




在之前的一系列中,我主要对yolo-pose做了笔记。这里我打算将一种高精度的关键点检测技术学习一下。那就是HRNet网络。是我们中国科学院大学和微软亚洲研究院一起发布的。实际上HRNet 和 YOLO 系列的关键点检测(如 YOLO-Pose、YOLOv8-Pose)是两种不同的技术路线,一种是基于回归的方式,一种是基于热力图的方式。它们在设计目标、网络结构和应用场景上有显著区别。HRNet 的提出时间早于 YOLO 的关键点检测方法,且两者的侧重点完全不同。所以有必要学习一下。

首先第一步对比一下二者,让我们从yolo过度一下。
1,HRNet和Yolo-pose的对比
1.1 提出时间对比
HRNet:最初在2019年提出,专注于高分辨率特征学习,后续被广泛应用于姿态估计(如HigherHRNet)。
YOLO关键点检测:如yolo-pose是在YOLO目标检测框架上的扩展,2021年后才逐渐成熟(比如yolov7-pose, yolov8-pose, 以及现在的yolov11-pose, yolov12-pose)。
所以说HRNet的提出早于YOLO的关键点检测方法,且二者解决的问题不同。
1.2 核心区别:HRNet vs YOLO关键点检测
1.2.1 设计目标不同

YOLO-pose 正如我们之前博客提到的是联合了检测等多任务融合;并且直接输出关键点的坐标,无需后处理,适合实时应用;他与目标检测框架共享主干网络,计算开销低,适合嵌入式或移动端部署。但是其对遮挡和复杂姿态的鲁棒性较差,精度低于热力图方式。
而HRNet则是高分辨率特征保持,全程并行多分枝结构,避免下采样导致的信息丢失,精度更高,对于热力图的后处理也是通过高斯热图峰值提取关键点,对遮挡和小目标更鲁棒。但是热图生成和后处理计算复杂度高,难以满足实时性需求。
1.2.2 网络结构差异

所以说HRNet就是通过复杂的多分支结构保持高分辨率,适合高精度场景;YOLO-Pose 则是在YOLO检测框架上增加关键点预测头,牺牲部分精度换取实时性。
1.2.3 关键点检测方式

对于HRNet来说,是先生成热图,再通过argmax 或 soft-argmanx解析关键点坐标。 而yolo-pose则可以直接输出坐标(比如[x1, y1, x2, y2, ....x17, y17 ])。而无需后处理。
所以这也是两种不同的检测方式。一种就是yolo系列这种基于回归(regressing)的方式直接预测每个关键点的位置坐标;另一种就是基于热力图(heatmap)的方式,即针对每个关键点预测一张热力图(预测出现在每个位置上的分数)。精度高肯定基于heatmap这种。
1.2.4 性能对比(精度 vs 速度)

很明显,HRNet精度更高,但是计算量大;而YOLO-pose速度极快,适合实时应用,但精度稍微低一些。
所以说YOLO系列就是在2021年开始整合关键点检测功能(如 YOLOv5-Pose、YOLOv7-Pose),特别是2023年后,yolov8-pose发布后,进一步优化了实时姿态估计的精度和速度。而且yolo-pose实际上就是工程优化的产物,基于 YOLO 已有的检测框架扩展关键点功能,更注重落地效率。但是HRNet是学术驱动的创新,专注于解决关键点检测的底层问题(分辨率丢失)。二者不冲突,yolo-pose的定位就是在速度和精度之间提供一种更平衡的选择;而HRNet至今仍然是高精度关键点检测的基准模型之一。所以我觉得有必要学习一下HRNet。
下面学习一下HRNet的核心思想,架构特点以及其应用。
2. HRNet 的核心思想
在关键点检测(Keypoint Detection)任务中(比如人体姿态估计,人脸关键点检测等)。HRNet(High-Resolution Network)的提出是为了解决传统方法中因分辨率丢失导致的定位精度不足问题。它的核心意义在于始终保持高分辨率特征表达,从而显著提升关键点的定位准确性。
所以我们先说一下传统方法的缺陷:
2.1 传统方法的缺陷
2.1.1 分辨率丢失与细节破坏
-
问题:
-
传统CNN(如VGG、ResNet)通过堆叠下采样层(stride=2卷积或池化)逐步降低分辨率,导致空间细节不可逆丢失。
