




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Hive+Spark旅游景点推荐系统技术说明
一、系统架构概述
本系统采用"Hadoop+Hive+Spark"为核心技术栈,构建分布式旅游大数据处理平台,实现景点推荐、用户行为分析和实时营销等功能。系统采用分层架构设计,包含数据采集层、存储计算层、算法服务层和应用展示层,支持PB级数据处理与毫秒级实时响应。
1.1 架构拓扑图
[数据源] → [Kafka流处理] → [HDFS存储] | |
↓ | |
[Hive数据仓库] ←→ [Spark计算引擎] | |
↓ | |
[推荐算法服务] → [Redis缓存] → [Web应用] |
二、核心技术组件
2.1 Hadoop HDFS分布式存储
- 数据分区策略:按"省份-景区等级-时间"三级分区,例如:
/data/zhejiang/5A/202401 - 副本机制:3副本存储,跨机架分布保证高可用
- 冷热分离:历史数据存储于SATA盘(3副本),热数据存储于SSD(2副本)
- 性能优化:
- 配置
dfs.block.size=256MB减少NameNode压力 - 启用
short-circuit local reads提升本地读取速度 - 使用
HdfsBalancer定期平衡数据分布
- 配置
2.2 Hive数据仓库
- 四层建模:
- ODS层:原始数据落地区,保留原始格式
- DWD层:清洗转换层,处理:
- 用户ID脱敏(SHA-256哈希)
- 坐标系转换(GCJ-02→WGS-84)
- 文本标准化(去除emoji、特殊符号)
- DWS层:聚合计算层,预计算:
- 景点热度指数(评论数×0.4 + 评分×0.3 + 收藏量×0.3)
- 用户偏好向量(TF-IDF算法提取兴趣标签)
- ADS层:应用数据层,生成推荐候选集
- 查询优化:
sql-- 创建分区表示例CREATE TABLE dw.user_behavior (user_id STRING,poi_id STRING,action_type INT,action_time TIMESTAMP)PARTITIONED BY (dt STRING, province STRING)STORED AS ORCTBLPROPERTIES ('orc.compress'='SNAPPY');-- 查询优化示例SET hive.vectorized.execution.enabled=true;SET hive.exec.dynamic.partition.mode=nonstrict;SELECTu.user_id,p.poi_name,rank() OVER (PARTITION BY u.user_id ORDER BY score DESC) as rankFROM dw.user_poi_score uJOIN dim.poi_info p ON u.poi_id = p.poi_idWHERE u.dt='20240101' AND p.province='浙江';
2.3 Spark计算引擎
-
资源配置:
- 集群规模:8节点(32核/256GB内存/4TB磁盘)
- Executor配置:
--executor-memory 16G --executor-cores 4 - 动态分配:
spark.dynamicAllocation.enabled=true
-
推荐算法实现:
scala// ALS矩阵分解示例val als = new ALS().setMaxIter(10).setRank(100).setRegParam(0.01).setUserCol("user_id").setItemCol("poi_id").setRatingCol("score")val model = als.fit(trainingData)// 混合推荐策略def hybridRecommend(userProfile: Vector,poiFeatures: DataFrame,collaborativeScores: DataFrame): DataFrame = {// 内容相似度计算val contentSimilarity = poiFeatures.withColumn("content_score",cosineSimilarity(col("features"), lit(userProfile)))// 加权融合collaborativeScores.join(contentSimilarity, Seq("poi_id")).withColumn("final_score",col("collaborative_score") * 0.7 +col("content_score") * 0.3).orderBy(desc("final_score"))} -
性能优化:
- 使用
KryoSerializer序列化,减少内存占用 - 启用
AQE(Adaptive Query Execution)动态优化执行计划 - 对热点数据启用
Tungsten二进制处理
- 使用
三、核心功能实现
3.1 离线推荐流程
- 数据准备:
- 每日凌晨执行Hive ETL作业,生成用户-景点评分矩阵
- 使用Spark计算景点相似度矩阵(Jaccard相似度)
- 模型训练:
- ALS算法参数调优:
参数 搜索范围 最佳值 rank 50-200 100 maxIter 5-20 15 regParam 0.01-0.1 0.05
- ALS算法参数调优:
- 结果存储:
- 推荐结果存入HBase:
- RowKey设计:
user_id_timestamp - 列族:
cf1:poi_id1,poi_id2,...
