




Linux内存管理13(基于6.1内核)---伙伴系统之碎片化
一、碎片化概述
1.1 内部碎片和外部碎片
分页与分段
页是信息的物理单位, 分页是为了实现非连续分配, 以便解决内存碎片问题, 或者说分页是由于系统管理的需要. 段是信息的逻辑单位,它含有一组意义相对完整的信息, 分段的目的是为了更好地实现共享, 满足用户的需要。
页的大小固定且由系统确定, 将逻辑地址划分为页号和页内地址是由机器硬件实现的. 而段的长度却不固定, 决定于用户所编写的程序, 通常由编译程序在对源程序进行编译时根据信息的性质来划分。
分页的作业地址空间是一维的. 分段的地址空间是二维的。
Linux 内存管理中,内部碎片(Internal Fragmentation)和外部碎片(External Fragmentation)是两种常见的内存碎片化现象,它们与操作系统如何分配和管理内存块有关。以下是这两者的详细说明:
1. 内部碎片(Internal Fragmentation)
内部碎片指的是由于内存分配单位(通常是页面、块、段等)不完全适应程序或进程实际需求而产生的空闲内存。具体来说,内部碎片是在已分配的内存块内部,实际使用的内存比所分配的内存少,导致的未使用内存空间。
发生原因:
- 当操作系统分配内存时,通常会以固定大小的内存块(比如页面、段或页框)为单位。若一个进程请求的内存大小没有恰好匹配这些固定的分配单位,就会出现一些空闲的未使用空间。
- 例如,如果操作系统分配了一个大小为 4KB 的内存页,而进程实际只用了 3KB 内存,那么就会剩下 1KB 空间,这部分空间无法被其他进程使用,从而造成内部碎片。
影响:
- 内部碎片会导致内存的浪费,尽管整个系统中有许多分配的内存块,但其中一部分内存实际上未被使用。
- 内部碎片的大小通常是固定的(取决于分配单位的大小)。
示例:
假设操作系统以 4KB 为分配单位:
- 一个进程请求 6KB 内存,操作系统会分配两个 4KB 的块,总共 8KB。结果是这个进程只用了 6KB,而剩余的 2KB 中有 1KB 的空闲内存是内部碎片。
2. 外部碎片(External Fragmentation)
外部碎片指的是操作系统中由于多个进程的内存分配和释放,导致内存空间被分割成多个不连续的块。尽管总的空闲内存可能足够,但由于这些空闲内存被分散在不同的位置,因此无法直接分配给需要的进程。
发生原因:
- 外部碎片通常是由于进程频繁的内存分配与释放所导致的。随着时间的推移,系统中会有许多不同大小的空闲内存块,这些块之间可能没有连续的空间可供新的进程分配。
- 比如,在一个大内存区域中,有若干个小的空闲区域,合起来它们的大小足够满足一个新的进程的请求,但由于它们是零散的,因此不能满足进程的连续内存需求。
影响:
- 外部碎片的存在会导致大内存请求无法得到满足,即使系统总的空闲内存足够。
- 对系统的性能产生影响,可能需要进行内存压缩、内存整理(例如内存碎片合并)或更复杂的内存管理策略来缓解。
示例:
假设一个系统有 100KB 内存:
- 进程 A 占用了 40KB,进程 B 占用了 30KB,进程 C 占用了 20KB,剩余 10KB 空闲。
- 如果一个新的进程请求 50KB 内存,尽管系统总共有 60KB 的空闲内存,但因为空闲内存被分成多个小块(比如 10KB、20KB 等),无法满足进程的连续内存需求,从而无法分配成功。
3. 内部碎片与外部碎片的区别
| 特点 | 内部碎片 | 外部碎片 |
|---|---|---|
| 定义 | 分配的内存块内部的未使用空间 | 内存中不连续的空闲空间 |
| 产生原因 | 内存分配单位不精确 | 内存的分配与释放导致不连续的空闲空间 |
| 存在位置 | 已分配的内存块内部 | 已分配的内存块之间的空闲空间 |
| 影响 | 内存浪费,不能被其他进程使用 | 总的空闲内存足够,但无法满足进程的需求 |
| 解决方法 | 增加内存分配的精度(如页面对齐等) | 内存压缩、合并、换区或更换分配算法 |
1.2 buddy伙伴系统如何避免碎片?
