




 本文介绍Android性能分析工具Simpleperf的使用方法,包括命令行记录和分析应用性能数据,以及如何生成火焰图帮助开发者定位性能瓶颈。
本文介绍Android性能分析工具Simpleperf的使用方法,包括命令行记录和分析应用性能数据,以及如何生成火焰图帮助开发者定位性能瓶颈。
android性能分析之Systrace
android性能分析之常用命令
Android Studio 包含 Simpleperf 的图形前端,记录在使用 CPU 性能剖析器检查 CPU 活动中。大多数用户更喜欢使用该图形前端,而不是直接使用 Simpleperf。
Android Profiler分析(一)概述
Android Profiler分析(二) Memory Profiler
Android Profiler分析(三) CPU Profiler
如果您更喜欢使用命令行,可以直接使用 Simpleperf。Simpleperf 是一个通用的命令行 CPU 性能剖析工具,包含在面向 Mac、Linux 和 Windows 的 NDK 中。
如果手机未root,待分析的App必须是debuggable,在App manifest application标签中确保android:debuggable为true.
ndk目录simpleperf或者 源码system/extras/ simpleperf/scripts /
bin/android/${arch}/simpleperf: static simpleperf executables used on the device.
bin/${host}/${arch}/simpleperf: simpleperf executables used on the host, only supports reporting.
获取
使用 ctrl+c 方式结束记录,有可能造成 free记录丢失,而且会使进程号失效,不方便二次操作;
使用 kill -9 pid方式结束记录,要么再开一个终端获取root权限后执行kill命令,要么在当前终端执行,在当前终端执行需要 simpleperf record 命令后台运行,也会出现 lost 情况。
所以使用 --duration方式结束记录:
simpleperf record -p 8484 --duration 10 --call-graph dwarf -o /sdcard/dwarf
simpleperf record --help
- -o 指定结果输出文件
- -p pid1,pid2… 监测pid1,pid2…
- -t tid1,tid2… 监测tid1,tid2…
- -e event1[:flag],event2[:flag]… 指定事件,如 -e cache-misses,kgsl:kgsl_mem_alloc; flag 设置空间:u - 用户空间,k - 内核空间
- –duration seconds 设置监视多长时间
- –call-graph fp | dwarf 使能函数调用图,可以使用 fp 或 dwarf 两种 调试信息格式。
- -g 等价于 --call-graph dwarf
- –no-unwind 在 --call-graph dwarf 选项下不展开用户堆栈
- –group 让一组事件在同一时间被监视,如simpleperf record -p pid -e event1[:flag],event2[:flag] --group cache-references:u,cache-misses:u --group cache-references:k,cache-misses:k
- -f 设置每秒最多记录多少事件,
- -c 设置经过多少个事件记录一次。-f / -c选项会影响其后的所有事件类型,直到遇到另一个-f / -c选项为止。 例如,对于“ -f 1000 cpu-cycles -c 1 -e sched:sched_switch”,cpu-cycles的采样频率为1000,sched:sched_switch事件的采样周期为1。
- -m 如果记录过程中有事件丢失,可以将 -m 的值调大,默认小于等于1024.
- –clockid clock_id 指定时钟源; --cpu 记录指定cpu上的事件,如0,或0-3;
- –no-inherit 不记录创建的子线程/进程。
- –cpu-percent percent 设置记录中cpu时间的最大百分比(1-100),默认25
- –no-cut-samples 当simpleperf的缓存空间不足时,不清除之前的记录
- -post-unwind=yes 在记录完后展开调用栈,如果不设置该项则在记录中展开调用栈,record耗时会长一点
- –no-dump-kernel-symbols 不将内核符号转储到结果文件中。
- 分析app使用
在PC可以使用app-profiler.py 来分析一个APP
下面的表格列出了关键属性
| 属性名 | 描述 | 例子 |
|---|---|---|
| app_package_name | 待分析的App的package name | app_package_name=“com.example.simpleperf.simpleperfexamplewithnative” |