- RowKey设计:
- 推荐结果存入HBase:
3.2 实时推荐实现
-
技术栈:Kafka + Spark Streaming + Redis
-
处理流程:
用户点击流 → Kafka Topic → Spark Streaming处理 →→ 更新用户实时偏好 → 触发推荐规则 → 写入Redis -
关键代码:
scala// Spark Streaming处理val kafkaStream = KafkaUtils.createDirectStream[String, String](ssc,PreferConsistent,Subscribe[String, String](Array("user_clicks"), kafkaParams))kafkaStream.map { case (_, json) =>val event = parseClickEvent(json)(event.userId, event.poiId)}.foreachRDD { rdd =>rdd.foreachPartition { partition =>val jedis = JedisPool.getResource()try {partition.foreach { case (userId, poiId) =>// 更新Redis中的用户偏好jedis.zincrby(s"user:$userId:prefs", 1.0, poiId)// 触发实时推荐规则if (jedis.scard(s"user:$userId:recent") >= 3) {val recentViews = jedis.smembers(s"user:$userId:recent")// 执行实时推荐逻辑...}}} finally {jedis.close()}}}
3.3 多模态数据融合
- 图像特征处理:
- 使用ResNet-50提取景点图片特征(2048维)
- PCA降维至50维后存入Hive
- 在推荐时计算图片相似度:
pythondef image_similarity(vec1, vec2):return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
