




 本文介绍了神经网络中的损失函数概念及其重要性,详细探讨了不同任务类型(如回归和分类)所适用的损失函数,并对比了均方误差和交叉熵损失在训练过程中的表现差异。
本文介绍了神经网络中的损失函数概念及其重要性,详细探讨了不同任务类型(如回归和分类)所适用的损失函数,并对比了均方误差和交叉熵损失在训练过程中的表现差异。
第6章 神经网络损失函数(Neural Network Loss Function)
损失函数
loss=“mean_squared_error”
model.compile(loss="mean_squared_error", optimizer="sgd", metrics=["mae", "acc])
大纲
入门
- 定义
在深度学习中,损失函数是用来衡量一组参数的质量的函数,衡量的方式是比较网络输出和真实输出的差异。
- 命名
损失函数(loss function)、代价函数(cost function)、目标函数(objective function)、误差函数(error function)
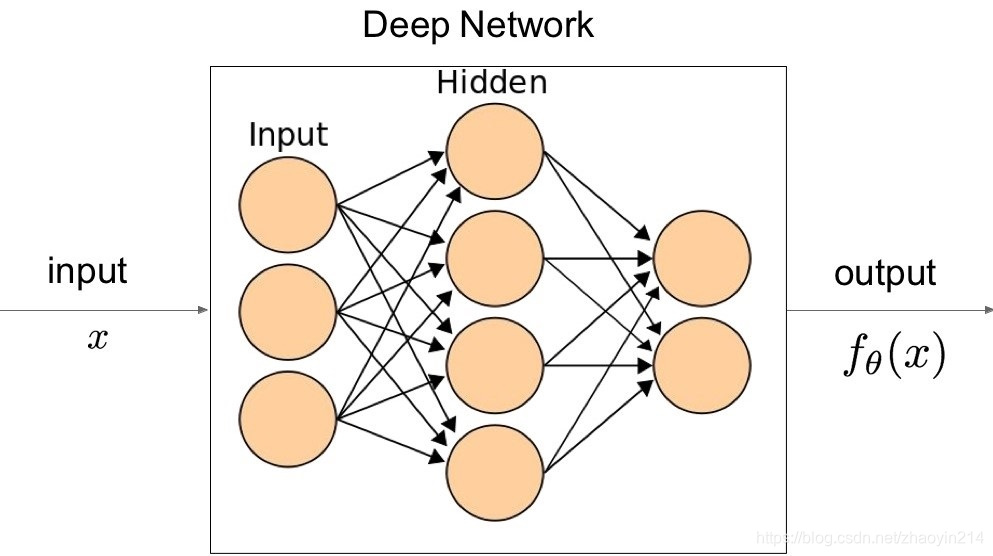
- 损失函数:衡量网络输出和真实值的差异
L ( θ ) = d i s t a n c e ( f θ ( x ) , y ) {L} (\theta) = \mathrm{distance} \left( f_{\theta} (x), y \right) L(θ)=distance(fθ(x),y)
(1)损失函数并不使用测试数据(test & validation data)来衡量网络的性能;
(2)损失函数用来指导训练过程,使得网络的参数向损失降低的方向改变。
- 训练过程
随机梯度下降法(Stochastic gradient descent)
(1)试图找到一组参数使得损失函数的值越小越好;
(2)调整参数的大小和方向取决于损失函数相对于参数的偏导数: ∂ L ∂ w \frac{\partial {L}}{\partial w} ∂w∂L, ∂ L ∂ b \frac{\partial {L}}{\partial b} ∂b∂L
- 特性
(1)当网络的输出和真实输出一致时,损失函数值最小(0);
(2)输出和真实输出越不一致,损失函数值越大。
(3)理想情况:凸函数(convex)
(4)实际情况:非凸函数(not convex)
损失函数需要根据输出的变化而平滑的变化:(1)可导(SGD优化);(2)容易求导
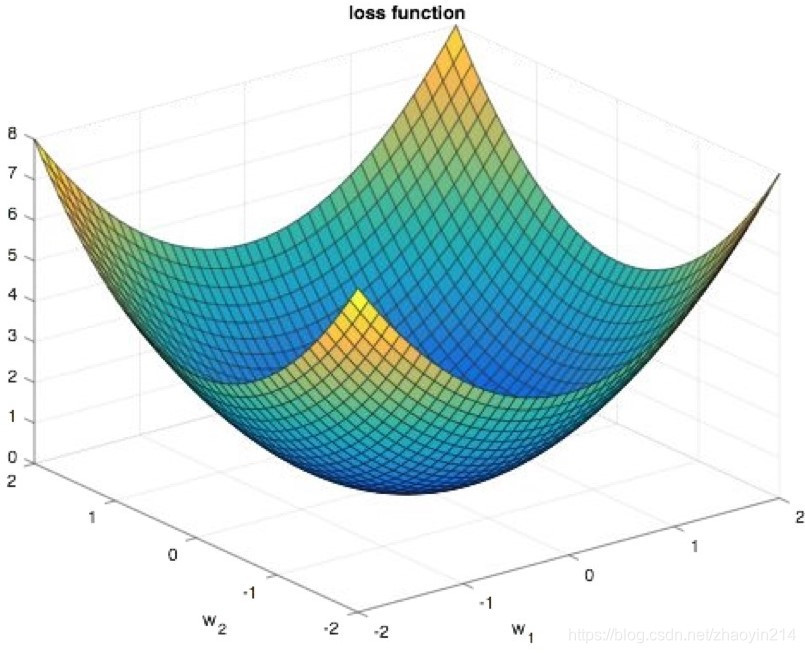
- 前提
为了使得误差向后传递(backpropagation)工作:
(1)损失函数为每一个独立训练样本损失的均值
L = 1 m ∑ i = 1 m L i {L} = \frac{1}{m} \sum_{i = 1}^{m} {L}_{i} L=m1i=1∑mLi
L {L} L称为经验风险(empirical risk)
(2)损失函数为网络输出的函数
常用的损失函数
- 不同的任务类型需要不同的损失函数
(1)回归(Regression):网络输出一个连续的数值
例如:预测一栋房屋的价值
损失函数:绝对值误差、平方差
(2)分类(Classification):网络的输出为一个类别,从预定义的一组类别中选择一个
实例:判断邮件是否是垃圾邮件
损失函数:合页损失(hinge loss)、交叉熵(Cross-entropy loss)
回归