Linux伙伴系统分配内存的大小要求2的幂指数页, 这也会产生严重的内部碎片。
伙伴系统的基本原理已经在前面已经讨论过, 一个双链表即可满足伙伴系统的所有需求, 其方案在最近几年间确实工作得非常好。但在Linux内存管理方面,有一个长期存在的问题 : 在系统启动并长期运行后,物理内存会产生很多碎片。该情形如下图所示:
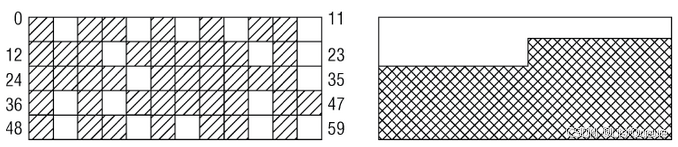
假定内存由60页组成,这显然不是超级计算机,但用于示例却足够了。左侧的地址空间中散布着空闲页。尽管大约25%的物理内存仍然未分配,但最大的连续空闲区只有一页. 这对用户空间应用程序没有问题:其内存是通过页表映射的,无论空闲页在物理内存中的分布如何,应用程序看到的内存。似乎总是连续的。右图给出的情形中,空闲页和使用页的数目与左图相同,但所有空闲页都位于一个连续区中。但对内核来说,碎片是一个问题. 由于(大多数)物理内存一致映射到地址空间的内核部分, 那么在左图的场景中, 无法映射比一页更大的内存区. 尽管许多时候内核都分配的是比较小的内存, 但也有时候需要分配多于一页的内存. 显而易见, 在分配较大内存的情况下, 右图中所有已分配页和空闲页都处于连续内存区的情形,是更为可取的。
很有趣的一点是, 在大部分内存仍然未分配时, 就也可能发生碎片问题. 考虑下图所示的情形。
只分配了4页,但可分配的最大连续区只有8页,因为伙伴系统所能工作的分配范围只能是2的幂次。

内存碎片只涉及内核,这只是部分正确的。大多数现代CPU都提供了使用巨型页的可能性,比普通页大得多。这对内存使用密集的应用程序有好处。在使用更大的页时,地址转换后备缓冲器只需处理较少的项,降低了TLB缓存失效的可能性。但分配巨型页需要连续的空闲物理内存!
很长时间以来,物理内存的碎片确实是Linux的弱点之一。尽管已经提出了许多方法,但没有哪个方法能够既满足Linux需要处理的各种类型工作负荷提出的苛刻需求,同时又对其他事务影响不大。
目前Linux内核为解决内存碎片的方案提供了两类解决方案:
-
依据可移动性组织页避免内存碎片。
-
虚拟可移动内存域避免内存碎片。
二、依据可移动性组织页避免内存碎片
2.1 依据可移动性组织页
反碎片的工作原理如何?
为理解该方法,我们必须知道内核将已分配页划分为下面3种不同类型。
| 页面类型 | 描述 | 举例 |
|---|---|---|
| 不可移动页 | 在内存中有固定位置, 不能移动到其他地方. | 核心内核分配的大多数内存属于该类别。 |
| 可移动页 | 可以随意地移动. | 属于用户空间应用程序的页属于该类别. 它们是通过页表映射的。 如果它们复制到新位置,页表项可以相应地更新,应用程序不会注意到任何事。 |
| 可回收页 | 不能直接移动, 但可以删除, 其内容可以从某些源重新生成. | 例如,映射自文件的数据属于该类别。 kswapd守护进程会根据可回收页访问的频繁程度,周期性释放此类内存. , 页面回收本身就是一个复杂的过程. 内核会在可回收页占据了太多内存时进行回收, 在内存短缺(即分配失败)时也可以发起页面回收。 |
页的可移动性,依赖该页属于3种类别的哪一种. 内核使用的反碎片技术, 即基于将具有相同可移动性的页分组的思想。
为什么这种方法有助于减少碎片?
由于页无法移动, 导致在原本几乎全空的内存区中无法进行连续分配. 根据页的可移动性, 将其分配到不同的列表中, 即可防止这种情形. 例如, 不可移动的页不能位于可移动内存区的中间, 否则就无法从该内存区分配较大的连续内存块.