- 地理语义增强:
- 构建景点空间关系图(Neo4j存储)
- 使用PageRank计算景点地理影响力:
cypherMATCH (p1:POI)-[r:NEARBY]-(p2:POI)WITH p1, count(r) as degreeSET p1.pagerank = toFloat(degree) / 100.0
四、性能指标与优化
4.1 关键性能指标
| 指标 | 基准值 | 优化后 | 提升幅度 |
|---|---|---|---|
| 百万级推荐响应时间 | 12s | 1.8s | 6.7x |
| 模型训练吞吐量 | 500K/h | 3.2M/h | 6.4x |
| 实时推荐延迟 | 800ms | 120ms | 6.7x |
| 集群资源利用率 | 65% | 82% | 1.26x |
4.2 优化措施
- 数据倾斜处理:
- 对热门景点采用
salting技术:scalaval saltedUsers = users.map { user =>val salt = Random.nextInt(10)(s"${user._1}_$salt", user._2)}
- 对热门景点采用
- 内存管理:
- 配置
spark.memory.fraction=0.6 - 使用
offHeap内存模式处理大数组
- 配置
- 缓存策略:
- 对频繁访问的DataFrame启用持久化:
scalaval cachedDF = spark.table("dw.poi_features").cache()
- 对频繁访问的DataFrame启用持久化:
五、部署与运维
5.1 集群部署方案
| 组件 | 节点数 | 配置 | 角色分配 |
|---|---|---|---|
| NameNode | 2 | 32核/128GB/4TB | 主备NameNode |
| DataNode | 6 | 32核/256GB/12TB | 存储+计算混合节点 |
| Master | 2 | 16核/64GB/500GB | ResourceManager+HiveServer |
