







 该博客围绕网络架构代码展开,重点解析先验框生成代码,以block8为例,详细讲解了先验框生成对应关系、np.mgrid的使用及计算过程,还涉及h和w的计算。同时提出疑问,探讨为何无法与论文中的对应关系一致,最后介绍了np.mgrid的指令知识点。
该博客围绕网络架构代码展开,重点解析先验框生成代码,以block8为例,详细讲解了先验框生成对应关系、np.mgrid的使用及计算过程,还涉及h和w的计算。同时提出疑问,探讨为何无法与论文中的对应关系一致,最后介绍了np.mgrid的指令知识点。
0 上一节没写完的代码
从零开始(三)---网络架构1-2
https://blog.youkuaiyun.com/zjc910997316/article/details/95518998
#!usr/bin/python
# -*- coding: utf-8 -*-
# Creation Date: 2019/7/10
import tensorflow as tf
import numpy as np
import cv2
class ssd(object):
def __init__(self):
# ===>完善:构造函数的参数<===
self.num_boxes = [] # 统计锚点框的个数
self.feaeture_map_size = [(38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)] # 特征图的大小
self.classes = ["aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"] # 这里有20个,加上背景是21个类别
self.feature_layers = ['block4', 'block7', 'block8', 'block9', 'block10', 'block11'] # 用于检测的特征层的名字
self.img_size = (300, 300) # 图片的大小
self.num_classes = 21 # 类别的个数,背景也算一类, 第一个类似是:'bg'背景
self.boxes_len = [4, 6, 6, 6, 4, 4] # 6个特征图生成的一组锚点框的框的个数,4 10 11层是4个一组其它的是6个一组
# block4: 38x38大小的特征图就会生成 38x38x4 个锚点框 5766
# block7: 19x19大小的特征图就会生成 19x19x6 个锚点框 2166
# block8: 10x10大小的特征图就会生成 10x10x6 个锚点框 600
# block9: 5x5大小的特征图就会生成 5x5x6 个锚点框 150
# block10: 3x3大小的特征图就会生成 3x3x4 个锚点框 36
# block11: 1x1大小的特征图就会生成 1x1x4 个锚点框 4
# 一共8732个锚点框 ?=?我算出来的是8722个
self.isL2norm = [True, False, False, False, False, False] # block4比较靠前, 因为norm太大需要L2norm
# ?=?如何起作用的呢
# ===>l2正则化<===
def l2norm(self, x, scale, trainable=True, scope='L2Normalization'):
n_channels = x.get_shape().as_list()[-1] # 通道数. 得到形状,变成列表,取后一个
l2_norm = tf.nn.l2_normalize(x, dim=[3], epsilon=1e-12) # 只对每个像素点在channels上做归一化
with tf.variable_scope(scope):
gamma = tf.get_variable("gamma", shape=[n_channels, ], dtype=tf.float32,
initializer=tf.constant_initializer(scale),
trainable=trainable)
return l2_norm * gamma
# ===>下面开始定义所需组件<===
# conv2d, max_pool2d, pad2d, dropout
# 定义一个卷积的操作 1输入 2卷积核个数 3卷积核大小 4步长 5padding 6膨胀 7激活函数 8名字
def conv2d(self, x, filter, # 输入x, 卷积核的个数filter
k_size, stride=[1, 1], # k_size卷积核是几*几,步长stride
padding='same', dilation=[1, 1], # padding, 空洞卷积指数这里1代表正常卷积
activation=tf.nn.relu, scope='conv2d'): # 激活函数relu, 名字scope
return tf.layers.conv2d(input=x, filters=filter, kernel_size=k_size,
strides=stride, padding=padding, dilation_rate=dilation,
name=scope, activation=activation)
def max_pool2d(self, x, pool_size, stride, scope='max_pool2d'): # 我猜padding是vaild
return tf.layers.max_pooling2d(inputs=x, pool_size=pool_size, strides=stride, padding='valid', name=scope)
# 用于填充s=2的第8,9层. 从6层往后的卷积层需要自己填充, 不要用它自带的填充.
def pad2d(self, x, pad):
return tf.pad(x, paddings=[[0, 0], [pad, pad], [pad, pad], [0, 0]])
def dropout(self, x, d_rate=0.5):
return tf.layers.dropout(inputs=x, rate=d_rate)
def ssd_prediction(self, x, num_classes, box_len, isL2norm, scope='multibox'):
reshape = [-1] + x.getshape().as_list()[1:-1] # 去除1 4维度,拿到2 3维度,变成列表.
# block8为例:shape = (?, 10, 10, 512)需要把23维度拿出来
# 前面的-1表示batch, 因为不知道是多少在这里tf一般写-1
with tf.variable_scope(scope): # 开始进行卷积
if isL2norm:
x = self.l2norm(x) # 先判断是否需要归一化
# ==>预测位置:坐标和大小,回归问题:不需softmax
location_pred = self.conv2d(x, filter=box_len * 4, k_size=[3 * 3], activation=None, scope='conv_loc')
'''filter:卷积核的个数=一个锚点多少框 x 一个框对应的4个数据xywh, 卷积核3x3,不需要激活函数,默认def conv2d有激活函数的'''
location_pred = tf.reshape(location_pred, reshape + [box_len, 4]) # 每个中心点生成一个锚点框?=?
