




我们知道yolov8在流行的yolov5的架构上进行了扩展。在多个方面提供了改进。Loss 计算方面采用了 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss。实际上可以看出,YOLOv8 主要参考了最近提出的诸如 YOLOX、YOLOv6、YOLOv7 和 PPYOLOE 等算法的相关设计,本身的创新点不多,偏向工程实践,主推的还是 ultralytics 这个框架本身。
but anyway,我们还是学习一下这个集大成者。
前面学习了yolov8的backbone,neck和head操作。特征提取完后就需要进行loss计算了。
1,yolov8-pose loss代码总体解析
我们以关键点检测为例。来学习Yolov8中训练过程中的损失函数计算。
正常流程都是模型在训练的时候,即调用forward()时候,会调用self.loss()函数。
那么我们就首先看看模型的定义,回到代码进行check。因为我们是以keypoint detection为主。所以仍然从Pose开始学习。
首先通过PoseModel进行寻找,如下所示,PoseModel里面实际上什么也没有写,除了init_criterion()函数。

我们继续进行check,因为PoseModel 是继承了DetectionModel,而DetectionModel 也是重写了init_criterion()函数,其他也没有有用的信息。

我们继续check其基类BaseModel,在这里我们发现了猫腻,找到了我们需要的函数loss function:
我们可以看到,第一次调用self.loss()时,是通过init_criterion()初始化损失函数模块,然后使用self.forward()函数得到预测结果,最后使用self.criterion()函数来计算损失。而所谓的self.criterion()函数就等于 self.init_criterion()。因为我们所用的是Pose模型,那么PoseModel重写了 self.init_criterion()函数,也就是最初的V8PoseLoss。通过V8PoseLoss来计算损失,然后供模型训练的反向传播更新参数使用。
既然整个流程我们清楚了,那么然后去check 对应的V8PoseLoss函数。
首先我们可以从下图看到yolov8是将各类任务(图像分类,目标检测,关键点检测,实例分割,旋转目标检测)的损失函数都放在了utils/loss.py中了。

然后我们进入V8PoseLoss函数中:
class v8PoseLoss(v8DetectionLoss):
"""Criterion class for computing training losses."""
def __init__(self, model): # model must be de-paralleled
"""Initializes v8PoseLoss with model, sets keypoint variables and declares a keypoint loss instance."""
super().__init__(model)
self.kpt_shape = model.model[-1].kpt_shape
self.bce_pose = nn.BCEWithLogitsLoss()
is_pose = self.kpt_shape == [17, 3]
nkpt = self.kpt_shape[0] # number of keypoints
sigmas = torch.from_numpy(OKS_SIGMA).to(self.device) if is_pose else torch.ones(nkpt, device=self.device) / nkpt
self.keypoint_loss = KeypointLoss(sigmas=sigmas)
def __call__(self, preds, batch):
"""Calculate the total loss and detach it."""
loss = torch.zeros(5, device=self.device) # box, cls, dfl, kpt_location, kpt_visibility
feats, pred_kpts = preds if isinstance(preds[0], list) else preds[1]
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1
)
# B, grids, ..
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
pred_kpts = pred_kpts.permute(0, 2, 1).contiguous()
dtype = pred_scores.dtype
imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
# Targets
batch_size = pred_scores.shape[0]
batch_idx = batch["batch_idx"].view(-1, 1)
targets = torch.cat((batch_idx, batch["cls"].view(-1, 1), batch["bboxes"]), 1)
targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0.0)
# Pboxes
pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
pred_kpts = self.kpts_decode(anchor_points, pred_kpts.view(batch_size, -1, *self.kpt_shape)) # (b, h*w, 17, 3)
_, target_bboxes, target_scores, fg_mask, target_gt_idx = self.assigner(
pred_scores.detach().sigmoid(),
(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt,
