




上文我们提到Loss 计算方面采用了 TaskAlignedAssigner 正样本分配策略,然而这个策略内容并没有细讲。这里展开学习一下。
TaskAlignedAssigner 又称为对齐分类器,在YOLOv8中是一种动态的正样本分配策略。主要用于解决目标检测中正样本分配的优化问题。其匹配策略简单来说就是:根据所有像素点预测的分类与回归的分数通过加权的方式得到的分数选择正样本。
1 TaskAlignedAssigner原理
以下是其核心策略的详细说明:
1,计算真实框和预测框的匹配程度
TaskAlignedAssigner的核心思想是将分类分数和回归分数(如CIOU)结合起来,通过加权的方式衡量预测框与真实框的匹配程度。具体来说,使用下面公式来计算匹配度:
![]()
其中,s是预测类别分值(分类得分), u是预测框和真实框的ciou值。 alpha和beta为权重超参数(alpha=0.5, beta=6.0),两者相乘就可以衡量匹配程度,当分类的分值越高且 ciou 越高时, align_meter的值就越接近于1,此时预测框就与真实框越匹配,就越符合正样本的标准。
tal.py的参考代码如下:
2,对于每个真实框,直接对 align_metric 匹配程度排序,选取 topK个预测框作为正样本
一个简单的分配规则来选择训练样本:对于每个GT实例,我们选择 m 个具有最大 t值的锚点作为正样本,而将剩余的锚点作为负样本。
3,对一个预测框与多个真实框匹配的情况进行处理,保留 ciou值最大的真实框。
前期处理的代码:
self.cuda = True if inputs[0].is_cuda else False
self.FloatTensor = torch.cuda.FloatTensor if self.cuda else torch.FloatTensor
self.LongTensor = torch.cuda.LongTensor if self.cuda else torch.LongTensor
# ---------- 预测结果预处理 ---------- #
# 将多尺度输出整合为一个Tensor,便于整体进展矩阵运算
pred_scores,pred_regs,strides = self.pred_process(inputs)
# --------- 生成anchors锚点 ---------#
# 各尺度特征图每个位置一个锚点Anchors(与yolov5中的anchors不同,此处不是先验框)
# 表示每个像素点只有一个预测结果
self.anc_points,self.stride_scales = self.make_anchors(strides)
# ------------- 解码 ------------- #
# 预测回归结果解码到bbox xmin,ymin,xmax,ymax格式
pred_bboxes = self.decode(pred_regs)
# ---------- 标注数据预处理 ----------- #
gt_bboxes,gt_labels,gt_mask = self.ann_process(annotations)预测结果解码
对于网络输出的 box 信息,实际上表示的是相对于每个像素点上不同的 anchor 的偏移值(左上角或右下角相对于中心点的距离)
1,预测数据预处理
# ---------- 预测结果预处理 ---------- #
# 将多尺度输出整合为一个Tensor,便于整体进展矩阵运算
pred_scores,pred_regs,strides = self.pred_process(inputs)
def pred_process(self,inputs):
'''
L = class_num + 4*self.reg_max = class_num + 64