# ==>预测类别:分类问题:需要softmax
class_pred = self.conv2d(x, filter=box_len * num_classes, k_size=3 * 3, activation=None,
scope='conv_cls')
'''filter:卷积核的个数=一个锚点多少框 x 一个框对应的21个类别, 卷积核3x3,不需要激活函数,默认def conv2d是有激活函数的'''
class_pred = tf.shape(class_pred, reshape + [box_len, num_classes]) # ?=?
print(location_pred, class_pred)
return location_pred, class_pred
# ===>下面开始写网络架构<===
def set_net(self):
check_points = {} # 装特征层的字典,用于循环迭代
predictions = []
locations = []
x = tf.placeholder(dtype=tf.float32, shape=[None, 300, 300, 3])
with tf.variable_scope('ssd_300_vgg'):
# ===>VGG前5层<===
# b1
net = self.conv2d(x, filter=64, k_size=[3, 3], scope='conv1_1') # 64个3*3卷积核, s=1 默认,标准卷积
net = self.conv2d(net, 64, [3, 3], scope='conv1_2') # 64个3*3卷积核, s=1默认
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2]) # 池化层2*2卷积核, s=2 默认,池化层一般都是2
# b2
net = self.conv2d(net, filter=128, k_size=[3, 3], scope='conv2_1')
net = self.conv2d(net, 128, [3, 3], scope='conv2_2')
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2], scope='pool2')
# b3
net = self.conv2d(net, filter=256, k_size=[3, 3], scope='conv3_1')
net = self.conv2d(net, 256, [3, 3], scope='conv3_2')
net = self.conv2d(net, 256, [3, 3], scope='conv3_3')
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2], scope='pool3')
# b4 =>第1个检测层
net = self.conv2d(net, filter=512, k_size=[3, 3], scope='conv4_1')
net = self.conv2d(net, 512, [3, 3], scope='conv4_2')
net = self.conv2d(net, 512, [3, 3], scope='conv4_3')
check_points['block4'] = net
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2], scope='pool4')
# b5 关键部分来了,这里与vgg不同了
net = self.conv2d(net, filter=512, k_size=[3, 3], scope='conv5_1')
net = self.conv2d(net, 512, [3, 3], scope='conv5_2')
net = self.conv2d(net, 512, [3, 3], scope='conv5_3')
net = self.max_pool2d(net, pool_size=[3, 3], stride=[1, 1], scope='pool5') # =>池化层3*3核, 步长变成1*1
# ===>卷积层,代替VGG全连接层<===
# b6 conv6: 3x3x1024-d6
net = self.conv2d(net, filter=1024, k_size=[3, 3], dilation=[6, 6], scope='conv6')
# => 个数1024, dilation=[6, 6]
# b7 conv7: 1x1x1024 =>第2个检测层
net = self.conv2d(net, filter=1024, k_size=[3, 3], scope='conv7')
# => 个数1024, 卷积核不是[1, 1] ?=?
check_points['block7'] = net
# b8 conv8_1: 1x1x256; conv8_2: 3x3x512-s2-vaild =>第3个检测层
net = self.conv2d(net, 256, [1, 1], scope='conv8_1x1') # =>个数256,卷积核1x1
net = self.conv2d(self.pad2d(net, 1), 512, [3, 3], [2, 2], scope='conv8_3x3', padding='valid')
# =>个数512, 卷积核3x3, 步长2, 'valid'
check_points['block8'] = net
# b9 conv9_1: 1x1x128 conv8_2: 3x3x256-s2-vaild =>第4个检测层
net = self.conv2d(net, 128, [1, 1], scope='conv9_1x1') # =>个数128,卷积核1x1
net = self.conv2d(self.pad2d(net, 1), 256, [3, 3], [2, 2], scope='conv9_3x3', padding='valid')
# =>个数256,卷积核3x3,步长2x2, valid
check_points['block9'] = net
# b10 conv10_1: 1x1x128 conv10_2: 3x3x256-s1-valid =>第5个检测层
net = self.conv2d(net, 128, [1, 1], scope='conv10_1x1') # =>个数128,卷积核1x1
net = self.conv2d(net, 256, [3, 3], scope='conv10_3x3', padding='valid')
# =>个数256,valid
check_points['block10'] = net
# b11 conv11_1: 1x1x128 conv11_2: 3x3x256-s1-valid =>第6检测层
net = self.conv2d(net, 128, [1, 1], scope='conv11_1x1') # =>个数128,卷积核1x1
net = self.conv2d(net, 256, [3, 3], scope='conv11_3x3', padding='valid')
# =>个数256, valid
check_points['block11'] = net
for i, j in enumerate(self.feature_layers): # 枚举特征层 i是个数, j是名字 blockx
loc, cls = self.ssd_prediction(x=check_points[j],
num_classes=self.classes,
box_len=self.boxes_len[i],
isL2norm=self.isL2norm[i],
scope=j + '_box'
)
predictions.append(tf.nn.softmax(cls)) # 需要softmax
locations.append(loc) # 不需要
print(check_points) # 检查网络的结构, eg:block8: (?, 10, 10, 512)
print(locations, predictions)
if __name__ == '__main__':
sd = ssd()
sd.set_net()本节重点代码部分解析如下:
init 初始化:
