






随着生成式 AI(GenAI)的兴起,向量数据库(Vector Database)迅速走红。然而,向量数据库的应用远不止于大模型(LLM),它同样适用于各种 AI 系统,尤其是在 RAG 的场景下。
在 AI 领域,我们经常处理向量嵌入(Vector Embeddings)。向量数据库正是为了高效存储、更新和检索这些嵌入数据而生的:
✅ 存储(Storing)
✅ 更新(Updating)
✅ 检索(Retrieving)
其中,检索(Retrieval) 指的是查找与查询向量最相似 的一组向量,这一过程被称为 近似最近邻(ANN, Approximate Nearest Neighbour)搜索。例如:
- 查询可以是一个图片,希望找到与之相似的图片。
- 查询也可以是一个文本问题,希望检索到相关背景信息,并借助 LLM 生成答案。
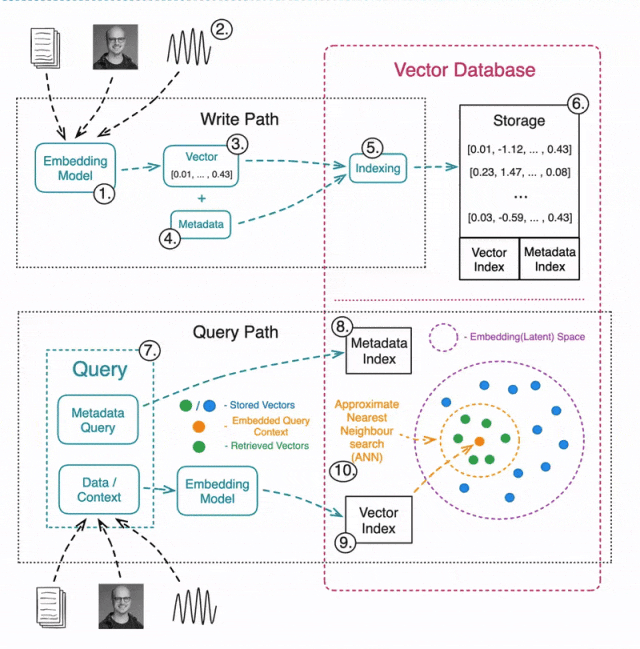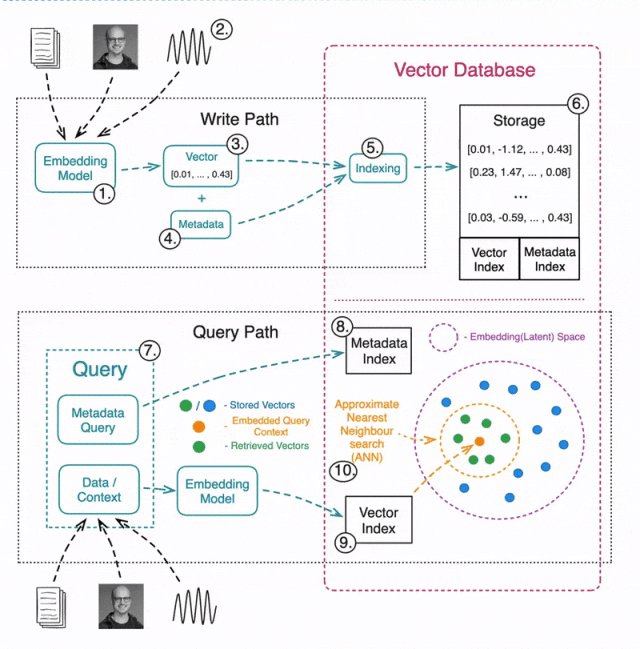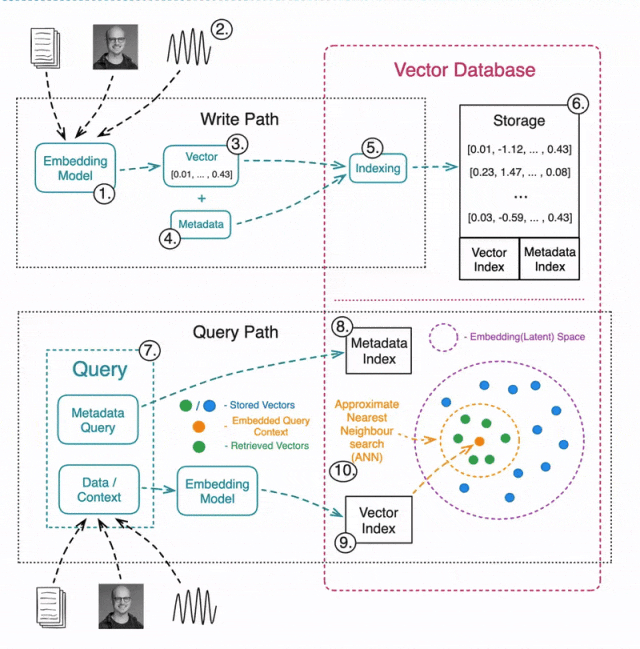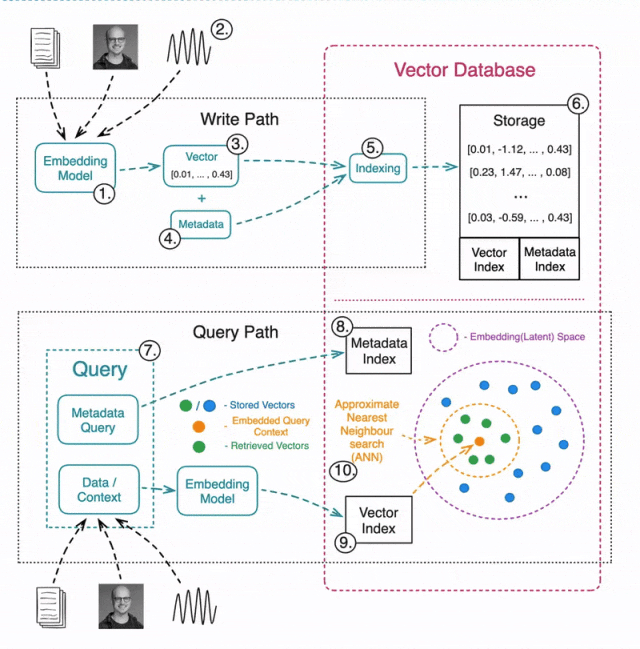
构建向量数据库:数据的写入与读取