| apk_file_path | 待分析的App的APK路径 | apk_file_path = “…/SimpleperfExampleWithNative/app/build/outputs/apk/app-profiling.apk” |
| android_studio_project_dir | Android Strudio工程路径 | android_studio_project_dir = “…/SimpleperfExampleWithNative/” |
| launch_activity | 待分析的App的Main Activity | launch_activity = “.GameMainActivity” |
| recompile_app | 将字节码编译成带有调试信息的机器码,如果只分析java代码设置为True,否则False | recompile_app = False |
| record_options | 分析选项,以参数的形式传递给Simple record命令 | record_options = “-g --duration 10” |
1、 进入scripts目录下
2、使用 -p 命令指定APP的包名
3、使用 --compile_java_code 命令把Java代码编译为native代码 (这一步在Android P 及以上可以跳过)
4、 -a 用来指定某一个activity来分析 -lib选项提供查找调试本机库的目录
PC端执行:
python app_profiler.py -p com.example.simpleperf.simpleperfexamplewithnative --compile_java_code -a .MixActivity -lib path_of_SimpleperfExampleWithNative
这个命令会在当前目录下(可以使用 -o 来更改路径)生成一个perf.data文件,和一个binary_cache目录
- 函数调用
使用 report -g 命令打印调用图,以查看其他函数调用的函数。这有助于确定是某个函数本身运行缓慢还是因为它调用的一个或多个函数运行较慢。
simpleperf record -a --call-graph fp -f 6000 --duration 10 -o /sdcard/dwarf
simpleperf record -p 8484 --duration 10 --call-graph dwarf -o /sdcard/dwarf
- 分析应用启动过程:
PC端执行
./run_simpleperf_on_device.py record --app 包名 --duration 2 -o /sdcard/dwarf
此命令会自动打开包名对应的APP,然后在手机上生成/sdcard/dwarf
- 抓取启动activity过程中的数据
./app_profiler.py -p 包名 -a Activity的名字 -o 输出路径
./app_profiler.py -p cn.wps.moffice_eng -a cn.wps.moffice.main.local.HomeRootActivity -o /sdcard/dwarf
(此命令会自动打开应用和所指定的activity,然后生成perf.data)
- 查找执行时间最长的共享库
查看哪些 .so 文件占用了最大的执行时间百分比(基于 CPU 周期数)
simpleperf report --sort dso
- 查找执行时间最长的函数
当您确定占用最多执行时间的共享库后,就可以运行此命令来查看执行该 .so 文件的函数所用时间的百分比。
simpleperf report --dsos library.so --sort symbol
- 查找线程中所用时间的百分比
.so 文件中的执行时间可以跨多个线程分配
simpleperf report --sort tid,comm
- 查找对象模块中所用时间的百分比
在找到占用大部分执行时间的线程之后,可以使用此命令来隔离在这些线程上占用最长执行时间的对象模块
simpleperf report --tids threadID --sort dso
查看
- 手机端或者PC查看(文本方式):
simpleperf report -i /sdcard/dwarf-n --full-callgraph -g callee -o /sdcard/dwarf.out- PC端(图形方式):
python report_html.py -i dwarf -o dwarf.html
或者
python report_sample.py dwarf --show_tracing_data > dwarf.log --show_tracing_data参数将输出到ring buffer的数据打印出来
simpleperf report --help
- -i 指定需要报告的文件
- -o 指定输出文件
- -n 打印每个item的计数
- –comms comm1,comm2… 只报告指定的comms; 类似还有 --dsos --pids --tids --symbols
- –full-callgraph -g callee 打印完整的被调用图
- –full-callgraph -g caller 打印完整的调用图