-
例如:输入256×256的图像,经过5次下采样后变为8×8的特征图,微小关键点(如手指关节)的定位信息几乎消失。
-
-
后果:
-
小目标或密集关键点的检测性能显著下降(COCO数据集中AP@small指标偏低)。
-
依赖上采样(如双线性插值)重建细节时,会引入模糊或伪影。
-
2.1.2 低效的信息传递机制
-
编码器-解码器结构(如U-Net、Hourglass)采用的“先降采样再升采样“的编码器-解码器结构:
-
单向信息流:高层语义特征只能通过上采样传递到低层,缺乏低层到高层的实时反馈。
-
跳跃连接局限:虽然U-Net通过跳跃连接融合深浅层特征,但融合方式简单(如通道拼接),无法实现跨分辨率的动态交互。编码器:通过池化或卷积逐步降低分辨率,提取高层语义特征。解码器:通过上采样恢复分辨率,但重建的细节存在信息损失。
-
-
后果:
-
特征融合粗糙,难以平衡细节与语义(如边缘锐利但分类错误,或语义正确但定位模糊)。小目标或密集关键点的定位精度下降(如手指关节、人脸特征点)。上采样操作(如转置卷积)无法完全还原低层细节。
-
2.1.3 语义与细节的冲突
-
传统假设:
-
低分辨率特征包含高级语义(如“人体姿态”),高分辨率特征包含低级细节(如“边缘”)。
-
-
实际缺陷:
-
下采样过程中,语义与细节被强制分离,导致模型需复杂解码器重新关联二者(如Hourglass的重复对称结构)。
-
例如:人脸关键点检测中,鼻子轮廓(细节)与头部朝向(语义)需协同建模,但传统方法需额外设计注意力机制弥补。
-
2.1.4 任务适应性差
-
固定分辨率策略:
-
大多数网络预设单一输出分辨率(如1/4输入尺寸),难以适应不同任务需求。
-
例如:语义分割需高分辨率输出,而目标检测可接受低分辨率。
-
-
后果:
-
同一网络在不同任务中需重复调整结构(如修改上采样次数),泛化性差。
-
2.1.5 计算资源浪费
-
重复计算:
-
编码器-解码器结构中,低层特征先被编码器丢弃,再被解码器重新计算(如U-Net的对称路径)。
-
-
后果:
-
显存占用高,训练效率低,尤其对大尺寸图像(如4K医学影像)。
-
2.2 HRNet的解决方案
HRNet(Hign-Resolution Net)是针对2D人体姿态估计(Human Pose Estimation任务提出的),并且该网络主要是针对单一个体的姿态评估(即输入网络的图形中应该只有一个人体目标)。在计算机视觉领域,许多任务(如目标检测、语义分割、姿态估计等)都需要精确的空间信息。传统卷积神经网络(CNN)通常采用高分辨率到低分辨率的编码-解码结构,但在下采样过程中可能会丢失重要的空间细节。HRNet(High-Resolution Network) 通过保持高分辨率特征表达,显著提升了视觉任务的性能。
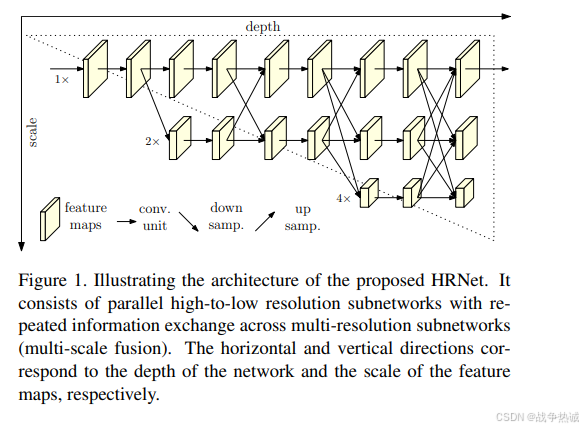
HRNet 的主要创新在于并行多分辨率子网络和跨分辨率信息融合,而不是像传统 CNN 那样逐步降低分辨率。其关键特点包括:
-
始终保持高分辨率主分支:不同于先降采样再升采样的 U-Net 或 FPN,HRNet 从始至终保持高分辨率特征图(如1/4尺度)。
-
低分辨率辅助分支:通过下采样生成多尺度特征(如1/8、1/16、1/32),补充全局上下文。
-
跨分辨率交互(多尺度特征融合):不同分支间通过双向融合交换信息(高分辨率→低分辨率传递细节,低分辨率→高分辨率补充语义)。通过并行连接不同分辨率)的子网络,并在不同阶段进行信息交换,增强模型的表达能力。
-
适用于密集预测任务:由于保留了丰富的空间信息,HRNet 在姿态估计、语义分割等任务上表现优异。
2.3 HRNet的主要创新点
HRNet 的架构可以分为以下几个部分:
1 并行多分辨率分支
-
高分辨率主分支:始终维持输入图像的高分辨率(如原始尺寸的 1/4)。
-
低分辨率分支:通过 stride=2 的卷积逐步新增低分辨率特征图(如 1/8、1/16、1/32)。