)
target_scores_sum = max(target_scores.sum(), 1)
# Cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[3] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
# Bbox loss
if fg_mask.sum():
target_bboxes /= stride_tensor
loss[0], loss[4] = self.bbox_loss(
pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask
)
keypoints = batch["keypoints"].to(self.device).float().clone()
keypoints[..., 0] *= imgsz[1]
keypoints[..., 1] *= imgsz[0]
loss[1], loss[2] = self.calculate_keypoints_loss(
fg_mask, target_gt_idx, keypoints, batch_idx, stride_tensor, target_bboxes, pred_kpts
)
loss[0] *= self.hyp.box # box gain
loss[1] *= self.hyp.pose # pose gain
loss[2] *= self.hyp.kobj # kobj gain
loss[3] *= self.hyp.cls # cls gain
loss[4] *= self.hyp.dfl # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
我们简单梳理一下这个V8PoseLoss的类。它首先是继承V8DetectionLoss这个类。其主要用于计算姿态估计任务中的损失。包括边界框(bbox)损失,分类(cls)损失,分布焦点损失(DFL),关键点位置损失(kpt_location)和关键点可见性损失(kpt_visibility)。
其初始化方法主要是一些定义:
- 设置关键点形状:从模型中获取关键点的形状kpt_shape。
- 创建BCE损失函数:用于关键点可见性的二元交叉熵损失。
- 判断是否为姿态任务:如果kpt_shape 是[17, 3],则认为是姿态任务(注意:这个个人理解主要来来查看sigmas的,如果不存在,那么默认设置sigmas)
- 设置关键点数量:nkpt是关键点的数量
- 设置关键点损失的权重:如果是姿态任务,使用预定义的OKS_SIGMA;否则使用均匀权重(利用上面的is_pose的bool值)
- 创建关键点损失实例:使用keypointLoss类来计算关键点位置损失
而其前向传播方法,即__call__函数包括:
- 初始化损失:创建一个长度为5的张量 loss, 分别对应 box, cls, dfl, kpt_location 和 kpt_visibility的损失。
- 处理预测结果:将预测结果 preds 分解为特征图 feats 和关键点预测 pred_kpts。
- 重新排列张量:将pred_scores和pred_distri 重新排列以适应后续操作。
- 计算图像尺寸:根据特征图的大小和步长计算图像尺寸。
- 生成锚点:使用 make_anchors函数生成锚点和步长张量。
- 处理目标数据:将批处理索引,类别标签和边界框组合成目标张量,并进行预处理。
- 解码预测边界框:使用 bbox_decode 方法将预测的分布解码为边界框。
- 解码关键点:使用 kpts_decode 方法将预测的关键点解码为图像坐标。
- 分配器:使用 assigner 方法将预测与真实值匹配,得到目标边界框,目标分数,前景掩码和目标索引。
- 分类损失:计算分类损失
- 边界框损失:如果存在前景掩码,则计算边界框损失
- 关键点损失:计算关键点位置损失和关键点可见性损失
- 调整损失:根据超参数调整每种损失的权重
- 返回总损失:返回加权后的总损失和没和单独的损失。
总结一下: V8PoseLoss类主要用于计算姿态估计任务中的多种损失,包括边界框损失,分类损失,分布焦点损失,关键点位置损失和关键点可见性损失。
其整体调用流程如下:
- 初始化各种损失函数和权重
- 处理预测结果和目标数据
- 解码预测的边界框和关键点
- 使用分配器将预测与真实值匹配(这里就是标签分配,调用TaskAlignedAssigner将测值对应到GT)
- 计算各种损失(比如调用BCE计算分类损失,调用BboxLoss计算iou损失和dfl损失,调用关键点损失计算函数)
- 调整损失权重并返回总损失
这就是yolov8的损失函数,它可以有效的计算姿态估计任务中的多方面损失,从而帮助优化模型的训练过程。下面对于这些损失函数我们一一分析。
我这里就从call函数的调用,从上往下学习了。首先肯定是拿到forward得到的预测结果。然后对结果进行拆解。那么首先就通过make_anchors()这个函数生成网格点;然后对真实框进行预处理,便于和预测对齐后进行计算。接着就是解码bbox和keypoint了。然后就是正负样本分配。对处理后的结果进行分类,矩形框,关键点等损失的计算了。最后对各个损失函数乘以对应的权重再相加就是最终的损失了。
所以我们也按照这个流程来将重点函数分析一下,首先就是网格点生成函数。
2,网格点生成——make_anchors函数
yolov8是一种anchor free的机制。不像Yolov5先预设一些尺寸的anchor,而是通过assigner取对齐gt和predict的box。其anchor匹配核心在TaskAlignedAssigner类。我们是根据loss的计算过程,一个一个函数解析的。所以这里只分析mask_anchors函数。到了正负样本分配的时候,我们再继续说TaskAlignedAssigner。
而make_anchors函数,这个方法在utils/tal.py中实现:
def make_anchors(feats, strides, grid_cell_offset=0.5):
"""Generate anchors from features."""