多尺度结果bxLx80x80,bxLx40x40,bxLx20x20,整合到一起为 b x 8400 x L
按照cls 与 box 拆分为 b x 8400 x 2 , b x 8400 x 64
'''
predictions = [] # 记录每个尺度的转换结果
strides = [] # 记录每个尺度的缩放倍数
for input in inputs:
self.bs,cs,in_h,in_w = input.shape
# 计算该尺度特征图相对于网络输入的缩放倍数
stride = self.input_h // in_h
strides.append(stride)
# shape 转换 如 b x 80 x 80 x (64+cls_num) -> b x 6400 x (64+cls_num)
prediction = input.view(self.bs,4*self.reg_max+self.class_num,-1).permute(0,2,1).contiguous()
predictions.append(prediction)
# b x (6400+1600+400)x (cls_num+64) = b x 8400 x (64+cls_num) = b x 8400 x 66
predictions = torch.cat(predictions,dim=1)
# 按照cls 与 reg 进行拆分
# b x 8400 x cls_num = b x 8400 x 2
pred_scores = predictions[...,4*self.reg_max:]
# b x 8400 x 64
pred_regs = predictions[...,:4*self.reg_max]
return pred_scores,pred_regs,strides
2,生成所有 anchor 锚点的中心坐标和缩放尺度
# --------- 生成anchors锚点 ---------#
# 各尺度特征图每个位置一个锚点Anchors(与yolov5中的anchors不同,此处不是先验框)
# 表示每个像素点只有一个预测结果
self.anc_points,self.stride_scales = self.make_anchors(strides)3,预测结果解码
# ------------- 解码 ------------- #
# 预测回归结果解码到bbox xmin,ymin,xmax,ymax格式
pred_bboxes = self.decode(pred_regs)此时,reg_max=16,通过16个值,结合softmax对box的四个预测值实现离散回归。最后通过积分的方式,得到最终结果。
def decode(self,pred_regs):
'''
预测结果解码
1. 对bbox预测回归的分布进行积分
2. 结合anc_points,得到所有8400个像素点的预测结果
'''
if self.use_dfl:
b,a,c = pred_regs.shape # b x 8400 x 64
# 分布通过 softmax 进行离散化处理
# 分布通过 softmax 进行离散化处理
# b x 8400 x 64 -> b x 8400 x 4 x 16 -> softmax处理
# l,t,r,b其中每个坐标值对应16个位置(0-15)的概率值
# 概率表示每个位置对于最终坐标值的重要程度
pred_regs = pred_regs.view(b,a,4,c//4).softmax(3)
# 积分,相当于对16个分布值进行加权求和,最终的结果是所有位置的加权求和
# b x 8400 x 4
pred_regs = pred_regs.matmul(self.proj.type(self.FloatTensor))