对于传统网络,他们只是串行下采样,分辨率逐步降低。而HRNet并行维持多个分辨率分支,避免高分辨率信息被丢失。例如:输入为256×256时,四分支分辨率分别为64×64(主分支)、32×32、16×16、8×8。
2 跨分辨率信息交换
HRNet 的关键在于不同分辨率分支之间的重复双向融合,例如:
-
高分辨率 → 低分辨率:通过下采样(如池化或卷积)传递信息。
-
低分辨率 → 高分辨率:通过上采样(如转置卷积或插值)恢复细节。
-
融合操作:逐元素相加或通道拼接
这种设计使得高分辨率特征既包含局部细节,又整合了低分辨率的全局上下文信息。不同于FPN(单向自上而下),HRNet在每个阶段都进行跨分辨率交互。例如:1/4分支不仅接收自身前一层的特征,而且融合1/8, 1/16分支的上采样结果。
3 高分辨率特征主导及其灵活的扩展性
-
关键点检测:直接在高分辨率热图上预测,无需后处理上采样。
-
语义分割:输出与输入同分辨率的特征图(如Cityscapes任务中1024×2048)。
-
变体设计:
-
HRNetV1:仅输出高分辨率特征。
-
HRNetV2:聚合多分辨率特征(适用于分割任务)。
-
HRNetV2p:添加金字塔池化模块(进一步提升全局上下文)。
-
-
轻量化改进:Lite-HRNet通过通道 shuffle 和分组卷积降低计算量。
传统方法是低分辨率特征主导预测(如ResNet最终层位=为1/32尺度),HRNet最终输出仍以高分辨率分支为主,仅利用低分辨率分支辅助增强语义。
3. HRNet的网络架构
说了一堆了,终于聊到正文了。
官网代码地址是:https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
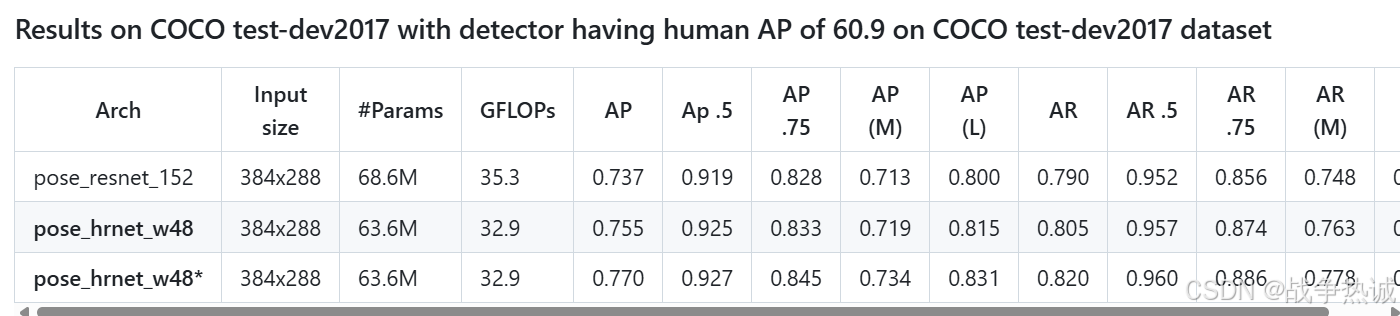
HRNet有两个主干架构,一个是HRNet-W32,另一个是HRNet-W48。二者的区别就是每个模块中所采用的通道个数不同。网络的整体结构都是一样的,而论文的核心思想就是不断地融合不同尺度上的信息,也就是论文中的Exchange Blocks。
先看简化版的架构图(以HRNetv1为例):

其代码的forward如下:

首先是stem层(入口层):快速降低计算量,同时保留足够信息;结构是两个步长为2的3*3卷积(输入-> 1/4 分辨率);例如输入256*256;那么经过卷积后,则输出64*64。
下面是Layer1的代码:
self.layer1 = self._make_layer(Bottleneck, 64, 4)其实现如下:
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(
self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False
),
nn.BatchNorm2d(planes * block.expansion, momentum=BN_MOMENTUM),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)如果你运行,则大致如下:
# Stage1
downsample = nn.Sequential(
nn.Conv2d(64, 256, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(256, momentum=BN_MOMENTUM)
)
self.layer1 = nn.Sequential(
Bottleneck(64, 64, downsample=downsample),
Bottleneck(256, 64),
Bottleneck(256, 64),
Bottleneck(256, 64)
)
其次是并行多分辨率分支,每个stage新增一个更低分辨率分支,通过卷积下采样实现:
-
Stage 1:仅1个分支(1/4尺度,64×64)。
-
Stage 2:新增1/8分支(32×32),原1/4分支保留。
-
Stage 3:新增1/16分支(16×16),保留前两个分支。
-
Stage 4:新增1/32分支(8×8),共四个并行分支。
