



一、Spring AI 构建私有化语义内容检索
Spring AI 是 Spring 官方社区项目,旨在简化 Java AI 应用程序开发,让 Java 开发者像使用 Spring 开发普通应用一样开发 AI 应用。
上篇文章我们基于 Spring AI MCP + DeepSeek R1 快速实现了数据库 ChatBI 能力。在AIGC领域,向量语义能力同样也有着十分重要的地位。因此本篇文章探索 Spring AI + bge-large-zh-v1.5 + Milvus 搭建一套私有化的内容语义检索能力方案。
其中 bge-large-zh-v1.5 本地私有化部署采用 vLLM 进行部署和优化。Spring AI 采用 1.0.0-SNAPSHOT 版本。
处理过程大致如下图所示:
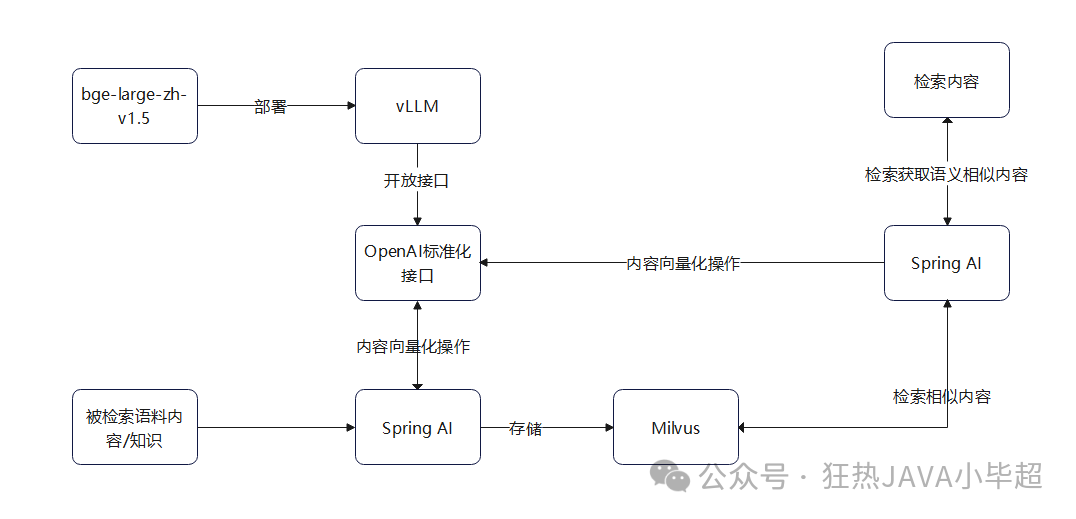
实验前需要提前部署好 Milvus 向量库,如果不清楚可参考下面文章的介绍。
二、vLLM 部署 bge-large-zh-v1.5 模型
如果不了解 vLLM ,可参考下面这篇文章中的介绍和使用过程:
首先使用 modelscope 下载模型:
modelscope download --model="BAAI/bge-large-zh-v1.5" --local_dir bge-large-zh-v1.5
加载模型,启动服务:
vllm serve bge-large-zh-v1.5 \
--port 8070 \
--dtype auto \
--task embed \
--trust-remote-code \
--api-key token-abc123
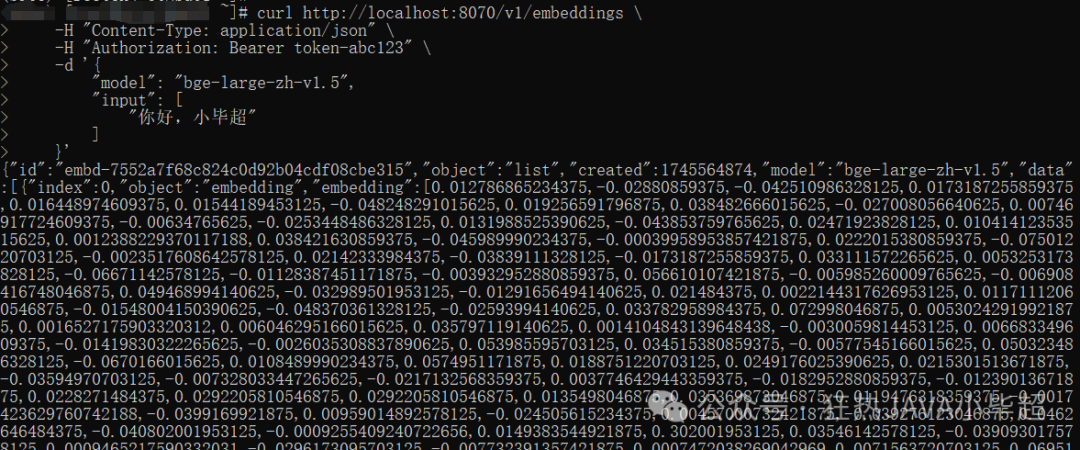
使用 curl 测试服务接口是否正常:
curl http://localhost:8070/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer token-abc123" \
-d '{
"model": "bge-large-zh-v1.5",
"input": [
"你好,小毕超"
]
}'
三、Spring AI 集成 OpenAI 格式向量模型
Spring AI 关于集成 OpenAI 格式向量模型的文档介绍如下:
https://docs.spring.io/spring-ai/reference/api/embeddings/openai-embeddings.html
新建 SpringBoot 项目,在 pom 中修改如下依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<groupId>com.example</groupId>
<modelVersion>4.0.0</modelVersion>
<artifactId>embedding</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>embedding</name>
<description>embedding</description>
<properties>
<java.version>17</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>3.3.0</spring-boot.version>
<spring-ai.version>1.0.0-SNAPSHOT</spring-ai.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<repositories>
<repository>
<name>Central Portal Snapshots</name>
<id>central-portal-snapshots</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>17</source>
<target>17</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring-boot.version}</version>
<configuration>
<mainClass>com.example.embedding.EmbeddingApplication</mainClass>
<skip>true</skip>
</configuration>
<executions>
<execution>
<id>repackage</id>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
修改 application.yml 添加 vLLM 服务的链接信息:
spring:
ai:
openai:
base-url: http://127.0.0.1:8070
api-key: token-abc123
embedding:
options:
model: bge-large-zh-v1.5
使用向量能力:
@SpringBootTest
classEmbeddingApplicationTests {
@Resource
private EmbeddingModel embeddingModel;
@Test
voidembed() {
EmbeddingResponseembeddingResponse= embeddingModel.call(
newEmbeddingRequest(List.of("你好,小毕超", "你叫什么名字"),
OpenAiEmbeddingOptions.builder().build()));
embeddingResponse.getResults().forEach(e -> {
System.out.println("向量维度:" + e.getOutput().length);
for (float f : e.getOutput()) System.out.print(f);
System.out.println();
});
}
}
运行后可以看到向量模型的维度是 1024 维,已经向量化后的信息。