anchor_points, stride_tensor = [], []
assert feats is not None
dtype, device = feats[0].dtype, feats[0].device
for i, stride in enumerate(strides):
_, _, h, w = feats[i].shape
sx = torch.arange(end=w, device=device, dtype=dtype) + grid_cell_offset # shift x
sy = torch.arange(end=h, device=device, dtype=dtype) + grid_cell_offset # shift y
sy, sx = torch.meshgrid(sy, sx, indexing="ij") if TORCH_1_10 else torch.meshgrid(sy, sx)
anchor_points.append(torch.stack((sx, sy), -1).view(-1, 2))
stride_tensor.append(torch.full((h * w, 1), stride, dtype=dtype, device=device))
return torch.cat(anchor_points), torch.cat(stride_tensor)
这段代码是用来从特征图生成锚点(anchor points)的。锚点在目标检测和姿态估计任务中非常重要,他们是预定义的参考点,用于帮助模型预测物体的位置。
我们解释一下这段代码。想象一下我们有一个棋盘格,每个格子代表图像中的一个位置。我们的目标是在这个棋盘格上放置一些标记点(即锚点),这些标记点将作为后续检测和姿态估计的参考点。
首先是传入的参数:
- 特征图(feats): 一个列表,包含多个特征图,这些特征图都是通过神经网络提取的,每个特征图对应不同尺度的图像。对于yolov8来说就是三个(如果是640*640的图像,那么特征图的size分别是20*20, 40*40, 80*80)。
- 步长(strides): 一个列表,包含多个步长,步长决定了特征图与原始图像的比例关系。例如步长为8意味着特征图像上一个像素对应于原始图像上的8*8的像素区域;(对于yolo-pose来说,如果不改变参数,基本的步长为8, 16, 32)。
- 网格单元的偏移量(grid_cell_offset): 一个浮点数,表示每个网格单元的偏移量,默认为 0.5。
然后就是生成锚点,对于每一个特征图:
1,获取特征图的形状:遍历输入的特征图和步长,并分别获取他们的高度、宽度和步长值。(这个也很简单,大家可以打印一下,特征图的步长为8, 那么对应的宽高为80,80;同理,步长为16, 那么宽高为40,40;步长为32,宽高为20,20)。
2,生成网格坐标:使用 PyTorch 的 arange() 函数生成一组横向和纵向的位移值,并添加一个偏移量(即 grid_cell_offset)以将锚点的中心对准每个网格单元的中心。具体来说:
sx = torch.arange(end=w, device=device, dtype=dtype) + grid_cell_offset表示生成从 0 到w-1的序列,并加上偏移量grid_cell_offset(默认为 0.5)。sy = torch.arange(end=h, device=device, dtype=dtype) + grid_cell_offset表示生成从 0 到h-1的序列,并加上偏移量grid_cell_offset。- 这个网格坐标sx, sy 基本就是按照1为步长,从0+偏移量开始。比如步长为32的时候,那么w和h就是20,对应的sx和sy都是[0.5, 1.5, 2.5, ....19.5],总共20个坐标序列。其他依次类推。
3,创建网格:使用 PyTorch 的 meshgrid() 函数生成所有可能的锚点位置,并将其保存在 anchor_points 列表中。其中,每个锚点的位置由两个坐标值表示,即 (x, y),并被转换为形状为 (n, 2) 的张量,其中 n 表示特征图上的像素点数量。对于此代码来说,sy和sx分别表示网格的行坐标和列坐标。torch.stack((sx, sy), -1) 是将sx和sy组合成一个形状为(h, w, 2)的张量,每个元素是一个 [x, y] 坐标。然后使用.vew(-1, 2)将其展平为形状为(h*w, 2)的张量,每个元素是一个 [x, y]坐标。
这里再废话一下meshgrid()函数。此函数用于从给定的一维坐标数组创建一个二维或更高维度的网格。它通常是用来生成一个可以表示图像或空间的所有点的坐标矩阵。假如我们有两个一维张量x和y。分别代表x轴和y轴上的一些点。我们可以使用此函数来创建这两个轴构成的所有点的组合。
示例如下:
a = torch.tensor([1,2])
b = torch.tensor([1,2])
res = torch.meshgrid(a, b)
print(res)
# 打印结果:
(tensor([[1, 1],
[2, 2]]), tensor([[1, 2],
[1, 2]]))
4,记录步长:在每个特征图上都需要保存相应的步长信息,以便后续计算。因此,使用 PyTorch 的 full() 函数创建一个形状为 (h*w, 1) 的张量,其中 h 和 w 分别表示特征图的高度和宽度,每个元素都被初始化为当前特征图的步长值。
5,收集结果:使用anchor_points和stride_tensor 将生成的锚点坐标和步长张量添加到对应列表中。
6,合并结果:通过将所有锚点位置和步长信息连接起来,可以得到形状为 (n*nl, 2) 和 (n*nl, 1) 的张量,其中 nl 表示特征图的数量,n 表示每个特征图上的像素点数量。这些张量将被用于计算每个锚点的位置和预测信息,并生成最终的预测结果。(沿用之前的640*640的size,那么得到的最终的锚点位置和步长信息的张量的size分别是(8400, 2)和(8400, 1)。通过这种方式,make_anchors 函数生成了一系列的锚点,这些锚点可以帮助模型更准确地定位和识别目标。
我们可以运行一下:
import torch
def make_anchors(feats, strides, grid_cell_offset=0.5):
"""Generate anchors from features."""