写入/更新数据
1️⃣ 选择合适的机器学习模型,用于生成向量嵌入。
2️⃣ 对各种类型的数据进行嵌入(文本、图像、音频、表格等)。
3️⃣ 使用嵌入模型将数据转换为向量表示。
4️⃣ 存储元数据,以便后续进行预筛选或后筛选。
5️⃣ 索引嵌入数据,常见索引方法包括:
-
- 随机投影(Random Projection)
-
- 产品量化(Product Quantization)
-
- 局部敏感哈希(Locality-Sensitive Hashing, LSH)
6️⃣ 存储向量数据,同时建立索引,以便后续高效检索。
读取数据
7️⃣ 查询向量数据库通常包括两部分:
-
-
用于 ANN 搜索的数据
(例如,查询一张图片,寻找相似图片)。
-
-
-
元数据查询
(例如,搜索公寓图片,但排除特定城市的公寓)。
-
8️⃣ 执行元数据查询,可以在 ANN 搜索之前或之后进行。
9️⃣ 使用相同的嵌入模型将查询数据转换为向量。
🔟 执行 ANN 搜索,找出最相似的向量。常见的相似性度量方法包括:
-
- 余弦相似度(Cosine Similarity)
-
- 欧几里得距离(Euclidean Distance)
-
- 点积(Dot Product)
上下文检索:如何提高检索数据的准确性?
