







 本文深入解析Linux内核的内存管理,重点介绍了alloc_pages函数的实现过程,包括gfp_mask标志的含义和如何影响内存分配行为。通过分析__alloc_pages函数及其相关标志,展示了内存分配在不同区域(如DMA、HIGHMEM等)的选择策略。同时,讨论了zone数据结构和watermark检查,以及内存回收的可能性。
本文深入解析Linux内核的内存管理,重点介绍了alloc_pages函数的实现过程,包括gfp_mask标志的含义和如何影响内存分配行为。通过分析__alloc_pages函数及其相关标志,展示了内存分配在不同区域(如DMA、HIGHMEM等)的选择策略。同时,讨论了zone数据结构和watermark检查,以及内存回收的可能性。
alloc_pages函数实现:
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order)

上图的nid是针对numa,此处不做引入分析,可以直接将nid当做0分析。
__alloc_pages函数是透传调用__alloc_pages_nodemask(gfp_mask, order, zonelist, NULL);
gfp_t gfp_allowed_mask __read_mostly = GFP_BOOT_MASK;
__GFP_BITS_MASK包含所有的存在含义的标志位。
#define GFP_BOOT_MASK (__GFP_BITS_MASK & ~(__GFP_WAIT|__GFP_IO|__GFP_FS))



上述代码的2809-2813行是定义一个局部变量alloc_context变量,并且初始化了优先分配的zone索引high_zonidx,nodemask=NULL,根据gfp标志算出分配的迁移类型。上述2815行是计算出合法的gfp_mask。2821行相当于是进行参数合法性检查2829-2830是进行zone的参数合法性检查。2832-2833是针对开启了CMA则指定ALLOC_CMA分配标志,其中2839-2843是决定从哪个zone分配内存,first_zones_zonelist函数会根据传入的gfp找到对应的目标zone,然后再全局的zonelist链表里搜索到索引值小于等于目标zone对应的索引值的zone。
在分析first_zones_zonelist函数之前先分析下数据结构。2850行get_page_from_freelist是真正执行分配任务的函数,详细实现参考1.2节。2851-2860是针对分配失败的情况这个后面会继续分析。2874-2875会再一次尝试。2877则是返回分配成功的page结构地址。
内存分配标志
下面标志表示对应的区域分配
#define __GFP_DMA ((__force gfp_t)___GFP_DMA) DMA zone分配
#define __GFP_HIGHMEM ((__force gfp_t)___GFP_HIGHMEM)
#define __GFP_DMA32 ((__force gfp_t)___GFP_DMA32)
#define __GFP_MOVABLE ((__force gfp_t)___GFP_MOVABLE) /* Page is movable */
#define GFP_ZONEMASK (__GFP_DMA|__GFP_HIGHMEM|__GFP_DMA32|__GFP_MOVABLE)
下面分配标志改变分配的行为,每个分配标志代码里都有详细的注释
#define __GFP_WAIT ((__force gfp_t)___GFP_WAIT) /* Can wait and reschedule? */
#define __GFP_HIGH ((__force gfp_t)___GFP_HIGH) /* Should access emergency pools? */
#define __GFP_IO ((__force gfp_t)___GFP_IO) /* Can start physical IO? */
#define __GFP_FS ((__force gfp_t)___GFP_FS) /* Can call down to low-level FS? */
#define __GFP_COLD ((__force gfp_t)___GFP_COLD) /* Cache-cold page required */
#define __GFP_NOWARN ((__force gfp_t)___GFP_NOWARN) /* Suppress page allocation failure warning */
#define __GFP_REPEAT ((__force gfp_t)___GFP_REPEAT) /* See above */
#define __GFP_NOFAIL ((__force gfp_t)___GFP_NOFAIL) /* See above */
#define __GFP_NORETRY ((__force gfp_t)___GFP_NORETRY) /* See above */
#define __GFP_MEMALLOC ((__force gfp_t)___GFP_MEMALLOC)/* Allow access to emergency reserves */
#define __GFP_COMP ((__force gfp_t)___GFP_COMP) /* Add compound page metadata */
#define __GFP_ZERO ((__force gfp_t)___GFP_ZERO) /* Return zeroed page on success */
#define __GFP_NOMEMALLOC ((__force gfp_t)___GFP_NOMEMALLOC) /* Don't use emergency reserves.