anchor_points, stride_tensor = [], []
assert feats is not None
dtype, device = feats[0].dtype, feats[0].device
for i, stride in enumerate(strides):
_, _, h, w = feats[i].shape
print("stride , h, w is ", stride, h, w)
sx = torch.arange(end=w, device=device, dtype=dtype) + grid_cell_offset # shift x
sy = torch.arange(end=h, device=device, dtype=dtype) + grid_cell_offset # shift y
# sy, sx = torch.meshgrid(sy, sx, indexing="ij") if TORCH_1_10 else torch.meshgrid(sy, sx)
sy, sx = torch.meshgrid(sy, sx)
anchor_points.append(torch.stack((sx, sy), -1).view(-1, 2))
stride_tensor.append(torch.full((h * w, 1), stride, dtype=dtype, device=device))
return torch.cat(anchor_points), torch.cat(stride_tensor)
if __name__ == "__main__":
feats = [torch.randn((8, 65, 80, 80)),
torch.randn((8, 65, 40, 40)),
torch.randn((8, 65, 20, 20))]
strides = [8, 16, 32]
grid_cell_offset=0.5
# torch.cat(anchor_points), torch.cat(stride_tensor)
res = make_anchors(feats, strides, grid_cell_offset)
print(res[0].shape, res[0][0].shape, res[0][1].shape, res[0][2].shape)
print(res[1].shape, res[1][0].shape, res[1][1].shape, res[1][2].shape)
# torch.Size([8400, 2]) torch.Size([2]) torch.Size([2]) torch.Size([2])
# torch.Size([8400, 1]) torch.Size([1]) torch.Size([1]) torch.Size([1])
我上面只打印了res(即锚点位置和步长信息)的shape。感兴趣的话,也可以打印其内容。
3,bbox解码——bbox_decode函数
bbox_decode函数的代码如下:
def bbox_decode(self, anchor_points, pred_dist):
"""Decode predicted object bounding box coordinates from anchor points and distribution."""
if self.use_dfl:
b, a, c = pred_dist.shape # batch, anchors, channels
pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)
return dist2bbox(pred_dist, anchor_points, xywh=False)
def dist2bbox(distance, anchor_points, xywh=True, dim=-1):
"""Transform distance(ltrb) to box(xywh or xyxy)."""
lt, rb = distance.chunk(2, dim)
x1y1 = anchor_points - lt
x2y2 = anchor_points + rb
if xywh:
c_xy = (x1y1 + x2y2) / 2
wh = x2y2 - x1y1
return torch.cat((c_xy, wh), dim) # xywh bbox
return torch.cat((x1y1, x2y2), dim) # xyxy bbox
它是用于将预测的边界框分布解码为实际的边界框坐标。
其传入参数是 anchor_points,锚点坐标,形状为(N, 2),其中N是锚点的数量。2就是上面说的x,y。而pred_dist即预测的边界框。如果使用了DFL(Distribution Focal Loss),那么则要进行DFL处理。即将pred_dist的形状由(b, a, c)变为(b, a, 4, c//4),即将每个锚点的c个通道分为4组,每组 c//4个通道。 对于每个组内的通道值应用 softmax函数,使得每个组内的值和为1。然后使用self.proj(一个预定义的投影矩阵)与 softmax后的结果进行矩阵乘法,得到最终的边界框偏移量。最后使用dist2bbox函数将结果转换为实际的边界框坐标。
而dist2bbox函数传入的就是上面得到的预测的边界框的偏移量,形状为(N, 4),其中N是锚点的数量,这四个值分别就是左上角和右下角的偏移量。而anchor_points就是锚点坐标。拿到参数后,首先分割偏移量,将其分为左上角的偏移量lt,右下角的偏移量rb。然后通过anchor_points减去左上角的偏移量和加上右下角的偏移量得到左上角和右下角的实际坐标。
yolov8模型对框的预测和训练都是基于anchor及其偏移量。如下方法用于转换:
bbox2dist 用于将 bbox(xyxy) 转换为 dist(lt, rb)
即将框由xyxy坐标形式变为相对锚点的偏移量形式(左上右下)
anchor_points 为坐标点,如对于长宽为 5*5 的图,
[[0,0],[1,0], ..., [4,0],
[0,1], [1,1], ..., [4,1],
[0,2], [1,2], ..., [4,2],
[0,3], [1,3], ..., [4,3],
[0,4], [1,4], ..., [4,4]]
基于 torch 的维度自动扩展,anchor_points 方便锚点位置转换的计算
x1y1, x2y2 = bbox.chunk(2, -1)
# 最后一个维度 [x1, y1, x2, y2] 分为两份,变成 [x1, y1], [x2, y2]。前面维度不变
torch.cat((anchor_points - x1y1, x2y2 - anchor_points), -1).clamp_(0, reg_max - 0.01) # dist (lt, rb)
# 先计算左,上,右,下的偏移量,然后将其取值范围压缩 clamp_ 到 [ 0, reg_max - 0.01]至今
# 最后返回 dist(lt, rb)
4,关键点解码——kpts_decode函数
kpts_decode函数的代码如下:
@staticmethod
def kpts_decode(anchor_points, pred_kpts):
"""Decodes predicted keypoints to image coordinates."""