# 此时的regs,shape-> bx8400x4,其中4表示 anc_point中心点分别距离预测box的左上边与右下边的距离
lt = pred_regs[...,:2]
rb = pred_regs[...,2:]
# xmin ymin
x1y1 = self.anc_points - lt
# xmax ymax
x2y2 = self.anc_points + rb
# b x 8400 x 4
pred_bboxes = torch.cat([x1y1,x2y2],dim=-1)
return pred_bboxes积分之后得到的 preg_regs,最后维度的四个值用 left_regs, top_regs, right_regs, bottom_regs表示则他们分别在特征图(80*80, 40*40, 20*20)每个像素点上, anchor points 中心点距离预测框左侧,上侧,右侧,下侧的距离。

这部分的参考地址:YOLOv8-训练流程-正负样本分配 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/633094573
https://zhuanlan.zhihu.com/p/633094573
2 TaskAlignedAssigner 代码详解
yolov8基于TaskAlignedAssigner分配策略实现正样本的匹配。我们依然从代码进行分析。直接进入V8PoseLoss函数的前向传播中。
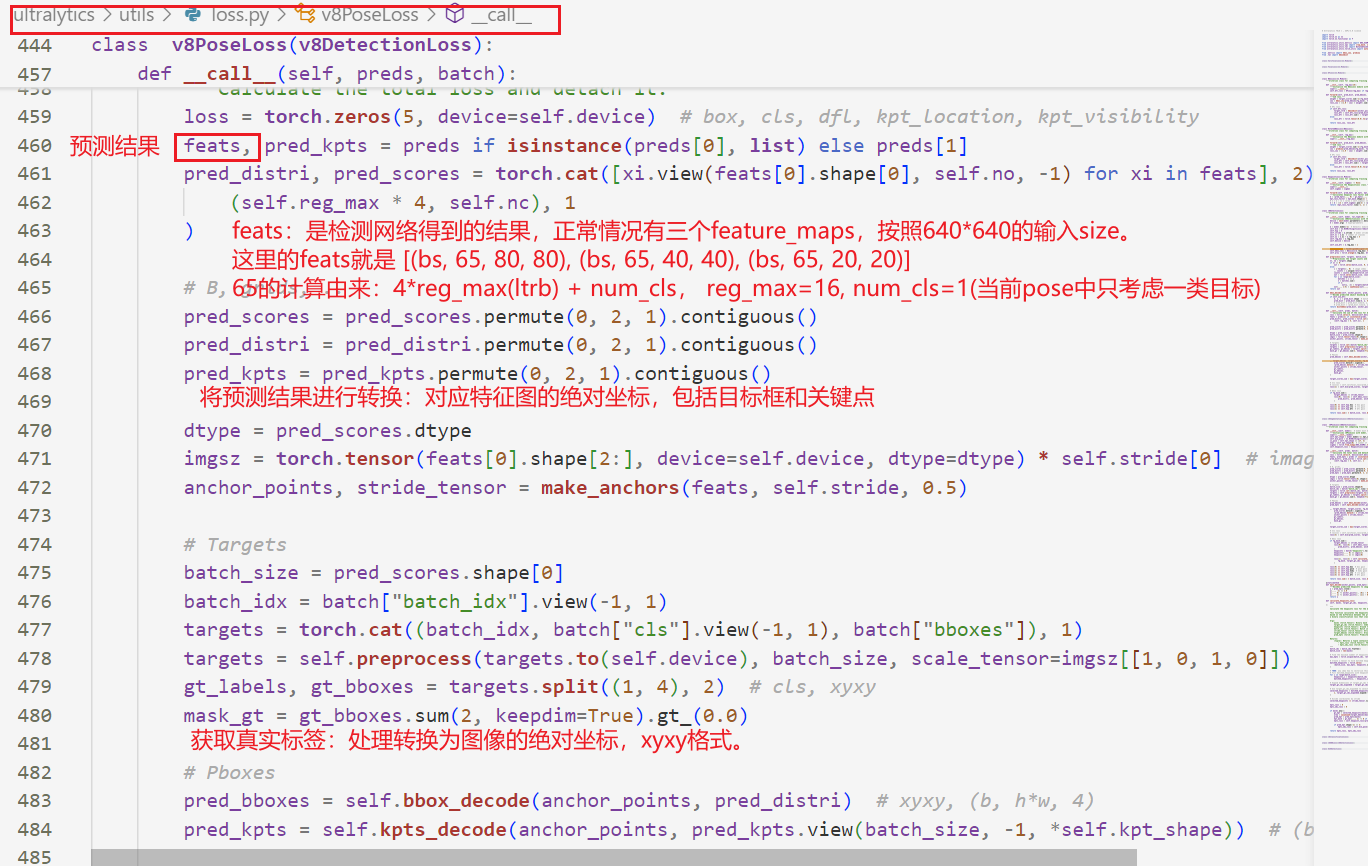
然后我们进入yolo-pose代码里面。
首先进入代码中,它在utils里面的tal.py文件里面。我们可以看到其输入参数如下:
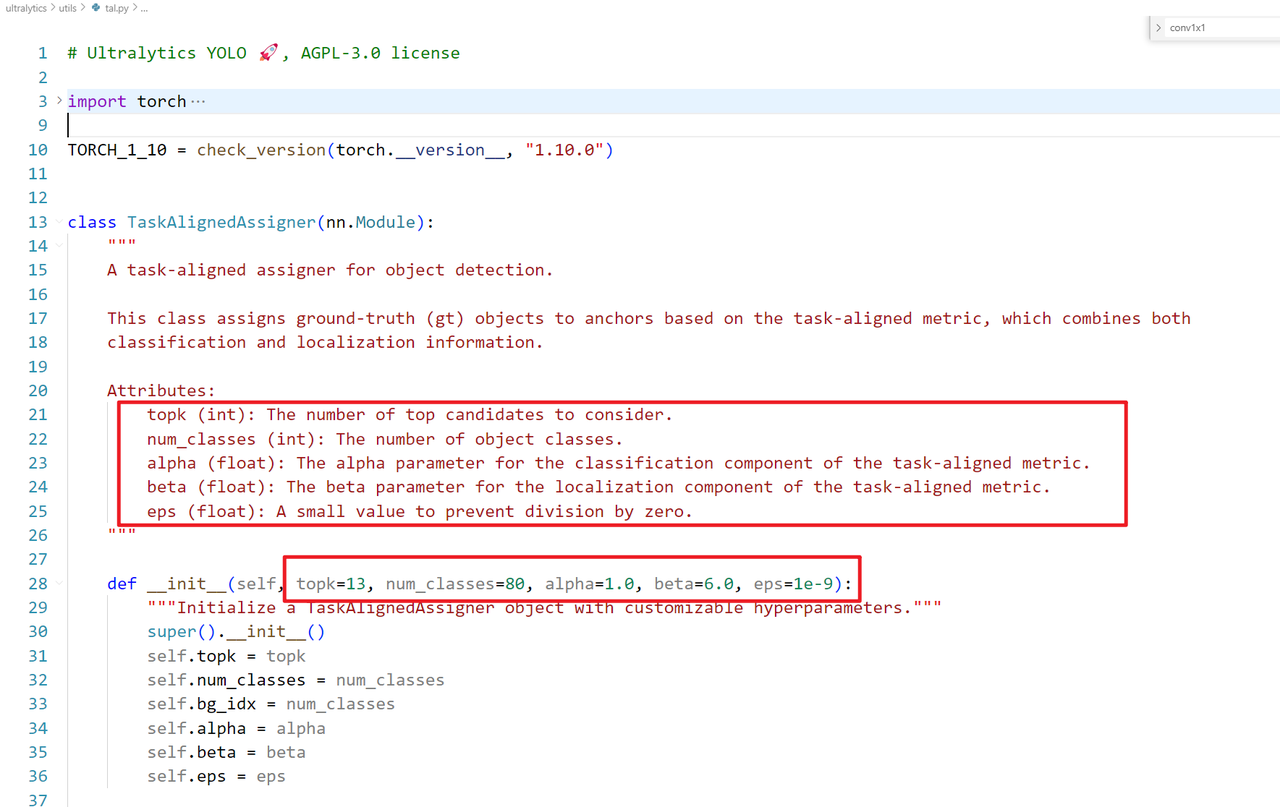
从代码中可以看到,TaskAlignedAssigner这个类的输入就是 topk,num_classes(类别数目),alpha和beta就是分类和bbox的权重超参数。
属性包括:
-
topk: 要考虑的前k个候选者数量。 -
num_classes: 对象类别的数量。 -
bg_idx: 背景索引(通常是类别的总数)。 -
alpha和beta: 任务对齐指标的超参数,分别用于分类和定位。 -
eps: 防止除以零的小值。
我们先整体看看其情况,它包含了主要的前向传播方法forward和其他辅助方法。

前向传播方法 (forward)
-
计算任务对齐分配,包括处理输入张量(预测分数、预测边界框、锚点、真实标签和边界框、mask等)。
-
如果没有真实边界框,将返回相应的零张量。
-
计算正样本的掩码、对齐指标和重叠。
-
根据最大重叠选择目标。
-
归一化对齐指标,并计算目标标签、目标边界框和目标分数。
辅助方法
-
get_pos_mask: 获取正样本掩码和对齐指标。 -
get_box_metrics: 计算对齐指标。 -
iou_calculation: 计算IoU。 -
select_topk_candidates: 选择前k个候选者。 -
get_targets: 计算目标标签、边界框和分数。 -
select_candidates_in_gts: 选择正锚框。 -
select_highest_overlaps: 选择重叠最大的锚框。
下面我们一一解析一下。
1,get_pose_mask函数
这个函数用来为物体检测模型生成一个正样本掩码。目的是通过一系列的筛选条件,将某些候选框(anchor)与目标框(ground truth boxes)进行匹配,最终确定哪些候选框(anchor)可以被视为正样本(positive samples),用于进一步计算损失。
代码如下:
def get_pos_mask(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points, mask_gt):