四、Spring AI 集成 Milvus 向量数据库实现持久化和语义检索能力
Spring AI 关于 Milvus 的文档如下:
https://docs.spring.io/spring-ai/reference/api/vectordbs/milvus.html#milvus-properties
在 pom 中增加 Milvus 依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-milvus</artifactId>
</dependency>
application.yml 中添加 Milvus 的链接信息:
spring:
ai:
openai:
base-url:http://127.0.0.1:8070
api-key:token-abc123
embedding:
options:
model:bge-large-zh-v1.5
vectorstore:
milvus:
client:
host:127.0.0.1
port:19530
username:"root"
password:"milvus"
databaseName:"default"
collectionName:"vector_test"
embeddingDimension:1024
indexType:IVF_FLAT
metricType:COSINE
initialize-schema: true
3.1 内容持久化至向量库中
@SpringBootTest
classMilvusTests {
@Resource
VectorStore vectorStore;
@Test
voidtoMinvus() {
List<Document> documents = List.of(
newDocument("我的爱好是打篮球", Map.of("name", "张三", "age", 18)),
newDocument("我的爱好的是学习!", Map.of("name", "李四", "age", 30)),
newDocument("今天的天气是多云", Map.of("name", "王五", "age", 50)),
newDocument("我的心情非常愉悦", Map.of("name", "赵六", "age", 25)),
newDocument("我叫小毕超", Map.of("name", "小毕超", "age", 28))
);
vectorStore.add(documents);
}
}
运行后,可在 Milvus 中看到自动创建的 collection:

3.2 语义内容检索
@SpringBootTest
classMilvusTests {
@Resource
VectorStore vectorStore;
@Test
voidsimilarity() {
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query("你叫什么名字")
.topK(3)
.similarityThreshold(0.2)
.build()
);
Optional.ofNullable(results).ifPresent(res->{
res.forEach(d -> System.out.println(d.getText()+" "+d.getMetadata()));
});
}
}

根据 meta 进行过滤检索,过滤表达可以使用文本表达式方式:
@Test
void similarity2() {
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query("你叫什么名字")
.topK(5)
.similarityThreshold(0.2)
.filterExpression("age > 15 && age < 30")
.build()
);
Optional.ofNullable(results).ifPresent(res->{
res.forEach(d -> System.out.println(d.getText()+" "+d.getMetadata()));
});
}

其中表达式也可使用 api 的方式:
@Test
voidsimilarity3() {
FilterExpressionBuilderfilter=newFilterExpressionBuilder();
List<Document> results = vectorStore.similaritySearch(
SearchRequest.builder()
.query("你叫什么名字")
.topK(5)
.similarityThreshold(0.2)
.filterExpression(
filter.and(filter.gt("age", 15), filter.lt("age", 30)).build()
).build()
);
Optional.ofNullable(results).ifPresent(res->{
res.forEach(d -> System.out.println(d.getText()+" "+d.getMetadata()));
});
}
可以得到同样的结果:

如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