* This takes precedence over the
* __GFP_MEMALLOC flag if both are
* set
*/
#define __GFP_HARDWALL ((__force gfp_t)___GFP_HARDWALL) /* Enforce hardwall cpuset memory allocs */
#define __GFP_THISNODE ((__force gfp_t)___GFP_THISNODE)/* No fallback, no policies */
#define __GFP_RECLAIMABLE ((__force gfp_t)___GFP_RECLAIMABLE) /* Page is reclaimable */
#define __GFP_NOTRACK ((__force gfp_t)___GFP_NOTRACK) /* Don't track with kmemcheck */
#define __GFP_NO_KSWAPD ((__force gfp_t)___GFP_NO_KSWAPD)
#define __GFP_OTHER_NODE ((__force gfp_t)___GFP_OTHER_NODE) /* On behalf of other node */
#define __GFP_WRITE ((__force gfp_t)___GFP_WRITE) /* Allocator intends to dirty page */
注意 __GFP_DMA、 __GFP_HIGHMEM、 __GFP_DMA32 和 __GFP_MOVABLE标志可以相互组合使用,如下的 GFP_ZONEMASK宏则是提取出这四个标志位,GFP_ZONE_TABLE 是合法的组合情况,GFP_ZONE_BAD是由于上述互斥引入的非法的情况。需要ZONES_SHIFT个位表示不同的zone。
Linux_4.0的源码如下:
static inline enum zone_type gfp_zone(gfp_t flags)
{
enum zone_type z;
//获取zone区域的标志组合
int bit = (__force int) (flags & GFP_ZONEMASK);
//根据组合判断出所属zone的区域
z = (GFP_ZONE_TABLE >> (bit * ZONES_SHIFT)) &
((1 << ZONES_SHIFT) - 1);
//对于非法zone组合给出waring
VM_BUG_ON((GFP_ZONE_BAD >> bit) & 1);
return z;
}
__GFP_DMA、 __GFP_HIGHMEM和 __GFP_DMA32 标志
等效于如下:
static inline enum zone_type gfp_zone(gfp_t flags)
{
#ifdef CONFIG_ZONE_DMA
if (flags & __GFP_DMA)
return ZONE_DMA;
#endif
#ifdef CONFIG_ZONE_DMA32
if (flags & __GFP_DMA32)
return ZONE_DMA32;
#endif
if ((flags & (__GFP_HIGHMEM | __GFP_MOVABLE)) ==
(__GFP_HIGHMEM | __GFP_MOVABLE))
return ZONE_MOVABLE;
#ifdef CONFIG_HIGHMEM
if (flags & __GFP_HIGHMEM)
return ZONE_HIGHMEM;
#endif
return ZONE_NORMAL;
}
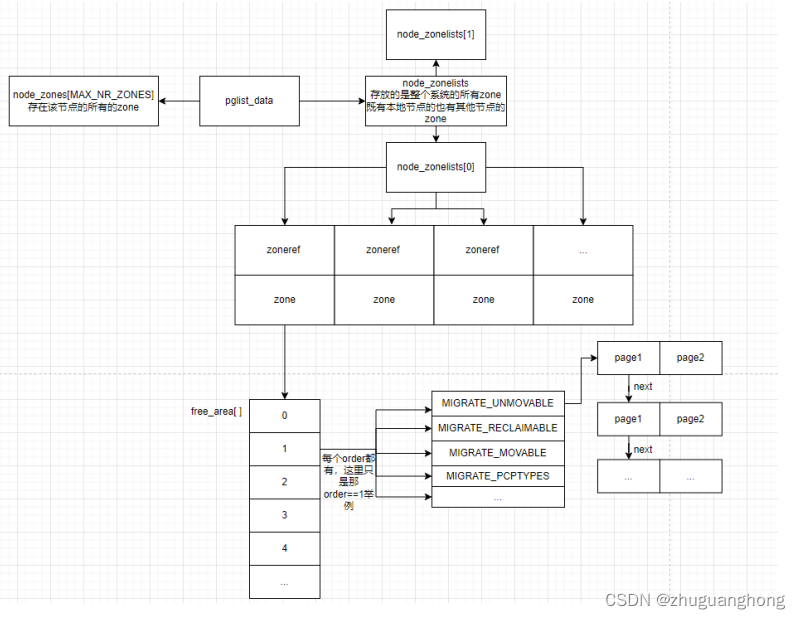
first_zones_zonelist函数
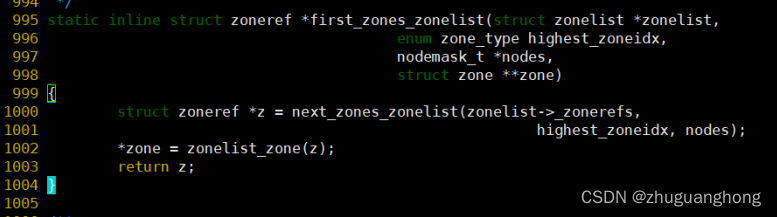
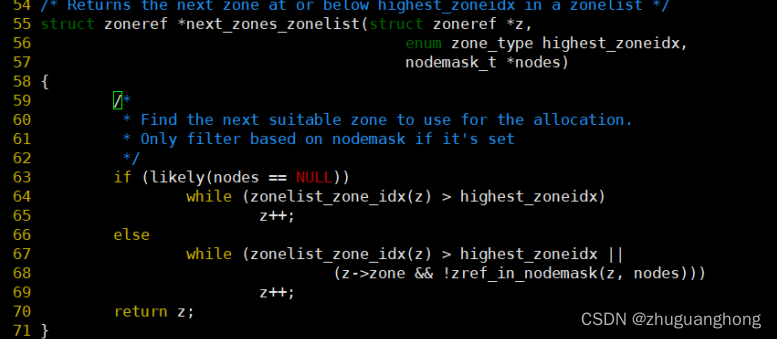
上述64行可以看出会在系统内包含所有zone的zoneref数组里遍历个索引值小于指定的zone的索引值。关于zoneref数据结构关系如下。
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; //存在该内存节点的内存区zones
struct zonelist node_zonelists[MAX_ZONELISTS];//zonelist装着系统中所有的内存节点的zones
int nr_zones;
...
}
#define MAX_ZONES_PER_ZONELIST (MAX_NUMNODES * MAX_NR_ZONES)
struct zonelist {
struct zonelist_cache *zlcache_ptr; // NULL or &zlcache
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
#ifdef CONFIG_NUMA
struct zonelist_cache zlcache; // optional ...