"""Get in_gts mask, (b, max_num_obj, h*w)."""
mask_in_gts = self.select_candidates_in_gts(anc_points, gt_bboxes)
# Get anchor_align metric, (b, max_num_obj, h*w)
align_metric, overlaps = self.get_box_metrics(pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_in_gts * mask_gt)
# Get topk_metric mask, (b, max_num_obj, h*w)
mask_topk = self.select_topk_candidates(align_metric, topk_mask=mask_gt.expand(-1, -1, self.topk).bool())
# Merge all mask to a final mask, (b, max_num_obj, h*w)
mask_pos = mask_topk * mask_in_gts * mask_gt
return mask_pos, align_metric, overlaps输入参数为:
pd_scores:预测的分数(每个候选框对应的类别分数)。
pd_bboxes:预测的边界框(每个候选框的坐标)。
gt_labels:真实目标的标签(ground truth labels)。
gt_bboxes:真实目标的边界框(ground truth boxes)。
anc_points:anchor points,候选框的锚点位置。
mask_gt:用于标记哪些 gt_bboxes 是有效的。
get_pos_mask 函数的作用是生成正样本掩码(mask_pos),它最终会返回三个结果:
mask_pos:表示哪些候选框是正样本的掩码。
align_metric:表示候选框和真实目标之间的一种匹配度指标(alignment metric)。
overlaps:表示候选框和真实目标的重叠度(比如 IoU 值)
代码整体流程的理解
-
首先,通过
select_candidates_in_gts函数找到候选框中哪些锚点位于 ground truth 边界框内,生成掩码mask_in_gts。 -
然后,使用
get_box_metrics函数计算每个候选框的匹配度和重叠度。这里的align_metric可以用于后续的筛选,overlaps则表示 IoU 或其他重叠度信息。 -
接着,使用
select_topk_candidates函数根据匹配度align_metric选择前topk个候选框,并生成相应的掩码mask_topk。 -
最后,结合
mask_in_gts和mask_topk,最终得到mask_pos,这表示哪些候选框会作为正样本参与到后续的训练或计算中。
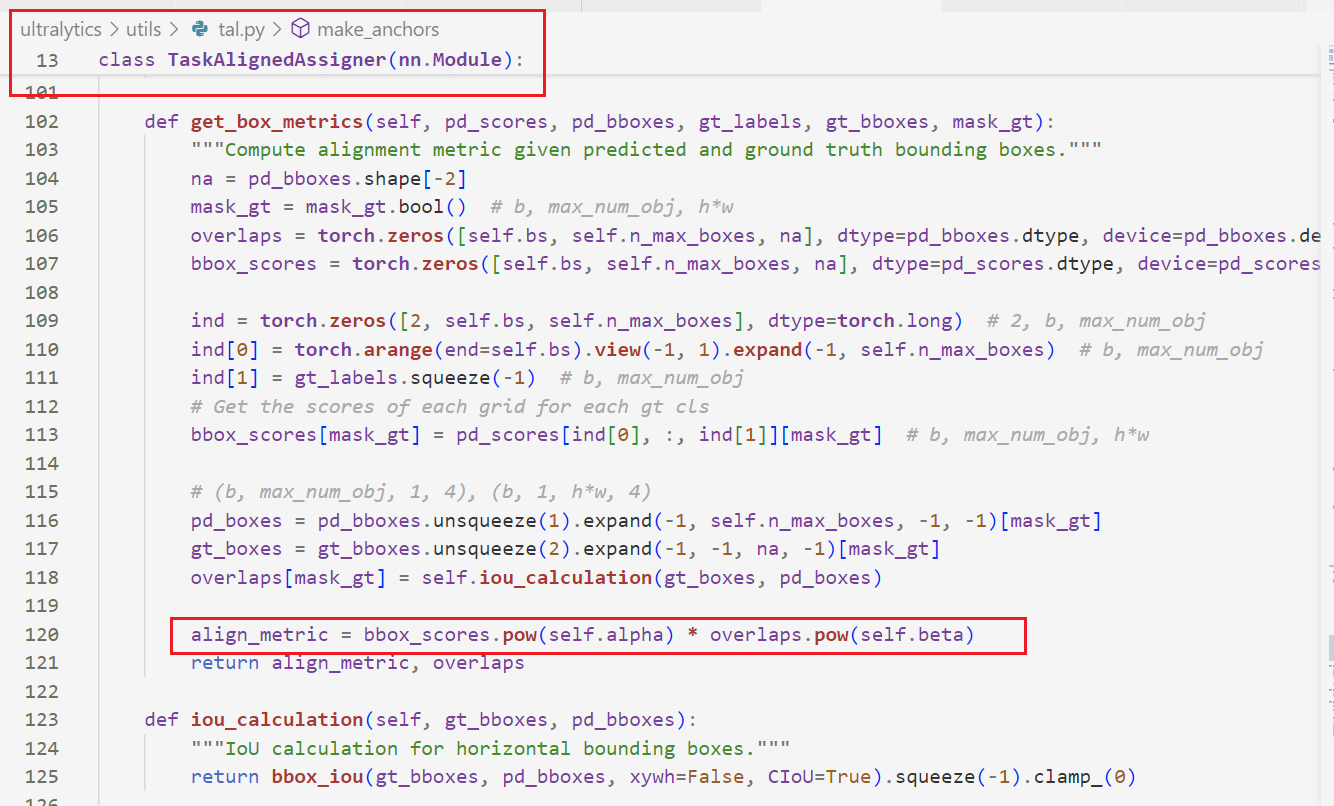
2,get_box_metrics函数
此函数用于计算预测边界框(bounding boxes)与真实标注框(ground truth)之间的对齐指标,结合了分类得分和狂的位置重合度(IOU),用于yolo中的候选框筛选和损失计算。
代码如下:
def get_box_metrics(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_gt):
"""Compute alignment metric given predicted and ground truth bounding boxes."""
na = pd_bboxes.shape[-2]
mask_gt = mask_gt.bool() # b, max_num_obj, h*w
