







一、归并排序
归并排序Merge Sort
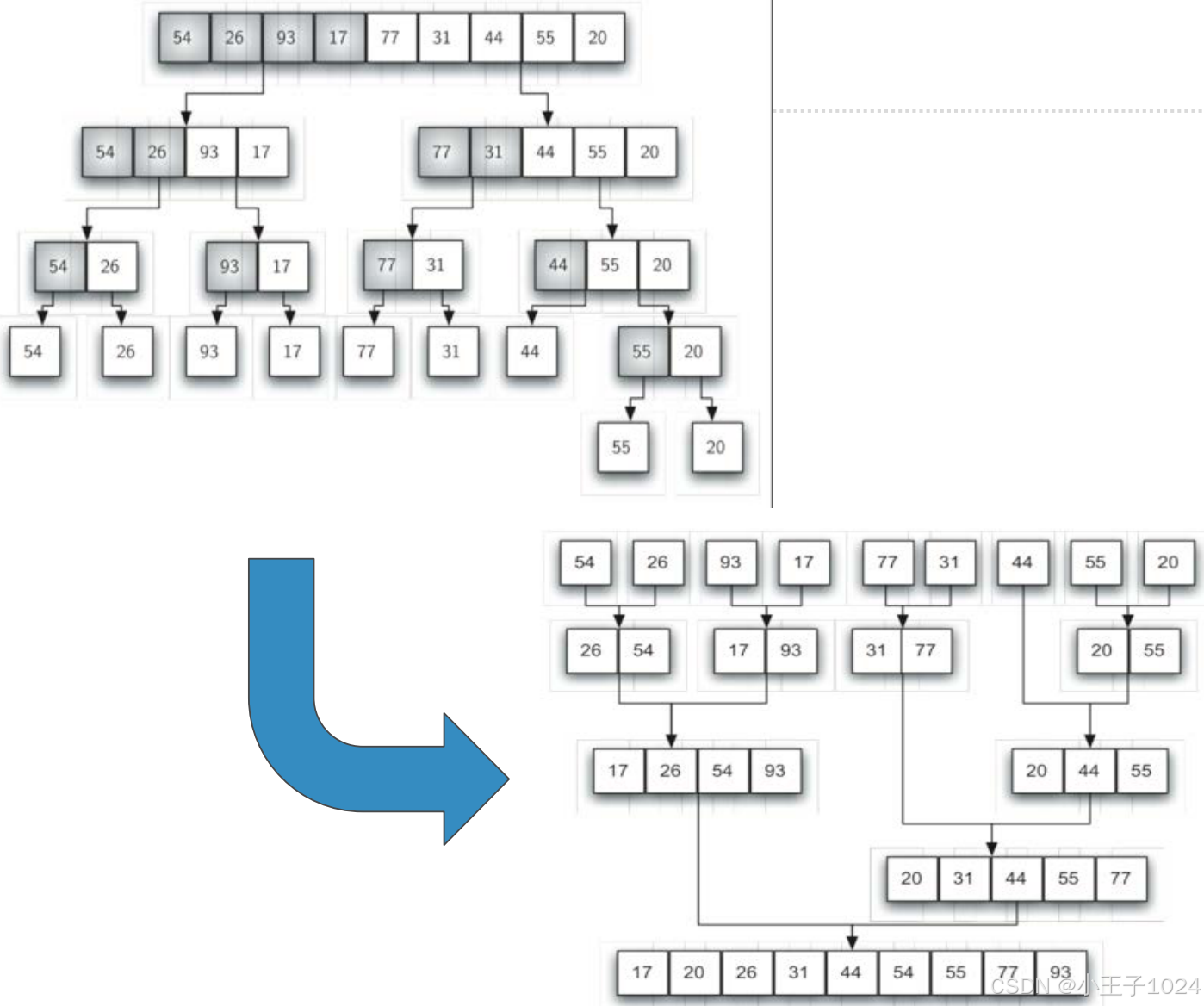
- 归并排序的思路是将数据表持续分裂为两半,对两半分别进行归并排序。属于递归算法,体现了分治策略在排序中的应用
- 递归的基本结束条件是:数据表仅有1个数据项,自然是排好序的;
- 缩小规模:将数据表分裂为两半,规模减为原来的二分之一;
- 调用自身:将两半分别调用自身排序,然后将分别排好序的两半进行归并,得到排好序的数据表
def merge_sort(lst):
# 数据项数量等于1,直接返回
if len(lst) <= 1:
return lst
# 数据项数量大于1,分裂为两半
mid = len(lst) // 2
left_lst = merge_sort(lst[:mid])
right_lst = merge_sort(lst[mid:])
# 对结果进行合并:每次比对左右半部第1个数据项,小的入列
result_lst = []
while left_lst and right_lst:
if left_lst[0] <= right_lst[0]:
result_lst.append(left_lst.pop(0))
else:
result_lst.append(right_lst.pop(0))
# 左右半部剩余项入列
result_lst.extend(left_lst if left_lst else right_lst)
return result_lst
test_list = [18, 48, 85, 67, 44, 36, 53, 32, 3, 5]
print(merge_sort(test_list))
### 输出结果
[3, 5, 18, 32, 36, 44, 48, 53, 67, 85]
归并排序-算法分析
- 将归并排序分为两个过程来分析:分裂和归并
- 分裂的过程,借鉴二分查找中的分析结果,是对数复杂度,时间复杂度为O(log n)
- 归并的过程,相对于分裂的每个部分,其所有数据项都会被比较和放置一次,所以是线性复杂度,其时间复杂度是O(n)
- 综合考虑,每次分裂的部分都进行一次O(n)的数据项归并,总的时间复杂度是O(nlog n)
- 归并排序算法使用了额外1倍的存储空间用于归并
二、快速排序
快速排序Quick Sort
- 快速排序的思路是依据一个“中值”数据项来把数据表分为两半:小于中值的一半和大于中值的一半,然后分别进行快速排序。也属于递归算法。
- 基本结束条件:数据表仅有1个数据项
- 缩小规模:根据“中值”,将数据表分裂分为两半,最好情况是相等规模的两半
- 调用自身:将两半分别调用自身进行排序
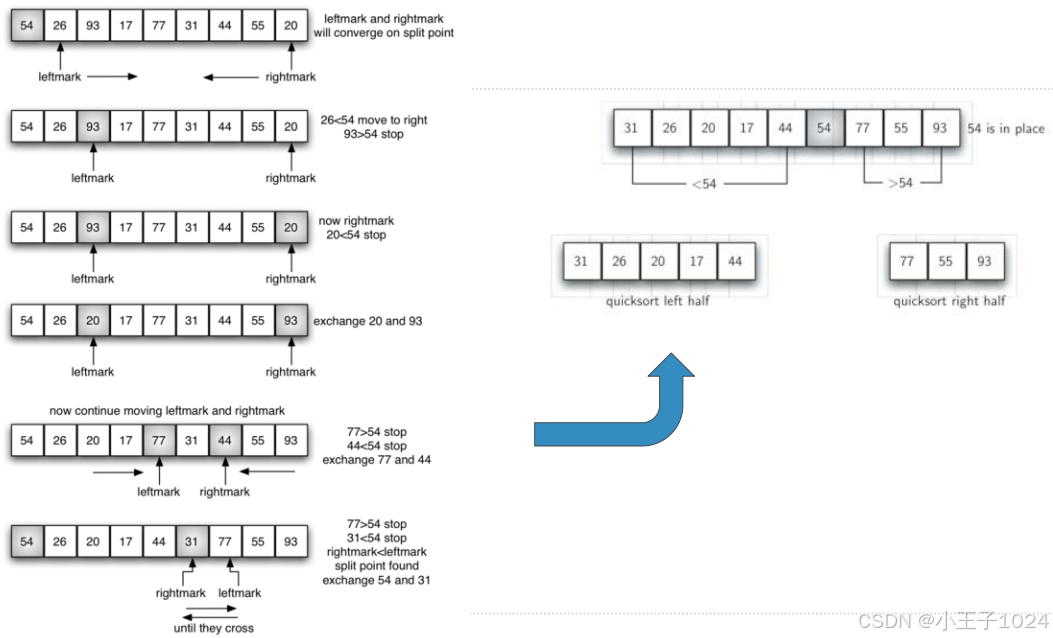
- 分裂过程
- 假设将表中第1项作为“中值”
- 设置左右标(left/rightmark),左标向右移动,右标向左移动
- 左标一直向右移动,碰到比中值大的就停止;右标一直向左移动,碰到比中值小的就停止;然后把左右标所指的数据项交换