#endif
};
一个zoneref对应一个zone
struct zoneref {
struct zone *zone; /* Pointer to actual zone */
int zone_idx; /* zone_idx(zoneref->zone) */
};
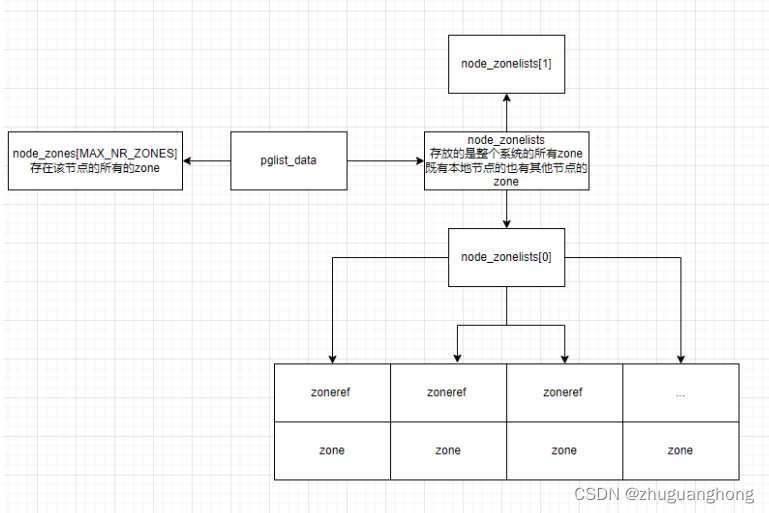
执行分配函数get_page_from_freelist
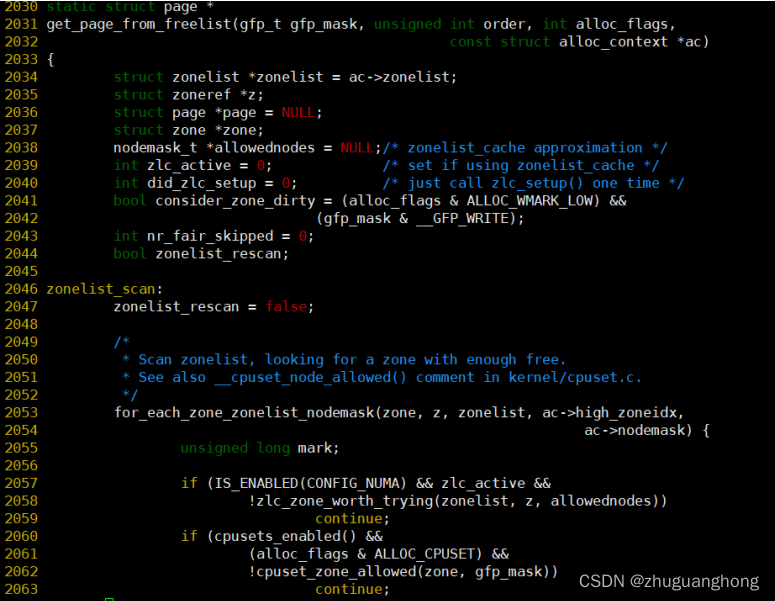
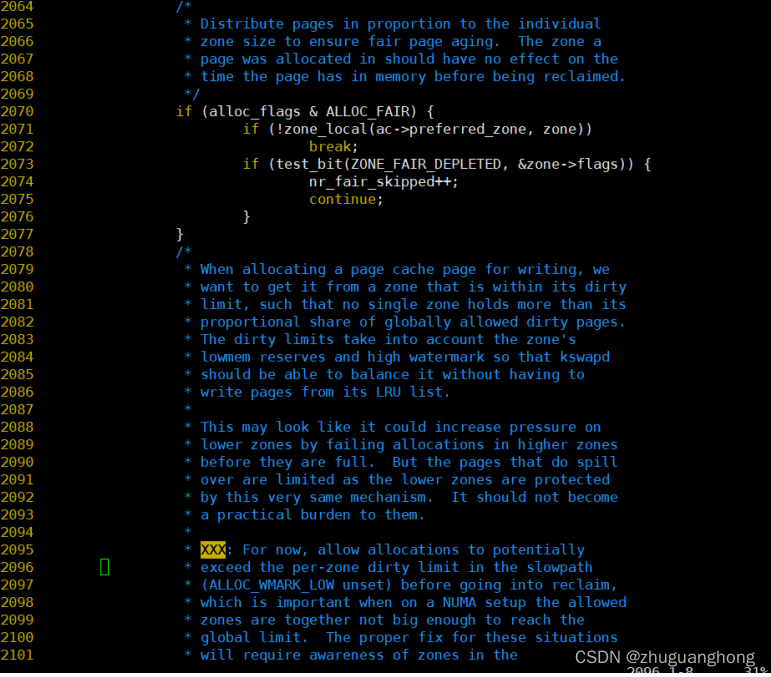
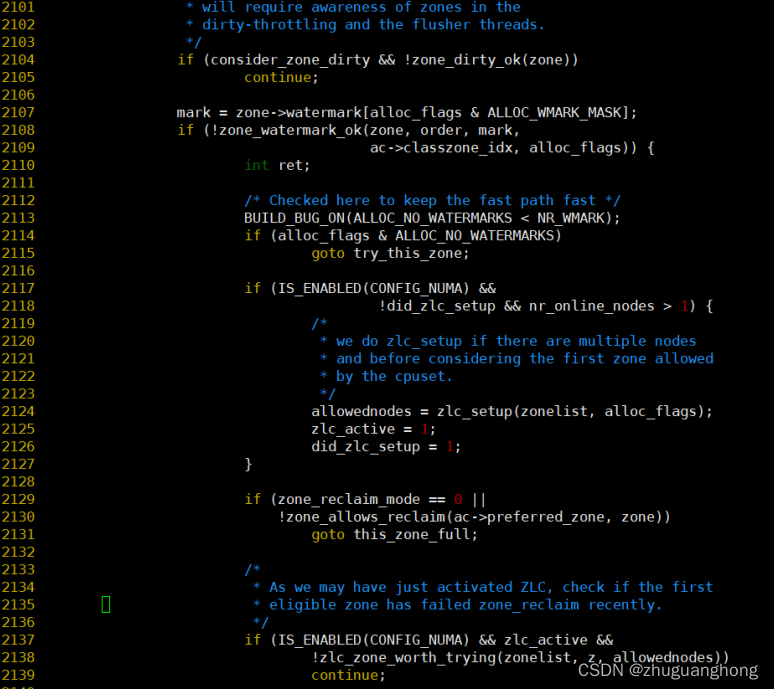
从上述代码的2053行可以看出在zoneref数组里遍历找寻满足索引值小于指定的zone区域对应的索引值的zone。2057-2105是对查找到的zone进行要求检查。2107-2170是针对watmark不满足要求的情况进行处理。其中2107是根据传入的分配标志决定使用哪个水位线。其中alloc_pages传入的是ALLOC_WMARK_LOW则对应的是WMARK_LOW。
#define ALLOC_WMARK_MIN WMARK_MIN
#define ALLOC_WMARK_LOW WMARK_LOW
#define ALLOC_WMARK_HIGH WMARK_HIGH