overlaps = torch.zeros([self.bs, self.n_max_boxes, na], dtype=pd_bboxes.dtype, device=pd_bboxes.device)
bbox_scores = torch.zeros([self.bs, self.n_max_boxes, na], dtype=pd_scores.dtype, device=pd_scores.device)
ind = torch.zeros([2, self.bs, self.n_max_boxes], dtype=torch.long) # 2, b, max_num_obj
ind[0] = torch.arange(end=self.bs).view(-1, 1).expand(-1, self.n_max_boxes) # b, max_num_obj
ind[1] = gt_labels.squeeze(-1) # b, max_num_obj
# Get the scores of each grid for each gt cls
bbox_scores[mask_gt] = pd_scores[ind[0], :, ind[1]][mask_gt] # b, max_num_obj, h*w
# (b, max_num_obj, 1, 4), (b, 1, h*w, 4)
pd_boxes = pd_bboxes.unsqueeze(1).expand(-1, self.n_max_boxes, -1, -1)[mask_gt]
gt_boxes = gt_bboxes.unsqueeze(2).expand(-1, -1, na, -1)[mask_gt]
overlaps[mask_gt] = self.iou_calculation(gt_boxes, pd_boxes)
align_metric = bbox_scores.pow(self.alpha) * overlaps.pow(self.beta)
return align_metric, overlaps输入参数:
-
pd_scores:模型预测的类别得分,形状为[batch_size, num_anchors, num_classes] -
pd_bboxes:模型预测的边界框坐标,形状为[batch_size, num_anchors, 4](格式通常是[x_center, y_center, width, height]) -
gt_labels:真实标注的类别标签,形状为[batch_size, max_num_objects, 1] -
gt_bboxes:真实标注的边界框坐标,形状同pd_bboxes -
mask_gt:布尔掩码,标记哪些标注框是有效的(非填充),形状为[batch_size, max_num_objects, h*w]
函数核心步骤:
1,初始化张量:overlaps:存储预测框与真实框之间的IOU值,初始全为0. bbox_scores:存储每个预测框对应真实类别的分数得分,初始为全零。
2,提取对应类别的预测得分:通过ind索引,从pd_scores中筛选出与gt_labels类别一致的分值,仅保留mask_gt为True的位置。
3,计算IOU(交并比):将预测框与真实框调整为相同维度,调用iou_calculation方法计算他们的重合度,结果存入overlaps。
4,生成对齐指标(align_metric)
3,iou_calcluation函数
这个函数用于计算预测边界框(predicted bboxes)与真实边界框(ground truth bboxes)之间的交并比,并支持CIOU 的计算方式。
下面是代码:
def iou_calculation(self, gt_bboxes, pd_bboxes):
"""IoU calculation for horizontal bounding boxes."""