想一下, 上图中大多数空闲页都属于可回收的类别, 而分配的页则是不可移动的. 如果这些页聚集到两个不同的列表中, 如下图所示. 在不可移动页中仍然难以找到较大的连续空闲空间, 但对可回收的页, 就容易多了。
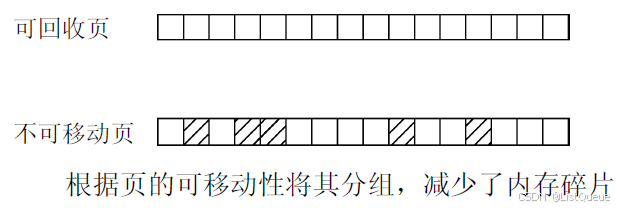
但要注意, 从最初开始, 内存并未划分为可移动性不同的区。这些是在运行时形成的。内核的另一种方法确实将内存分区, 分别用于可移动页和不可移动页的分配, 我会下文讨论其工作原理。但这种划分对这里描述的方法是不必要的。
2.2 迁移类型
尽管内核使用的反碎片技术卓有成效,它对伙伴分配器的代码和数据结构几乎没有影响。内核定义了一些枚举常量(早期用宏来实现)来表示不同的迁移类型, 参见include/linux/mmzone.h
include/linux/mmzone.h
enum {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
/*
* MIGRATE_CMA migration type is designed to mimic the way
* ZONE_MOVABLE works. Only movable pages can be allocated
* from MIGRATE_CMA pageblocks and page allocator never
* implicitly change migration type of MIGRATE_CMA pageblock.
*
* The way to use it is to change migratetype of a range of
* pageblocks to MIGRATE_CMA which can be done by
* __free_pageblock_cma() function. What is important though
* is that a range of pageblocks must be aligned to
* MAX_ORDER_NR_PAGES should biggest page be bigger then
* a single pageblock.
*/
MIGRATE_CMA,
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES
};
| 宏 | 类型 |
|---|---|
| MIGRATE_UNMOVABLE | 不可移动页 |
| MIGRATE_MOVABLE | 可移动页 |
| MIGRATE_RECLAIMABLE | 可回收页 |
| MIGRATE_PCPTYPES | 是per_cpu_pageset, 即用来表示每CPU页框高速缓存的数据结构中的链表的迁移类型数目 |
| MIGRATE_HIGHATOMIC | = MIGRATE_PCPTYPES, 在罕见的情况下,内核需要分配一个高阶的页面块而不能休眠.如果向具有特定可移动性的列表请求分配内存失败,这种紧急情况下可从MIGRATE_HIGHATOMIC中分配内存 |
| MIGRATE_CMA | Linux内核最新的连续内存分配器(CMA), 用于避免预留大块内存 |
| MIGRATE_ISOLATE | 是一个特殊的虚拟区域, 用于跨越NUMA结点移动物理内存页. 在大型系统上, 它有益于将物理内存页移动到接近于使用该页最频繁的CPU. |
| MIGRATE_TYPES | 只是表示迁移类型的数目, 也不代表具体的区域 |
对于MIGRATE_CMA类型, 其中使用ARM等嵌入式Linux系统的时候, 一个头疼的问题是GPU, Camera, HDMI等都需要预留大量连续内存,这部分内存平时不用,但是一般的做法又必须先预留着. 目前, Marek Szyprowski和Michal Nazarewicz实现了一套全新的Contiguous Memory Allocator. 通过这套机制, 我们可以做到不预留内存,这些内存平时是可用的,只有当需要的时候才被分配给Camera,HDMI等设备.内核为此提供了函数is_migrate_cma来检测当前类型是否为MIGRATE_CMA, 该函数定义include/linux/mmzone.h
#ifdef CONFIG_CMA
# define is_migrate_cma(migratetype) unlikely((migratetype) == MIGRATE_CMA)
# define is_migrate_cma_page(_page) (get_pageblock_migratetype(_page) == MIGRATE_CMA)
#else
# define is_migrate_cma(migratetype) false
# define is_migrate_cma_page(_page) false
#endif
2.3 free_area的改进
对伙伴系统数据结构的主要调整, 是将空闲列表分解为MIGRATE_TYPE个列表, 可以参见free_area的include/linux/mmzone.h
include/linux/pageblock-flags.h
struct free_area
{
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
- nr_free统计了所有列表上空闲页的数目,而每种迁移类型都对应于一个空闲列表
假设有一个总大小为 64KB 的内存区域,画出这部分内存如何通过伙伴系统进行管理。
- Step 1: 64KB内存块的初始分配: 在最初,所有内存(64KB)是一个单独的大块。它可以分割成更小的块。