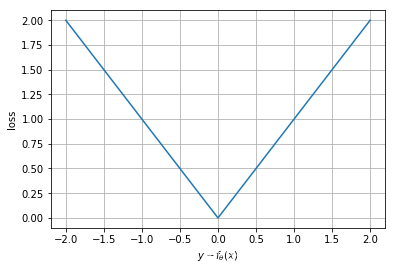
- 绝对误差函数(Absolute value, l 1 l_1 l1-norm):非常质感的损失函数
L = 1 m ∑ i = 1 m ∣ y i − f θ ( x i ) ∣ {L} = \frac{1}{m} \sum_{i = 1}^{m} \left| y_i - f_{\theta} (x_i) \right| L=m1i=1∑m∣yi−fθ(xi)∣
(1)得到的解会比较稀疏sparser
在高维度任务中表现比较好
预测速度快
(2)对异常值(outliers)不敏感
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-2, 2, 51)
y = np.abs(x)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(x, y)
ax.grid(True)
ax.set_xlabel(r"$y - f_{\theta} (x)$")
ax.set_ylabel(r"loss")
plt.show()
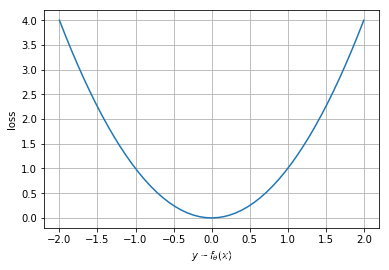
- 方差函数(Square error,Euclidean loss, L 2 L_2 L2-norm):常用的损失函数
L = 1 m ∑ i = 1 m ( y i − f θ ( x i ) ) 2 {L} = \frac{1}{m} \sum_{i = 1}^{m} \left( y_i - f_{\theta} (x_i) \right)^{2} L=m1i=1∑m(yi−fθ(xi))2
(1)比绝对误差函数输出结果更精准
(2)对大的误差输出更敏感
(3)对异常值(outliers)很敏感
x = np.linspace(-2, 2, 51)
y = x ** 2
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(x, y)
ax.grid(True)
ax.set_xlabel(r"$y - f_{\theta} (x)$")
ax.set_ylabel(r"loss")
plt.show()
PS:敏感是指误差函数非线性特性,误差函数对大的误差(或异常值)敏感是指其对大的误差(或异常值)的输出相对于其对小的误差(或正常值)的输出大于线性,即:
L ( α Δ x ) > α L ( Δ x ) , α ∈ R + {L} (\alpha \Delta x) > \alpha {L} ( \Delta x), \alpha \in {R}^{+} L(αΔx)>αL(Δx),α∈R+
分类
将输入分为固定的几个类别
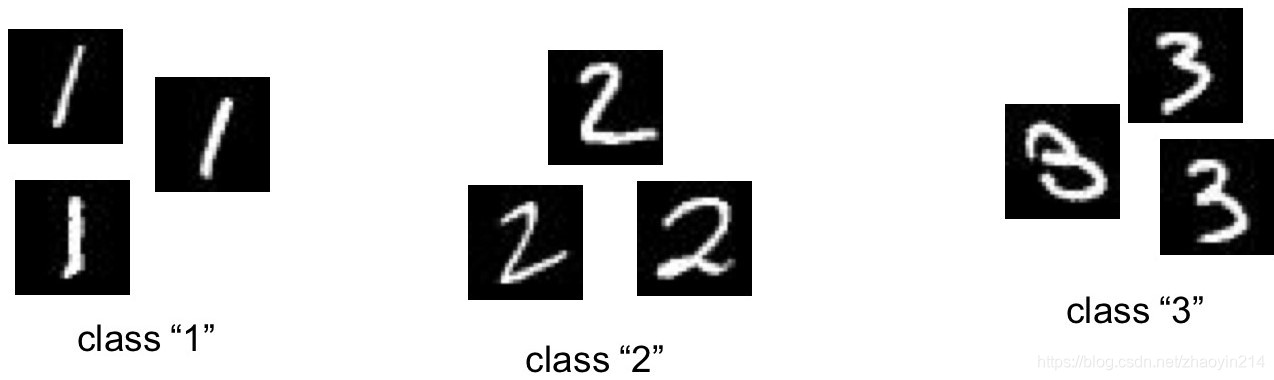
- 期望得到的结果是每一个输入对应一个类别输出
(1)网络的输出包含对每一个类别的预测值
(2)如果有 K K K个类别,网络的输出为 K K K维向量
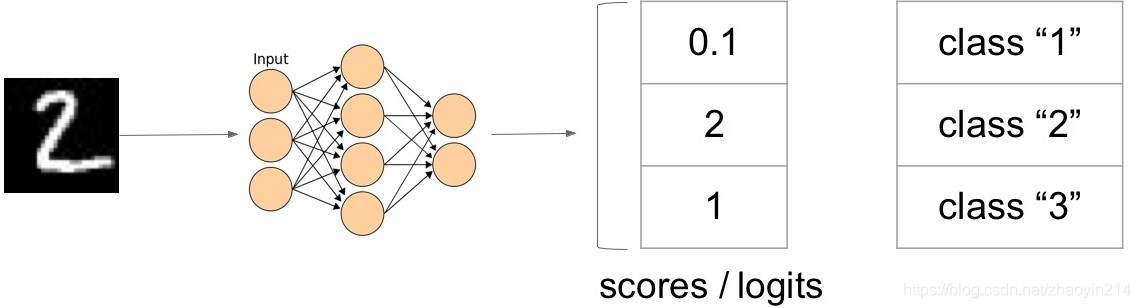
- 如何设计分类函数
(1)将样本的类别标签编码为一个向量 → \rightarrow →独热编码(one-hot encoding)
(2)非概率解释 → \rightarrow →合页函数(hinge loss)
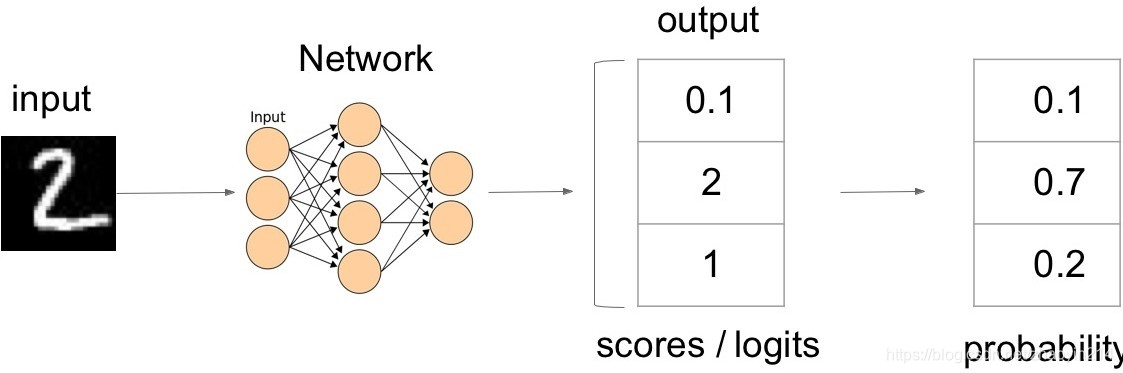