其具体参数示例:
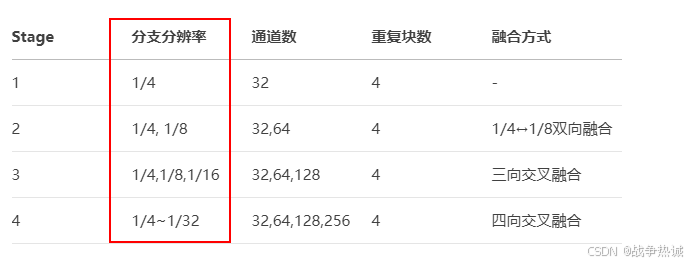
他与传统的网络结构差异如下:
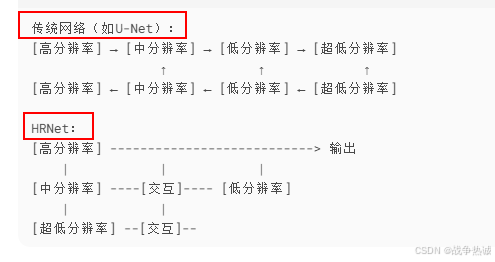
对于从高分辨率到中分辨率交互,在每个stage的起始处都会通过下采样生成更低分辨率的并行分支。比如说Transition1,他在layer1的输出基础上通过并行两个卷积核大小为3*3的卷积层得到两个不同的尺度分支,即下采样4倍的尺度以及下采样8倍的尺度。在Transition2中在原来的两个尺度分支基础上再新加一个下采样16倍的尺度,注意这里是直接在下采样8倍的尺度基础上通过一个卷积核大小为3*3步距为2的卷积层得到下采样16倍的尺度。
以Stage1(单分支)——》stage2(双分支)的transition为例。
输入为stage1输出的高分辨率特征图(如1/4尺度,通道数C=32)。操作:保持原分支,高分辨率分支直接进入下一stage(不处理)。新增低分辨率分支:通过步长为2的3*3卷积下采样(1/4 → 1/8分辨率)后接1*1卷积调整通道数,输出:两个并行分支(1/4尺度-C=32,1/8尺度-C=64)。
示例代码:
class Transition(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
# 新增低分辨率分支的卷积层
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=1) # 通道调整
def forward(self, x):
# 原分支直接保留(高分辨率)
x_high = x
# 新分支:下采样+通道调整
x_low = F.relu(self.conv2(F.relu(self.conv1(x))))
return [x_high, x_low] # 返回多分支列表stage阶段。其作用是多分辨率特征提取:每个Stage包含多个并行分支,分别处理不同分辨率特征。跨分辨率融合:通过双向交互模块交换不同分支的信息。以stage2(双分支)为例:
-
输入:Transition输出的多分支特征(如[1/4尺度, 1/8尺度])。
-
分支处理:
-
每个分支由 多个Bottleneck块(或BasicBlock)堆叠而成,独立提取特征。
-
例如:
-
高分辨率分支:4个Bottleneck(输入输出均为1/4尺度)。
-
低分辨率分支:4个Bottleneck(输入输出均为1/8尺度)。
-
-
-
跨分辨率融合:
-
高→低分辨率:高分辨率特征通过步长=2卷积降采样,与低分辨率分支相加。
-
低→高分辨率:低分辨率特征通过双线性上采样,与高分辨率分支相加。
-
代码示例:
class Stage(nn.Module):
def __init__(self, channels_list, num_blocks):
super().__init__()
# 每个分支的卷积块(例如Bottleneck)
self.high_branch = nn.Sequential(*[Bottleneck(channels_list[0]) for _ in range(num_blocks)])
self.low_branch = nn.Sequential(*[Bottleneck(channels_list[1]) for _ in range(num_blocks)])
# 跨分辨率融合模块
self.fusion = FusionModule(high_ch=channels_list[0], low_ch=channels_list[1])
def forward(self, x_list):
x_high, x_low = x_list
# 各分支独立处理
x_high = self.high_branch(x_high)
x_low = self.low_branch(x_low)
# 双向融合
x_high, x_low = self.fusion(x_high, x_low)
