







一、图的应用-最短路径问题
最短路径问题-介绍
- 互联网实际上是一个由路由器连接成的网络。这些路由器各自独立而又协同工作,负责将信息从Internet的一端传送到另一端。建模如下:
- 将互联网路由器体系表示为一个带权边的图
- 路由器作为顶点,路由器之间网络连接作为边
- 权重可以包括网络连接的速度、网络负载程度、分时段优先级等影响因素
- 作为一个抽象,我们把所有影响因素合成为单一的权重
- 解决信息在路由器网络中选择传播速度最快路径的问题,就转变为在带权图上最短路径的问题。与广度优先搜索BFS算法解决的词梯问题相似,只是在边上增加了权重
最短路径问题-Dijkstra算法
- 这是一个迭代算法,得出从一个顶点到其余所有顶点的最短路径。
- 在顶点Vertex类的属性distance,用于记录从开始顶点到本顶点的最短带权路径长度(权重之和),对图中的每个顶点迭代一次
- 顶点的访问次序由一个优先队列来控制,队列中作为优先级的是顶点的distance属性。
- 最初,只有开始顶点distance设为0,而其他所有顶点distance设为sys.maxsize(最大整数),全部加入优先队列。
- 随着队列中每个最低distance顶点率先出队,并计算它与邻接顶点的权重,会引起其它顶点distance的减小和修改,引起堆重排
- 并据更新后的distance优先级再依次出队
- Dijkstra算法时间复杂度约为O((|V|+|E|)log|V|)
Dijkstra算法实现
- 优先队列BinaryHeap类:增加堆重排rebuild_heap方法
- 顶点类Vertex:属性distance的默认值设置为sys.maxsize
- dijkstra函数:实现Dijkstra算法
import sys
class BinaryHeap:
def rebuild_heap(self):
"""对堆中所有元素进行堆重排"""
tmp = self.heap_list[1:]
self.build_heap(tmp)
# 其它代码详见《数据结构与算法Python版 二叉堆与优先队列》
class Vertex:
"""顶点类"""
def __init__(
self,
key,
distance=sys.maxsize,
pred=None,
color="white",
discovery=None,
finish=None,
):
self.key = key
self.connected_to = {}
self.distance = distance
self.pred = pred
self.color = color
self.discovery = discovery
self.finish = finish
# 其它代码详见《数据结构与算法Python版 通用的深度优先搜索》
def dijkstra(g: Graph, start: Vertex):
"""dijkstra算法实现"""
bh = BinaryHeap()
# 开始顶点distance设为0
start.set_distance(0)
# 全部加入优先队列
bh.build_heap([v for v in g])
while not bh.is_empty():
# 最低distance顶点出队
cur_vert = bh.del_min()
# 计算它与邻接顶点的权重
for next_vert in cur_vert.get_connections():
new_dist = cur_vert.get_distance() + cur_vert.get_weight(next_vert)
if new_dist < next_vert.get_distance():
next_vert.set_distance(new_dist)
next_vert.set_pred(cur_vert)
# 堆重排
bh.rebuild_heap()
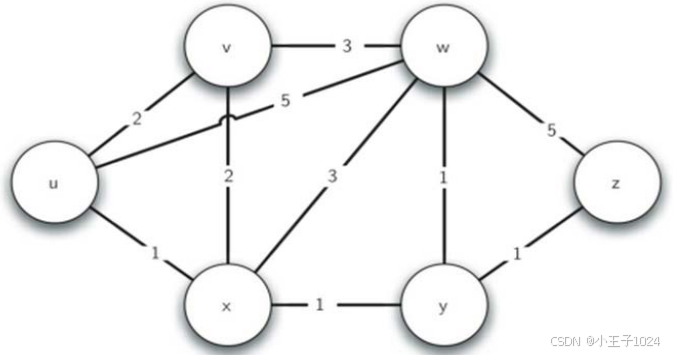
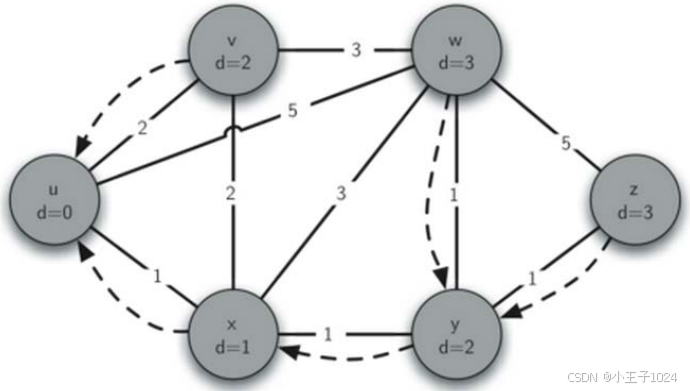
最短路径问题-示例
# 构建图
edges = [
["u", "v", 2],
["u", "x", 1],
["u", "w", 5],
["v", "w", 3],
["v", "x", 2],
["x", "w", 3],
["x", "y", 1],
["w", "y", 1],
["w", "z", 5],
["y", "z", 1],
]
g = Graph()
for i in edges:
g.add_edge(i[0], i[1], i[2])
g.add_edge(i[1], i[0], i[2])
dijkstra(g, g.vertexes["u"])
def get_path(cur: Vertex, start: Vertex):
"""获取从当前顶点到开始顶点的路径"""
tmp = []
tmp.append(cur.key)
while cur != start:
cur = cur.get_pred()
tmp.append(cur.key)
return tmp
for i in g.vertexes.values():
print(