#define ALLOC_NO_WATERMARKS 0x04 /* don't check watermarks at all */
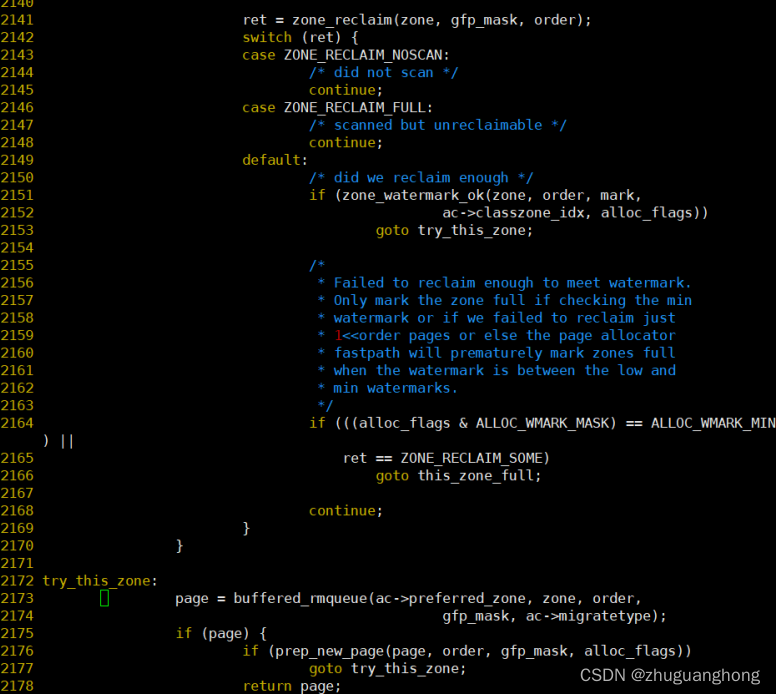
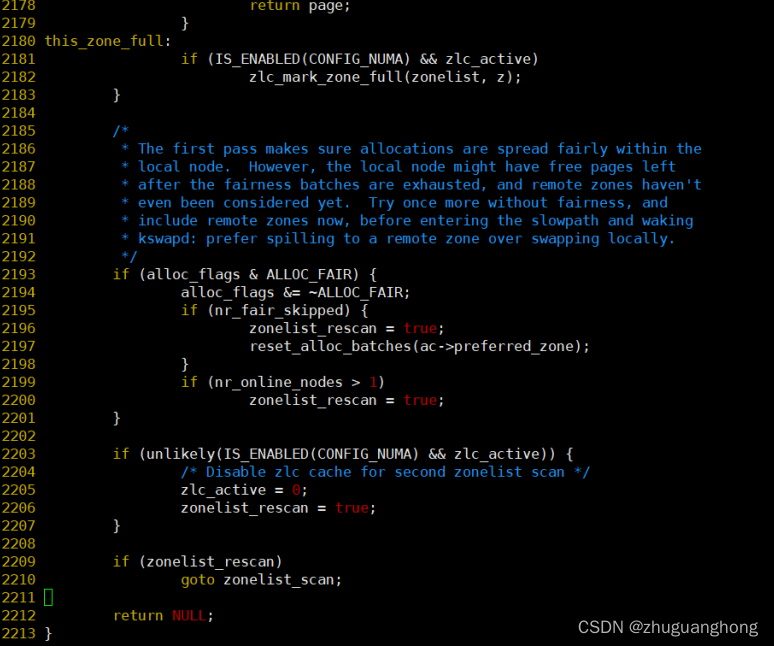
2108行是调用zone_watermark_ok去判断zone内部是否还有足够的空闲页面。zone_watermark_ok函数实现参考2.1节。如果对于不足的情况则是调用zone_reclaim函数去回收内存。2142-2153是对zone_reclaim函数返回值做出不同的处理分别存在没有进行回收扫描则是进行下一个zone的尝试,尝试回收扫描了但是没有可回收页面则也进行下一个zone分配。其他情况则判断页面水位线是否满足要求满足则继续分配,否则继续扫描其他的zone。关于内存回收函数__zone_reclaim将会在另外一篇内存回收文章里展开分析。
2173行是调用buffered_rmqueue进行真正的分配动作。
判断水位线函数zone_watermark_ok:

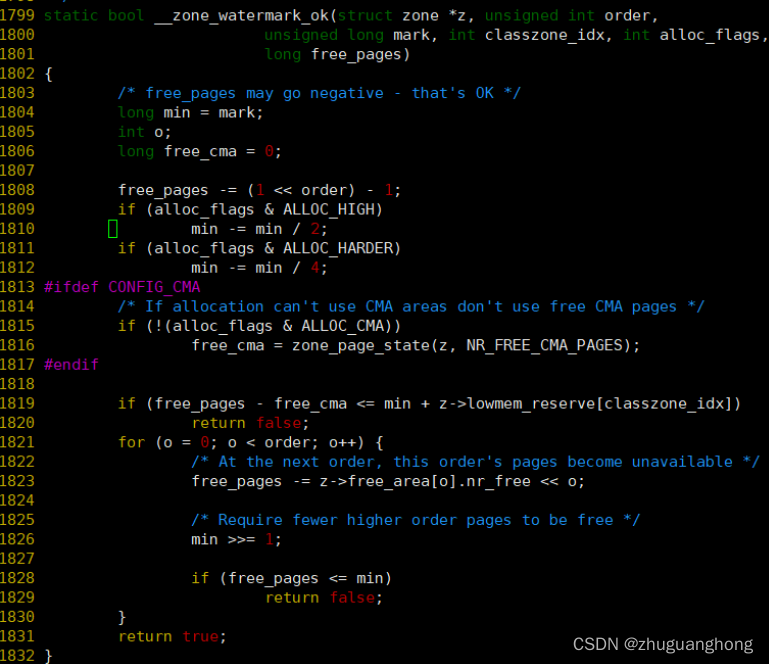