return [x_high, x_low]还有就是fusion模块,即融合模块。核心操作就是高到低分辨率融合:高分辨率特征图 → 步长=2的3×3卷积 → 与低分辨率分支相加。低到高分辨率融合:低分辨率特征图 → 双线性上采样 → 1×1卷积(对齐通道)→ 与高分辨率分支相加。
代码实现:
class FusionModule(nn.Module):
def __init__(self, high_ch, low_ch):
super().__init__()
# 高→低分辨率融合路径
self.high_to_low = nn.Sequential(
nn.Conv2d(high_ch, low_ch, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(low_ch)
)
# 低→高分辨率融合路径
self.low_to_high = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear'),
nn.Conv2d(low_ch, high_ch, kernel_size=1),
nn.BatchNorm2d(high_ch)
)
def forward(self, x_high, x_low):
# 高→低融合
fused_low = x_low + self.high_to_low(x_high)
# 低→高融合
fused_high = x_high + self.low_to_high(x_low)
return fused_high, fused_low下面展示完整的HRNet的结构流程示例,以HRNet-W32(4个Stages)为例:

4,HRNet预测结果的流程
在HRNet中,将输出的热力图(Heatmap)转换为关键点坐标是一个关键的后处理步骤,其核心是通过热力图峰值提取或概率统计方法确定关键点的精确位置。以下是详细的转换流程及代码实现:
4.1 热力图生成原理
-
网络输出:HRNet的最后一层通过1×1卷积输出一个
K×H×W的张量,其中:-
K:关键点数量(如人体姿态估计中通常为17个关键点)。 -
H×W:热力图的分辨率(如输入图像的1/4大小,64×64)。
-
-
热力图含义:每个通道是一个高斯分布矩阵,峰值(最高值)位置对应关键点的预测坐标。
4.2 热力图到坐标的转换方法
(1) Argmax(硬峰值提取)
-
步骤:
-
对每个关键点的热力图通道,找到值最大的像素位置。
-
将该像素的坐标
(x, y)作为关键点预测坐标。
-
-
公式:
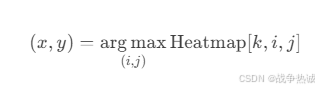
- 代码实现:
import torch
def heatmap_to_coord(heatmap):
"""
heatmap: Tensor of shape [K, H, W]
Returns: Coordinates [K, 2] (x, y)
"""
K, H, W = heatmap.shape
coords = torch.zeros(K, 2)
for k in range(K):
# 找到热力图中最大值的位置
max_idx = heatmap[k].argmax()
y = max_idx // W # 行坐标
x = max_idx % W # 列坐标
coords[k] = torch.tensor([x, y])
return coords # 坐标是整数像素位置但是其也有缺点:
-
只能输出整数坐标,精度受限(如64×64热图的最小误差为±0.5像素)。
-
对噪声敏感(若热力图存在多个局部峰值,可能选错位置)。
(2) Soft-Argmax(软峰值提取)
-
原理:通过加权平均计算热力图的“概率中心”,得到亚像素级坐标。
-
公式:
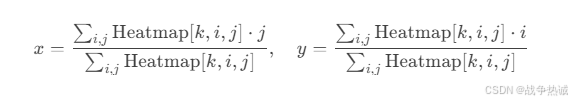
- 代码实现:
def soft_argmax(heatmap):
"""
heatmap: Tensor of shape [K, H, W]
Returns: Coordinates [K, 2] (x, y) in continuous space