在 RAG 任务中,传统的检索方式可能会导致重要的上下文缺失,影响生成结果的质量。因此,Anthropic 团队提出了一种新的方法——上下文检索(Contextual Retrieval),其核心思想是在数据预处理阶段增强上下文信息,使得模型在查询时能够获得更精准的背景数据。
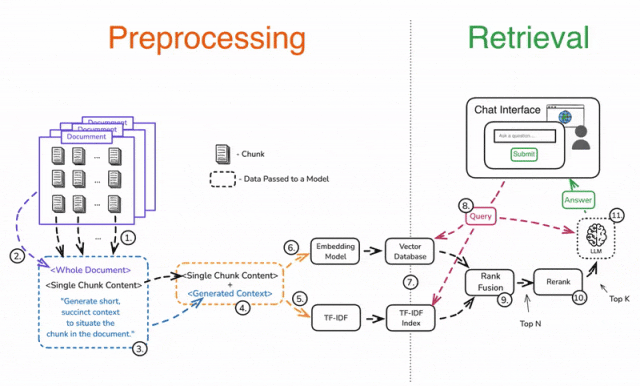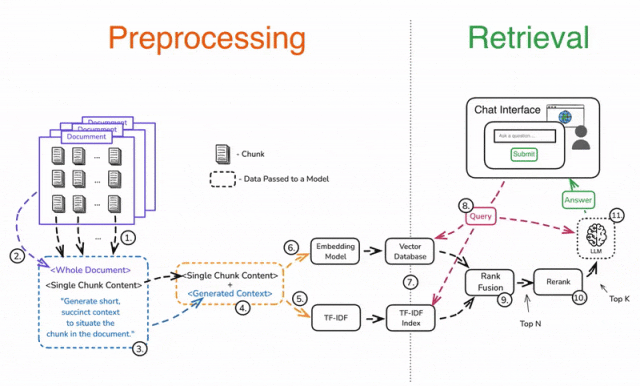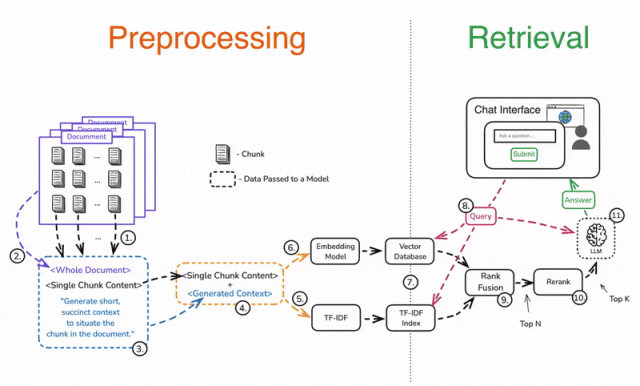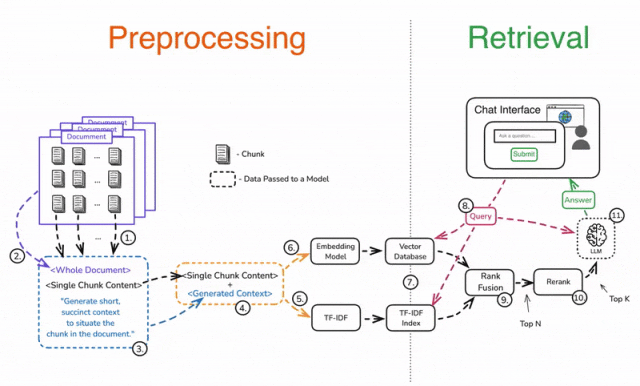
预处理(Preprocessing)
1️⃣ 将文档拆分成多个块(Chunks)。
2️⃣ 对每个分块单独处理,将其与完整文档一起加入 Prompt。
3️⃣ 添加指令,让 LLM 生成该分块的简要上下文,并明确该分块在文档中的位置。
4️⃣ 合并生成的上下文与原始分块。
5️⃣ 使用 TF-IDF 进行嵌入,提高关键词匹配能力。
6️⃣ 使用 LLM 进行向量嵌入,获取语义表示。
7️⃣ 存储嵌入数据,支持高效检索。
检索(Retrieval)
8️⃣ 使用用户查询进行上下文检索,ANN 进行语义匹配,TF-IDF 进行精确匹配。
9️⃣ 应用 Rank Fusion 技术,合并和去重检索结果,筛选出前 N 个最相关的数据块。
🔟 重新排序(Rerank)**结果,提取**前 K 个数据块。
1️⃣1️⃣ 将筛选后的数据块与用户查询一起输入 LLM,最终生成高质量的答案。
❗ 步骤 3 可能会带来较高的计算成本,但可以通过Prompt 缓存(Prompt Caching)降低成本,提高响应效率。
向量数据库 + 上下文检索,打造更精准的 AI 应用
向量数据库提供了一种高效的数据存储和检索方式,而上下文检索则进一步提高了数据的准确性和相关性。在 AI 领域,二者结合可以极大地提升 RAG 任务的质量,使 AI 能够生成更准确、更有用的答案。
如果你正在使用向量数据库,或者希望优化 AI 检索能力,不妨试试上下文检索!
💬 你是否已经在项目中使用了向量数据库和上下文检索?欢迎在评论区分享你的经验和思考! 👇
https://x.com/Aurimas_Gr/status/1895487197903454215
https://x.com/Aurimas_Gr/status/1895091102132429286
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭优快云大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