def __init__(self): # ===>完善:构造函数的参数<=== self.num_boxes = [] # 统计锚点框的个数 self.feaeture_map_size = [(38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)] # 特征图的大小 self.classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"] # 这里有20个,加上背景是21个类别 self.feature_layers = ['block4', 'block7', 'block8', 'block9', 'block10', 'block11'] # 用于检测的特征层的名字 self.img_size = (300, 300) # 图片的大小 self.num_classes = 21 # 类别的个数,背景也算一类, 第一个类似是:'bg'背景 self.boxes_len = [4, 6, 6, 6, 4, 4] # 6个特征图生成的一组锚点框的框的个数,4 10 11层是4个一组,其它的是6个一组 # block4: 38x38大小的特征图就会生成 38x38x4 个锚点框 5766 # block7: 19x19大小的特征图就会生成 19x19x6 个锚点框 2166 # block8: 10x10大小的特征图就会生成 10x10x6 个锚点框 600 # block9: 5x5大小的特征图就会生成 5x5x6 个锚点框 150 # block10: 3x3大小的特征图就会生成 3x3x4 个锚点框 36 # block11: 1x1大小的特征图就会生成 1x1x4 个锚点框 4 # 一共8732个锚点框 ?=?我算出来的是8722个 self.isL2norm = [True, False, False, False, False, False] # block4比较靠前, 因为norm太大需要L2norm self.anchor_size = [(21., 45.), (45., 99.), (99., 153.), (153., 207.), (207., 261.), (261., 315.)] self.anchor_ratios = [[2, .5], [2, .5, 3, 1./3], [2, .5, 3, 1./3], [2, .5, 3, 1./3], [2, .5], [2, .5]] self.anchor_steps = [8, 16, 32, 64, 100, 300] self.prior_scaling = [0.1, 0.1, 0.2, 0.2] # 特征先验框缩放比例: 0.1:xy坐标的缩放比, 0.2:wy坐标的缩放比 self.n_boxes = [5776, 2166, 600, 150, 36, 4]def 先验框生成:
def ssd_anchor_layer(self, img_size, feature_map_size, anchor_size, anchor_ratio, anchor_step, box_num, offset=0.5): # 提取feature map 的每一个坐标 y, x = np.mgrid[0: feature_map_size[0], 0:feature_map_size[1]] # 以block8为例这里是 0:10,0:10 y = (y.astype(np.float32) + offset) * anchor_step / img_size[0] x = (x.astype(np.float32) + offset) * anchor_step / img_size[1] # 计算两个长宽比为1的 h, w h = np.zeros((box_num,), np.float32) w = np.zeros((box_num,), np.float32) h[0] = anchor_size[0] / img_size[0] # 小正方形 w[0] = anchor_size[0] / img_size[0] h[1] = (anchor_size[0] * anchor_size[1]) ** 0.5 / img_size[0] # 大正方形 w[1] = (anchor_size[0] * anchor_size[1]) ** 0.5 / img_size[0] for i, j in enumerate(anchor_ratio): h[i + 2] = anchor_size[0] / img_size[0] / (j ** 0.5) w[i + 2] = anchor_size[0] / img_size[0] * (j ** 0.5) return x, y, h, wmain 主函数:
if __name__ == '__main__': sd = ssd() locations, predictions, x = sd.set_net() box = sd.ssd_anchor_layer(sd.img_size, (10, 10), (99., 153.), [2., .5, 3., 1/3], 32, 6) boex = sd.ssd_decode(locations[2], box, sd.prior_scaling) print(boex) # shape = (?, 10, 10, 6, 4) # 这里以block8为例:的输出结果为Tensor("stacck:0", shape=(?, 10, 10, 6, 4), dtype=float32) # 10, 10表示的是第三个特征层为10x10, 因为是locations[2] ?=? # 6表示六个特征图 ?=? # 4表示 左上角&右下角坐标 max_x max_y min_x min_y # locations[0]是38x38 locations[1]是19x19 locations[2]是10x10 locations[3]是5x5 [4]是3x3 [5]是2x2 [6]是1x1 cls, sco, a_box = sd.choose_anchor_boxes(predictions[2], boex, sd.n_boxes[2]) print('----------------------------') print(cls, sco, a_box)
逐步解析:本代码以block8为例
1 ===> 先验框生成对应关系:def函数 & 主函数<===
# def 定义函数
def ssd_anchor_layer( self,
img_size, feature_map_size,
anchor_size, anchor_ratio, anchor_step,
box_num, offset=0.5 ):# main 函数赋值
box = sd.ssd_anchor_layer(
sd.img_size, (10, 10),
(99., 153.), [2., .5, 3., 1/3], 32,
6)
2 ===> np.mgrid <===
=> y, x = np.mgrid[0: feature_map_size[0], 0:feature_map_size[1]] PS:=>表示是本节解释的源代码,其他代码都是辅助
# 以block8为例这里是 0:10,0:10
# PS: 这里x,y换位置了,很奇怪哦
# >>> print(x)
# [[0 1 2 3 4 5 6 7 8 9]
# [0 1 2 3 4 5 6 7 8 9]
# [0 1 2 3 4 5 6 7 8 9]
# [0 1 2 3 4 5 6 7 8 9]
# [0 1 2 3 4 5 6 7 8 9]
# [0 1 2 3 4 5 6 7 8 9]
# [0 1 2 3 4 5 6 7 8 9]
# [0 1 2 3 4 5 6 7 8 9]
# [0 1 2 3 4 5 6 7 8 9]
# [0 1 2 3 4 5 6 7 8 9]]# >>> print(y)
# [[0 0 0 0 0 0 0 0 0 0]
# [1 1 1 1 1 1 1 1 1 1]
# [2 2 2 2 2 2 2 2 2 2]
# [3 3 3 3 3 3 3 3 3 3]
# [4 4 4 4 4 4 4 4 4 4]
# [5 5 5 5 5 5 5 5 5 5]
# [6 6 6 6 6 6 6 6 6 6]
# [7 7 7 7 7 7 7 7 7 7]
# [8 8 8 8 8 8 8 8 8 8]
# [9 9 9 9 9 9 9 9 9 9]]anchor_steps = img_size / feaeture_map_size ?=?应该是这样吧
self.img_size = (300, 300) # 图片的大小
# 因为特征图的大小是
self.feaeture_map_size = [ (38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1) ]
# 因而
self.anchor_steps = [ 8, 16, 32, 64, 100, 300]