(3)概率解释:将输出转换为概率函数 → \rightarrow →Softmax
- Softmax
S ( l i ) = e l i ∑ k e l k S(l_i) = \frac{e^{l_i}}{\sum_k e^{l_k}} S(li)=∑kelkeli
其中, l i l_i li为scores(logits)
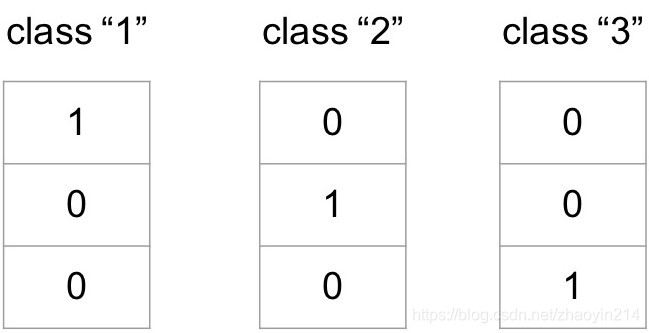
- 独热编码(One-hot encoding)
将每条样本的类别标签转换成对应的向量(每个向量元素的值为1或者0)
(1)向量维数为类别数量 K K K;
(2)元素1的位置对应样本的类别标签在标签集合中的索引。
- 交叉熵(Cross-entropy loss)
样本标签采用独热编码方式,即编码后标签为一 K K K维向量:
y = [ y 1 , y 2 , ⋯   , y K ] T \mathbf{y} = \left[ y_1, y_2, \cdots, y_K \right]^{\mathrm{T}} y=[y1,y2,⋯,yK]T
第 i i i条样本的独热编码标签记为 y i \mathbf{y}_i yi,Softmax输入向量记为 l i = f θ ( x i ) \mathbf{l}_i = f_{\theta} (\mathbf{x}_i) li=fθ(xi),则第 i i i条样本的交叉熵表示为:
L i = − ∑ k = 1 K y i , k log ( S k ( l i ) ) = − y i T ⋅ log [ S ( l i ) ] = − y i T ⋅ log [ S ( f θ ( x i ) ) ] \begin{aligned} {L}_i = & - \sum_{k = 1}^{K} y_{i, k} \log \left( S_k(\mathbf{l}_i) \right) \\ = & - \mathbf{y}_i^T \cdot \log \left[ S(\mathbf{l}_i) \right] \\ = & - \mathbf{y}_i^T \cdot \log \left[ S \left( f_{\theta} (\mathbf{x}_i) \right) \right] \\ \end{aligned} Li===−k=1∑Kyi,klog(Sk(li))−yiT⋅log[S(li)]−yiT⋅log[S(fθ(xi))]
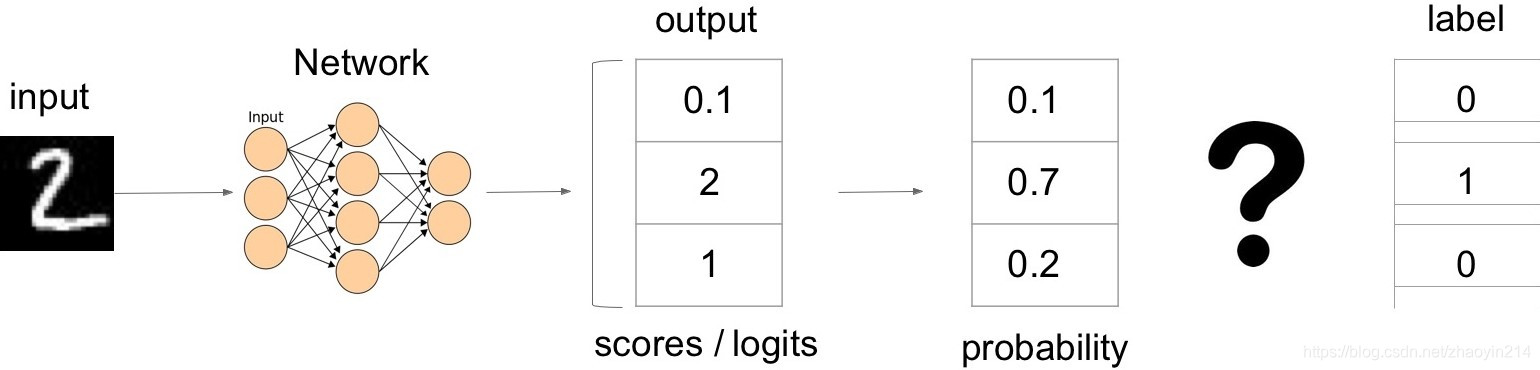
x = np.linspace(1e-5, 1, 1e3)
y = -1 * np.log(x)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(x, y)
ax.grid(True)
ax.set_xlabel(r"$x$")
ax.set_ylabel(r"- $\log$")
plt.show()
D:\ProgramData\Anaconda3\envs\greedyai\lib\site-packages\ipykernel_launcher.py:1: DeprecationWarning: object of type <class 'float'> cannot be safely interpreted as an integer.
"""Entry point for launching an IPython kernel.
