



 文章详细解释了Transformer的核心注意力机制,如何通过点云示例理解其工作原理,包括Q、K和V的操作,以及Encoder和Decoder在模型中的作用。还提到VisionTransformer和使用CNN的变体。
文章详细解释了Transformer的核心注意力机制,如何通过点云示例理解其工作原理,包括Q、K和V的操作,以及Encoder和Decoder在模型中的作用。还提到VisionTransformer和使用CNN的变体。
transformer的核心是attention机制
attention的本质是找相关性,过滤掉相关性不高的部分,保留相关性高的部分,其实和卷积类似,都是滤波器(长得像的被保留,长得不像的被过滤)
下面以点云为例,理解一个transformer的原理:
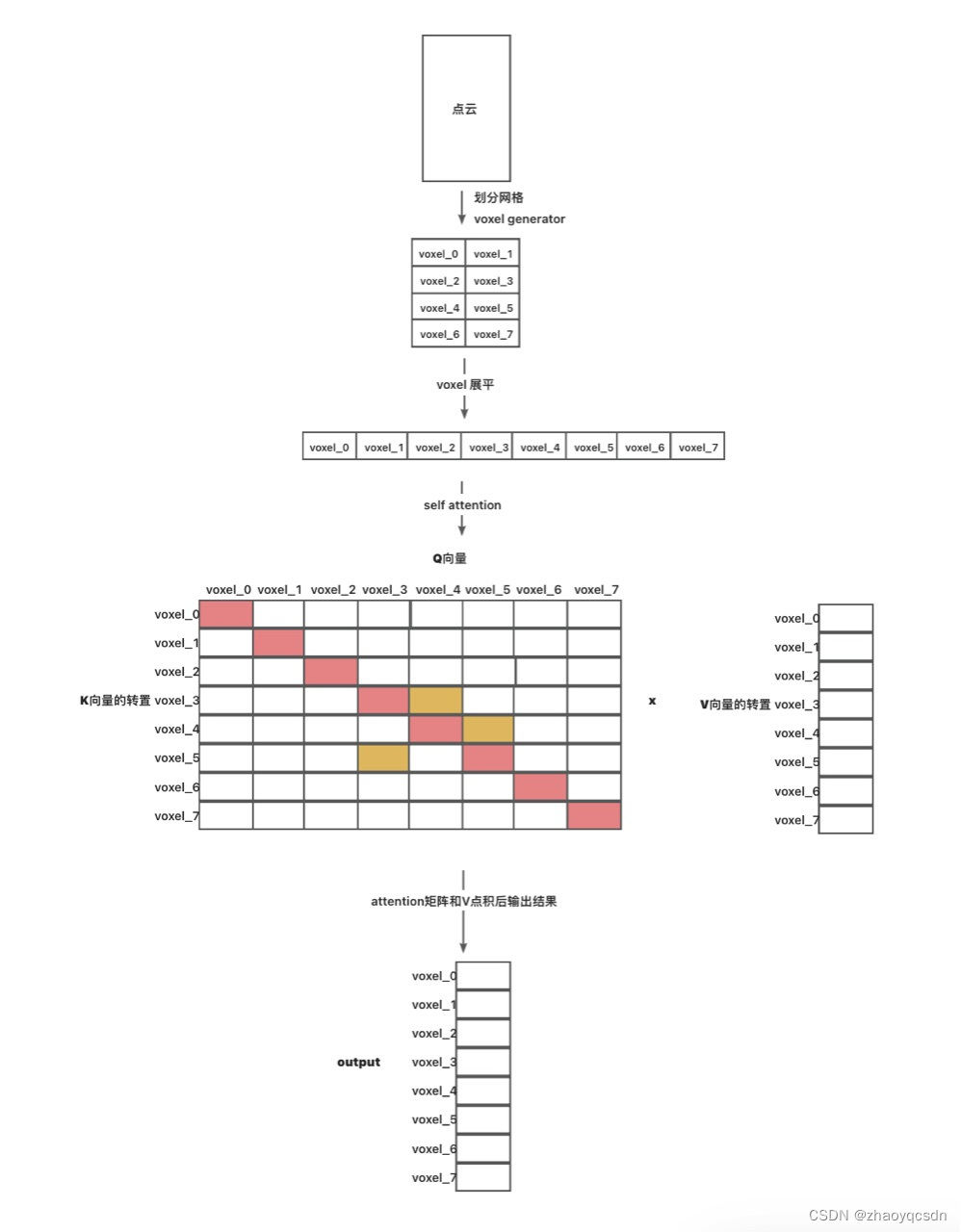
● Q和K进行点积和softmax, 得到attention分数矩阵,如上图。根据点积的定义,相似的向量得到的点积结果比较大;
● 因此,越是长得像(比如中心点位置接近)的voxel, 其对应的得分就会越高,比如Q 的voxel_0和K的voxel_0, 如果是自注意力,则他俩是相同的,因此相似度很高,得分就很高;
● 比如Q 的voxel_4和K的voxel_3,他俩得分比较高,说明他俩比较相似;
● 用左边的attention分数矩阵,和右边的V向量进行相乘,就将与voxel_i相似的值保留下来(因为权重大),而不相似的就被过滤了(被乘了很小的系数,比如0);
● 因此attention本质上还是过滤不相似的部分,得到相似的部分
● 经过attention,具有相似特征的voxel被叠加(聚合)在一起成为一个feature,比如上面的output,voxel_0中的值就是结合了K 0这一行所有和voxel_0比较像的结果,voxel_0可能和voxel_2也比较像,但是他俩在output中是两个feature,因此再经过一个linear层,将这些feature合并成想要的结果,比如分类别。
● 相同的输入做attention,就是self-attention
● 这个矩阵和算metrics的混淆矩阵还有点像
对于transformer来说,它分了encoder和decoder两个部分,
其中encoder部分就和上面说的一样,进行特征提取
然后将得到的结果复制两份,分别作为K和V输入muti-head-attention
而decoder的输入作为Q输入muti-head-attention,其原理也和上面一样,先看Q和K哪些"长得像",然后在把长得像的V取出来,就很想搜索一样,因此叫Query
在实际使用上,encoder和decoder可以不都有,两个可以单独使用,
如果只用来做特征提取,就只用encoder部分,比如vision transformer;
也可以用CNN做encoder部分,然后只使用transformer的decoder部分

















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