Initial Memory (64KB)
+------------------------+
| 64KB (Block 0) |
+------------------------+
- Step 2: 分割内存块: 如果 64KB 的块不适合分配请求,系统会把它分割成两个 32KB 的块(这是2的幂)。
+------------------------+
| 32KB (Block 0) | <-- Buddy 0
+------------------------+ <-- Split
| 32KB (Block 1) | <-- Buddy 1
+------------------------+
- Step 3: 继续分割(16KB, 8KB, 4KB...): 每个大的块会继续被分割成两个更小的块。例如,32KB 会被分割为 16KB,16KB 会被分割为 8KB,直到 4KB 等最小块。
+------------------------+
| 16KB (Block 0) | <-- Buddy 0
+------------------------+ <-- Split
| 16KB (Block 1) | <-- Buddy 1
+------------------------+
|
+------------------------+
| 8KB (Block 0) | <-- Buddy 0
+------------------------+ <-- Split
| 8KB (Block 1) | <-- Buddy 1
+------------------------+
|
+------------------------+
| 4KB (Block 0) | <-- Buddy 0
+------------------------+ <-- Split
| 4KB (Block 1) | <-- Buddy 1
+------------------------+
- Step 4: 内存分配与释放: 当内存请求发生时,系统会从合适的空闲块中分配内存。如果内存块不可用,系统会递归分割更大的块。在释放内存时,两个空闲块会合并成一个更大的块。
+------------------------+ +------------------------+
| 32KB (Block 0) | | 64KB (Block 0) | <-- After Merging
+------------------------+ <-------> +------------------------+
宏for_each_migratetype_order(order, type)可用于迭代指定迁移类型的所有分配阶
#define for_each_migratetype_order(order, type) \
for (order = 0; order < MAX_ORDER; order++) \
for (type = 0; type < MIGRATE_TYPES; type++)
2.4 迁移备用列表fallbacks
如果内核无法满足针对某一给定迁移类型的分配请求, 会怎么样?
此前已经出现过一个类似的问题, 即特定的NUMA内存域无法满足分配请求时. 我们需要从其他内存域中选择一个代价最低的内存域完成内存的分配, 因此内核在内存的结点pg_data_t中提供了一个备用内存域列表zonelists.
内核在内存迁移的过程中处理这种情况下的做法是类似的. 提供了一个备用列表fallbacks, 规定了在指定列表中无法满足分配请求时. 接下来应使用哪一种迁移类型, 定义在mm/page_alloc.c
/*
* This array describes the order lists are fallen back to when
* the free lists for the desirable migrate type are depleted
*
* The other migratetypes do not have fallbacks.
*/
static int fallbacks[MIGRATE_TYPES][MIGRATE_PCPTYPES - 1] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE },
};
2.5 全局pageblock_order变量
全局变量和辅助函数尽管页可移动性分组特性总是编译到内核中,但只有在系统中有足够内存可以分配到多个迁移类型对应的链表时,才是有意义的。由于每个迁移链表都应该有适当数量的内存,内核需要定义”适当”的概念. 这是通过两个全局变量pageblock_order和pageblock_nr_pages提供的. 第一个表示内核认为是”大”的一个分配阶, pageblock_nr_pages则表示该分配阶对应的页数。如果体系结构提供了巨型页机制, 则pageblock_order通常定义为巨型页对应的分配阶. 定义在include/linux/pageblock-flags.h
#ifdef CONFIG_HUGETLB_PAGE
#ifdef CONFIG_HUGETLB_PAGE_SIZE_VARIABLE
/* Huge page sizes are variable */
extern unsigned int pageblock_order;
#else /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */
/*
* Huge pages are a constant size, but don't exceed the maximum allocation
* granularity.