y = pred_kpts.clone()
y[..., :2] *= 2.0
y[..., 0] += anchor_points[:, [0]] - 0.5
y[..., 1] += anchor_points[:, [1]] - 0.5
return y
解码关键点:是将预测的关键点从相对坐标解码为图像中 的绝对坐标。通过乘以2并加上锚点的位置,再减去0.5来调整关键点的位置。这个过程涉及到对关键点坐标的调整和偏移。
对代码的解析:
缩放关键点坐标:将y的前两个维度(x和y坐标)乘以2.0,这一步通常是为了将归一化后的坐标恢复到一个更大的范围。
调整x坐标:将y中的x坐标(y[..., 0])加上对应的锚点的x坐标,并减去0.5。这一步是为了将关键点的x坐标相对于锚点进行偏移。
调整y坐标:将u中的y坐标(y[..., 1])加上对应的锚点的y坐标,并减去0.5。这一步是为了将关键点的y坐标相对于锚点进行偏移。
通过这种方式,kpts_decode方法帮我们将预测的关键点从相对坐标转换为图像中的绝对坐标,从而更准确的表达目标的姿态信息。
5,注意: TaskAlignedAssigner 正样本分配策略
这里我打算新起一篇文章来详细学习。这里不讲,大家可以参考下一篇哈:link undetermined。
6,类别损失——BCELoss函数
BCE(二元交叉熵)损失函数是用来监督可见性的学习。一般用于二分类任务中的损失计算。它可以衡量预测概率和实际标签之间的差异。
下面看看BCELoss计算原理(内容于chatgpt生成):

yolov8使用BCE作为其分类损失,每类别判断“是否为此类”,并输出置信度(仅计算正样本)。简单来说,BCE就是把两个信息 “是此类”,“不是此类” 的熵都算出来,并加起来一起计算,让这个损失函数在上述两种情况下算出的损失都不为0。
self.bce_pose = nn.BCEWithLogitsLoss()
yolov5由于有对象损失的存在,在反算时,只对BCE分类输出的置信度分数做取最大值,得到置信度最大的类别后,直接输出。但是yolov8中由于去掉了对象损失,在输出中也去掉了“对象置信度”,直接输出各个类别的“置信度分数”, 再对其求最大值。yolov8用的多分类损失是N个目标的二元交叉熵损失。而不是一般我们认为的多目标的softmax交叉熵损失。
从下面代码可以看到,这里的分类损失是把N个目标的二元交叉熵损失求和,再取平均。

7,矩形框回归损失——bbox_loss函数
yolov8的矩形框损失主要由iou_loss和DFL loss组成。
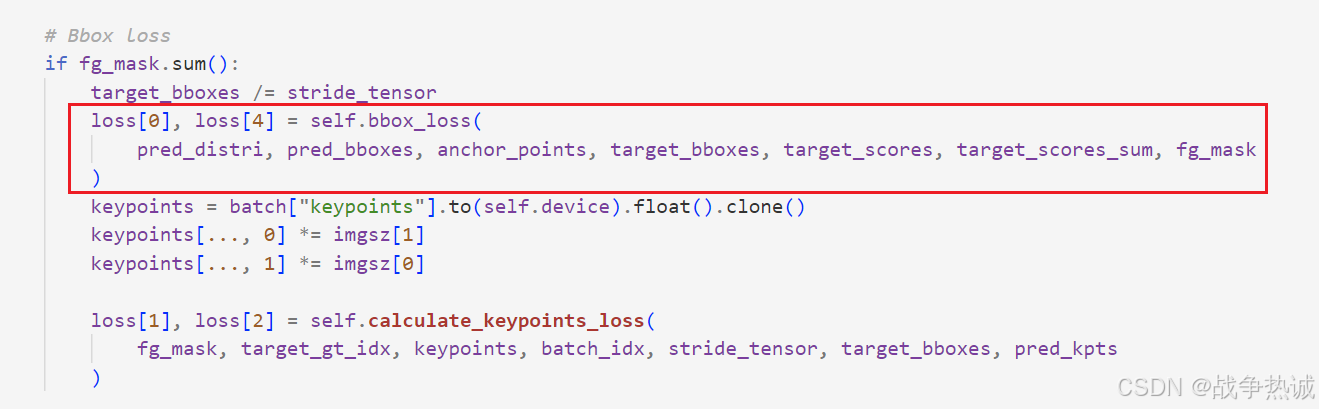
我们查看代码,可以看到 self.bbox_loss是初始化了BBoxLoss类。
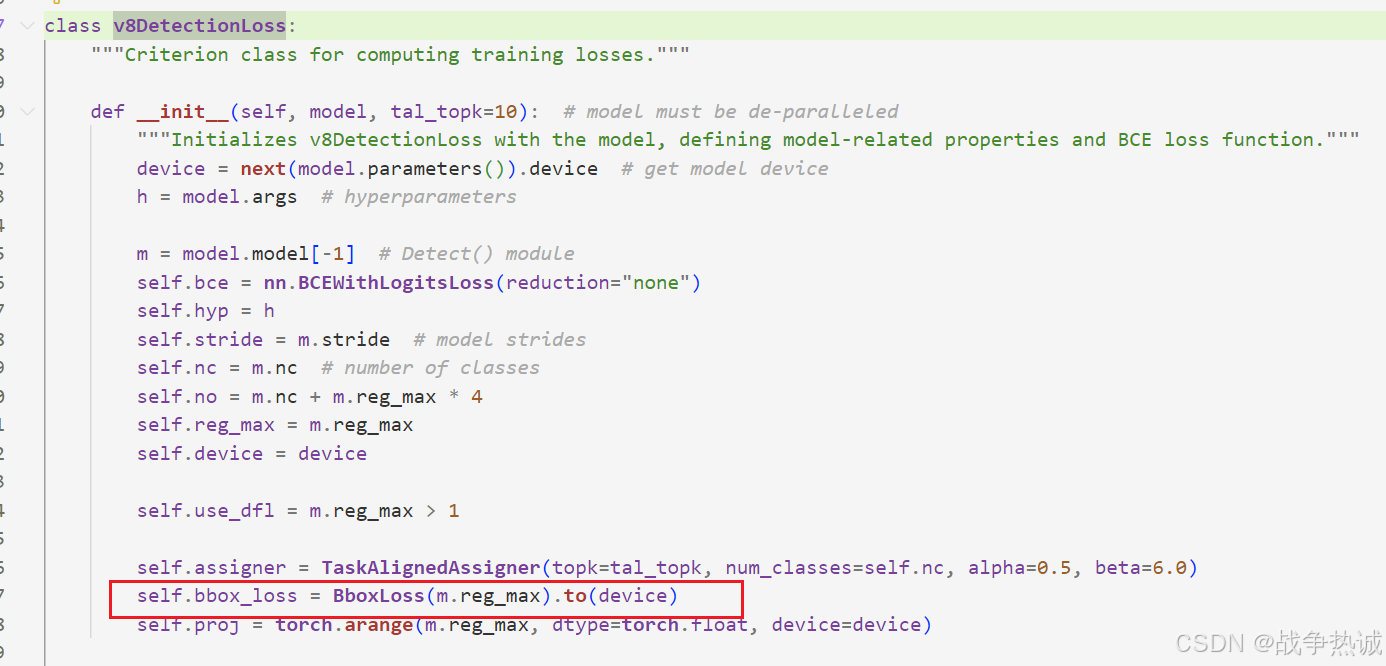
我们点进去,可以看到其代码如下:
class BboxLoss(nn.Module):
"""Criterion class for computing training losses during training."""
def __init__(self, reg_max=16):
"""Initialize the BboxLoss module with regularization maximum and DFL settings."""
super().__init__()
self.dfl_loss = DFLoss(reg_max) if reg_max > 1 else None
def forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):
