




🚩 从表格到向量:数据库的进化之路
“两岸猿声啼不住,轻舟已过万重山。
长江的水奔流不息,科技的巨轮滚滚向前。
代码如浪,算力为舟,且看技术洪流如何重塑未来。”
在这个数据驱动一切的时代,数据库就像大脑的记忆系统——帮助我们保存信息,也能快速找到需要的内容。它不仅支撑着业务系统的正常运行,还成为人工智能、搜索推荐等智能场景的基础。
但数据库不是一种就能打天下。从传统的 SQL 到灵活的 NoSQL,再到现在火热的向量数据库(Vector Database),它们各有侧重,也正在共同塑造现代智能系统。
今天,我们就一起来看看它们各自是怎么工作的,有什么不同,又为什么「向量数据库」会成为新焦点。
一、数据库到底是干什么的?
简单来说,数据库是用来存储和管理数据的软件系统。
不论你是要保存一个用户的信息、商品的库存,还是一段视频的描述内容,都需要数据库帮你记住、管理,并在你需要时迅速找回来。
比如:
- 微信聊天记录存在数据库里;
- 电商平台的订单数据也是;
- AI 模型生成内容时检索的资料,也来自数据库。
随着场景越来越丰富,不同类型的数据(结构化、非结构化、多模态)需要不同的数据库来处理,于是就有了 SQL、NoSQL 和 Vector DB 三种主流形态。
二、SQL Databases:经典的结构化数据库
🔍 什么是 SQL 数据库?
SQL(Structured Query Language)数据库,也就是关系型数据库,从 1970 年代起就作为数据存储的主流,是最传统、最常见的数据库类型。
它把数据存储成一张张表格,每一行代表一条记录,每一列是一个字段。
例如,一个用户表可能是这样的:
SQL 语言能让我们方便地增删查改这些数据,并支持多表关联(join)、聚合分析、事务控制等强大功能。
常见的 SQL 数据库包括:MySQL、PostgreSQL、Oracle、SQL Server。
🩸 优势
- 数据结构清晰,适合业务逻辑复杂、字段固定的系统。
- 支持事务(ACID),能保障数据一致性,非常适合金融、电商等领域。
- 强大查询能力:可以跨多个表做 join,支持复杂报表和聚合。
- 生态成熟,工具、文档、人才都很丰富。
- 适合场景:必须保障数据一致性、结构固定、业务逻辑复杂的系统。
⚠️ 局限
- 扩展性差:面对海量数据或高并发,单机性能瓶颈明显,处理能力强依赖于硬件性能。
- 结构僵硬:字段固定,变更表结构较麻烦,不适合灵活变化的内容型数据。
- 处理非结构化数据能力弱:比如图片、音频、嵌套 JSON。
三、NoSQL:为灵活性与多样性优化的数据而生
🔍 什么是 NoSQL?
NoSQL(Not Only SQL)是一类非关系型数据库,诞生于 Web 2.0 时代,专为解决 SQL 在大数据、灵活性、扩展性方面的不足。
它的特点是:结构更自由,扩展更方便,不强制用“表格”存数据,而是按需设计存储模型。
🧱 NoSQL 的四大类型
Key-Value(键值型):就像字典,通过一个 key 找一个 value,适合做缓存或简单数据存取。
📦 代表:Redis、valkey
Document(文档型):每条数据是一个 JSON 或 BSON 文档,支持嵌套字段,非常适合半结构化数据。
📄 代表:MongoDB、CouchDB
Column(列族型):数据以列为单位存储,适合高压写入和大数据分析。
📊 代表:Cassandra、HBase
Graph(图数据库):专为关系密集型数据设计,比如社交网络、推荐系统中的“谁认识谁”。
🔗 代表:Neo4j、JanusGraph

🩸 优势
- 灵活的结构:不需要提前定义字段,适应快速迭代的开发节奏。
- 弹性好:文档(Document)、键值(Key‑Value)、列族(Column)和图(Graph)数据库多种形态可选。
- 天然支持分布式扩展,能轻松横向扩容。
- 适合大数据场景,高可用、高吞吐、响应速度优先,结构可变性高。
⚠️ 局限
- 缺乏一致性保障:部分 NoSQL 系统牺牲事务一致性来换取性能。
- 查询能力弱于 SQL:很多场景下需要手动实现逻辑。
- 没有通用语言标准:每种 NoSQL 都有自己的语法和方式。
四、Vector Databases:AI 时代的新主角
🔍 什么是向量数据库?
向量数据库(Vector DB)专门用来存储和检索向量数据。
把文本、图片、语音等内容转成高维向量,存进专门优化向量检索的数据库,如 Milvus。
简单说,当你用大语言模型(LLM)把一段文本转成「一个 1536 维的向量」后,这个向量就代表了这段文字的语义。
而向量数据库能高效存储这些高维向量,并支持“找出最相似的几个”这样的查询。
举个例子:你搜索“西红柿炒鸡蛋”,向量数据库可以返回“番茄炒蛋”、“番茄蛋花汤”这些语义相近的菜谱。
🧩 它是怎么工作的?
- 文本/图像/音频等内容 → 嵌入模型 → 向量表示(例如:[0.12, 0.78, …])
- 向量存入数据库。
- 查询时:把查询也转成向量 → 进行“最近邻搜索” → 找出最相似的结果。
以下是用高维向量表示一只猫的例子:

🩸 优势
- 支持语义搜索:不再是关键词匹配,而是理解“意思”。
- 和 AI 模型结合紧密,是构建智能搜索、推荐、问答系统的关键。
- 优化了高维检索,用 HNSW、IVF、PQ 等算法实现亿级数据毫秒级返回。
- 适合场景:智能问答、推荐系统、语义搜索、多模态分析、工业图像识别等 AI 业务中核心组件。
五、Vector DB 与 RAG:智能问答背后的秘密
🔍 什么是 RAG?向量数据库在里面干嘛的?
RAG 全称是 Retrieval-Augmented Generation,翻译过来是“检索增强生成”,RAG 是一种设计思路。
它解决的是大语言模型(像 GPT)脱离上下文、一本正经胡说八道的问题。
🧩 RAG 的核心思路:
不是让模型「自己想」,而是「先找资料,再回答」。
整个流程长这样:
- 用户提问:「什么是 Kubernetes?」
- 检索阶段(Retrieval):
- 系统把这个问题转成一个向量(语义表示),
- 然后去 向量数据库里找最相关的文档(比如你公司里的知识库、FAQ、技术文档)。
- 生成阶段(Generation):
- 把检索到的文档 + 用户问题一起送进大模型,
- 模型根据真实资料来生成答案。
🩸 为什么不能只靠大模型?
- 模型知识是“训练好的”,无法实时更新。
- 很多公司有自己的知识、业务、文档,大模型根本不知道。
- 单靠模型回答容易“编故事”,而通过 RAG 可以引入真实数据源,答案更可靠。
🧠 RAG 与向量数据库是怎样协同工作的?
可以理解为:
- 向量数据库:做“语义理解 + 相关资料推荐”的工作;
- 大模型:根据资料“理解 + 生成自然语言回答”。
比如:
“我公司 2024 年年报中,总营收是多少?”
这时候:
- 向量数据库能立刻找出年报中包含“营收”的段落;
- 然后大模型读这些段落,再用自然语言总结给你看。
这就是 RAG 的真正威力:既有模型的表达能力,也有数据库的事实支撑。
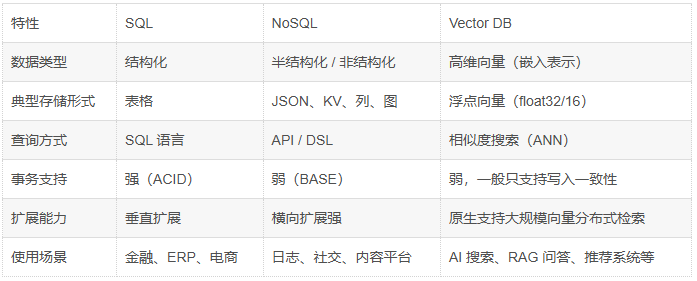
六、三种数据库的对比一览
七、数据库的未来趋势
未来,数据库不会只扮演“存储器”的角色,它会变得更“聪明”、更“嵌入式”:
- 数据和 AI 越来越融合,数据库需要理解语义、支持推理。
- 多模态数据(文本、图像、音频)将进入主流,要求数据库处理能力更广。
- 原生支持向量检索的数据库(如 PostgreSQL + pgvector)将成为新常态。
- 数据库之间的边界会越来越模糊,可能一个系统同时支持 SQL + NoSQL + 向量。
八、总结:技术演进的背后,是需求的升级
数据库技术的演进,并不是为了炫技,而是回应现实需求的变化:
- 业务上,从表单录入走向海量推荐与语义搜索;
- 技术上,从传统报表走向生成式 AI 与 RAG;
- 用户期望从“关键词检索”变成“理解我说了什么”。
向量数据库之所以兴起,是因为它站在了 AI 与数据之间的桥梁上,未来也会随着 AI 的深入落地,成为企业技术栈的重要一环。
这不仅是一次存储的升级,更是数据理解力的跃迁。
如果你对 SQL、NoSQL 或 Vector DB 有实际的使用经历,也欢迎在评论区一起分享 ~
想看更多关于 RAG、知识库构建、向量检索的深度内容,也可以点个「关注」!
重点提醒 :喜欢请加关注哦 👇!


















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











