







 本文介绍了神经网络的基本组成部分,包括输入层、输出层和隐藏层,特别关注了前馈神经网络与递归神经网络的区别。作者探讨了隐藏层设计的艺术性和启发式方法,并指出递归神经网络虽有潜力但学习算法相对较弱,本教程将主要聚焦于前馈网络的应用。
本文介绍了神经网络的基本组成部分,包括输入层、输出层和隐藏层,特别关注了前馈神经网络与递归神经网络的区别。作者探讨了隐藏层设计的艺术性和启发式方法,并指出递归神经网络虽有潜力但学习算法相对较弱,本教程将主要聚焦于前馈网络的应用。
架构
在下一部分,我将介绍一个能够相当不错地对手写数字进行分类的神经网络。为了做好准备,有必要解释一些术语,这些术语让我们能够给网络的不同部分命名。假设我们有以下网络:
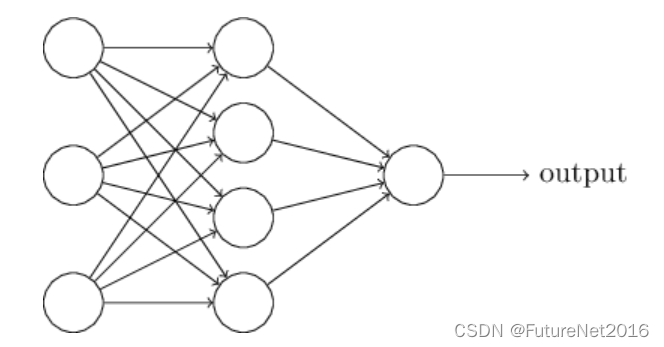
如前所述,这个网络中最左边的层被称为输入层,层内的神经元被称为输入神经元。最右边或输出层包含输出神经元,或者在这种情况下,一个单独的输出神经元。中间层被称为隐藏层,因为这一层中的神经元既不是输入也不是输出。术语"隐藏"可能听起来有点神秘 - 我第一次听到这个术语时以为它一定有一些深刻的哲学或数学意义 - 但它实际上只是意味着"既不是输入也不是输出"。上面的网络只有一个隐藏层,但有些网络有多个隐藏层。例如,下面的四层网络有两个隐藏层:
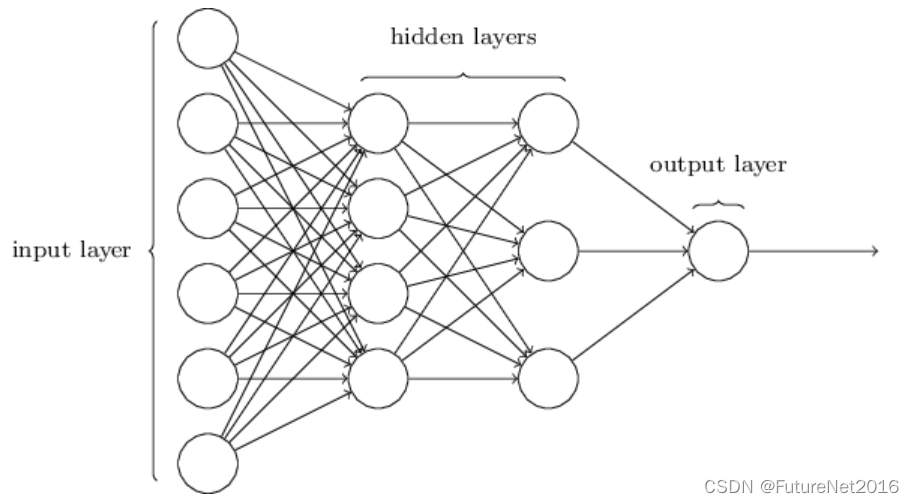
有点令人困惑是,也是出于历史原因,这种多层网络有时被称为多层感知器或MLP,尽管它们由Sigmoid神经元组成,而不是感知器。在本教程中,我不打算使用MLP术语,因为我认为它容易混淆,但我想提醒你它的存在。
神经网络中输入和输出层的设计通常是直接的。例如,假设我们试图确定一幅手写图像是否描绘了一个"9"。设计网络的一种自然方式是将图像像素的强度编码到输入神经元中。如果图像是一个64×64的灰度图像,那么我们将有4,096=64×64个输入神经元,其强度在0到1之间适当缩放。输出层将只
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2097
2097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