f'顶点:{i.key},最短距离:{i.distance},最短路径:{get_path(i, g.vertexes["u"])}'
)
输出结果
顶点:u,最短距离:0,最短路径:['u']
顶点:v,最短距离:2,最短路径:['v', 'u']
顶点:x,最短距离:1,最短路径:['x', 'u']
顶点:w,最短距离:3,最短路径:['w', 'y', 'x', 'u']
顶点:y,最短距离:2,最短路径:['y', 'x', 'u']
顶点:z,最短距离:3,最短路径:['z', 'y', 'x', 'u']
二、图的应用-最小生成树
信息广播问题
- 单播解法:广播源维护一个收听者的列表,将每条消息采用最短路径算法向每个收听者发送一次。如果有4个收听者,则每条消息会被发送4次,会产生许多额外流量。
- 洪水解法:所有的路由器都将收到的消息转发到自己相邻的路由器和收听者,如果没有任何限制,这个方法将造成网络洪水灾难,永不停止!给每条消息附加一个生命值(TTL:Time To Live),每个路由器收到一条消,如果其TTL值大于0,则将TTL减少1,再转发出去。
- 最小生成树:信息广播问题的最优解法
- 路由器关系图上选取具有最小权重的生成树(minimum weight spanning tree)
- 生成树:拥有图中所有的顶点和最少数量的边,以保持连通的子图。
- 图G(V,E)的最小生成树T,定义为包含所有顶点V,以及E的无圈子集,并且边权重之和最小
最小生成树-Prim算法
- Prim算法,属于“贪心算法”,即每步都沿着最小权重的边向前搜索。如果T还不是生成树,则反复做:
- 找到一条最小权重的可以安全添加的边,将边添加到树T
- “可以安全添加”的边,定义为一端顶点在树中,另一端不在树中的边,以便保持树的无圈特性
Prim算法实现
- 优先队列BinaryHeap类:增加特殊方法
__contains__方法,实现in语法判断 - Prim函数:实现Prim算法
class BinaryHeap:
def __contains__(self, key):
"""实现in语法判断"""
return key in self.heap_list
# 其它代码详见《数据结构与算法Python版 二叉堆与优先队列》
def prim(g: Graph, start: Vertex):
"""prim算法实现"""
bh = BinaryHeap()
# 开始顶点distance设为0
start.set_distance(0)
# 全部加入优先队列
bh.build_heap([v for v in g])
while not bh.is_empty():
# 每次最低distance顶点出队(贪婪算法)
cur_vert = bh.del_min()
for next_vert in cur_vert.get_connections():
new_dist = cur_vert.get_weight(next_vert)
if next_vert in bh and new_dist < next_vert.get_distance():
next_vert.set_pred(cur_vert)
next_vert.set_distance(new_dist)
bh.rebuild_heap()
最小生成树-示例
# 构建图
edges = [
["A", "B", 2],
["A", "C", 3],
["B", "C", 1],
["B", "D", 1],
["B", "E", 4],
["C", "F", 5],
["D", "E", 1],
["E", "F", 1],
["F", "G", 1],
]
g = Graph()
for i in edges:
g.add_edge(i[0], i[1], i[2])
g.add_edge(i[1], i[0], i[2])
# 执行prim算法,并打印结果
prim(g, g.vertexes["A"])
def get_path(cur: Vertex, start: Vertex):
"""获取从当前顶点到开始顶点的路径"""
tmp = []
tmp.append(cur.key)
while cur != start:
cur = cur.get_pred()
tmp.append(cur.key)
return tmp
for i in g.vertexes.values():
print(f'顶点:{i.key},最小生成树路径:{get_path(i, g.vertexes["A"])}')
输出结果
顶点:A,最小生成树路径:['A']
顶点:B,最小生成树路径:['B', 'A']
顶点:C,最小生成树路径:['C', 'B', 'A']
顶点:D,最小生成树路径:['D', 'B', 'A']
顶点:E,最小生成树路径:['E', 'D', 'B', 'A']
顶点:F,最小生成树路径:['F', 'E', 'D', 'B', 'A']
顶点:G,最小生成树路径:['G', 'F', 'E', 'D', 'B', 'A']
您正在阅读的是《数据结构与算法Python版》专栏!关注不迷路~

















 539
539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