*/
#define pageblock_order min_t(unsigned int, HUGETLB_PAGE_ORDER, MAX_ORDER)
#endif /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */
#else /* CONFIG_HUGETLB_PAGE */
/* If huge pages are not used, group by MAX_ORDER_NR_PAGES */
#define pageblock_order MAX_ORDER
#endif /* CONFIG_HUGETLB_PAGE */
#define pageblock_nr_pages (1UL << pageblock_order)
在IA-32体系结构上, 巨型页长度是4MB, 因此每个巨型页由1024个普通页组成, 而HUGETLB_PAGE_ORDER则定义为10. 相比之下, IA-64体系结构允许设置可变的普通和巨型页长度, 因此HUGETLB_PAGE_ORDER的值取决于内核配置。
如果体系结构不支持巨型页, 则将其定义为第二高的分配阶, 即MAX_ORDER - 1
/* If huge pages are not used, group by MAX_ORDER_NR_PAGES */
#define pageblock_order (MAX_ORDER-1)
如果各迁移类型的链表中没有一块较大的连续内存,那么页面迁移不会提供任何好处, 因此在可用内存太少时内核会关闭该特性。这是在build_all_zonelists函数中检查的, 该函数用于初始化内存域列表。如果没有足够的内存可用,则全局变量:extern int page_group_by_mobility_disabled设置为0, 否则设置为1。
内核如何知道给定的分配内存属于何种迁移类型?
内核提供了两个标志,分别用于表示分配的内存是可移动的(__GFP_MOVABLE)或可回收的(__GFP_RECLAIMABLE)。
2.6 gfpflags_to_migratetype转换分配标识到迁移类型
如果这些标志都没有设置, 则分配的内存假定为不可移动的. 辅助函数gfpflags_to_migratetype可用于转换分配标志及对应的迁移类型, 该函数定义include/linux/gfp.h
static inline int gfp_migratetype(const gfp_t gfp_flags)
{
VM_WARN_ON((gfp_flags & GFP_MOVABLE_MASK) == GFP_MOVABLE_MASK);
BUILD_BUG_ON((1UL << GFP_MOVABLE_SHIFT) != ___GFP_MOVABLE);
BUILD_BUG_ON((___GFP_MOVABLE >> GFP_MOVABLE_SHIFT) != MIGRATE_MOVABLE);
BUILD_BUG_ON((___GFP_RECLAIMABLE >> GFP_MOVABLE_SHIFT) != MIGRATE_RECLAIMABLE);
BUILD_BUG_ON(((___GFP_MOVABLE | ___GFP_RECLAIMABLE) >>
GFP_MOVABLE_SHIFT) != MIGRATE_HIGHATOMIC);
if (unlikely(page_group_by_mobility_disabled))
return MIGRATE_UNMOVABLE;
/* Group based on mobility */
return (__force unsigned long)(gfp_flags & GFP_MOVABLE_MASK) >> GFP_MOVABLE_SHIFT;
}
2.7 pageblock_flags变量与其函数接口
最后要注意, 每个内存域都提供了一个特殊的字段, 可以跟踪包含pageblock_nr_pages个页的内存区的属性. 即zone->pageblock_flags字段, 当前只有与页可移动性相关的代码使用, include/linux/mmzone.h
struct zone
{
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
};
在初始化期间, 内核自动确保对内存域中的每个不同的迁移类型分组, 在pageblock_flags中都分配了足够存储NR_PAGEBLOCK_BITS个比特位的空间。当前,表示一个连续内存区的迁移类型需要3个比特位, include/linux/pageblock-flags.h
/* Bit indices that affect a whole block of pages */
enum pageblock_bits {
PB_migrate,
PB_migrate_end = PB_migrate + 3 - 1,
/* 3 bits required for migrate types */
PB_migrate_skip,/* If set the block is skipped by compaction */
/*
* Assume the bits will always align on a word. If this assumption
* changes then get/set pageblock needs updating.