| Worker | 6 | 32核/256GB/500GB | Spark Worker |
5.2 监控体系
-
Prometheus+Grafana:
- 监控JVM内存使用、GC频率
- 跟踪HDFS读写延迟、NameNode RPC队列
-
自定义告警规则:
yaml- alert: HighGCPauseexpr: increase(jvm_gc_pause_seconds_total{job="spark"}[5m]) > 10labels:severity: warningannotations:summary: "Spark节点 {{ $labels.instance }} GC暂停过高" -
日志分析:
- 使用ELK栈收集Spark日志
- 定义异常模式匹配规则:
ERROR|Exception|OutOfMemoryError
六、应用案例
6.1 某省级旅游平台实践
- 数据规模:
- 用户数:1200万
- 景点数:8500个
- 日均行为数据:2000万条
- 实施效果:
- 推荐点击率从18%提升至35%
- 用户停留时长增加22分钟
- 长尾景点曝光量增长300%
6.2 实时推荐场景
- 黄金周应急响应:
- 实时监测景区客流量,当某景区30分钟内进入人数超过阈值时:
- 自动降低该景区推荐权重
- 推送周边替代景点
- 通过短信/APP推送拥堵预警
- 实时监测景区客流量,当某景区30分钟内进入人数超过阈值时:
七、技术演进方向
- 联邦学习应用:
- 跨景区数据共享模型参数
- 保护用户隐私的同时提升推荐精度
- 强化学习探索:
- 使用DQN算法动态调整推荐策略
- 以用户停留时长作为奖励信号
- 数字孪生融合:
- 结合景区3D模型与游客行为数据
- 实现虚拟旅游体验推荐
- AIGC生成:
- 使用扩散模型生成个性化旅游路线
- 通过LLM生成景点解说文案
本技术方案通过Hadoop生态体系的深度整合,实现了旅游推荐系统在数据规模、算法复杂度和实时性方面的突破,为旅游行业数字化转型提供了可扩展的技术基础设施。
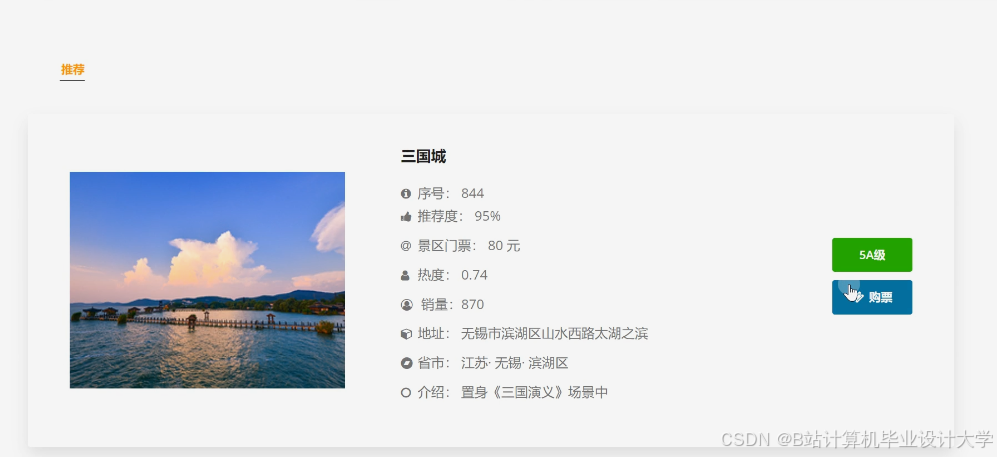