# 因为存在padding的原因所以计算不等于300吗 ?=?
38x8 = 304
19x16 = 304
10x32 = 320
5x64 = 320
3x100 = 300
1x300 = 300
3 ===> np.mgrid <===
=> y = ( y.astype(np.float32) + offset ) * anchor_step / img_size[0] = (y矩阵 + 0.5)×32 / 300
=> x = ( x.astype(np.float32) + offset ) * anchor_step / img_size[1] = (x矩阵 + 0.5)×32 / 300
#>>> y+0.5
array([[ 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5],
[ 1.5, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5, 1.5],
[ 2.5, 2.5, 2.5, 2.5, 2.5, 2.5, 2.5, 2.5, 2.5, 2.5],
[ 3.5, 3.5, 3.5, 3.5, 3.5, 3.5, 3.5, 3.5, 3.5, 3.5],
[ 4.5, 4.5, 4.5, 4.5, 4.5, 4.5, 4.5, 4.5, 4.5, 4.5],
[ 5.5, 5.5, 5.5, 5.5, 5.5, 5.5, 5.5, 5.5, 5.5, 5.5],
[ 6.5, 6.5, 6.5, 6.5, 6.5, 6.5, 6.5, 6.5, 6.5, 6.5],
[ 7.5, 7.5, 7.5, 7.5, 7.5, 7.5, 7.5, 7.5, 7.5, 7.5],
[ 8.5, 8.5, 8.5, 8.5, 8.5, 8.5, 8.5, 8.5, 8.5, 8.5],
[ 9.5, 9.5, 9.5, 9.5, 9.5, 9.5, 9.5, 9.5, 9.5, 9.5]])
#>>> x+0.5
array([[ 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5],
[ 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5],
[ 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5],
[ 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5],
[ 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5],
[ 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5],
[ 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5],
[ 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5],
[ 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5],
[ 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5]])注意:下面示意图仅表示紫色部分,还要 * anchor_step / 300 归一化 ?=?
y = ( y.astype(np.float32) + offset ) * anchor_step / img_size[0] = (y矩阵 + 0.5)×32 / 300
x = ( x.astype(np.float32) + offset ) * anchor_step / img_size[1] = (x矩阵 + 0.5)×32 / 300
PS:绿色部分省略了y坐标
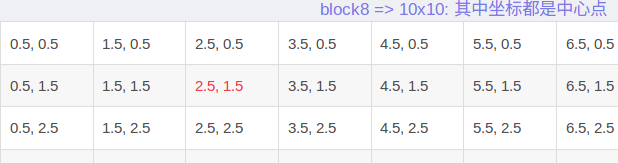
block8 => 10x10: 其中坐标都是中心点 0.5, 0.5 1.5, 0.5 2.5, 0.5 3.5, 0.5 4.5, 0.5 5.5, 0.5 6.5, 0.5 7.5, 0.5 8.5, 0.5 9.5, 0.5 0.5, 1.5 1.5, 1.5 2.5, 1.5 3.5, 1.5 4.5, 1.5 5.5, 1.5 6.5, 1.5 7.5, 1.5 8.5, 1.5 9.5, 1.5 0.5, 2.5 1.5, 2.5 2.5, 2.5 3.5, 2.5 4.5, 2.5 5.5, 2.5 6.5, 2.5 7.5, 2.5 8.5, 2.5 9.5, 2.5 0.5, 3.5 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5, 0.5, 4.5 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5, 0.5, 5.5 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5, 0.5, 6.5 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5, 0.5, 7.5 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5, 0.5, 8.5 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5, 0.5, 9.5 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5, 9.5,
4 ===> 准备 h, w <===
# 计算两个长宽比为1的 h, w
=> h = np.zeros( (box_num,), np.float32 )
=> w = np.zeros( (box_num,), np.float32 )
ps: box_num = 6>>> h = np.zeros((6,),np.float32) >>> w = np.zeros((6,),np.float32) >>> h array([ 0., 0., 0., 0., 0., 0.], dtype=float32) >>> w array([ 0., 0., 0., 0., 0., 0.], dtype=float32)
5 ===>计算h, w<===
=> h [0] = anchor_size[0] / img_size[0] = 99./300 # 小正方形
=> w[0] = anchor_size[0] / img_size[0] = 99./300=> h[1] = (anchor_size[0] * anchor_size[1]) ** 0.5 / img_size[0] = (99. * 153.)**0.5 / 300 = 123.07315 # 大正方形
=> w[1] = (anchor_size[0] * anchor_size[1]) ** 0.5 / img_size[0] = (99. * 153.)**0.5 / 300 = 123.07315=> for i, j in enumerate(anchor_ratio): # 枚举特征层i表示第几个, j 是里面内容
=> h[i + 2] = anchor_size[0] / img_size[0] / (j ** 0.5)
=> w[i + 2] = anchor_size[0] / img_size[0] * (j ** 0.5)
=> return x, y, h, wPS:这里的
anchor_size = (99., 153.)