*/
NR_PAGEBLOCK_BITS
};
内核提供set_pageblock_migratetype负责设置以page为首的一个内存区的迁移类型, 该函数定义mm/page_alloc.c
void set_pageblock_migratetype(struct page *page, int migratetype)
{
if (unlikely(page_group_by_mobility_disabled &&
migratetype < MIGRATE_PCPTYPES))
migratetype = MIGRATE_UNMOVABLE;
set_pageblock_flags_group(page, (unsigned long)migratetype,
PB_migrate, PB_migrate_end);
}
migratetype参数可以通过上文介绍的gfpflags_to_migratetype辅助函数构建. 请注意很重要的一点, 页的迁移类型是预先分配好的, 对应的比特位总是可用, 与页是否由伙伴系统管理无关. 在释放内存时,页必须返回到正确的迁移链表。这之所以可行,是因为能够从get_pageblock_migratetype获得所需的信息. include/linux/mmzone.h
#define get_pageblock_migratetype(page) \
get_pfnblock_flags_mask(page, page_to_pfn(page), MIGRATETYPE_MASK)
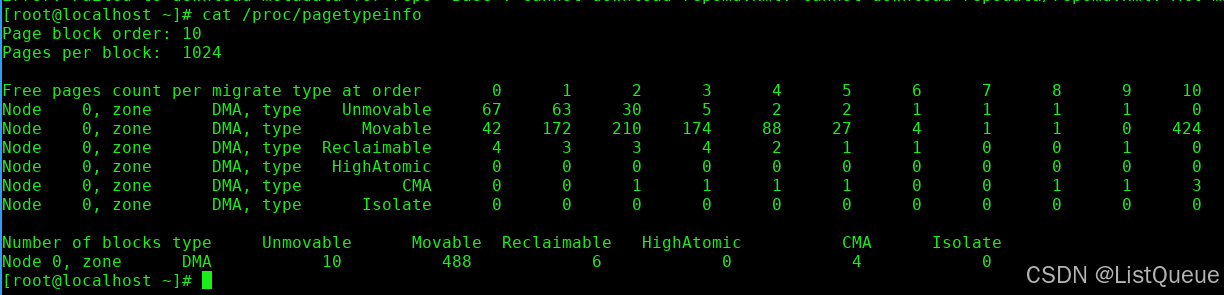
2.8 /proc/pagetypeinfo获取页面分配状态
最后请注意, 在各个迁移链表之间, 当前的页面分配状态可以从/proc/pagetypeinfo获得.
2.9 可移动性的分组的初始化
在内存子系统初始化期间, memmap_init_range负责处理内存域的page实例. 该函数定义mm/mm_init.c函数完成了一些不怎么有趣的标准初始化工作,但其中有一件是实质性的,即所有的页最初都标记为可移动的
/*
* Initially all pages are reserved - free ones are freed
* up by memblock_free_all() once the early boot process is
* done. Non-atomic initialization, single-pass.
*
* All aligned pageblocks are initialized to the specified migratetype
* (usually MIGRATE_MOVABLE). Besides setting the migratetype, no related
* zone stats (e.g., nr_isolate_pageblock) are touched.
*/
void __meminit memmap_init_range(unsigned long size, int nid, unsigned long zone,
unsigned long start_pfn, unsigned long zone_end_pfn,
enum meminit_context context,
struct vmem_altmap *altmap, int migratetype)
{
unsigned long pfn, end_pfn = start_pfn + size;
struct page *page;
if (highest_memmap_pfn < end_pfn - 1)
highest_memmap_pfn = end_pfn - 1;
#ifdef CONFIG_ZONE_DEVICE
/*
* Honor reservation requested by the driver for this ZONE_DEVICE
* memory. We limit the total number of pages to initialize to just
* those that might contain the memory mapping. We will defer the
* ZONE_DEVICE page initialization until after we have released
* the hotplug lock.
*/
if (zone == ZONE_DEVICE) {
if (!altmap)
return;
if (start_pfn == altmap->base_pfn)
start_pfn += altmap->reserve;
end_pfn = altmap->base_pfn + vmem_altmap_offset(altmap);
}
#endif
for (pfn = start_pfn; pfn < end_pfn; ) {
/*
* There can be holes in boot-time mem_map[]s handed to this
* function. They do not exist on hotplugged memory.
*/
if (context == MEMINIT_EARLY) {
if (overlap_memmap_init(zone, &pfn))
continue;
if (defer_init(nid, pfn, zone_end_pfn)) {
deferred_struct_pages = true;
break;
}
}
page = pfn_to_page(pfn);
__init_single_page(page, pfn, zone, nid);
if (context == MEMINIT_HOTPLUG)
__SetPageReserved(page);
/*
* Usually, we want to mark the pageblock MIGRATE_MOVABLE,
* such that unmovable allocations won't be scattered all
* over the place during system boot.
