




(1)
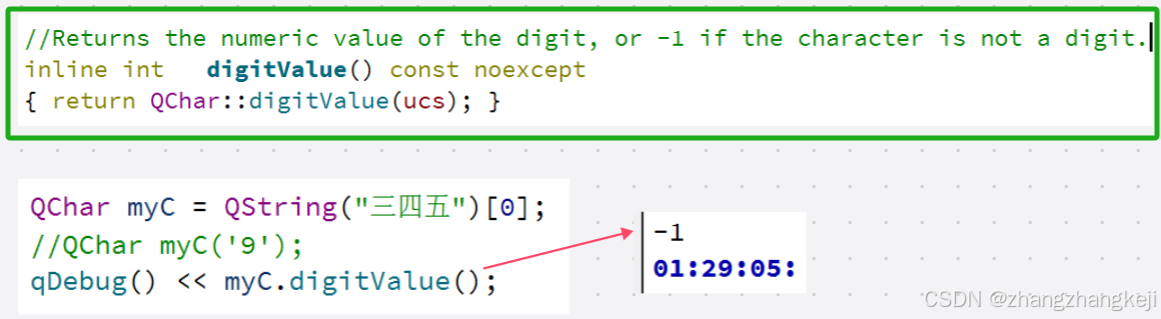
++
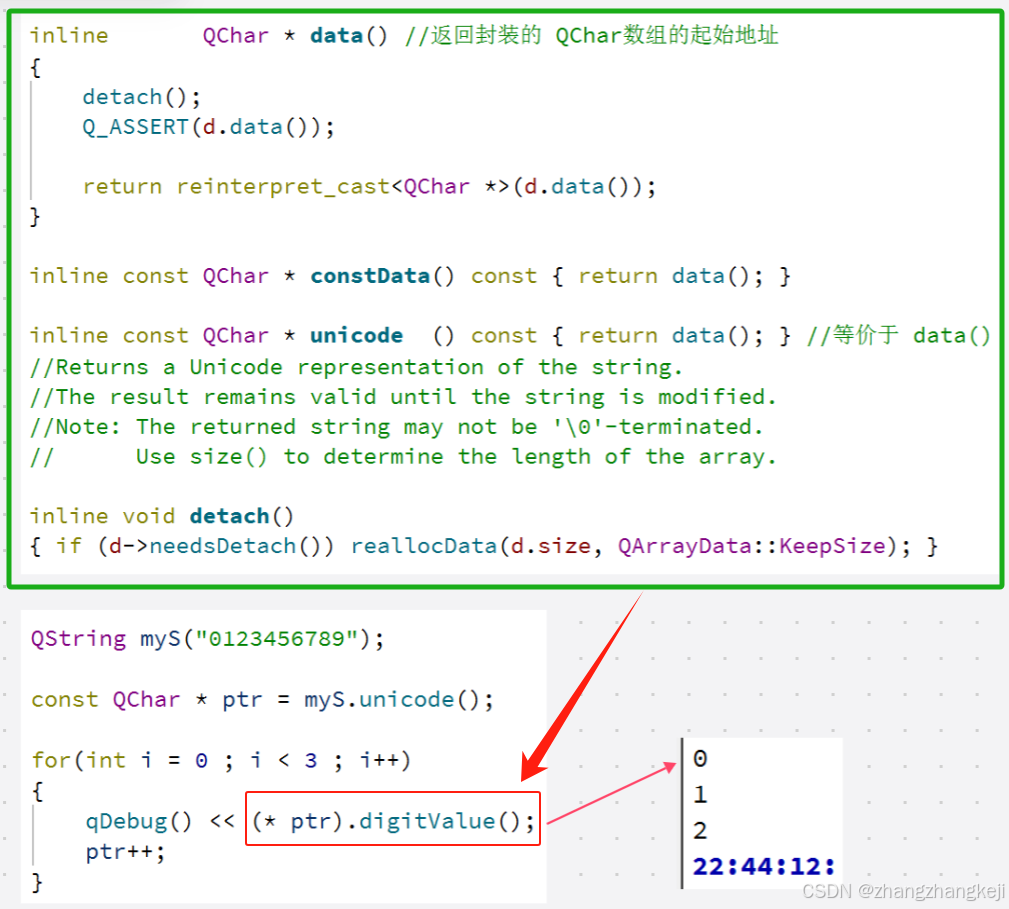
++

(2)给出源码:
#ifndef QCHAR_H
#define QCHAR_H
#include <QtCore/qglobal.h>
#include <functional> // for std::hash
QT_BEGIN_NAMESPACE //说明本类建立在 QT 的全局命名空间
class QString;
struct QLatin1Char
{
private:
char ch; //包含了一个字节的 字符,
public:
constexpr inline explicit QLatin1Char(char c) noexcept : ch(c) {} //有参构造函数
constexpr inline char toLatin1() const noexcept { return ch; } //返回内部的数据成员
constexpr inline char16_t unicode() const noexcept //返回本类内字符对应的 unicode码
{ return char16_t(uchar(ch)); }
friend constexpr inline
bool operator==(QLatin1Char lhs, QLatin1Char rhs) noexcept
{ return lhs.ch == rhs.ch; }
friend constexpr inline
bool operator!=(QLatin1Char lhs, QLatin1Char rhs) noexcept
{ return lhs.ch != rhs.ch; }
friend constexpr inline
bool operator<=(QLatin1Char lhs, QLatin1Char rhs) noexcept
{ return lhs.ch <= rhs.ch; }
friend constexpr inline
bool operator>=(QLatin1Char lhs, QLatin1Char rhs) noexcept
{ return lhs.ch >= rhs.ch; }
friend constexpr inline
bool operator< (QLatin1Char lhs, QLatin1Char rhs) noexcept
{ return lhs.ch < rhs.ch; }
friend constexpr inline
bool operator> (QLatin1Char lhs, QLatin1Char rhs) noexcept
{ return lhs.ch > rhs.ch; }
friend constexpr inline //另一组
bool operator==(char lhs, QLatin1Char rhs) noexcept
{ return lhs == rhs.toLatin1(); }
friend constexpr inline
bool operator!=(char lhs, QLatin1Char rhs) noexcept
{ return lhs != rhs.toLatin1(); }
friend constexpr inline
bool operator<=(char lhs, QLatin1Char rhs) noexcept
{ return lhs <= rhs.toLatin1(); }
friend constexpr inline
bool operator>=(char lhs, QLatin1Char rhs) noexcept
{ return lhs >= rhs.toLatin1(); }
friend constexpr inline
bool operator< (char lhs, QLatin1Char rhs) noexcept
{ return lhs < rhs.toLatin1(); }