anchor_ratios = [2, .5, 3, 1./3]
self.img_size = (300, 300) # 图片的大小
self.anchor_size = [ (21., 45.), (45., 99.), (99., 153.), (153., 207.), (207., 261.), (261., 315.) ]
4 7 8 9 10 11 层
self.anchor_ratios = [ [2, .5], [2, .5, 3, 1./3], [2, .5, 3, 1./3], [2, .5, 3, 1./3], [2, .5], [2, .5] ]
2/1, 1/2 2/1, 1/2, 3/1, 1/3 2/1, 1/2, 3/1, 1/3 2/1, 1/2, 3/1, 1/3 2/1, 1/2 2/1, 1/2PS: def 先验框带入数据可以表示为:
anchor_ratio = [2, .5, 3, 1./3] anchor_size = (99., 153.) h = np.zeros((6,), np.float32) w = np.zeros((6,), np.float32) h[0] = 99. / 300 w[0] = 99. / 300 h[1] = (99. * anchor_size[1]) ** 0.5 / 300 w[1] = (99. * anchor_size[1]) ** 0.5 / 300 for i, j in enumerate(anchor_ratio): # 枚举特征层i表示第几个, j 是里面内容 h[i + 2] = 99. / 300 / (j ** 0.5) w[i + 2] = 99. / 300 * (j ** 0.5) # h[0]=99/300 w[0]=99/300: 小 正方型 h w # h[1]=sqrt(99*513)/300 w[1]=sqrt(99*513)/300: 大 正方型 h w # h[2]=99/300/sqrt(2) w[2]=99/300*sqrt(2): 横向 - 长方型2/1 对应 anchor_ratio[0] = 2 # h[3]=99/300/sqrt(0.5) w[2]=99/300*sqrt(0.5): 纵向 | 长方型1/2 对应 anchor_ratio[1] = .5 # h[4]=99/300/sqrt(3) w[2]=99/300*sqrt(3): 横向 - 长方型3/1 对应 anchor_ratio[2] = 3 # h[5]=99/300/sqrt(1/3) w[2]=99/300*sqrt(1/3): 纵向 | 长方型1/3 对应 anchor_ratio[3] = 1./3关于h, w列表的输出结果:
>>> h array([ 0.33000001, 0.41024384, 0.23334524, 0.46669048, 0.19052559, 0.57157677], dtype=float32) >>> w array([ 0.33000001, 0.41024384, 0.46669048, 0.23334524, 0.57157677, 0.19052559], dtype=float32)
疑问?=?