上述的1808行是计算当前空闲页面去掉本地分配的之后剩余页面,1809-1812行是针对传入的分配标志适当的放低水位线。1819-1820则是针对实际的页面数低于水位线和保留页面之和的情况则直接返回失败。1821-1830是先将剩余页面减去小于分配请求的order的页面数。相应的将min缩小到原来的一半,比较剩余页面数与min的值如果小于等于则依旧判定为失败。其他情况判定为ok。
buffered_rmqueue函数实现:
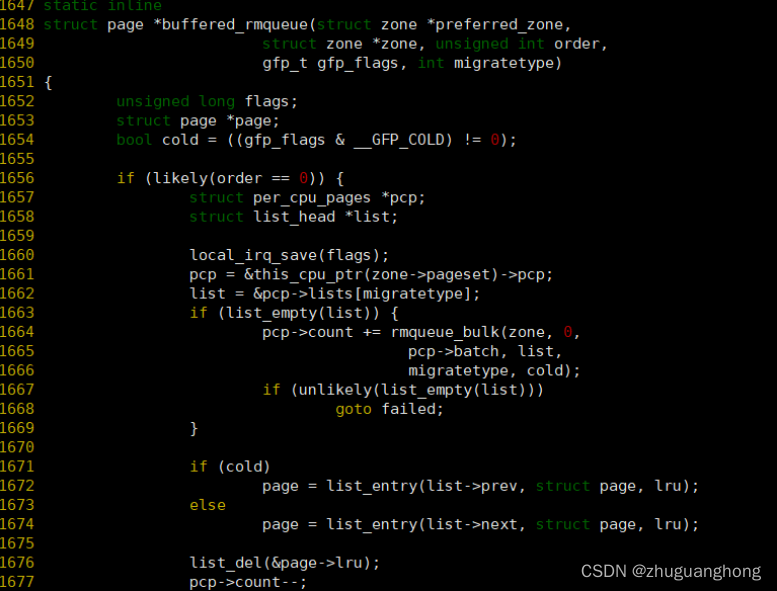
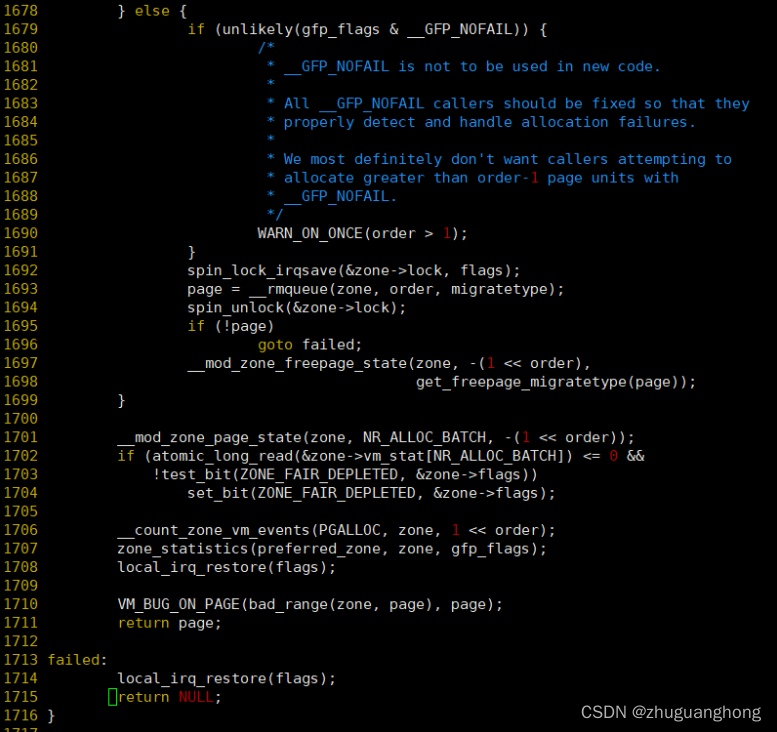
1660-1662行是获取pcpu的缓存页面,1663行判断出对应类型的页面链表是空的则调用rmqueue_bulk从伙伴系统中分配pcp->batch个页面。1671-1676则是从list里取出一页内存。1701-1711是设置一些统计计数,然后返回申请到的页面。1679-1697行主要是调用__rmqueue从伙伴系统内分配出内存。
__rmqueue函数实现如下:
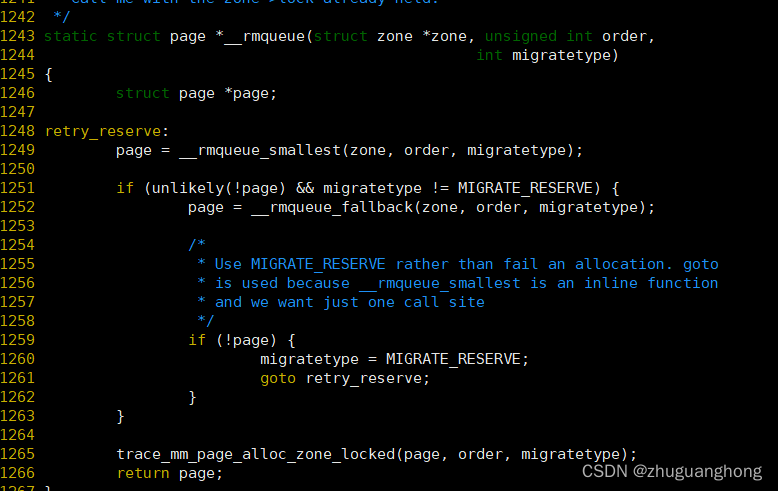
可以看出是先调用__rmqueue_smallest函数去分配对应的大小的内存页面,如果分配失败且分配类型不是MIGRATE_RESERVE则继续调用__rmqueue_fallback函数分配。
__rmqueue_smallest:
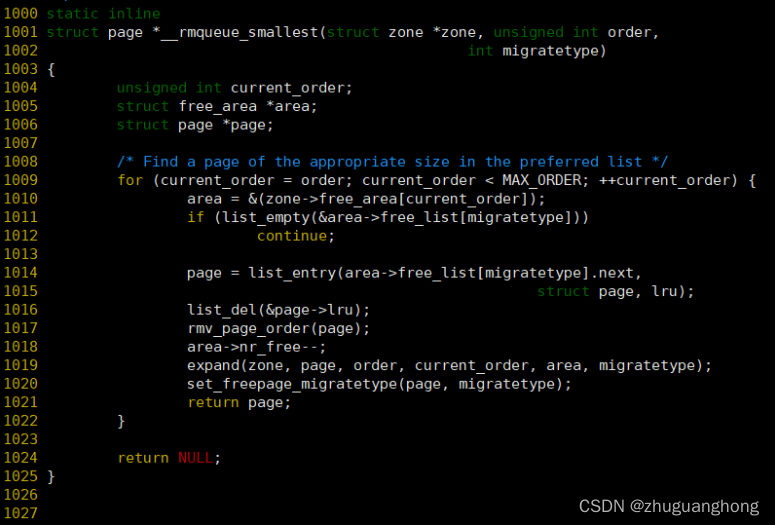