对于包含 m m m个样本的批输入,其交叉熵为
L = 1 m ∑ i = 1 m L i = − 1 m ∑ i = 1 m y i T ⋅ log [ S ( f θ ( x i ) ) ] = 1 m ∑ i = 1 m ∑ k = 1 K L i , k = − 1 m ∑ i = 1 m ∑ k = 1 K y i , k log [ S k ( f θ ( x i ) ) ] \begin{aligned} {L} = & \frac{1}{m} \sum_{i = 1}^{m} {L}_i \\ = & - \frac{1}{m} \sum_{i = 1}^{m} \mathbf{y}_i^T \cdot \log \left[ S \left( f_{\theta} (\mathbf{x}_i) \right) \right] \\ = & \frac{1}{m} \sum_{i = 1}^{m} \sum_{k = 1}^{K} {L}_{i, k} \\ = & - \frac{1}{m} \sum_{i = 1}^{m} \sum_{k = 1}^{K} y_{i, k} \log \left[ S_k \left( f_{\theta} (\mathbf{x}_i) \right) \right] \\ \end{aligned} L====m1i=1∑mLi−m1i=1∑myiT⋅log[S(fθ(xi))]m1i=1∑mk=1∑KLi,k−m1i=1∑mk=1∑Kyi,klog[Sk(fθ(xi))]
一般而言,在分类问题中,交叉熵函数表现优于方差函数:
(1)方差函数对误差的输出惩罚非常大
(2)如果使用Softmax作为激活函数,方差函数作为损失函数,则梯度中包含 y ^ k ( 1 − y ^ k ) \hat{y}_{k}(1 - \hat{y}_{k}) y^k(1−y^k)( y ^ k \hat{y}_{k} y^k为Softmax输出列向量的第 k k k个元素),当输出接近0.0或者1.0时,梯度值非常小,网络训练会很慢。
二分类任务中,方差损失与交叉熵损失
考虑二分类任务,分类器结构采用单层网络、激活函数为Sigmoid,网络输入为 x i \mathbf{x}_i xi、输出为 y ^ i \hat{y}_i y^i
i i i:样本索引
x i = [ x i , 1 , x i , 2 , ⋯   , x i , n ] \mathbf{x}_i = \left[ x_{i, 1}, x_{i, 2}, \cdots, x_{i, n} \right] xi=[xi,1,xi,2,⋯,xi,n]:第 i i i条样本, n n n维列向量
y ^ i \hat{y}_i y^i:第 i i i条样本估计,标量;
y i y_i yi:第 i i i条样本的标签,标量;
θ \mathbf{\theta} θ:单层网络权值系数向量, n × 1 {n \times 1} n×1维, [ θ j ] n × 1 \left[ \theta_{j} \right]_{n \times 1} [θj]n×1
b b b:单层网络偏置系数,标量
- 方差函数的梯度(Gradient of square error loss)
预测:
y
^
i
=
σ
(
θ
T
x
i
+
b
)
\hat{y}_i = \sigma ( \mathbf{\theta}^{\mathrm{T}} \mathbf{x}_i + b )
y^i=σ(θTxi+b)
损失:
L
i
=
1
2
∥
y
i
−
y
^
i
∥
2
=
1
2
(
y
i
−
y
^
i
)
2
\begin{aligned} {L}_i = & \frac{1}{2} \left\| y_i - \hat{y}_i \right\|^{2} \\ = & \frac{1}{2} \left( y_{i} - \hat{y}_{i} \right)^{2} \end{aligned}
Li==21∥yi−y^i∥221(yi−y^i)2
损失函数关于 θ j \theta_{j} θj的梯度:
∂ L i ∂ θ j = ∂ L i ∂ y ^ i ∂ y ^ i ∂ θ j \frac{\partial {L}_i}{\partial \theta_{j}} = \frac{\partial {L}_i}{\partial \hat{y}_{i}} \frac{\partial \hat{y}_{i}}{\partial \theta_{j}} ∂θj∂Li=∂y^i∂Li∂θj∂y^i
(1) L i {L}_i Li关于 y ^ i \hat{y}_{i} y^i的偏导:
∂ L i ∂ y ^ i = ( y ^ i − y i ) \frac{\partial {L}_i}{\partial \hat{y}_{i}} = \left( \hat{y}_{i} - y_{i} \right) ∂y^i∂Li=(y^i−yi)
(2) y ^ i \hat{y}_{i} y^i关于 θ j \theta_{j} θj的偏导:
y ^ i = σ ( θ T x i + b ) = 1 1 + e − ( θ T x i + b ) \begin{aligned} \hat{y}_i = & \sigma \left( \mathbf{\theta}^{\mathrm{T}} \mathbf{x}_i + b \right) = \frac{1}{1 + e^{ - \left( \mathbf{\theta}^{\mathrm{T}} \mathbf{x}_i + b \right)}} \\ \end{aligned} y^i=σ(θTxi+b)=1+e−(θTxi+b)1
∂ y ^ i ∂ θ j = σ k ( 1 − σ k ) x i , j = y ^ i ( 1 − y ^ i ) x i , j \begin{aligned} \frac{\partial \hat{y}_{i}}{\partial \theta_{j}} = & \sigma_{k} \left( 1 - \sigma_{k} \right) x_{i, j} \\ = & \hat{y}_{i} \left( 1 - \hat{y}_{i} \right) x_{i, j} \end{aligned} ∂θj∂y^i==σk(1−σk)xi,jy^i(1−y^i)xi,j
即
∂ L i ∂ θ j = ( y ^ i − y i ) y ^ i ( 1 − y ^ i ) x i , j \frac{\partial {L}_i}{\partial \theta_{j}} = \left( \hat{y}_{i} - y_{i} \right) \hat{y}_{i} \left( 1 - \hat{y}_{i} \right) x_{i, j} ∂θj∂Li=(y^i−yi)y^i(1−y^i)xi,j
注意: y ^ i ∈ ( 0 , 1 ) \hat{y}_{i} \in ( 0, 1 ) y^i∈(0,1),因此当 y ^ i → 1 or 0 \hat{y}_{i} \rightarrow 1 \ \text{or} \ 0 y^i→1 or 0时,无论 y ^ i \hat{y}_{i} y^i是否趋近于 y i y_i yi(即无论样本是否被正确分类,或损失函数是否到达关于样本 i i i的极小值点),都有 ∂ L i ∂ θ j → 0 , ∀ j \frac{\partial {L}_i}{\partial \theta_{j}} \rightarrow 0, \forall j ∂θj∂Li→0,∀j,即损失函数梯度消失,权值系数向量 θ \mathbf{\theta} θ更新近似停止。
- 交叉熵函数的梯度(Gradient of cross-entropy loss)
预测:
y
^
i
=
σ
(
θ
x
i
+
b
)
\hat{y}_i = \sigma ( \mathbf{\theta} \mathbf{x}_i + b )
y^i=σ(θxi+b)
损失:
L
i
=
∑
k
=
1
2
L
i
=
−
y
i
log
[
y
^
i
]
−
(
1
−
y
i
)
log
[
1
−
y
^
i
]
=
−
y
i
log
[
σ
k
(
θ
x
i
+
b
)
]
−
(
1
−
y
i
)
log
[
1
−
σ
k
(
θ
x
i
+
b
)
]