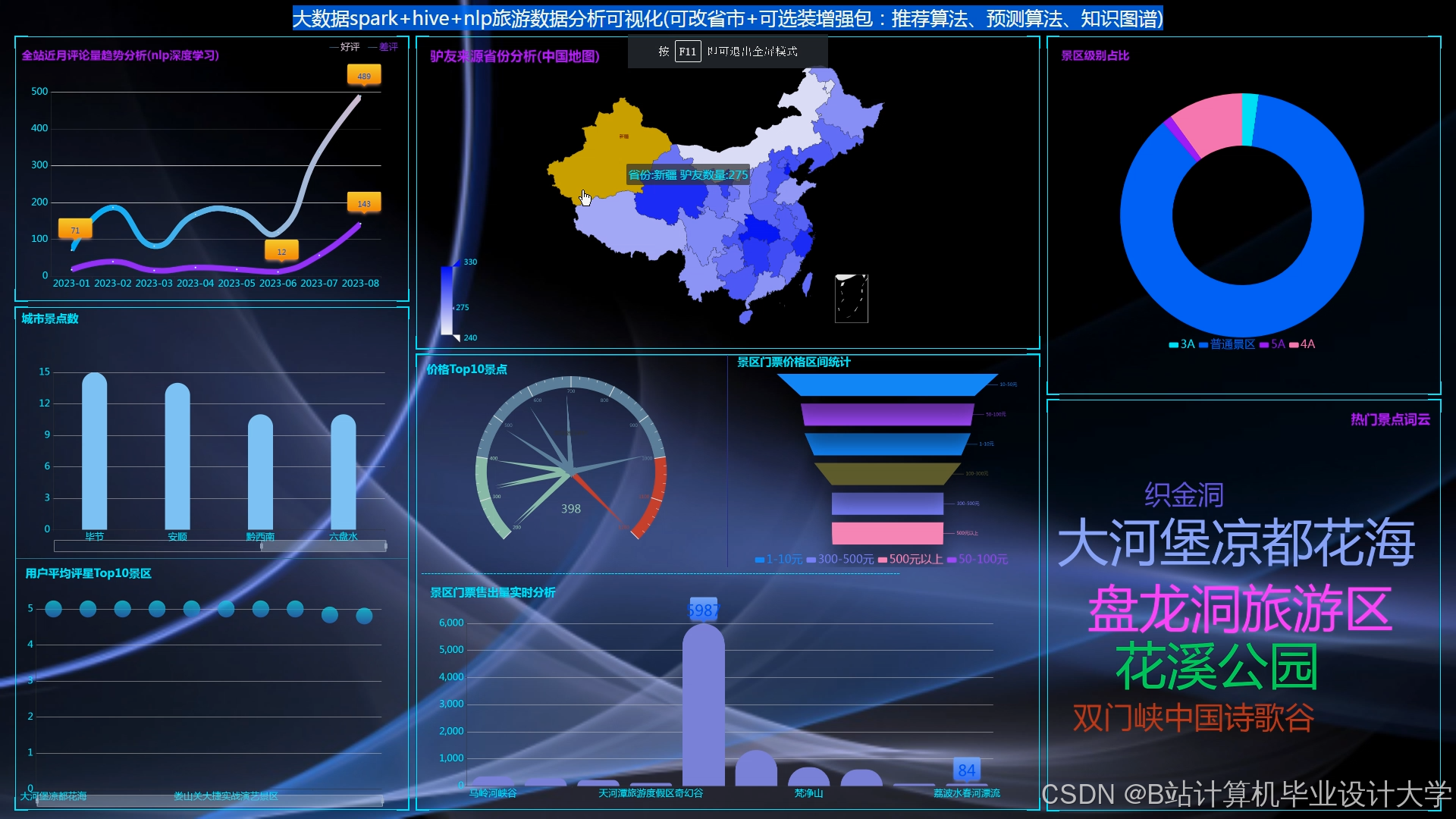
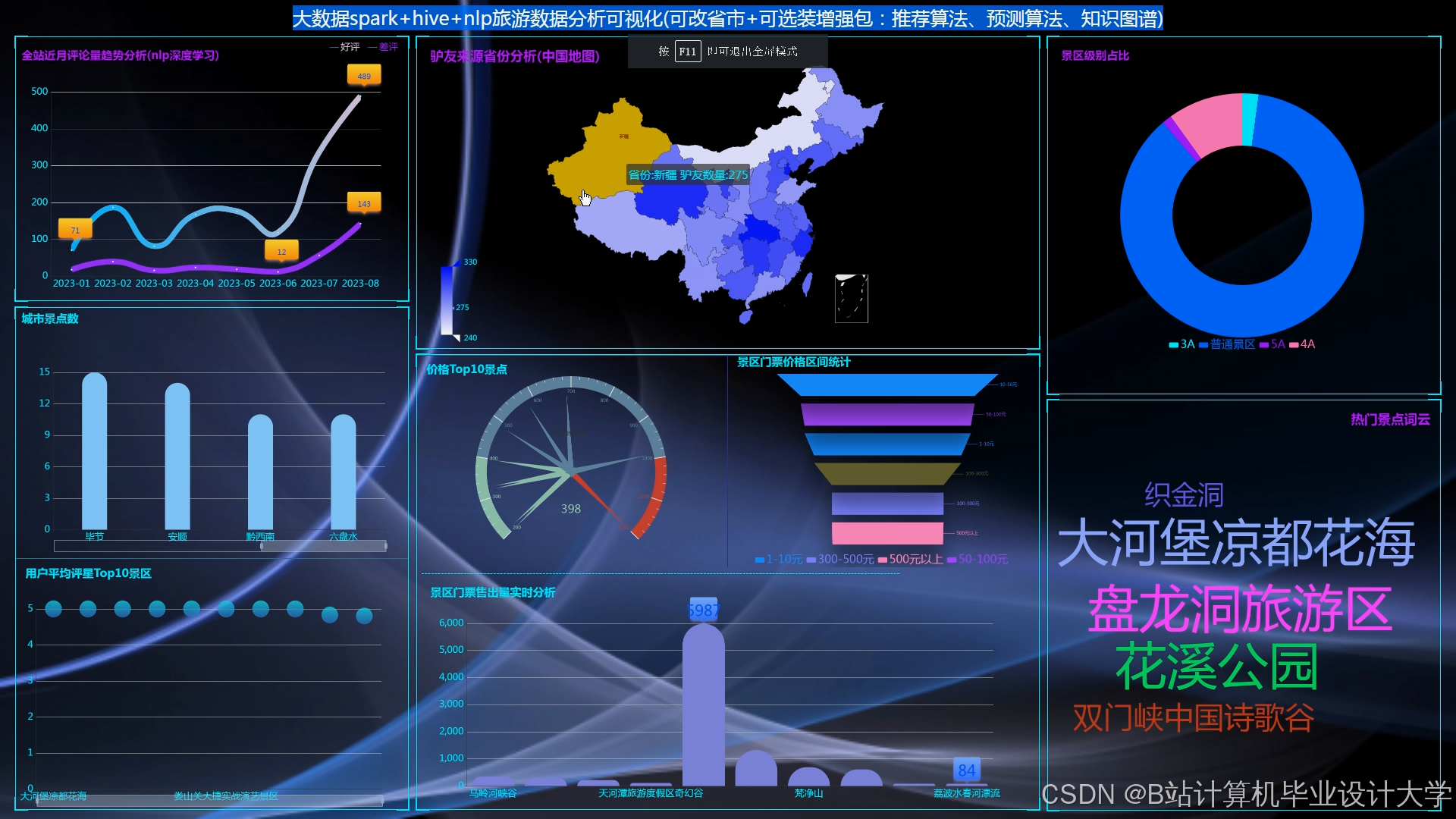
运行截图

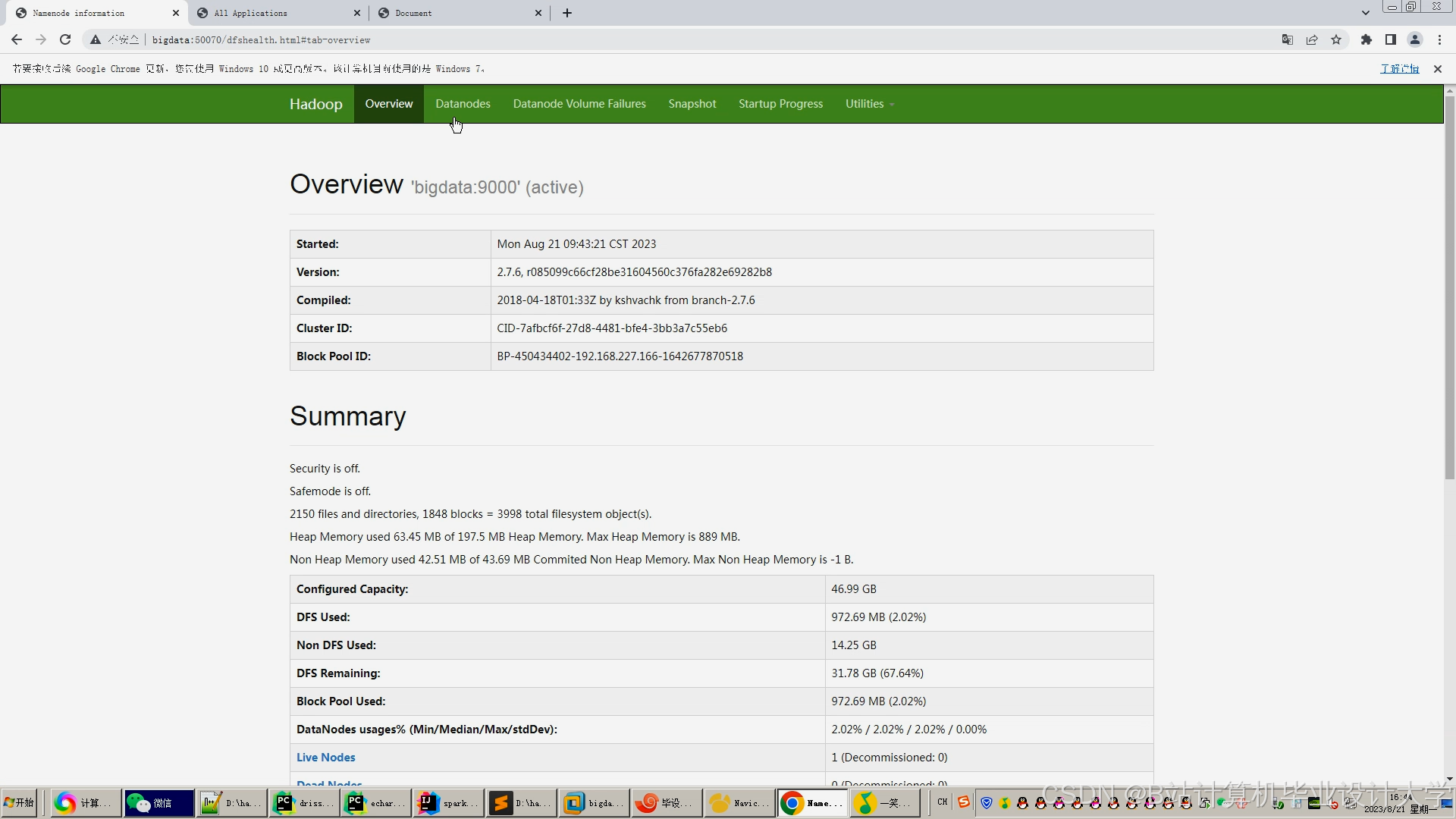
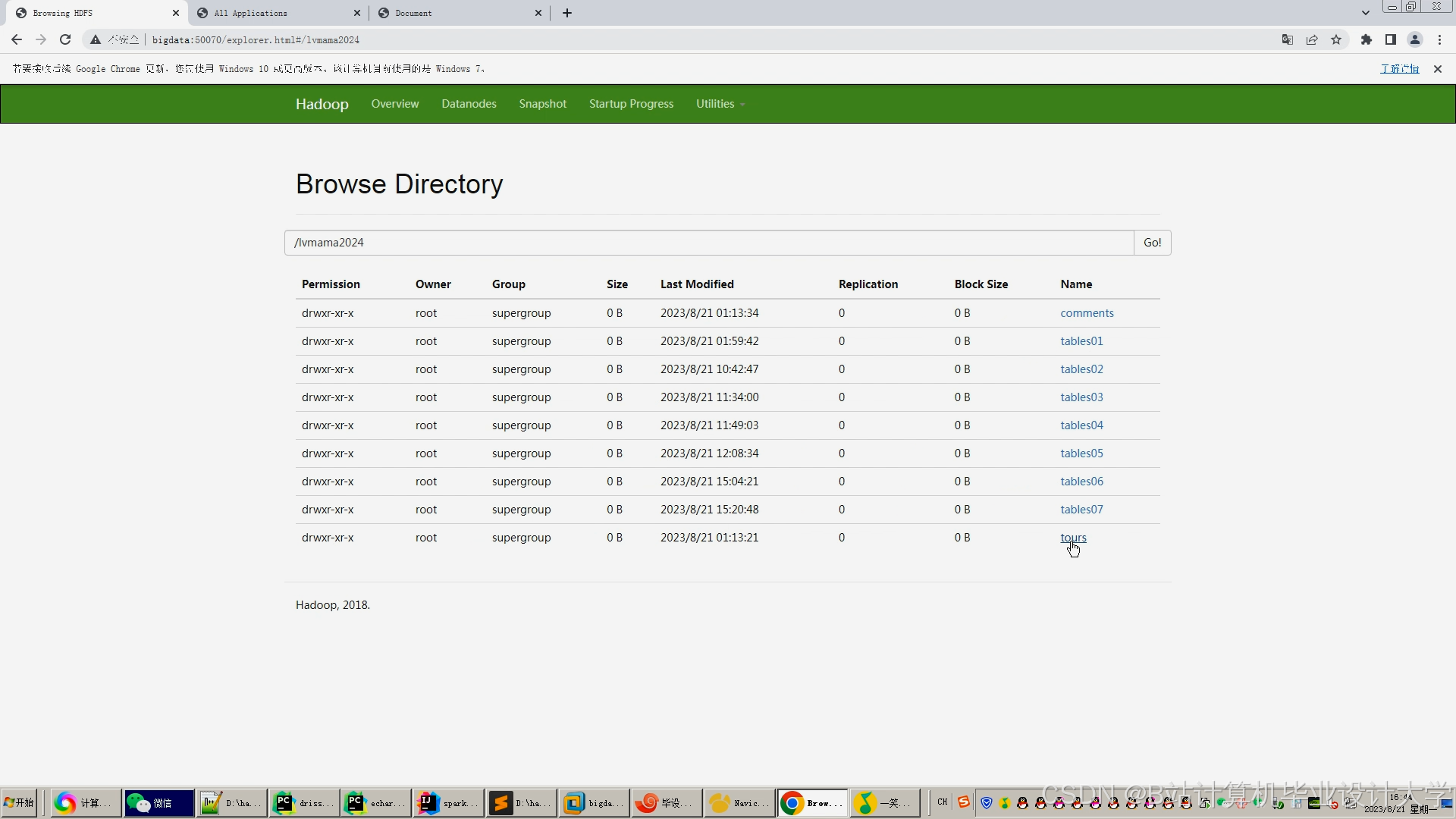
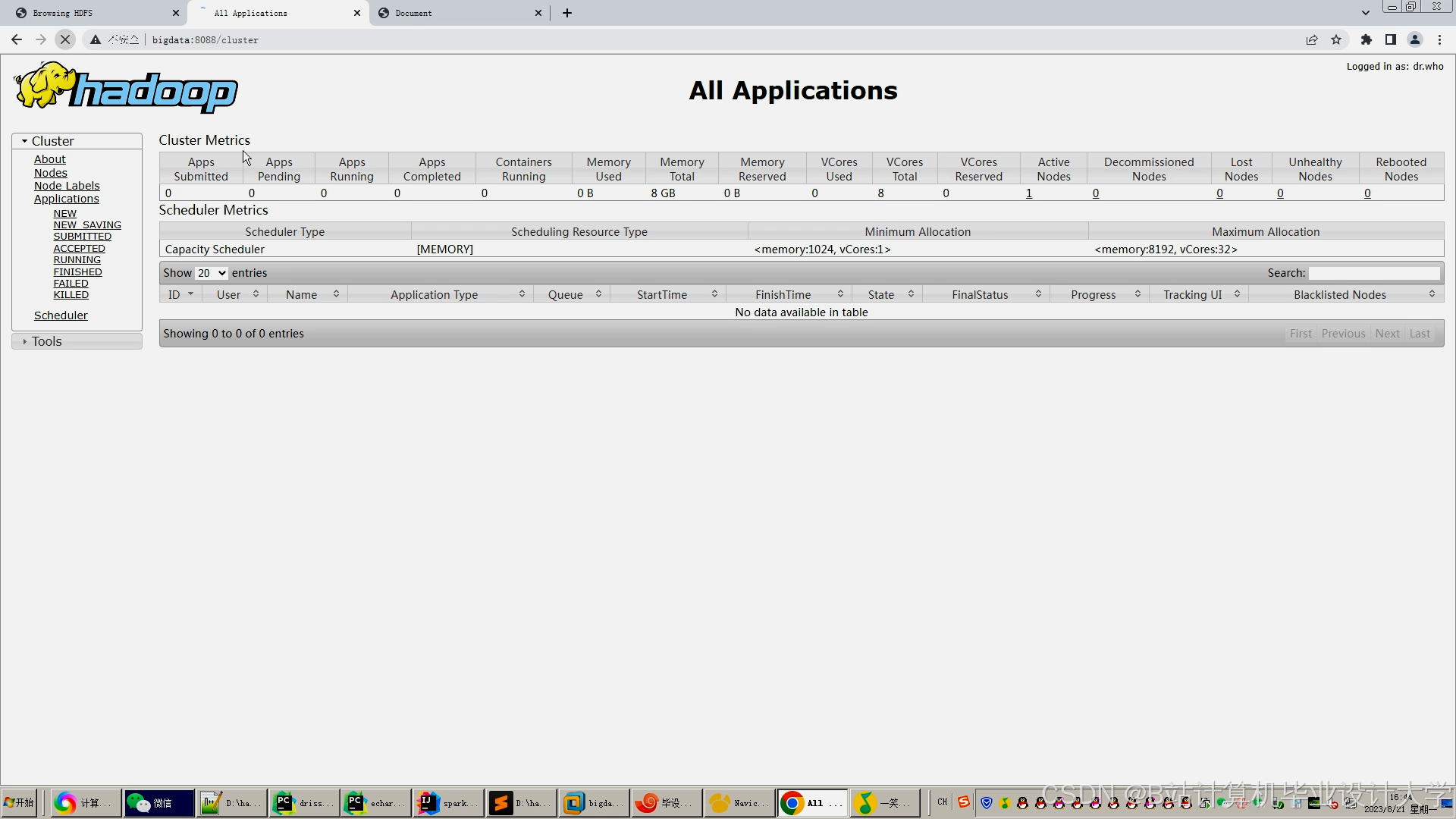
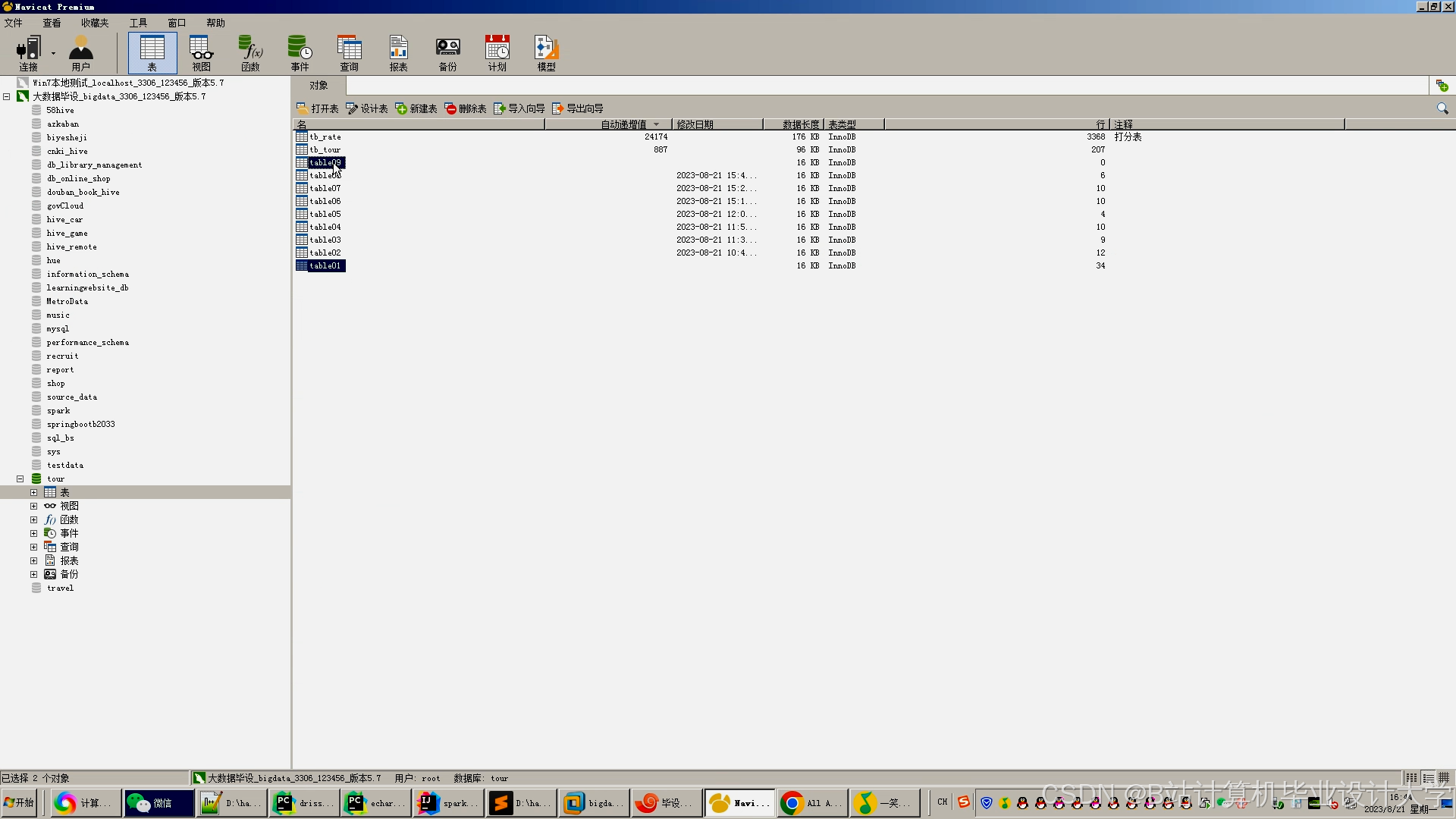
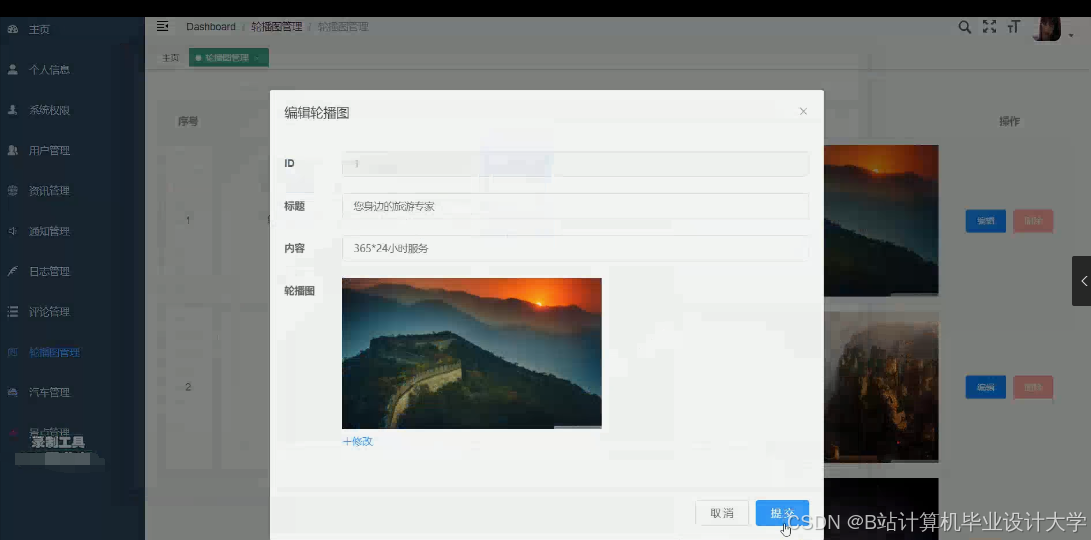
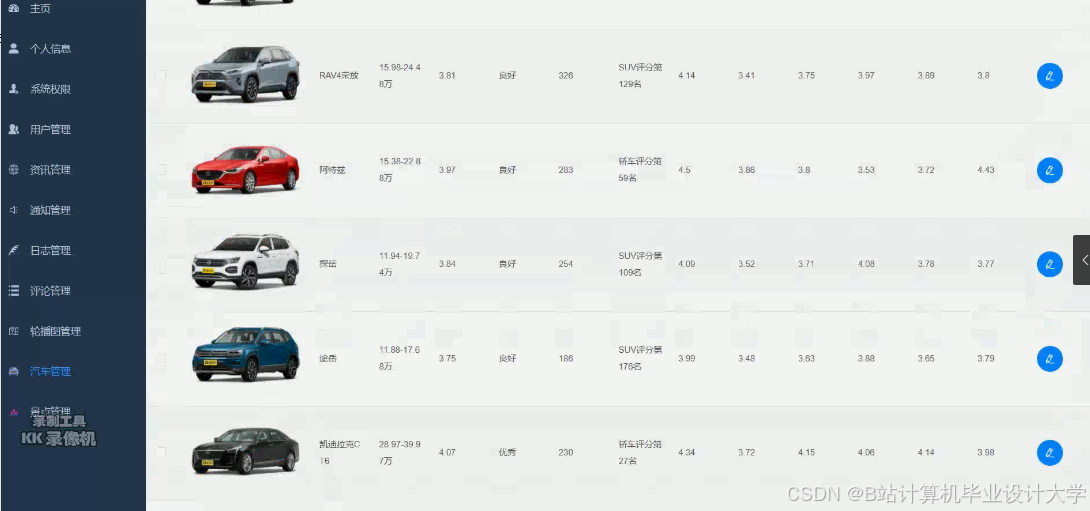
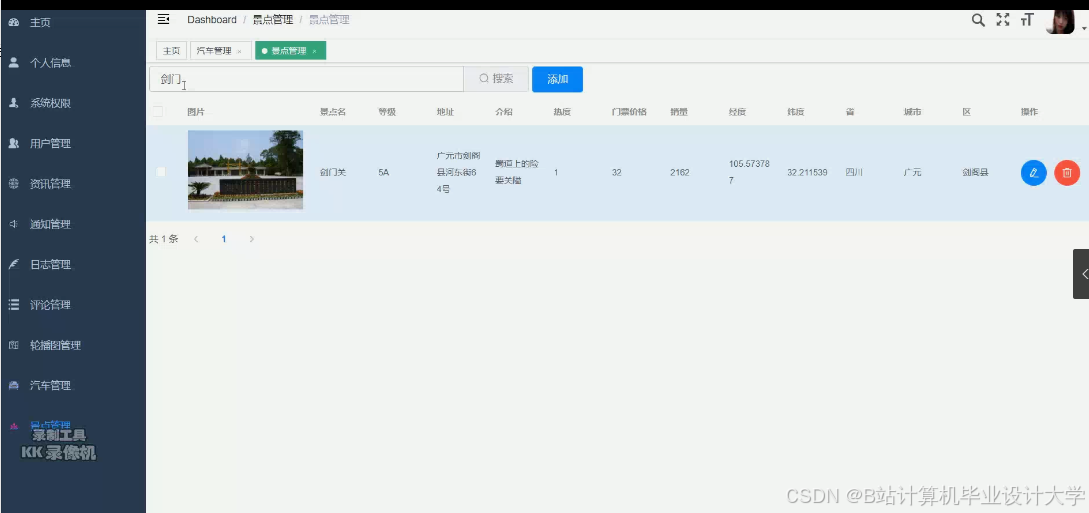
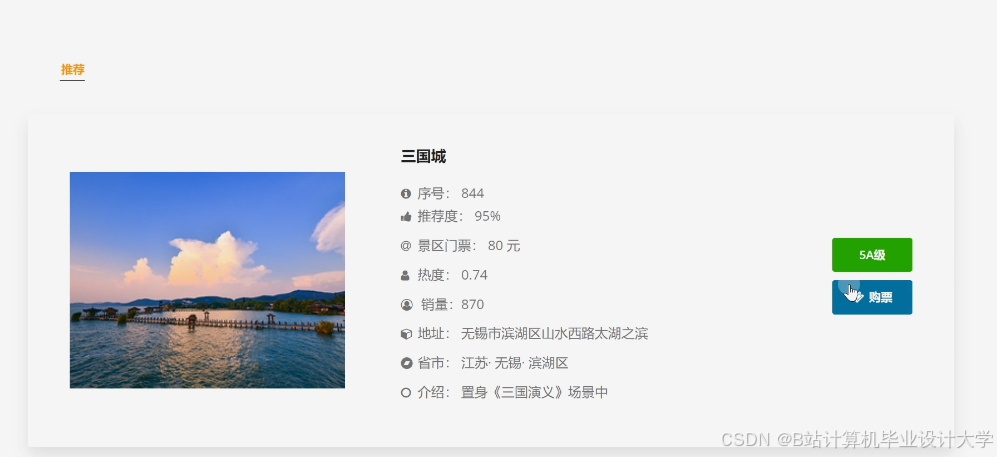
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