"""IoU loss."""
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
# DFL loss
if self.dfl_loss:
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.dfl_loss.reg_max - 1)
loss_dfl = self.dfl_loss(pred_dist[fg_mask].view(-1, self.dfl_loss.reg_max), target_ltrb[fg_mask]) * weight
loss_dfl = loss_dfl.sum() / target_scores_sum
else:
loss_dfl = torch.tensor(0.0).to(pred_dist.device)
return loss_iou, loss_dfl
我们简单分析一下,BBoxLoss类是用于在训练过程中计算边界框的损失。也是比较简单,其初始化函数传入了一个reg_max的参数,表示DFL的最大正则化值。(如果传入的reg_max大于1,则实例化一个DFLoss对象,并将其存储为dfl_loss属性,否则,将其设置为None)。
前向传播函数接收多个参数:预测的分布 pred_dist,预测的边界框 pred_bboxes, 锚点 anchor_points, 目标边界框 target_bboxes, 目标分数 target_scores,目标分布总和 target_scores_sum,前景掩码 fg_mask。其每一行代码解析如下:
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1): 计算权重,它基于目标分数对每个前景样本进行加权。iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True): 计算预测边界框与目标边界框之间的交并比 (IoU),这里使用的是CIoU (Complete IoU)。loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum: 根据IoU和权重计算IoU损失,然后除以目标分数总和来归一化损失。- 如果存在
dfl_loss对象(即reg_max > 1),则计算DFL损失:target_ltrb = bbox2dist(anchor_points, target_bboxes, self.dfl_loss.reg_max - 1): 将目标边界框转换成相对于锚点的左上右下距离形式。loss_dfl = self.dfl_loss(pred_dist[fg_mask].view(-1, self.dfl_loss.reg_max), target_ltrb[fg_mask]) * weight: 使用dfl_loss计算DFL损失,并乘以权重。loss_dfl = loss_dfl.sum() / target_scores_sum: 归一化DFL损失。
- 如果没有
dfl_loss对象,则将loss_dfl设置为设备上的零张量。 - 最后,函数返回两个损失值
loss_iou和loss_dfl。
代码中用到了bbox iou 和 DFLLoss 我们也顺带学习一下。
bbox iou
代码如下:
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
"""
Calculate Intersection over Union (IoU) of box1(1, 4) to box2(n, 4).