?=?为何无法与 block8的mgrid网格中对应关系像论文中一样
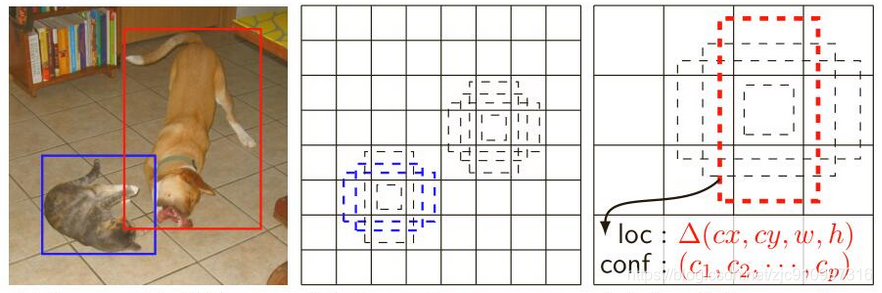
像下图一样
拿2.5, 1.5中心点为例
其配套的wh为
h[0]正方型 h[1]正方型 h[2]长方型2/1 h[3]长方型1/2 h[4]长方型3/1 h[5]长方型1/3>>> w = array([ 0.33000001, 0.41024384, 0.46669048, 0.23334524, 0.57157677, 0.19052559], dtype=float32)
>>> h = array([ 0.33000001, 0.41024384, 0.23334524, 0.46669048, 0.19052559, 0.57157677], dtype=float32)300x300的图,
block8:10x10
以w为例,2.5,1.5中心点对应的方格的宽为1, 大正方型的宽为0.41,大正方行仍然在格子里面,如法形成下图
指令知识点:
1 np.mgrid()
https://www.cnblogs.com/shenxiaolin/p/8854197.html (含有meshgrid与mgrid区别)
用法:返回多维结构,常见的如2D图形,3D图形。
对比np.meshgrid,在处理大数据时速度更快,且能处理多维(np.meshgrid只能处理2维)
ret = np.mgrid[ 第1维,第2维 ,第3维 , …]
返回多值,以多个矩阵的形式返回,第1返回值 为第1维数据在最终结构中的分布,
第2返回值 为第2维数据在最终结构中的分布,以此类推。(分布以矩阵形式呈现)例如np.mgrid[X , Y]
样本(i,j)的坐标为 (X[i,j] ,Y[i,j])
X代表第1维,Y代表第2维,在此例中分别为横, 纵坐标。
例如1D结构(array),如下:import numpy as np pp=np.mgrid[-5:5:5j] # 5j表示分成5份? pp Out[4]: array([-5. , -2.5, 0. , 2.5, 5. ])例如2D结构:
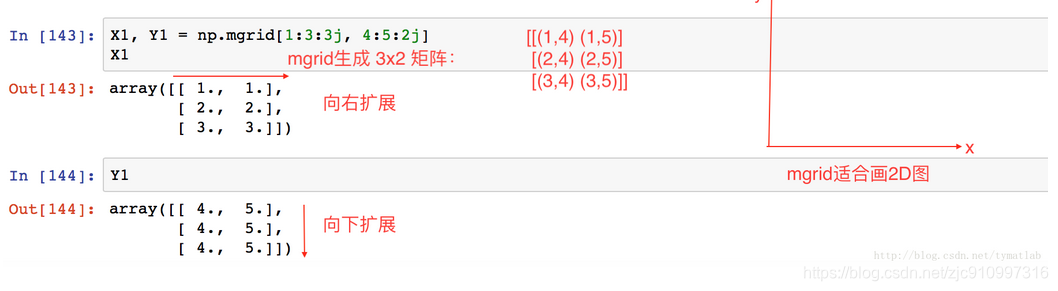
>>> pp = np.mgrid[-1:1:2j,-2:2:3j] # 2行3列, >>> x , y = pp >>> x array([[-1., -1., -1.], # x为第一行-1,第二行1 [ 1., 1., 1.]]) >>> y array([[-2., 0., 2.], # y为第一列-2,第二列0, 第三列2 [-2., 0., 2.]])总结:
1 先看几行几列,三行两列
2 x对应行: 第一行1, 第二行2, 第三行3, 扩展
3 y对应列: 第一列4, 第二列5 扩展
ssd算法中:注意源代码中xy是换位置的,看上面
>>> x, y= np.mgrid[0:10, 0:10] # 10行10列 >>> print(x) # 第一行为1,第二行为2,...,第十行为10 [[0 0 0 0 0 0 0 0 0 0] [1 1 1 1 1 1 1 1 1 1] [2 2 2 2 2 2 2 2 2 2] [3 3 3 3 3 3 3 3 3 3] [4 4 4 4 4 4 4 4 4 4] [5 5 5 5 5 5 5 5 5 5] [6 6 6 6 6 6 6 6 6 6] [7 7 7 7 7 7 7 7 7 7] [8 8 8 8 8 8 8 8 8 8] [9 9 9 9 9 9 9 9 9 9]] >>> print(y) # 第一列为1,第二列为2,...,第十列为10 [[0 1 2 3 4 5 6 7 8 9] [0 1 2 3 4 5 6 7 8 9] [0 1 2 3 4 5 6 7 8 9] [0 1 2 3 4 5 6 7 8 9] [0 1 2 3 4 5 6 7 8 9] [0 1 2 3 4 5 6 7 8 9] [0 1 2 3 4 5 6 7 8 9] [0 1 2 3 4 5 6 7 8 9] [0 1 2 3 4 5 6 7 8 9] [0 1 2 3 4 5 6 7 8 9]]
本节代码更新到最新
#!usr/bin/python
# -*- coding: utf-8 -*-
# Creation Date: 2019/7/10
import tensorflow as tf
import numpy as np
import cv2
''' 注释说明
# 1 /==== === === ===>xxxx<=== === ==== ===\ 为一级标题-start
\==== === === ===>xxxx<=== === === ====/ 为一级标题-end
# 2 /=== ===>xxxx<=== ===\ 为二级标题-start
\=== ===>xxxx<=== ===/ 为二级标题-end
# 2 |===xxx 为一二级标题的补充说明
# 3 ===>xxxx<=== 为三级标题
# 4 ===>xxx\ 为四级标题-start
# ===>xxx/ 为四级标题-end
# 5 => 为重点-特殊情况
# 6 ?=? 存在疑惑
'''
class ssd(object):
def __init__(self):
# ===>完善:构造函数的参数<===
self.num_boxes = [] # 统计锚点框的个数
self.feaeture_map_size = [(38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)] # 特征图的大小
self.classes = ["aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"] # 这里有20个,加上背景是21个类别
self.feature_layers = ['block4', 'block7', 'block8', 'block9', 'block10', 'block11'] # 用于检测的特征层的名字
self.img_size = (300, 300) # 图片的大小
self.num_classes = 21 # 类别的个数,背景也算一类, 第一个类似是:'bg'背景
self.boxes_len = [4, 6, 6, 6, 4, 4] # 6个特征图生成的一组锚点框的框的个数,4 10 11层是4个一组其它的是6个一组
# block4: 38x38大小的特征图就会生成 38x38x4 个锚点框 5766
# block7: 19x19大小的特征图就会生成 19x19x6 个锚点框 2166
# block8: 10x10大小的特征图就会生成 10x10x6 个锚点框 600
# block9: 5x5大小的特征图就会生成 5x5x6 个锚点框 150
# block10: 3x3大小的特征图就会生成 3x3x4 个锚点框 36
# block11: 1x1大小的特征图就会生成 1x1x4 个锚点框 4
# 一共8732个锚点框 ?=?我算出来的是8722个
self.isL2norm = [True, False, False, False, False, False] # block4比较靠前, 因为norm太大需要L2norm
self.anchor_size = [(21., 45.), (45., 99.), (99., 153.), (153., 207.), (207., 261.), (261., 315.)]