return bbox_iou(gt_bboxes, pd_bboxes, xywh=False, CIoU=True).squeeze(-1).clamp_(0)这个就不详细说了,只是补充一下CIoU,其相对于普通iou,额外考虑中心点距离(Distance),宽高比(Aspect Ratio),重叠面积(Overlap Area)。其公式如下:
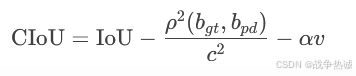
其中rho是中心点距离,c是最小外接矩形对角线长度,v是宽高比一致性权重。
4,select_topk_candidates函数
这个函数是用于从一组候选框(anchor points)中筛选出每个真实目标(ground truth object)对应的Top-K最优预测框,常用于目标检测任务中的标签分配。
其关键步骤如下:
- 1,选取top-K候选框
- 2,生成有效性掩码
- 3,过滤无效索引
- 4,统计被选中的锚点
- 5,做去重处理
代码如下:
def select_topk_candidates(self, metrics, largest=True, topk_mask=None):
"""
Select the top-k candidates based on the given metrics.
Args:
metrics (Tensor): A tensor of shape (b, max_num_obj, h*w), where b is the batch size,
max_num_obj is the maximum number of objects, and h*w represents the
total number of anchor points.
largest (bool): If True, select the largest values; otherwise, select the smallest values.
topk_mask (Tensor): An optional boolean tensor of shape (b, max_num_obj, topk), where
topk is the number of top candidates to consider. If not provided,
the top-k values are automatically computed based on the given metrics.
Returns:
(Tensor): A tensor of shape (b, max_num_obj, h*w) containing the selected top-k candidates.
"""
# (b, max_num_obj, topk)
topk_metrics, topk_idxs = torch.topk(metrics, self.topk, dim=-1, largest=largest)
if topk_mask is None:
topk_mask = (topk_metrics.max(-1, keepdim=True)[0] > self.eps).expand_as(topk_idxs)
# (b, max_num_obj, topk)
topk_idxs.masked_fill_(~topk_mask, 0)
# (b, max_num_obj, topk, h*w) -> (b, max_num_obj, h*w)
count_tensor = torch.zeros(metrics.shape, dtype=torch.int8, device=topk_idxs.device)
ones = torch.ones_like(topk_idxs[:, :, :1], dtype=torch.int8, device=topk_idxs.device)
for k in range(self.topk):
# Expand topk_idxs for each value of k and add 1 at the specified positions
count_tensor.scatter_add_(-1, topk_idxs[:, :, k : k + 1], ones)
# count_tensor.scatter_add_(-1, topk_idxs, torch.ones_like(topk_idxs, dtype=torch.int8, device=topk_idxs.device))
# Filter invalid bboxes
count_tensor.masked_fill_(count_tensor > 1, 0)
return count_tensor.to(metrics.dtype)比如说假设输入 metrics 形状为 [1, 2, 9](1张图片,2个真实目标,9个锚点),self.topk=2:
-
Step1: 对每个目标选Top-2锚点(如目标1选锚点3和5,目标2选锚点1和3)。
-
Step2: 统计锚点被选中次数:
-
锚点3被选中两次(冲突),最终会被置0。
-
-
输出:类似
[ [ [0, 1, 0, 0, 1, 0, 0, 0, 0], [1, 0, 0, 0, 0, 0, 0, 0, 0] ] ]。
5,get_targets函数
这段代码的核心功能是根据分配给 anchor 点的真实框信息,计算出用于训练的目标标签、目标边界框以及目标分数。它处理了前景 anchor 点的标签和边界框,并为每个 anchor 点生成目标分数(分类分数)。
其关键步骤如下:
- 1,计算目标索引
- 2,计算目标标签
- 3,计算目标边界框
- 4,处理目标标签中的负值
- 5,创建目标分数张量
- 6,应用前景掩码
代码如下:
def get_targets(self, gt_labels, gt_bboxes, target_gt_idx, fg_mask):
"""
Compute target labels, target bounding boxes, and target scores for the positive anchor points.