\begin{aligned} {L}_i = & \sum_{k = 1}^{2} {L}_{i} \\ = & - y_{i} \log \left[ \hat{y}_i \right] - (1 - y_{i}) \log \left[ 1 - \hat{y}_i \right] \\ = & - y_{i} \log \left[ \sigma_k \left( \mathbf{\theta} \mathbf{x}_i + b \right) \right] - (1 - y_{i}) \log \left[ 1 - \sigma_k \left( \mathbf{\theta} \mathbf{x}_i + b \right) \right] \end{aligned}
Li===k=1∑2Li−yilog[y^i]−(1−yi)log[1−y^i]−yilog[σk(θxi+b)]−(1−yi)log[1−σk(θxi+b)]
损失函数关于 θ j \theta_{j} θj的梯度:
∂ L i ∂ θ j = ∂ L i ∂ y ^ i ∂ y ^ i ∂ θ j \frac{\partial {L}_i}{\partial \theta_{j}} = \frac{\partial {L}_i}{\partial \hat{y}_{i}} \frac{\partial \hat{y}_{i}}{\partial \theta_{j}} ∂θj∂Li=∂y^i∂Li∂θj∂y^i
(1) L i {L}_i Li关于 y ^ i \hat{y}_{i} y^i的偏导:
∂ L i ∂ y ^ i = − y i y ^ i + 1 − y i 1 − y ^ i = − ( y i − y ^ i ) y ^ i ( 1 − y ^ i ) \frac{\partial {L}_i}{\partial \hat{y}_{i}} = - \frac{y_{i}}{\hat{y}_{i}} + \frac{1 - y_{i}}{1 - \hat{y}_{i}} = - \frac{(y_i - \hat{y}_i)}{\hat{y}_i (1 - \hat{y}_i)} ∂y^i∂Li=−y^iyi+1−y^i1−yi=−y^i(1−y^i)(yi−y^i)
(2) y ^ i \hat{y}_{i} y^i关于 θ j \theta_{j} θj的偏导:
∂ y ^ i ∂ θ j = y ^ i ( 1 − y ^ i ) x i , j \begin{aligned} \frac{\partial \hat{y}_{i}}{\partial \theta_{j}} = & \hat{y}_{i} \left( 1 - \hat{y}_{i} \right) x_{i, j} \end{aligned} ∂θj∂y^i=y^i(1−y^i)xi,j
即
∂ L i ∂ θ j = − ( y i − y ^ i ) x i , j \begin{aligned} \frac{\partial {L}_i}{\partial \theta_{j}} = & - (y_i - \hat{y}_i) x_{i, j} \end{aligned} ∂θj∂Li=−(yi−y^i)xi,j
注意: y ^ i ∈ ( 0 , 1 ) \hat{y}_{i} \in ( 0, 1 ) y^i∈(0,1),仅当 y ^ i → y i \hat{y}_{i} \rightarrow y_i y^i→yi时,即样本被正确分类(损失函数关于样本 i i i的极小值点),损失函数关于 θ j \theta_{j} θj的梯度才会消失,权值系数向量 θ \mathbf{\theta} θ更新停止。
多分类任务中,方差损失与交叉熵损失
考虑多分类任务,分类器结构采用单层网络、激活函数为Softmax,网络输入为 x i \mathbf{x}_i xi、输出为 y ^ i \hat{\mathbf{y}}_i y^i
i i i:样本索引
x i = [ x i , 1 , x i , 2 , ⋯   , x i , n ] \mathbf{x}_i = \left[ x_{i, 1}, x_{i, 2}, \cdots, x_{i, n} \right] xi=[xi,1,xi,2,⋯,xi,n]:第 i i i条样本, n n n维列向量
y ^ i = [ y ^ i , 1 , y ^ i , 2 , ⋯   , y ^ i , k , ⋯   , y ^ i , K ] \hat{\mathbf{y}}_i = \left[ \hat{y}_{i, 1}, \hat{y}_{i, 2}, \cdots, \hat{y}_{i, k}, \cdots, \hat{y}_{i, K} \right] y^i=[y^i,1,y^i,2,⋯,y^i,k,⋯,y^i,K]:第 i i i条样本估计, K K K维列向量;
y i \mathbf{y}_i yi:第 i i i条样本独热编码标签, K K K维列向量
θ \mathbf{\theta} θ:单层网络权值系数矩阵, K × n K \times n K×n维, [ θ k j ] K × n \left[ \theta_{kj} \right]_{K \times n} [θkj]K×n
b = [ b 1 , b 2 , ⋯   , b K ] \mathbf{b} = \left[ b_{1}, b_{2}, \cdots, b_{K} \right] b=[b1,b2,⋯,bK]:单层网络偏置系数, K K K维列向量
- 方差函数的梯度(Gradient of square error loss)
预测:
y
^
i
=
S
(
θ
x
i
+
b
)
\hat{\mathbf{y}}_i = S ( \mathbf{\theta} \mathbf{x}_i + \mathbf{b} )
y^i=S(θxi+b)
损失:
L
i
=
1
2
∥
y
i
−
y
^
i
∥
2
=
1
2
(
y
i
−
y
^
i
)
T
(
y
i
−
y
^
i
)
=
∑
k
L
i
,
k
=
1
2
∑
k
(
y
i
,
k
−
y
^
i
,
k
)
2
\begin{aligned} {L}_i = & \frac{1}{2} \left\| \mathbf{y}_i - \hat{\mathbf{y}}_i \right\|^{2} \\ = & \frac{1}{2} \left( \mathbf{y}_i - \hat{\mathbf{y}}_i \right)^{T} \left( \mathbf{y}_i - \hat{\mathbf{y}}_i \right) \\ = & \sum_k {{L}}_{i, k} \\ = & \frac{1}{2} \sum_k \left( y_{i, k} - \hat{y}_{i, k} \right)^{2} \end{aligned}
Li====21∥yi−y^i∥221(yi−y^i)T(yi−y^i)k∑Li,k21k∑(yi,k−y^i,k)2
损失函数关于 θ k , j \theta_{k, j} θk,j的梯度:
∂ L i ∂ θ k , j = ∂ L i ∂ y ^ i , k ∂ y ^ i , k ∂ θ k , j + ∑ l ̸ = k ∂ L i ∂ y ^ i , l ∂ y ^ i , l ∂ θ l , j \frac{\partial {L}_i}{\partial \theta_{k, j}} = \frac{\partial {L}_i}{\partial \hat{y}_{i, k}} \frac{\partial \hat{y}_{i, k}}{\partial \theta_{k, j}} + \sum_{l \not= k} \frac{\partial {L}_i}{\partial \hat{y}_{i, l}} \frac{\partial \hat{y}_{i, l}}{\partial \theta_{l, j}} ∂θk,j∂Li=∂y^i,k∂Li∂θk,j∂y^i,k+l̸=k∑∂y^i,l∂Li∂θl,j∂y^i,l
(1) L i {L}_i Li关于 y ^ i , k \hat{y}_{i, k} y^i,k的偏导:
∂ L i ∂ y ^ i , k = ( y ^ i , k − y i , k ) \frac{\partial {L}_i}{\partial \hat{y}_{i, k}} = \left( \hat{y}_{i, k} - y_{i, k} \right) ∂y^i,k∂Li=(y^i,k−yi,k)
(2) y ^ i , k \hat{y}_{i, k} y^i,k关于 θ k , j \theta_{k, j} θk,j的偏导:
y ^ i = S ( θ x i + b ) = e θ x i + b ∑ e θ x i + b y ^ i , k = S k ( θ x i + b ) = e θ [ k , : ] x i + b k ∑ k e θ [ k , : ] x i + b k \begin{aligned} \hat{\mathbf{y}}_i = & S \left( \mathbf{\theta} \mathbf{x}_i + \mathbf{b} \right) = \frac{e^{\mathbf{\theta} \mathbf{x}_i + \mathbf{b}}}{\sum e^{\mathbf{\theta} \mathbf{x}_i + \mathbf{b}}} \\ \hat{y}_{i, k} = & S_{k} \left( \mathbf{\theta} \mathbf{x}_i + \mathbf{b} \right) = \frac{e^{\mathbf{\theta}_{[k, :]} \mathbf{x}_i + b_{k}}}{\sum_{k} e^{\mathbf{\theta}_{[k, :]} \mathbf{x}_i + b_{k}}} \end{aligned} y^i=y^i,k=S(θxi+b)=∑eθxi+beθxi+bSk(θxi+b)=∑keθ[k,:]xi+bkeθ[k,:]xi+bk
∂ y ^ i , k ∂ θ k , j = S k ( 1 − S k ) x i , j = y ^ i , k ( 1 − y ^ i , k ) x i , j \begin{aligned} \frac{\partial \hat{y}_{i, k}}{\partial \theta_{k, j}} = & S_{k} \left( 1 - S_{k} \right) x_{i, j} \\ = & \hat{y}_{i, k} \left( 1 - \hat{y}_{i, k} \right) x_{i, j} \end{aligned} ∂θk,j∂y^i,k==Sk(1−Sk)xi,jy^i,k(1−y^i,k)xi,j
(3) y ^ i , l \hat{y}_{i, l} y^i,l( l ̸ = k l \not= k l̸=k)关于 θ k , j \theta_{k, j} θk,j的偏导:
y ^ i , l = S l ( θ x i + b ) = e θ [ l , : ] x i + b l ∑ k e θ [ k , : ] x i + b k \hat{y}_{i, l} = S_{l} \left( \mathbf{\theta} \mathbf{x}_i + \mathbf{b} \right) = \frac{e^{\mathbf{\theta}_{[l, :]} \mathbf{x}_i + b_{l}}}{\sum_{k} e^{\mathbf{\theta}_{[k, :]} \mathbf{x}_i + b_{k}}} y^i,l=Sl(θxi+b)=∑keθ[k,:]xi+bkeθ[l,:]xi+bl
∂ y ^ i , l ∂ θ k , j = − S k S l x i , j = − y ^ i , k y ^ i , l x i , j \begin{aligned} \frac{\partial \hat{y}_{i, l}}{\partial \theta_{k, j}} = & - S_{k} S_{l} x_{i, j} \\ = & - \hat{y}_{i, k} \hat{y}_{i, l} x_{i, j} \end{aligned} ∂θk,j∂y^i,l==−SkSlxi,j−y^i,ky^i,lxi,j
即
∂ L i ∂ θ k , j = ( y ^ i , k − y i , k ) y ^ i , k ( 1 − y ^ i , k ) x i , j − ∑ l ̸ = k ( y ^ i , l − y i , l ) y ^ i , k y ^ i , l x i , j \frac{\partial {L}_i}{\partial \theta_{k, j}} = \left( \hat{y}_{i, k} - y_{i, k} \right) \hat{y}_{i, k} \left( 1 - \hat{y}_{i, k} \right) x_{i, j} - \sum_{l \not= k} \left( \hat{y}_{i, l} - y_{i, l} \right) \hat{y}_{i, k} \hat{y}_{i, l} x_{i, j} ∂θk,j∂Li=(y^i,k−yi,k)y^i,k(1−y^i,k)xi,j−l̸=k∑(y^i,l−yi,l)y^i,ky^i,lxi,j
注意: y ^ i , k ∈ [ 0 , 1 ] \hat{y}_{i, k} \in [ 0, 1 ] y^i,k∈[0,1]且 ∑ k y ^ i , k = 1 \sum_{k} \hat{y}_{i, k} = 1 ∑ky^i,k=1,因此当 y ^ i , r → 1 , ∀ r \hat{y}_{i, r} \rightarrow 1, \forall r y^i,r→1,∀r时, y ^ i , l ∣ l ̸ = r → 0 \hat{y}_{i, l | l \not= r} \rightarrow 0 y^i,l∣l̸=r→0或者 ( 1 − y ^ i , k ∣ k = r ) → 0 \left( 1 - \hat{y}_{i, k | k = r} \right) \rightarrow 0 (1−y^i,k∣k=r)→0,此时 ∂ L i ∂ θ k , j → 0 , ∀ k , j \frac{\partial {L}_i}{\partial \theta_{k, j}} \rightarrow 0, \forall k, j ∂θk,j∂Li→0,∀k,j,即无论 y ^ i \hat{\mathbf{y}}_{i} y^i是否趋近于 y i \mathbf{y}_i yi(无论样本是否被正确分类,或者损失函数是否到达关于样本 i i i的极小值点),损失函数梯度都会消失,权值系数矩阵 θ = [ θ k j ] K × n \mathbf{\theta} = \left[ \theta_{kj} \right]_{K \times n} θ=[θkj]K×n更新近似停止。
- 交叉熵函数的梯度(Gradient of cross-entropy loss)
预测:
y
^
i
=
S
(
θ
x
i
+
b
)
\hat{\mathbf{y}}_i = S ( \mathbf{\theta} \mathbf{x}_i + \mathbf{b} )
y^i=S(θxi+b)
损失:
L
i
=
∑
k
=
1
K
L
i
,
k
=
−
∑
k
=
1
K
y
i
,
k
log
y
^
i
,
k
=
−
∑
k
=
1
K
y
i
,
k
log
[
S
k
(
θ
x
i
+
b
)
]
\begin{aligned} {L}_i = & \sum_{k = 1}^{K} {L}_{i, k} \\ = & - \sum_{k = 1}^{K} y_{i, k} \log \hat{y}_{i, k} \\ = & - \sum_{k = 1}^{K} y_{i, k} \log \left[ S_k \left( \mathbf{\theta} \mathbf{x}_i + \mathbf{b} \right) \right] \end{aligned}
Li===k=1∑KLi,k−k=1∑Kyi,klogy^i,k−k=1∑Kyi,klog[Sk(θxi+b)]
损失函数关于 θ k , j \theta_{k, j} θk,j的梯度:
∂ L i ∂ θ k , j = ∂ L i ∂ y ^ i , k ∂ y ^ i , k ∂ θ k , j + ∑ l ̸ = k ∂ L i ∂ y ^ i , l ∂ y ^ i , l ∂ θ l , j \frac{\partial {L}_i}{\partial \theta_{k, j}} = \frac{\partial {L}_i}{\partial \hat{y}_{i, k}} \frac{\partial \hat{y}_{i, k}}{\partial \theta_{k, j}} + \sum_{l \not= k} \frac{\partial {L}_i}{\partial \hat{y}_{i, l}} \frac{\partial \hat{y}_{i, l}}{\partial \theta_{l, j}} ∂θk,j∂Li=∂y^i,k∂Li∂θk,j∂y^i,k+l̸=k∑∂y^i,l∂Li∂θl,j∂y^i,l