friend constexpr inline
bool operator> (char lhs, QLatin1Char rhs) noexcept
{ return lhs > rhs.toLatin1(); }
friend constexpr inline
bool operator==(QLatin1Char lhs, char rhs) noexcept
{ return lhs.toLatin1() == rhs; }
friend constexpr inline
bool operator!=(QLatin1Char lhs, char rhs) noexcept
{ return lhs.toLatin1() != rhs; }
friend constexpr inline
bool operator<=(QLatin1Char lhs, char rhs) noexcept
{ return lhs.toLatin1() <= rhs; }
friend constexpr inline
bool operator>=(QLatin1Char lhs, char rhs) noexcept
{ return lhs.toLatin1() >= rhs; }
friend constexpr inline
bool operator< (QLatin1Char lhs, char rhs) noexcept
{ return lhs.toLatin1() < rhs; }
friend constexpr inline
bool operator> (QLatin1Char lhs, char rhs) noexcept
{ return lhs.toLatin1() > rhs; }
};
/*
在Qt中,Unicode字符是16位实体,没有任何标记或结构。这个类表示这样的实体。
它是轻量级的,因此可以在任何地方使用。大多数编译器将其视为无符号短整型。
QChar提供了完整的测试/分类功能、转换为其他格式和从其他格式转换为分解的Unicode,
并尝试进行比较和大小写转换(如果你要求它这样做的话)。
分类函数包括类似于标准 C++标头<cctype>(以前称为<ctype.h>)中的函数,
但对整个Unicode 字符范围进行作,而不仅仅是对 ASCIl 范围进行作。
如果字符是某种类型的字符,则它们都返回 true,否则返回 false。
这些分类函数是isNull()(如果字符为"0',则返回 true
isPrint()(如果字符是任何类型的可打印字符,包括空格,则为true)、isPunct()(任何类型的标点符号)、
isMark()(Unicode标记)、isLetter()(字母)、isNumbel()(任何类型的数字字符,而不仅仅是0-9)、
isLetterOrNumber()和isDigit()(十进制数字)。
所有这些都是在 category()周围的包装器,它们返回每个字符的 Unicode 定义的类别。
其中一些还计算派生属性(例如,如果字符的类别是 Separator*或来自 OtherControl类的异常代码点,
则isSpace()返回true)。
它表示这个字符的 “自然”书写方向。joiningType()QChar还提供了direction(),
函数指示字符如何与其邻居连接(主要用于阿拉伯语或叙利亚语),
最后是hasMirrored它指示当字符以“不自然”的书写方向打印时是否需要镜像该字符。
组成的Unicode字符(如ring)可以通过使用decomposition()函数转换为分解的Unicode
(“a”后面跟着“ringabove”)。
在Unicode中,比较不一定可能,而且转换大小写即使是在最好的情况下也非常困难。
Unicode涵盖了“整个”世界,也包括了世界上大多数的大小写和排序问题。
operator==()和friends将基于字符的Unicode数值(代码点)进行纯粹的数字比较,
而toUpper()和toLower()将在字符具有明确的上/下标对应时进行大小写转换。
对于依赖于语境的比较,请使用QString:ocaleAwareCompare)。