Args:
gt_labels (Tensor): Ground truth labels of shape (b, max_num_obj, 1), where b is the
batch size and max_num_obj is the maximum number of objects.
gt_bboxes (Tensor): Ground truth bounding boxes of shape (b, max_num_obj, 4).
target_gt_idx (Tensor): Indices of the assigned ground truth objects for positive
anchor points, with shape (b, h*w), where h*w is the total
number of anchor points.
fg_mask (Tensor): A boolean tensor of shape (b, h*w) indicating the positive
(foreground) anchor points.
Returns:
(Tuple[Tensor, Tensor, Tensor]): A tuple containing the following tensors:
- target_labels (Tensor): Shape (b, h*w), containing the target labels for
positive anchor points.
- target_bboxes (Tensor): Shape (b, h*w, 4), containing the target bounding boxes
for positive anchor points.
- target_scores (Tensor): Shape (b, h*w, num_classes), containing the target scores
for positive anchor points, where num_classes is the number
of object classes.
"""
# Assigned target labels, (b, 1)
batch_ind = torch.arange(end=self.bs, dtype=torch.int64, device=gt_labels.device)[..., None]
target_gt_idx = target_gt_idx + batch_ind * self.n_max_boxes # (b, h*w)
target_labels = gt_labels.long().flatten()[target_gt_idx] # (b, h*w)
# Assigned target boxes, (b, max_num_obj, 4) -> (b, h*w, 4)
target_bboxes = gt_bboxes.view(-1, gt_bboxes.shape[-1])[target_gt_idx]
# Assigned target scores
target_labels.clamp_(0)
# 10x faster than F.one_hot()
target_scores = torch.zeros(
(target_labels.shape[0], target_labels.shape[1], self.num_classes),
dtype=torch.int64,
device=target_labels.device,
) # (b, h*w, 80)
target_scores.scatter_(2, target_labels.unsqueeze(-1), 1)
fg_scores_mask = fg_mask[:, :, None].repeat(1, 1, self.num_classes) # (b, h*w, 80)
target_scores = torch.where(fg_scores_mask > 0, target_scores, 0)
return target_labels, target_bboxes, target_scores参数解释
-
gt_labels(Tensor):形状为(b, max_num_obj, 1)的张量,包含批次中的真实框标签,其中b是批次大小,max_num_obj是图像中最多的目标数量。 -
gt_bboxes(Tensor):形状为(b, max_num_obj, 4)的张量,包含真实框的坐标,坐标格式为(x1, y1, x2, y2)。 -
target_gt_idx(Tensor):形状为(b, h*w)的张量,表示每个前景 anchor 匹配到的真实框的索引。 -
fg_mask(Tensor):形状为(b, h*w)的布尔张量,表示哪些 anchor 是前景点(正样本)。
返回的三部分内容是:
-
target_labels:形状为(b, h*w)的张量,表示前景 anchor 的目标标签。 -
target_bboxes:形状为(b, h*w, 4)的张量,表示前景 anchor 的目标边界框。 -
target_scores:形状为(b, h*w, num_classes)的张量,表示每个前景 anchor 对应的类别分数,其中num_classes是类别总数。
6,select_candidates_in_gts函数
这个函数的目的是从候选点(anchor points)中选择那些落在目标边界框(ground truth bounding boxes)中的点。它根据候选点相对于边界框的位置来计算,并返回一个布尔掩码,用来标识那些候选点是在目标边界框内部的。
关键步骤:
- 1,获取候选点数量和batch大小。
- 2,切分边界框的左上角和右下角
- 3,计算候选点和边界框的相对位置
- 4,判断候选点是否在边界框内
代码如下:
def select_candidates_in_gts(xy_centers, gt_bboxes, eps=1e-9):
"""
Select the positive anchor center in gt.