(1) L i {L}_i Li关于 y ^ i , k \hat{y}_{i, k} y^i,k的偏导:
∂ L i ∂ y ^ i , k = − y i , k y ^ i , k \frac{\partial {L}_i}{\partial \hat{y}_{i, k}} = - \frac{y_{i, k}}{\hat{y}_{i, k}} ∂y^i,k∂Li=−y^i,kyi,k
(2) y ^ i , k \hat{y}_{i, k} y^i,k关于 θ k , j \theta_{k, j} θk,j的偏导:
∂ y ^ i , k ∂ θ k , j = y ^ i , k ( 1 − y ^ i , k ) x i , j \begin{aligned} \frac{\partial \hat{y}_{i, k}}{\partial \theta_{k, j}} = & \hat{y}_{i, k} \left( 1 - \hat{y}_{i, k} \right) x_{i, j} \end{aligned} ∂θk,j∂y^i,k=y^i,k(1−y^i,k)xi,j
(3) y ^ i , l \hat{y}_{i, l} y^i,l( l ̸ = k l \not= k l̸=k)关于 θ k , j \theta_{k, j} θk,j的偏导:
∂ y ^ i , l ∂ θ k , j = − y ^ i , k y ^ i , l x i , j \begin{aligned} \frac{\partial \hat{y}_{i, l}}{\partial \theta_{k, j}} = & - \hat{y}_{i, k} \hat{y}_{i, l} x_{i, j} \end{aligned} ∂θk,j∂y^i,l=−y^i,ky^i,lxi,j
即
∂ L i ∂ θ k , j = − y i , k y ^ i , k y ^ i , k ( 1 − y ^ i , k ) x i , j + ∑ l ̸ = k y i , l y ^ i , l y ^ i , k y ^ i , l x i , j = − y i , k ( 1 − y ^ i , k ) x i , j + ∑ l ̸ = k y i , l y ^ i , k x i , j \begin{aligned} \frac{\partial {L}_i}{\partial \theta_{k, j}} = & - \frac{y_{i, k}}{\hat{y}_{i, k}} \hat{y}_{i, k} \left( 1 - \hat{y}_{i, k} \right) x_{i, j} + \sum_{l \not= k} \frac{y_{i, l}}{\hat{y}_{i, l}} \hat{y}_{i, k} \hat{y}_{i, l} x_{i, j} \\ = & - y_{i, k} \left( 1 - \hat{y}_{i, k} \right) x_{i, j} + \sum_{l \not= k} y_{i, l} \hat{y}_{i, k} x_{i, j} \end{aligned} ∂θk,j∂Li==−y^i,kyi,ky^i,k(1−y^i,k)xi,j+l̸=k∑y^i,lyi,ly^i,ky^i,lxi,j−yi,k(1−y^i,k)xi,j+l̸=k∑yi,ly^i,kxi,j
注意: y ^ i , k ∈ [ 0 , 1 ] \hat{y}_{i, k} \in [ 0, 1 ] y^i,k∈[0,1]且 ∑ k y ^ i , k = 1 \sum_{k} \hat{y}_{i, k} = 1 ∑ky^i,k=1,因此当 y ^ i , r → 1 , ∀ r \hat{y}_{i, r} \rightarrow 1, \forall r y^i,r→1,∀r时, y ^ i , l ∣ l ̸ = r → 0 \hat{y}_{i, l | l \not= r} \rightarrow 0 y^i,l∣l̸=r→0或者 ( 1 − y ^ i , k ∣ k = r ) → 0 \left( 1 - \hat{y}_{i, k | k = r} \right) \rightarrow 0 (1−y^i,k∣k=r)→0,此时 ∂ L i ∂ θ k , j ≈ ∑ l ̸ = k y i , l x i , j , k = r , ∀ j \frac{\partial {L}_i}{\partial \theta_{k, j}} \approx \sum_{l \not= k} y_{i, l} x_{i, j}, k = r, \forall j ∂θk,j∂Li≈∑l̸=kyi,lxi,j,k=r,∀j或者 ∂ L i ∂ θ k , j ≈ − y i , k x i , j , ∀ j , k ̸ = r \frac{\partial {L}_i}{\partial \theta_{k, j}} \approx - y_{i, k} x_{i, j}, \forall j, k \not= r ∂θk,j∂Li≈−yi,kxi,j,∀j,k̸=r。仅当 y ^ i → y i \hat{\mathbf{y}}_{i} \rightarrow \mathbf{y}_i y^i→yi时,即样本被正确分类(损失函数关于样本 i i i的极小值点),损失函数关于 θ k , j \theta_{k, j} θk,j的梯度才会消失,权值系数矩阵 θ = [ θ k j ] K × n \mathbf{\theta} = \left[ \theta_{kj} \right]_{K \times n} θ=[θkj]K×n更新停止。
PS:上述推导过程是针对单样本的损失函数 L i {L}_i Li进行的,对于批量梯度下降,损失函数 L = 1 m ∑ i = 1 m L i {L} = \frac{1}{m} \sum_{i = 1}^{m} {L}_i L=m1∑i=1mLi,此时,
(1)对于方差损失,只要大多数样本预测向量中包含 y ^ i , k → 1 \hat{y}_{i, k} \rightarrow 1 y^i,k→1(无论这些样本是否被正确分类),损失函数梯度就会消失,权值系数 θ \mathbf{\theta} θ更新近似停止,即训练过程可能陷入鞍点(saddle point),而难以到达方差损失的局部极小值点。
(2)对于交叉熵损失,只有当大多数样本预测向量否被正确分类时,损失函数梯度才会消失,权值系数 θ \mathbf{\theta} θ更新停止,交叉熵损失到达局部极小值而不会陷入鞍点。
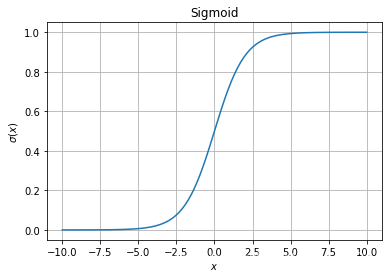
- 多标签(Multi-label)分类问题
多标签分类问题不是多分类(Multi-class)问题
(1)输出属于多个类别中的一个或者多个类;
例如:一幅包含猫咪的图像可以同时属于“猫”、“哺乳动物”和“宠物”类别。
(2)对每一个输出独立使用Sigmoid( σ ( ⋅ ) \sigma (\cdot) σ(⋅))作为激活函数,而非Softmax;
σ ( l i ) = 1 1 + e − l i \sigma \left( l_i \right) = \frac{1}{ 1 + e^{- l_i}} σ(li)=1+e−li1
def sigmoid(x):
return 1 / (1 + np.exp(-1 * x))
x = np.linspace(-10, 10, 100)
y = sigmoid(x)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(x, y)
ax.grid(True)
ax.set_xlabel("$x$")
ax.set_ylabel("$\\sigma(x)$")
ax.set_title("Sigmoid")
plt.show()
(3)多标签问题的交叉熵损失(Cross-entropy loss for multi-label classification)