- 重复上面步骤,直到左标移到右标的右侧,停止移动。这时,将中值和右标所指位置数据项交换
- 分裂完成,左半部比中值小,右半部比中值大
示例:第1趟分裂过程
def quick_sort(lst, first, last):
if first < last: # 基本结束条件
pivot_value = lst[first]
left_mark = first + 1
right_mark = last
done = False
while not done:
# 左标向右移动
while left_mark <= right_mark and lst[left_mark] <= pivot_value:
left_mark += 1
# 右标向左移动
while lst[right_mark] >= pivot_value and right_mark >= left_mark:
right_mark -= 1
# 直到左标移到右标的右侧
if right_mark < left_mark:
done = True
else:
# 左右标所指的数据项交换
lst[left_mark], lst[right_mark] = lst[right_mark], lst[left_mark]
# 中值与右标所指数据项交换
lst[first], lst[right_mark] = lst[right_mark], lst[first]
quick_sort(lst, first, right_mark - 1)
quick_sort(lst, right_mark + 1, last)
test_list = [18, 48, 85, 67, 44, 36, 53, 32, 3, 5]
quick_sort(test_list, 0, len(test_list) - 1)
print(test_list)
### 输出结果
[3, 5, 18, 32, 36, 44, 48, 53, 67, 85]
快速排序-算法分析
- 快速排序过程分为两部分:分裂和移动。如果分裂总能把数据表分为相等的两部分,那么就是O(log n)的复杂度;而移动需要将每项都与中值进行比对,还是O(n)。综合起来就是
O(nlog n) - 与归并排序算法不同,快速排序不需要额外的存储空间
- 快速排序的关键是“中值”的选取,如果分裂时造成左或右部分始终没有数据,时间复杂度退化到O(n^2)。此时,加上递归调用开销,性能比冒泡排序还差。
- 中值取值的方法:三数取中法,九数取中法,随机取中法等
三、小结
在解决实际问题时,不要只考虑算法理论的时间复杂度,需要综合考虑算法的运行环境要求、处理数据对象的特性等因素,来选择合适的算法。
您正在阅读的是《数据结构与算法Python版》专栏!关注不迷路~

















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