此函数比较简单则是从zone里的伙伴系统上分配order数量的内存页,如果对应的order大小的区域没有则向上一级申请,如果最大的order都申请不到相应类型的内存页面页没有则返回NULL。其中expand函数作用是将上一级的连续page页面分成两份,一份作为返回的申请页面,一份链接在当前申请级别的链表上。
Expand函数代码如下:
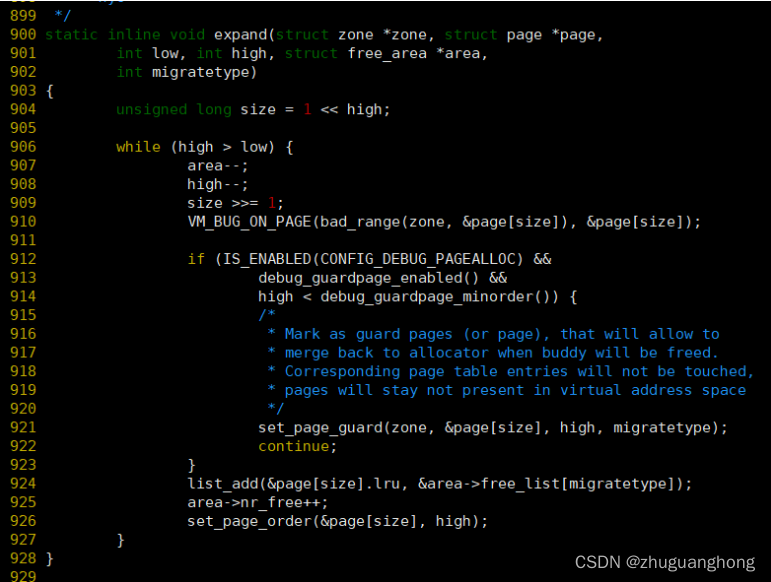
987-909行的area从上一级变为下一级,high也一样,size表示上一级的一项里的页表数目在909行改写为原有的一半,924-926行将申请到的page+size链接到area对应的链表上,同时更新area的空闲项计数,并且调用set_page_order改写page[size]里的连续空闲页面计数。
Free_pages函数实现:
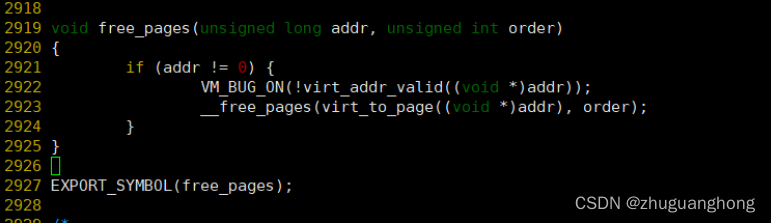
上图可以看出实际调用的是__free_pages去执行真正的释放动作。
__free_pages函数实现:
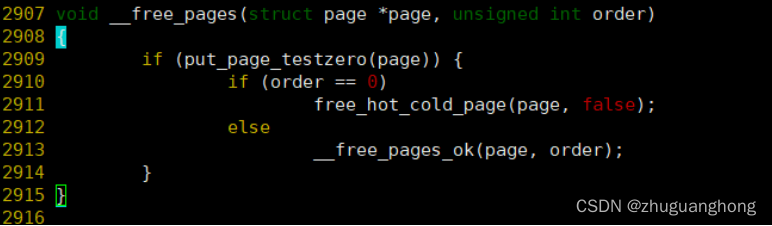
上图可以看出在释放单个页面的时候调用free_hot_cold_page,释放多个页面的时候调用__free_pages_ok。