*/
if (pageblock_aligned(pfn)) {
set_pageblock_migratetype(page, migratetype);
cond_resched();
}
pfn++;
}
}
在分配内存时, 如果必须”盗取”不同于预定迁移类型的内存区, 内核在策略上倾向于”盗取”更大的内存区. 由于所有页最初都是可移动的, 那么在内核分配不可移动的内存区时, 则必须”盗取”。
实际上, 在启动期间分配可移动内存区的情况较少, 那么分配器有很高的几率分配长度最大的内存区, 并将其从可移动列表转换到不可移动列表. 由于分配的内存区长度是最大的, 因此不会向可移动内存中引入碎片。
总而言之, 这种做法避免了启动期间内核分配的内存(经常在系统的整个运行时间都不释放)散布到物理内存各处, 从而使其他类型的内存分配免受碎片的干扰,这也是页可移动性分组框架的最重要的目标之一。
三、虚拟可移动内存域避免内存碎片
3.1 虚拟可移动内存域
依据可移动性组织页是防止物理内存碎片的一种可能方法,内核还提供了另一种阻止该问题的手段 : 虚拟内存域ZONE_MOVABLE。
该机制在内核2.6.23开发期间已经并入内核, 比可移动性分组框架加入内核早一个版本. 与可移动性分组相反, ZONE_MOVABLE特性必须由管理员显式激活。
基本思想很简单 : 可用的物理内存划分为两个内存域, 一个用于可移动分配, 一个用于不可移动分配. 这会自动防止不可移动页向可移动内存域引入碎片。
这马上引出了另一个问题 : 内核如何在两个竞争的内存域之间分配可用的内存?
这显然对内核要求太高,因此系统管理员必须作出决定。毕竟,人可以更好地预测计算机需要处理的场景,以及各种类型内存分配的预期分布。
3.2 数据结构
kernelcore参数用来指定用于不可移动分配的内存数量, 即用于既不能回收也不能迁移的内存数量。剩余的内存用于可移动分配。在分析该参数之后,结果保存在全局变量required_kernelcore中.
还可以使用参数movablecore控制用于可移动内存分配的内存数量。required_kernelcore的大小将会据此计算。如果有些聪明人同时指定两个参数,内核会按前述方法计算出required_kernelcore的值,并取指定值和计算值中较大的一个.
全局变量required_kernelcore和required_movablecore的定义mm/mm_init.c
static unsigned long __initdata required_kernelcore;
static unsigned long __initdata required_movablecore;
取决于体系结构和内核配置,ZONE_MOVABLE内存域可能位于高端或普通内存域, include/linux/mmzone.h
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};
与系统中所有其他的内存域相反, ZONE_MOVABLE并不关联到任何硬件上有意义的内存范围. 实际上, 该内存域中的内存取自高端内存域或普通内存域, 因此我们在下文中称ZONE_MOVABLE是一个虚拟内存域.
mm/mm_init.c辅助函数find_zone_movable_pfns_for_nodes用于计算进入ZONE_MOVABLE的内存数量.
如果kernelcore和movablecore参数都没有指定find_zone_movable_pfns_for_nodes会使ZONE_MOVABLE保持为空,该机制处于无效状态.
谈到从物理内存域提取多少内存用于ZONE_MOVABLE的问题, 必须考虑下面两种情况
-
用于不可移动分配的内存会平均地分布到所有内存结点上
-
只使用来自最高内存域的内存。在内存较多的32位系统上, 这通常会是ZONE_HIGHMEM, 但是对于64位系统,将使用ZONE_NORMAL或ZONE_DMA32.
实际计算相当冗长,也不怎么有趣,因此我不详细讨论了。实际上起作用的是结果
-
用于为虚拟内存域ZONE_MOVABLE提取内存页的物理内存域,保存在全局变量movable_zone中
-
对每个结点来说, zone_movable_pfn[node_id]表示ZONE_MOVABLE在movable_zone内存域中所取得内存的起始地址.
zone_movable_pfn定义mm/mm_init.c
static unsigned long zone_movable_pfn[MAX_NUMNODES] __initdata;
内核确保这些页将用于满足符合ZONE_MOVABLE职责的内存分配。
3.3 实现
到现在为止描述的数据结构如何应用?
类似于页面迁移方法, 分配标志在此扮演了关键角色。
所有可移动分配都必须指定__GFP_HIGHMEM和__GFP_MOVABLE即可。
由于内核依据分配标志确定进行内存分配的内存域, 在设置了上述的标志时, 可以选择ZONE_MOVABLE内存域. 这是将ZONE_MOVABLE集成到伙伴系统中所需的唯一改变。

















 1816
1816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









