







一、插入排序
插入排序Insertion Sort
- 插入排序维持一个已排好序的子列表,其位置始终在列表的前部,然后逐步扩大这个子列表直到全表
- 第1趟,子列表仅包含第1个数据项,将第2个数据项作为“新项”插入到子列表的合适位置中,这样已排序的子列表就包含了2个数据项
- 第2趟,再继续将第3个数据项跟前2个数据项比对,并移动比自身大的数据项,空出位置来,以便加入到子列表中
- 经过n-1趟比对和插入,子列表扩展到全表,排序完成
- 插入排序时间复杂度仍然是O(n^2)
- 插入排序的比对主要用来寻找“新项”的插入位置
- 最差情况是每趟都与子列表中所有项进行比对,总比对次数与冒泡排序相同,数量级仍是O(n^2)
- 最好情况,列表已经排好序的时候,每趟仅需1次比对,总次数是O(n)
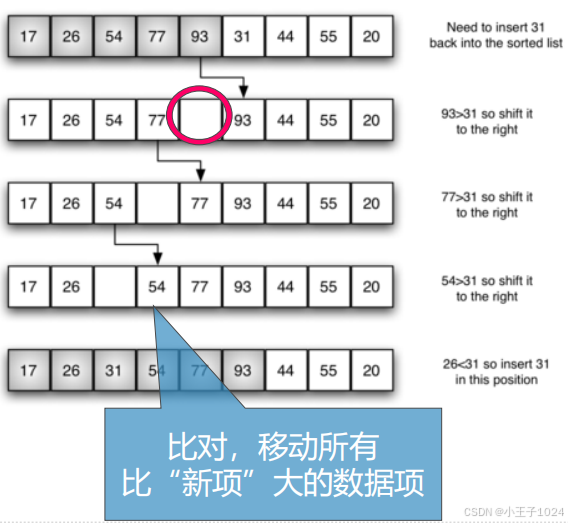
示例:第5趟,对第6个数据项“31”,跟前面5个数据项比对,并把比自身大的数据项向后移
def insertion_sort(lst):
for index in range(1, len(lst)): # n-1趟
current_value = lst[index] # 指向新项的值
position = index
while position > 0 and lst[position - 1] > current_value:
lst[position] = lst[position - 1] # 移动比自身大的数据项
position -= 1
lst[position] = current_value
test_list = [18, 48, 85, 67, 44, 36, 53, 32, 3, 5]
insertion_sort(test_list)
print(test_list)
### 输出结果
[3, 5, 18, 32, 36, 44, 48, 53, 67, 85]
二、谢尔排序
谢尔排序Shell Sort
- 谢尔排序以插入排序作为基础,对无序表以间隔划分为多个子列表,对每个子列表分别执行插入排序
- 插入排序的比对次数,在最好的情况下是O(n),这种情况发生在列表已是有序的情况下,实际上,列表越接近有序,插入排序的比对次数就越少
- 子列表的间隔从n/2开始(即子列表数量从2个开始),然后到n/4, n/8……直到1(即n个子列表)。n个子列表代表最后一趟是标准的插入排序,但由于前面几趟已经将列表处理到接近有序,这一趟仅需少数几次移动即可完成
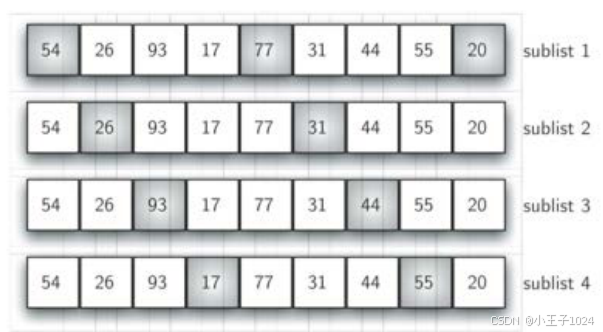
示例:以间隔为4,划分为4个子列表
def insertion_sort_gap(lst, start, gap):
"""
对列表中指定的子列表进行插入排序
指定的子列表是指:开始下标为start,间隔为gap所形成的列表
"""
for index in range(start + gap, len(lst), gap):
current_value = lst[index]
position = index
while position >= gap and lst[position - gap] > current_value:
lst[position] = lst[position - gap]
position -= gap
lst[position] = current_value
def shell_sort(lst):
# 子列表的间隔:从n/2开始,然后到n/4, n/8……直到1
gap = len(lst) // 2
while gap > 0:
# 子列表进行插入排序
for start in range(gap):
insertion_sort_gap(lst, start, gap)
# 打印不同间隔下子列表的排序的结果
print(gap, lst)
gap //= 2
test_list = [18, 48, 85, 67, 44, 36, 53, 32, 3, 5]
shell_sort(test_list)
### 输出结果
5 [18, 48, 32, 3, 5, 36, 53, 85, 67, 44]
2 [5, 3, 18, 36, 32, 44, 53, 48, 67, 85]
1 [3, 5, 18, 32, 36, 44, 48, 53, 67, 85]
谢尔排序-算法分析
- 谢尔排序以插入排序为基础,由于每趟都使得列表更加接近有序,这过程会减少很多原先需要的“无效”比对
- 谢尔排序的时间复杂度约为
O(n^(3/2)),介于O(n)和O(n^2)之间
您正在阅读的是《数据结构与算法Python版》专栏!关注不迷路~

















 1355
1355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