self.anchor_ratios = [[2, .5], [2, .5, 3, 1./3], [2, .5, 3, 1./3], [2, .5, 3, 1./3], [2, .5], [2, .5]]
self.anchor_steps = [8, 16, 32, 64, 100, 300]
'''
self.prior_scaling = [0.1, 0.1, 0.2, 0.2] # 特征先验框缩放比例: 0.1:xy坐标的缩放比, 0.2:wy坐标的缩放比
'''
# /==== === === ===>ssd网络架构部分<=== === === ====\
# ==== ===>l2正则化<=== ====
def l2norm(self, x, scale, trainable=True, scope='L2Normalization'):
n_channels = x.get_shape().as_list()[-1] # 通道数. 得到形状,变成列表,取后一个
l2_norm = tf.nn.l2_normalize(x, dim=[3], epsilon=1e-12) # 只对每个像素点在channels上做归一化
with tf.variable_scope(scope):
gamma = tf.get_variable("gamma", shape=[n_channels, ], dtype=tf.float32,
initializer=tf.constant_initializer(scale),
trainable=trainable)
return l2_norm * gamma
# /=== ===>下面:定义所需组件<=== ====\
# |===conv2d, max_pool2d, pad2d, dropout
# 定义一个卷积的操作 1输入 2卷积核个数 3卷积核大小 4步长 5padding 6膨胀 7激活函数 8名字
def conv2d(self, x, filter, # 输入x, 卷积核的个数filter
k_size, stride=[1, 1], # k_size卷积核是几*几,步长stride
padding='same', dilation=[1, 1], # padding, 空洞卷积指数这里1代表正常卷积
activation=tf.nn.relu, scope='conv2d'): # 激活函数relu, 名字scope
return tf.layers.conv2d(input=x, filters=filter, kernel_size=k_size,
strides=stride, padding=padding, dilation_rate=dilation,
name=scope, activation=activation)
def max_pool2d(self, x, pool_size, stride, scope='max_pool2d'): # 我猜padding是vaild
return tf.layers.max_pooling2d(inputs=x, pool_size=pool_size, strides=stride, padding='valid', name=scope)
# 用于填充s=2的第8,9层. 从6层往后的卷积层需要自己填充, 不要用它自带的填充.
def pad2d(self, x, pad):
return tf.pad(x, paddings=[[0, 0], [pad, pad], [pad, pad], [0, 0]])
def dropout(self, x, d_rate=0.5):
return tf.layers.dropout(inputs=x, rate=d_rate)
def ssd_prediction(self, x, num_classes, box_len, isL2norm, scope='multibox'):
reshape = [-1] + x.getshape().as_list()[1:-1] # 去除1 4维度,拿到2 3维度,变成列表.
# block8为例:shape = (?, 10, 10, 512)需要把23维度拿出来
# 前面的-1表示batch, 因为不知道是多少在这里tf一般写-1
with tf.variable_scope(scope): # 开始进行卷积
if isL2norm:
x = self.l2norm(x) # 先判断是否需要归一化
# ==>预测位置:坐标和大小,回归问题:不需softmax
location_pred = self.conv2d(x, filter=box_len * 4, k_size=[3 * 3], activation=None, scope='conv_loc')
'''filter:卷积核的个数=一个锚点多少框 x 一个框对应的4个数据xywh, 卷积核3x3,不需要激活函数,默认def conv2d有激活函数的'''
location_pred = tf.reshape(location_pred, reshape + [box_len, 4]) # 每个中心点生成一个锚点框?=?