L i = − ∑ k = 1 K y i , k log [ σ ( f θ , k ( x i ) ) ] + ( 1 − y i , k ) log [ 1 − σ ( f θ , k ( x i ) ) ] \begin{aligned} {L}_i = & - \sum_{k = 1}^{K} y_{i, k} \log \left[ \sigma \left( f_{\theta, k} (\mathbf{x}_i) \right) \right] + (1 - y_{i, k}) \log \left[ 1 - \sigma \left( f_{\theta, k} (\mathbf{x}_i) \right) \right] \end{aligned} Li=−k=1∑Kyi,klog[σ(fθ,k(xi))]+(1−yi,k)log[1−σ(fθ,k(xi))]
(4)多分类问题的交叉熵损失(Cross-entropy loss for multi-class classification)
L i = − ∑ k = 1 K y i , k log [ S k ( f θ ( x i ) ) ] \begin{aligned} {L}_i = & - \sum_{k = 1}^{K} y_{i, k} \log \left[ S_k \left( f_{\theta} (\mathbf{x}_i) \right) \right] \end{aligned} Li=−k=1∑Kyi,klog[Sk(fθ(xi))]
其中, f θ ( x i ) f_{\theta} \left( \mathbf{x}_i \right) fθ(xi)是一个 K K K维列向量,表示输出层激活函数的输入, f θ , k ( x i ) f_{\theta, k} \left( \mathbf{x}_i \right) fθ,k(xi)表示 f θ ( x i ) f_{\theta} \left( \mathbf{x}_i \right) fθ(xi)的第 k k k个元素。
正则化
正则化(Regularization):避免网络过拟合(prevent overfitting)
(1) L 2 L_2 L2正则( L 2 L_2 L2-regularization)权值衰减(weight decay):
L r e g = L + λ 2 ∥ θ ∥ 2 2 {L}_{\mathrm{reg}} = {L} + \frac{\lambda}{2} \left\| \theta \right\|_{2}^{2} Lreg=L+2λ∥θ∥22
(2) L 1 L_1 L1-regularization:
L r e g = L + λ 2 ∥ θ ∥ 1 {L}_{\mathrm{reg}} = {L} + \frac{\lambda}{2} \left\| \theta \right\|_{1} Lreg=L+2λ∥θ∥1
实例
平均交叉熵损失:
L = 1 m ∑ i = 1 m L i = − 1 m ∑ i = 1 m y i T ⋅ log [ S ( f θ ( x i ) ) ] \begin{aligned} {L} = & \frac{1}{m} \sum_{i = 1}^{m} {L}_i = - \frac{1}{m} \sum_{i = 1}^{m} \mathbf{y}_i^T \cdot \log \left[ S \left( f_{\theta} (\mathbf{x}_i) \right) \right] \\ \end{aligned} L=m1i=1∑mLi=−m1i=1∑myiT⋅log[S(fθ(xi))]
平均方差损失:
L = 1 m ∑ i = 1 m L i = 1 m ∑ i = 1 m 1 2 ∥ y i − y ^ i ∥ 2 \begin{aligned} {L} = & \frac{1}{m} \sum_{i = 1}^{m} {L}_i = \frac{1}{m} \sum_{i = 1}^{m} \frac{1}{2} \left\| \mathbf{y}_i - \hat{\mathbf{y}}_i \right\|^{2} \end{aligned} L=m1i=1∑mLi=m1i=1∑m21∥yi−y^i∥2
例1:
| 网络输出(Softmax) | 真实输出 | 是否正确 |
|---|---|---|
| 0.3, 0.3, 0.4 | 0 0 1 | 是 |
| 0.3, 0.4, 0.3 | 0 1 0 | 是 |
| 0.1, 0.2, 0.7 | 1 0 0 | 否 |
y_hat = np.array(
[[0.3, 0.3, 0.4],
[0.3, 0.4, 0.3],
[0.1, 0.2, 0.7]])
y = np.array(
[[0, 0, 1],
[0, 1, 0],
[1, 0, 0]])
avg_classification_acc = np.array([np.argmax(y[idx]) == np.argmax(y_hat[idx]) for idx in range(3)]).sum() / 3
avg_cross_entropy_loss = -1 * np.array([np.dot(y[idx], np.log(y_hat[idx])) for idx in range(3)]).sum() / 3
avg_square_error_loss = np.array([np.dot(y[idx] - y_hat[idx], y[idx] - y_hat[idx]) for idx in range(3)]).sum() / 3
print("average classification accuracy: {}".format(avg_classification_acc))
print("average cross entropy loss: {}".format(avg_cross_entropy_loss))
print("average square error loss: {}".format(avg_square_error_loss))
average classification accuracy: 0.6666666666666666
average cross entropy loss: 1.3783888522474517
average square error loss: 0.8066666666666666
例2:
| 网络输出(Softmax) | 真实输出 | 是否正确 |
|---|---|---|
| 0.1, 0.2, 0.7 | 0 0 1 | 是 |
| 0.1, 0.7, 0.2 | 0 1 0 | 是 |
| 0.3, 0.4, 0.3 | 1 0 0 | 否 |
y_hat = np.array(
[[0.1, 0.2, 0.7],
[0.1, 0.7, 0.2],
[0.3, 0.4, 0.3]])
y = np.array(
[[0, 0, 1],
[0, 1, 0],
[1, 0, 0]])
avg_classification_acc = np.array([np.argmax(y[idx]) == np.argmax(y_hat[idx]) for idx in range(3)]).sum() / 3
avg_cross_entropy_loss = -1 * np.array([np.dot(y[idx], np.log(y_hat[idx])) for idx in range(3)]).sum() / 3
avg_square_error_loss = np.array([np.dot(y[idx] - y_hat[idx], y[idx] - y_hat[idx]) for idx in range(3)]).sum() / 3
print("average classification accuracy: {}".format(avg_classification_acc))
print("average cross entropy loss: {}".format(avg_cross_entropy_loss))
print("average square error loss: {}".format(avg_square_error_loss))
average classification accuracy: 0.6666666666666666
average cross entropy loss: 0.6391075640678003
average square error loss: 0.34


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