Args:
box1 (torch.Tensor): A tensor representing a single bounding box with shape (1, 4).
box2 (torch.Tensor): A tensor representing n bounding boxes with shape (n, 4).
xywh (bool, optional): If True, input boxes are in (x, y, w, h) format. If False, input boxes are in
(x1, y1, x2, y2) format. Defaults to True.
GIoU (bool, optional): If True, calculate Generalized IoU. Defaults to False.
DIoU (bool, optional): If True, calculate Distance IoU. Defaults to False.
CIoU (bool, optional): If True, calculate Complete IoU. Defaults to False.
eps (float, optional): A small value to avoid division by zero. Defaults to 1e-7.
Returns:
(torch.Tensor): IoU, GIoU, DIoU, or CIoU values depending on the specified flags.
"""
# Get the coordinates of bounding boxes
if xywh: # transform from xywh to xyxy
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
else: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
# Intersection area
inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp_(0) * (
b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)
).clamp_(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps
# IoU
iou = inter / union
if CIoU or DIoU or GIoU:
cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw.pow(2) + ch.pow(2) + eps # convex diagonal squared
rho2 = (
(b2_x1 + b2_x2 - b1_x1 - b1_x2).pow(2) + (b2_y1 + b2_y2 - b1_y1 - b1_y2).pow(2)
) / 4 # center dist**2
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi**2) * ((w2 / h2).atan() - (w1 / h1).atan()).pow(2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
return iou - rho2 / c2 # DIoU
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
return iou # IoU
这个大家再熟悉不过了。就这样吧。
dfl loss
YOLOv8使用DFL衡量预测框的损失。DFL(Distribution Focal Loss)采用从锚点到边界框四边的相对偏移量作为回归目标,单个偏移量用一般分布(General distribution)表示。
假定标签 y 的范围,其最小值为 y0,最大值为yn,DFL将整个范围 [y0, yn]离散成一个集合{y0, y1, ...yi, yi+1, yn-1, yn},以步长为1递增。以目标检测框的偏移量为例。yolov8代码中取 reg_max=16,则离散的集合为 {0, 1, 2, 。。。14, 15},模型实际上是预测偏移量落在0~15每个整数的概率,所有整数点的概率求和等于1。
代码如下:
class DFLoss(nn.Module):
"""Criterion class for computing DFL losses during training."""
def __init__(self, reg_max=16) -> None:
"""Initialize the DFL module."""
super().__init__()
self.reg_max = reg_max
def __call__(self, pred_dist, target):
"""
Return sum of left and right DFL losses.
Distribution Focal Loss (DFL) proposed in Generalized Focal Loss
https://ieeexplore.ieee.org/document/9792391
"""
target = target.clamp_(0, self.reg_max - 1 - 0.01)
tl = target.long() # target left
tr = tl + 1 # target right
wl = tr - target # weight left
wr = 1 - wl # weight right
return (
F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl
+ F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr
).mean(-1, keepdim=True)
稍微解析一下这个模块。DFL是一种在目标检测任务中用来改进回归损失的方法。
其初始化方法接收一个参数reg_max,默认值是16,这通常是对应于预测分布的最大可能值。
其前向传播方法首先对target进行clamp,确保target值在有效范围内;然后计算左侧和右侧的目标索引;再计算左侧和右侧的权重;最后计算交叉熵损失,并根据权重加权。
代码详解:
target.clamp_(0, self.reg_max - 1 - 0.01):确保target的值被限制在一个小范围[0, reg_max - 1 - 0.01]内,防止溢出或下溢。tl = target.long():将target转换为整数,得到左边的目标索引。tr = tl + 1:计算右边的目标索引。wl = tr - target:计算左边目标的权重,基于target和tr之间的差值。wr = 1 - wl:计算右边目标的权重。- 使用
F.cross_entropy函数计算两个交叉熵损失:- 对于
tl,计算每个样本的损失,不进行归约(reduction="none")。 - 对于
tr,同样计算每个样本的损失,不进行归约。
- 对于
- 将这些损失重新塑形为与
tl相同的形状,并乘以相应的权重wl和wr。 - 最后,对最后一个维度求平均(
mean(-1, keepdim=True)),保持输出有一个额外的维度。