- –kallsyms 设置文件以读取内核符号
- –no-demangle 不要删除符号名称
- –sort key1,key2,…设置排序方式,默认 --sort comm,pid,tid,dso,symbol
Simpleperf是如何工作的
现代的CPU具有一个硬件组件,称为性能监控单元(PMU)。PMU具有一些硬件计数器,计数一些诸如 经历了多少次CPU周期,执行了多少条指令,或发生了多少次缓存未命中 等的事件。
Linux内核将这些硬件计数器包装到硬件perf事件 (hardware perf events)中。此外,Linux内核还提供了独立于硬件的软件事件和跟踪点事件。Linux内核通过 perf_event_open 系统调用将这些都暴露给了用户空间,这正是simpleperf所使用的机制。
Simpleperf具有三个主要的功能:stat,record 和 report。
Stat命令给出了在一个时间段内被分析的进程中发生了多少事件的摘要。以下是它的工作原理:
给定用户选项,simpleperf通过对linux内核进行系统调用来启用分析。
Linux 内核在调度到被分析进程时启用计数器。
分析之后,simpleperf从内核读取计数器,并报告计数器摘要。
Record 命令在一段时间内记录剖析进程的样本。它的工作原理如下:
给定用户选项,simpleperf通过对linux内核进行系统调用来启用分析。
Simpleperf 在simpleperf 和 linux 内核之间创建映射缓冲区。
Linux 内核在调度到被分析进程时启用计数器。
每次给定数量的事件发生时,linux 内核将样本转储到映射缓冲区。
Simpleperf 从映射缓冲区读取样本并生成 perf.data。
Report 命令读取 “perf.data” 文件及所有被剖析进程用到的共享库,并输出一份报告,展示时间消耗在了哪里。
如果我们想使用 -g 选项来记录并报告一个程序的调用图,我们需要转储每个记录中的用户栈和寄存器集合,然后展开栈来查找调用链。Simpleperf 支持在记录时展开,因此它无需在 perf.data 中存储用户栈。因而可以在设备上有限的空间内剖析更长的时间。
火焰图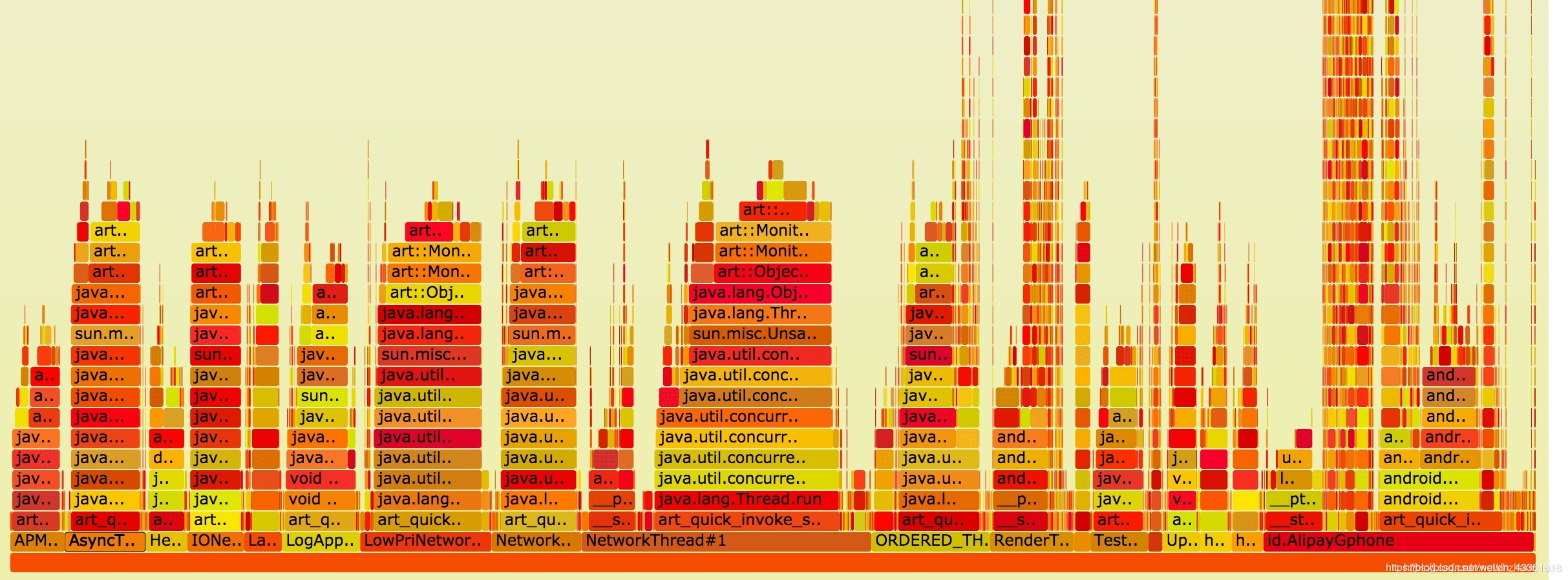
1、火焰图是基于 perf 命令结果产生的图片,用于展示 CPU 的调用栈。其中,纵轴表示调用栈,每一层都是一个函数。
调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。 横轴表示抽样数,如果一个函数在横轴占据的宽度越宽,就表示它被抽到的次数越多,即:执行的时间越长(注意:横轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的)。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有"平顶"(plateaus),就表示该函数可能存在性能问题。
比方说,最经典的火焰图是统计某一个软件的所有代码路径在 CPU 上的时间分布。通过这张分布图我们就可以直观地看出哪些代码路径花费的 CPU 时间较多,而哪些则是无关紧要的。
进一步地,我们可以在不同的软件层面上生成火焰图,比如说可以在系统软件的 C/C++ 语言层面上画出一张图,然后再在更高的,比如说:动态脚本语言的层面,例如:Lua、Perl 代码的层面,画出火焰图。
不同层面的火焰图常常会提供不同的视角,从而反映出不同层面上的代码热点。火焰图可以帮助用户快速地进行性能问题的定位,而不至于反复地试错、胡乱猜测,节约时间。
值得注意的是,即使是遇到我们并不了解的陌生程序,即使从未阅读过它的一行源码,通过看火焰图,也可以大致推出性能问题的所在。
因为通过火焰图上面直接显示出来的函数名,我们可以大致推测出对应的函数,乃至对应的某一条代码路径,大致是做什么事情的,从而推断出这个程序所存在的性能问题。
火焰图其实可以拓展到其他维度,比如:上面所说的火焰图是看程序运行在 CPU 上的时间,在所有代码路径上的分布,这是 on-CPU 时间这个维度。类似地,某一个进程不运行在任何 CPU 上的时间其实也是非常有趣的,我们称之为 off-CPU 时间。off-CPU 时间一般是这个进程因为某种原因处于休眠状态,比如:在等待某一个系统级别的锁,或者被一个非常繁忙的进程调度器(scheduler)强行剥夺 CPU 时间片。这些情况都会导致这个进程无法运行在 CPU 上,但是仍然花费很多的挂钟时间。通过这个维度的火焰图我们可以得到另一幅很不一样的图景。通过这个维度上的信息,我们可以分析系统锁方面的开销(例如:sem_wait 这样的系统调用),某些阻塞的 I/O 操作(例如:open、read 等),还可以分析进程或线程之间争用 CPU 的问题。通过 off-CPU 火焰图,都一目了然。类似地,我们可以把火焰图拓展到其它的系统指标维度,比如:内存泄漏的字节数、文件 I/O 的延时和数据量等。
2、将鼠标悬停在图中的某一行时,会标注函数名,鼠标悬浮时会显示完整的函数名、抽样抽中的次数、占据总抽样次数的百分比。

















 1920
1920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