Args:
xy_centers (Tensor): shape(h*w, 2)
gt_bboxes (Tensor): shape(b, n_boxes, 4)
Returns:
(Tensor): shape(b, n_boxes, h*w)
"""
n_anchors = xy_centers.shape[0]
bs, n_boxes, _ = gt_bboxes.shape
lt, rb = gt_bboxes.view(-1, 1, 4).chunk(2, 2) # left-top, right-bottom
bbox_deltas = torch.cat((xy_centers[None] - lt, rb - xy_centers[None]), dim=2).view(bs, n_boxes, n_anchors, -1)
# return (bbox_deltas.min(3)[0] > eps).to(gt_bboxes.dtype)
return bbox_deltas.amin(3).gt_(eps)参数解析
-
xy_centers (Tensor):形状为(h*w, 2),表示所有 anchor 点的中心坐标。h*w是总的 anchor 数量,2是每个点的(x, y)坐标。 -
gt_bboxes (Tensor):形状为(b, n_boxes, 4),表示每个 batch 图片中目标物体的边界框。b是 batch 大小,n_boxes是每张图片中的目标数量,4代表每个边界框的左上角和右下角坐标(x1, y1, x2, y2)。 -
eps (float):一个小值,用于数值稳定性。在这里用来确保计算中的差值大于某个很小的阈值(避免浮点数精度问题导致不正确的比较结果)。
返回值
-
返回的 Tensor 是一个布尔类型的掩码,形状为
(b, n_boxes, h*w)。它标识哪些候选点(anchor points)是落在对应的目标边界框中的。
这个函数的作用是在物体检测任务中,从候选点中选出那些位于目标边界框内部的点。其步骤可以总结为:
-
将每个候选点的坐标与目标边界框的左上角和右下角坐标计算出相对偏移量。
-
检查候选点是否同时在边界框的 4 条边之内(即距离值都大于某个小的阈值
eps)。 -
返回一个布尔掩码,表示哪些候选点位于目标边界框内部。
7,select_highest_overlaps函数
这段代码的功能是处理预测框和真实框的匹配问题。特别是针对一个预测框可能同时匹配多个真实框(ground truth,简称 gt)的情况。核心任务是选择具有 最高 IoU(Intersection over Union)的真实框,并确保每个预测框只分配给一个真实框。
关键步骤:
- 1,计算每个预测框匹配真实框的个数
- 2,处理一个预测框匹配多个真实框的情况
- 3,更新 mask_pos,选择IOU最大的真实框
- 4,重新计算前景框的掩码
- 5,确定每个候选框最终匹配的真实框索引
代码如下:
def select_highest_overlaps(mask_pos, overlaps, n_max_boxes):
"""
If an anchor box is assigned to multiple gts, the one with the highest IoU will be selected.
Args:
mask_pos (Tensor): shape(b, n_max_boxes, h*w)
overlaps (Tensor): shape(b, n_max_boxes, h*w)
Returns:
target_gt_idx (Tensor): shape(b, h*w)
fg_mask (Tensor): shape(b, h*w)
mask_pos (Tensor): shape(b, n_max_boxes, h*w)
"""
# 一个预测框匹配真实框的个数
# (b, n_max_boxes, h*w) -> (b, h*w)
fg_mask = mask_pos.sum(-2)
if fg_mask.max() > 1: # one anchor is assigned to multiple gt_bboxes 如果一个预测框匹配真实框的个数大于1
mask_multi_gts = (fg_mask.unsqueeze(1) > 1).expand(-1, n_max_boxes, -1) # (b, n_max_boxes, h*w)
max_overlaps_idx = overlaps.argmax(1) # (b, h*w)
is_max_overlaps = torch.zeros(mask_pos.shape, dtype=mask_pos.dtype, device=mask_pos.device)
is_max_overlaps.scatter_(1, max_overlaps_idx.unsqueeze(1), 1)
mask_pos = torch.where(mask_multi_gts, is_max_overlaps, mask_pos).float() # (b, n_max_boxes, h*w)
fg_mask = mask_pos.sum(-2)
# Find each grid serve which gt(index)
target_gt_idx = mask_pos.argmax(-2) # (b, h*w)
return target_gt_idx, fg_mask, mask_pos-
输入参数:
-
mask_pos (Tensor): 形状为(b, n_max_boxes, h*w),表示哪些 anchor(预测框)被分配给哪些真实框。b是批次大小,n_max_boxes是每张图像中的最大真实框数量,h*w是候选框的数量。 -
overlaps (Tensor): 形状为(b, n_max_boxes, h*w),表示每个真实框和候选框之间的 IoU(重叠度)。 -
n_max_boxes (int): 每张图像中最大真实框的数量。
-
-
返回值:
-
target_gt_idx (Tensor): 形状为(b, h*w),表示每个候选框最终匹配的真实框的索引(index)。 -
fg_mask (Tensor): 形状为(b, h*w),表示前景框(候选框是否匹配到任意一个真实框)。 -
mask_pos (Tensor): 形状为(b, n_max_boxes, h*w),更新后的匹配掩码,表示哪些预测框最终分配给哪些真实框。
-



















 4405
4405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