"""
K, H, W = heatmap.shape
device = heatmap.device
# 生成网格坐标(i,j)
j = torch.arange(W, dtype=torch.float32, device=device).view(1, 1, -1) # [1,1,W]
i = torch.arange(H, dtype=torch.float32, device=device).view(1, -1, 1) # [1,H,1]
# 计算加权平均
x = (heatmap * j).sum(dim=(1,2)) / heatmap.sum(dim=(1,2)) # [K]
y = (heatmap * i).sum(dim=(1,2)) / heatmap.sum(dim=(1,2)) # [K]
return torch.stack([x, y], dim=1) # [K, 2]其优点:
-
输出浮点数坐标,精度更高(如可输出(120.3, 80.7))。
-
对噪声鲁棒性强(利用全局信息而非单个峰值)。
(3) 高斯拟合(更高精度)
-
步骤:
-
先用
argmax找到粗略峰值位置。 -
在峰值附近局部区域拟合二维高斯函数,求解其中心作为精确坐标。
-
-
适用场景:需要亚像素级精度的任务(如医疗图像分析)。
-
代码示例:
from scipy.optimize import minimize
def gaussian_fit(heatmap_patch):
"""
拟合局部热力图区域的高斯函数,返回中心坐标
"""
H, W = heatmap_patch.shape
x = np.arange(W)
y = np.arange(H)
xx, yy = np.meshgrid(x, y)
# 定义高斯函数
def gauss(params):
x0, y0, sigma = params
z = np.exp(-((xx-x0)**2 + (yy-y0)**2) / (2*sigma**2))
return np.sum((heatmap_patch - z)**2)
# 初始猜测(局部最大值)
x0, y0 = np.unravel_index(heatmap_patch.argmax(), heatmap_patch.shape)
res = minimize(gauss, [x0, y0, 1.0], method='L-BFGS-B')
return res.x[0], res.x[1] # 拟合后的中心坐标4.3 后处理细节
(1) 热力图缩放至原图坐标
-
HRNet输出的热力图分辨率通常为输入的1/4(如输入256×256 → 热力图64×64)。
-
需将坐标映射回原图:
def scale_coords(coords, heatmap_size, image_size):
"""
coords: [K, 2] (x, y) in heatmap space
Returns: [K, 2] in original image space
"""
scale_x = image_size[0] / heatmap_size[1]
scale_y = image_size[1] / heatmap_size[0]
return coords * torch.tensor([scale_x, scale_y])(2) 关键点置信度
-
热力图的最大值可作为关键点的置信度分数:
confidences = heatmap.max(dim=1)[0].max(dim=1)[0] # [K]HRNet通过热力图输出关键点概率分布,再通过Soft-Argmax(默认)或Argmax将其转换为坐标。这一设计平衡了精度与效率,使其成为姿态估计任务的标杆方法。若需更高精度,可结合高斯拟合或改进热力图生成方式(如基于PCA的分布建模)。



















 2386
2386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











