



 文章介绍了CUDA共享内存的优势、结构(32个bank与warp线程对应),以及静态和动态共享内存的声明方式。重点讲解了如何在CUDA编程中利用共享内存提高性能和线程协作,以及大小限制和动态分配的机制。
文章介绍了CUDA共享内存的优势、结构(32个bank与warp线程对应),以及静态和动态共享内存的声明方式。重点讲解了如何在CUDA编程中利用共享内存提高性能和线程协作,以及大小限制和动态分配的机制。
共享内存(shared memory)
● 比global快上百倍
● 可以通过缓存数据减少对global memory的读写
● 线程间可以使用shared memory进行协作
共享内存会被分为32个bank,和warp中的线程数一致,即一个线程访问一个bank
从软件概念来讲,一个共享内存是在一个block内,block内的所有线程都能使用该共享内存
从硬件概念来讲,一个共享内存是在一个sm中
在使用共享内存时,一般会有两种用法:
静态共享内存
声明方式:
● __shared__关键字,固定大小
__shared__ float a[N];
这种使用方式可以定义多个共享内存变量,他们之间不会冲突,可以分别使用
动态共享内存
声明方式:
● extern __shared__关键字,不固定大小,大小由调用核函数<<<… shared_size>>>时指定。
extern __shared__ float a[];
这种使用方式原理是这样的:
首先注明了c++ 关键词 extern,表示该处只是声明而不是定义,说明这个变量不是在写extern shared float a[];这里定义的;
那是在哪里定义的呢?其实是cuda runtime 根据kernel函数插入的参数隐式的定义的;
那我们怎么知道它定义的地址呢?就是使用声明来声明一个变量就行,在一个核函数内,可以声明多个名字不同的extern __shared变量,但是实际上它们都是指向的同一个内存地址;
比如在代码中写了:
extern __shared__ float a[];
extern __shared__ float b[];
编译不会报错,你以为这是两个变量,但是实际上a和b是同一块内存,都是cuda runtime 为这个核函数定义的那块共享内存,a和b只是对这块内存的不同的名字而已
如果想使用多个数组,可以用指针,
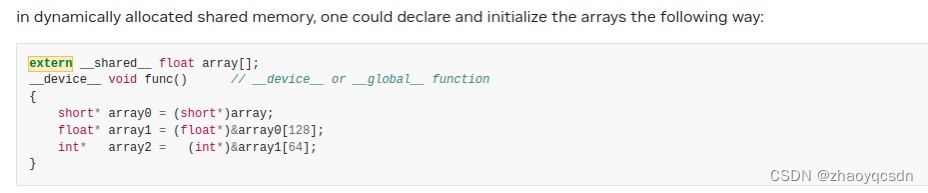
每个thread block的最大shared memory大小为64KB(arch-specific)
如果想声明超过48KB的共享内存,必须使用dynamic shared memory 且要设置cudaFuncAttributeMaxDynamicSharedMemorySize


















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