# ==>预测类别:分类问题:需要softmax
class_pred = self.conv2d(x, filter=box_len * num_classes, k_size=3 * 3, activation=None,
scope='conv_cls')
'''filter:卷积核的个数=一个锚点多少框 x 一个框对应的21个类别, 卷积核3x3,不需要激活函数,默认def conv2d是有激活函数的'''
class_pred = tf.shape(class_pred, reshape + [box_len, num_classes]) # ?=?
print(location_pred, class_pred)
return location_pred, class_pred
# \=== ===>上面:定义所需组件<=== ====/
# /=== ===>下面:具体网络架构<=== ===\
def set_net(self):
check_points = {} # 装特征层的字典,用于循环迭代
predictions = []
locations = []
x = tf.placeholder(dtype=tf.float32, shape=[None, 300, 300, 3])
with tf.variable_scope('ssd_300_vgg'):
# ===>VGG前5层<===
# b1
net = self.conv2d(x, filter=64, k_size=[3, 3], scope='conv1_1') # 64个3*3卷积核, s=1 默认,标准卷积
net = self.conv2d(net, 64, [3, 3], scope='conv1_2') # 64个3*3卷积核, s=1默认
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2]) # 池化层2*2卷积核, s=2 默认,池化层一般都是2
# b2
net = self.conv2d(net, filter=128, k_size=[3, 3], scope='conv2_1')
net = self.conv2d(net, 128, [3, 3], scope='conv2_2')
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2], scope='pool2')
# b3
net = self.conv2d(net, filter=256, k_size=[3, 3], scope='conv3_1')
net = self.conv2d(net, 256, [3, 3], scope='conv3_2')
net = self.conv2d(net, 256, [3, 3], scope='conv3_3')
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2], scope='pool3')
# b4 =>第1个检测层
net = self.conv2d(net, filter=512, k_size=[3, 3], scope='conv4_1')
net = self.conv2d(net, 512, [3, 3], scope='conv4_2')
net = self.conv2d(net, 512, [3, 3], scope='conv4_3')
check_points['block4'] = net
net = self.max_pool2d(net, pool_size=[2, 2], stride=[2, 2], scope='pool4')
# b5 关键部分来了,这里与vgg不同了
net = self.conv2d(net, filter=512, k_size=[3, 3], scope='conv5_1')
net = self.conv2d(net, 512, [3, 3], scope='conv5_2')
net = self.conv2d(net, 512, [3, 3], scope='conv5_3')
net = self.max_pool2d(net, pool_size=[3, 3], stride=[1, 1], scope='pool5') # =>池化层3*3核, 步长变成1*1
# ===>卷积层,代替VGG全连接层<===
# b6 conv6: 3x3x1024-d6
net = self.conv2d(net, filter=1024, k_size=[3, 3], dilation=[6, 6], scope='conv6')
# => 个数1024, dilation=[6, 6]
# b7 conv7: 1x1x1024 =>第2个检测层
net = self.conv2d(net, filter=1024, k_size=[3, 3], scope='conv7')
# => 个数1024, 卷积核不是[1, 1] ?=?
check_points['block7'] = net
# b8 conv8_1: 1x1x256; conv8_2: 3x3x512-s2-vaild =>第3个检测层
net = self.conv2d(net, 256, [1, 1], scope='conv8_1x1') # =>个数256,卷积核1x1
net = self.conv2d(self.pad2d(net, 1), 512, [3, 3], [2, 2], scope='conv8_3x3', padding='valid')
# =>个数512, 卷积核3x3, 步长2, 'valid'
check_points['block8'] = net
# b9 conv9_1: 1x1x128 conv8_2: 3x3x256-s2-vaild =>第4个检测层
net = self.conv2d(net, 128, [1, 1], scope='conv9_1x1') # =>个数128,卷积核1x1
net = self.conv2d(self.pad2d(net, 1), 256, [3, 3], [2, 2], scope='conv9_3x3', padding='valid')
# =>个数256,卷积核3x3,步长2x2, valid
check_points['block9'] = net
# b10 conv10_1: 1x1x128 conv10_2: 3x3x256-s1-valid =>第5个检测层
net = self.conv2d(net, 128, [1, 1], scope='conv10_1x1') # =>个数128,卷积核1x1
net = self.conv2d(net, 256, [3, 3], scope='conv10_3x3', padding='valid')
# =>个数256,valid
check_points['block10'] = net
# b11 conv11_1: 1x1x128 conv11_2: 3x3x256-s1-valid =>第6检测层
net = self.conv2d(net, 128, [1, 1], scope='conv11_1x1') # =>个数128,卷积核1x1
net = self.conv2d(net, 256, [3, 3], scope='conv11_3x3', padding='valid')
# =>个数256, valid
check_points['block11'] = net
for i, j in enumerate(self.feature_layers): # 枚举特征层 i是个数, j是名字 blockx
loc, cls = self.ssd_prediction(x=check_points[j],
num_classes=self.classes,
box_len=self.boxes_len[i],
isL2norm=self.isL2norm[i],
scope=j + '_box'
)
predictions.append(tf.nn.softmax(cls)) # 需要softmax
locations.append(loc) # 不需要
print(check_points) # 检查网络的结构, eg:block8: (?, 10, 10, 512)
print(locations, predictions)
return locations, predictions, x
# \=== ===>上面:具体网络架构<=== ===/
# \=== === ===>ssd网络架构部分<=== === ===/
if __name__ == '__main__':
sd = ssd()
sd.set_net()


















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