8,计算关键点损失——calculate_kepoints_loss函数
calculate_keypoints_loss函数用于计算关键点(keypoints)损失和关键点对象损失。它主要用于处理那些需要检测和定位图像中特定关键点的任务。
其代码如下:
def calculate_keypoints_loss(
self, masks, target_gt_idx, keypoints, batch_idx, stride_tensor, target_bboxes, pred_kpts
):
batch_idx = batch_idx.flatten()
batch_size = len(masks)
# Find the maximum number of keypoints in a single image
max_kpts = torch.unique(batch_idx, return_counts=True)[1].max()
# Create a tensor to hold batched keypoints
batched_keypoints = torch.zeros(
(batch_size, max_kpts, keypoints.shape[1], keypoints.shape[2]), device=keypoints.device
)
# Fill batched_keypoints with keypoints based on batch_idx
for i in range(batch_size):
keypoints_i = keypoints[batch_idx == i]
batched_keypoints[i, : keypoints_i.shape[0]] = keypoints_i
# Expand dimensions of target_gt_idx to match the shape of batched_keypoints
target_gt_idx_expanded = target_gt_idx.unsqueeze(-1).unsqueeze(-1)
# Use target_gt_idx_expanded to select keypoints from batched_keypoints
selected_keypoints = batched_keypoints.gather(
1, target_gt_idx_expanded.expand(-1, -1, keypoints.shape[1], keypoints.shape[2])
)
# Divide coordinates by stride
selected_keypoints /= stride_tensor.view(1, -1, 1, 1)
kpts_loss = 0
kpts_obj_loss = 0
if masks.any():
gt_kpt = selected_keypoints[masks]
area = xyxy2xywh(target_bboxes[masks])[:, 2:].prod(1, keepdim=True)
pred_kpt = pred_kpts[masks]
kpt_mask = gt_kpt[..., 2] != 0 if gt_kpt.shape[-1] == 3 else torch.full_like(gt_kpt[..., 0], True)
kpts_loss = self.keypoint_loss(pred_kpt, gt_kpt, kpt_mask, area) # pose loss
if pred_kpt.shape[-1] == 3:
kpts_obj_loss = self.bce_pose(pred_kpt[..., 2], kpt_mask.float()) # keypoint obj loss
return kpts_loss, kpts_obj_loss
稍微理解一下:
- 批量关键点处理:根据 batch_idx 将关键点组织成批量形式
- 选择关键点:使用 target_gt_idx 选择对应的目标关键点
- 调整坐标:将选择的关键点坐标除以步长
- 计算关键点损失:如果存在前景掩码,计算关键点位置损失和关键点可见性损失
- 返回损失:返回关键点位置损失和关键点可见性损失
keypoint loss
关键点损失(kpts_loss)是用于计算关键点(keypoints)的损失。它主要基于预测的关键点和地面真实关键点之间的欧几里得距离,并考虑了关键点的存在性掩码和物体的面积。
其代码如下:
class KeypointLoss(nn.Module):
"""Criterion class for computing training losses."""
def __init__(self, sigmas) -> None:
"""Initialize the KeypointLoss class."""
super().__init__()
self.sigmas = sigmas
def forward(self, pred_kpts, gt_kpts, kpt_mask, area):
"""Calculates keypoint loss factor and Euclidean distance loss for predicted and actual keypoints."""
d = (pred_kpts[..., 0] - gt_kpts[..., 0]).pow(2) + (pred_kpts[..., 1] - gt_kpts[..., 1]).pow(2)
kpt_loss_factor = kpt_mask.shape[1] / (torch.sum(kpt_mask != 0, dim=1) + 1e-9)
# e = d / (2 * (area * self.sigmas) ** 2 + 1e-9) # from formula
e = d / ((2 * self.sigmas).pow(2) * (area + 1e-9) * 2) # from cocoeval
return (kpt_loss_factor.view(-1, 1) * ((1 - torch.exp(-e)) * kpt_mask)).mean()
其前向传播函数首先计算预测关键点与地面真实关键点之间的平方欧几里得距离。然后计算关键点损失因子。并通过sigmas来计算归一化的误差,并计算最终的损失。
详解:
1,计算欧几里得距离:代码计算了预测关键点pred_kpts和地面真实关键点 gt_kpts之间的平方欧几里得距离d。通过代码可以看到,对于每个关键点,分布计算了其x和y坐标的差值的平方,然后相加。
2,计算关键点损失因子:kpt_mask是一个掩码张量,指示哪些关键点是有效的(非零)。kpt_loss_factor计算了每张图像中有效关键点的数量与总关键点数量的比例。这有助于平衡不同图像中关键点数量不一致的情况。
3,计算归一化的误差:根据sigmas和area来计算,将欧几里得距离d除以一个基于sigmas和area的项。这样做的目的是使误差与物体的大小成比例,并且考虑到关键点的重要程度。
4,计算最终的损失:使用平滑L1损失函数的形式(可以减少梯度爆炸的问题)。将上述结果乘以关键点掩码kpt_mask,确保只有有效关键点参与损失计算,最后乘以kpt_loss_factor并对所有样本求平均,得到最终的损失。
OK,关键内容已经解析完毕了。这里就这样吧。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