free_hot_cold_page函数实现:
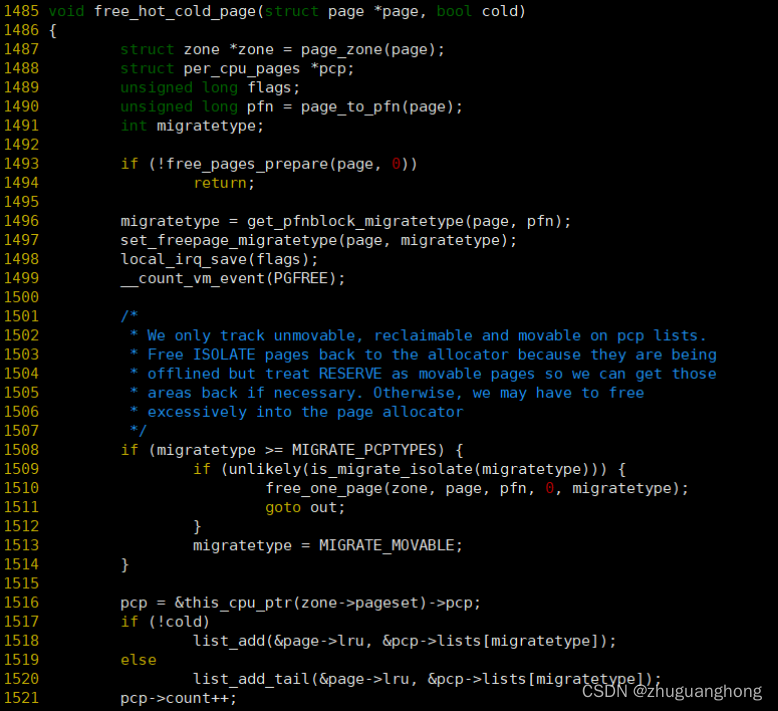
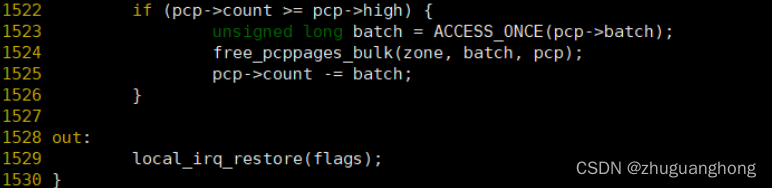
上述代码其实是将单个页面缓存在pcp链表上,但是这个只是针对unmovable、reclaimable和movable类型的页面,MIGRATE_ISOLATE类型的页面会调用free_one_page函数去释放。其他都缓存在pcp里的MIGRATE_MOVABLE的类型的链表。free_one_page函数后续分析。
对于1522-1526行是针对pcp里面缓存的页面大于特定值则调用free_pcppages_bulk函数去释放到伙伴系统内部。
__free_pages_ok函数实现:
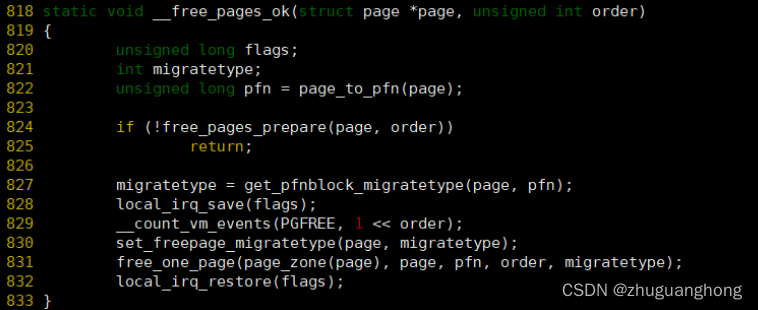
可以看到__free_pages_ok函数也是调用free_one_page去释放页面。
free_one_page函数实现:
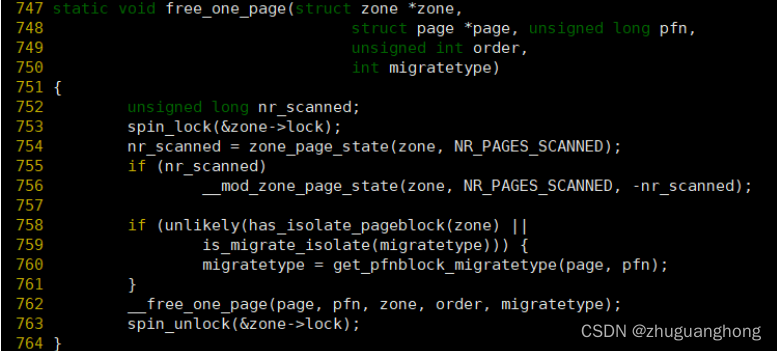
可以看到free_one_page函数是直接调用__free_one_page函数
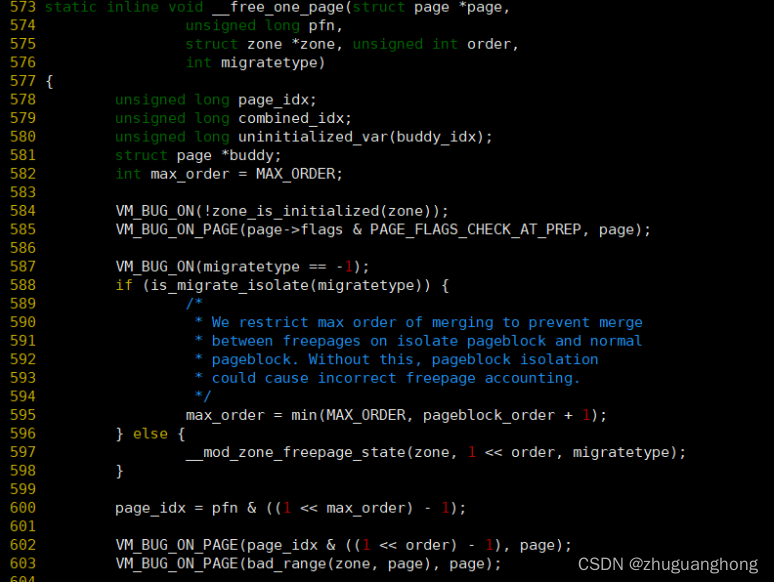
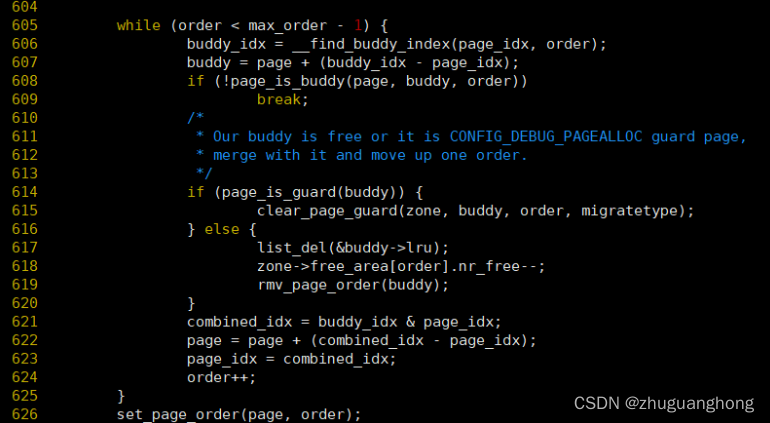
