆分为更小的块,直到满足请求大小。 - 分配内存并标记为已用:分配内存后,将内存块标记为已分配。
内存释放(Freeing)
内存释放的关键步骤包括:
- 合并空闲块:通过
free_pages()或__free_pages()将释放的页面返回伙伴系统。如果释放的内存块有相邻的伙伴块且也为空闲状态,系统会将这两个块合并,形成一个更大的块。 - 递归合并:释放内存块后,系统会递归地检查相邻的伙伴是否空闲,直到无法合并为止,从而减少内存碎片。
内存分配控制的辅助函数
get_page_from_freelist()
这是一个从空闲链表中获取页面的辅助函数。它会检查不同大小的空闲内存块,并返回一个合适的内存块。
put_page_to_freelist()
用于将释放的页面放回空闲链表,准备供后续使用。它确保空闲块按照合适的大小被放回到对应的链表中。
__free_one_page()
用于释放一个单一的内存页,并将其返回到伙伴系统中。
zone_statistics()
这个函数提供有关内存区(zone)使用情况的统计信息,它在内存管理过程中用于调度和优化。
伙伴系统的优化
- 延迟合并:Linux 的伙伴系统采用延迟合并策略,即不会立即合并所有释放的块,而是根据实际需求延迟合并操作,以减少频繁合并所带来的性能开销。
- 内存回收与页面回收:当内存不足时,内核会调用
try_to_free_pages()来回收内存页面,释放一些暂时不需要的内存来满足新的分配请求。

















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