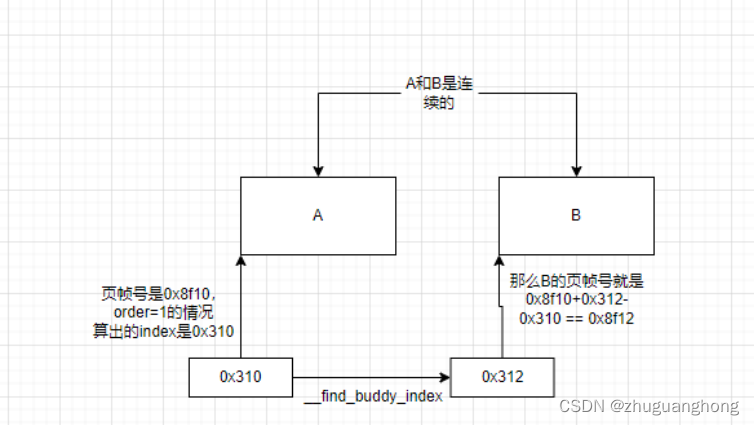
上述代码600行是根据传入的pfn号算出在相应order区间的index索引。605-625是将相邻的buddy向上规整,606行根据计算出的index查找对应的buddy,

因为buddy之间的pfn差距肯定都是order的整数倍,所以如果此次释放的pfn的index的order的位是0那么对应的buddy对应的index对应的order位肯定是1,反之如果是1肯定对应的是0。607行是根据找到的索引值求取buddy的page,608行判断是不是真正的buddy,如果不是则说明无法继续合并跳出循环,如果是则两者合并,循环递归到上层order。直到最大order或者不能合并为止。626行调用set_page_order将order保存到page->private里。
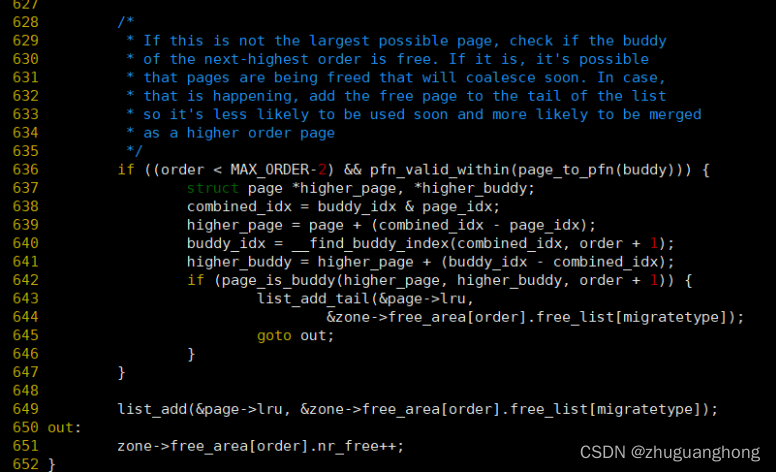
636-647行是对没有达到最大order的情况下,对于能够与上层页面合并的情况则将页面链入链表末尾。649行则是正常链接到链表头。651行是增加对应的order的free计数。
整个查找buddy计算如下图:

















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