转换函数包括unicode()(转换为标量)、tolatin1()(转换为标量,但将所有非拉丁1字符转换为0)、
row()(返回Unicode行)、cell()(返回Unicode单元格)、
digitValue()(返回大量数字字符的整数值)以及许多构造函数。
QChar提供了构造函数和转换运算符,使得轻松转换到和从传统的8位字符。
如果您像QString文档中所解释的那样定义了OT NO CAST FROM ASCI和OT NO CAST TO ASCII,
则需要显式调用fromLatin1或使用QLatin1Char,以从8位字符构造QChar,
并且需要调用toLatin1()以获取8位值。
从Ot6.0开始,大多数QChar构造函数都是显式的。这是为了避免意外混合整数类型和字符串时出现危险的错误。
您可以通过定义宏QTIMPLICIT OCHAR CONSTRUCTION来选择退出(并使这些构造函数隐式)。
*/
//The QChar class provides a 16-bit Unicode character.
class Q_CORE_EXPORT QChar
{
private:
//这些静态的私有函数用于辅助实现判断本字符是否是空白符、字母、数字。
static bool QT_FASTCALL
isSpace_helper (char32_t ucs4) noexcept Q_DECL_CONST_FUNCTION;
static bool QT_FASTCALL
isLetter_helper(char32_t ucs4) noexcept Q_DECL_CONST_FUNCTION;
static bool QT_FASTCALL
isNumber_helper(char32_t ucs4) noexcept Q_DECL_CONST_FUNCTION;
static bool QT_FASTCALL
isLetterOrNumber_helper(char32_t ucs4) noexcept Q_DECL_CONST_FUNCTION;
#ifdef QT_NO_CAST_FROM_ASCII //经验证,此 if 不成立
QChar(char c) = delete; //所以是允许这么构造的。
QChar(uchar c) = delete;
#endif
char16_t ucs; //1993年发布的ISO/IEC 10646标准正式定义了UCS
//(Universal Character Set),作为Unicode的技术实现基础。
public:
enum SpecialCharacter { //特殊字符
Null = 0x0000,
Tabulation = 0x0009, //tab
LineFeed = 0x000a,
FormFeed = 0x000c,
CarriageReturn = 0x000d, //回车
Space = 0x0020, //空白符
Nbsp = 0x00a0, //这是 html 里的标志
SoftHyphen = 0x00ad,
ReplacementCharacter = 0xfffd,
ObjectReplacementCharacter = 0xfffc,
ByteOrderMark = 0xfeff,
ByteOrderSwapped = 0xfffe,
ParagraphSeparator = 0x2029, //段分隔符
LineSeparator = 0x2028, //行分隔符
VisualTabCharacter = 0x2192,
LastValidCodePoint = 0x10ffff
};
#ifdef QT_IMPLICIT_QCHAR_CONSTRUCTION
#define QCHAR_MAYBE_IMPLICIT Q_IMPLICIT
#else
#define QCHAR_MAYBE_IMPLICIT explicit
#endif
constexpr Q_IMPLICIT
QChar() noexcept : ucs(0) {}
constexpr Q_IMPLICIT
QChar(ushort rc) noexcept : ucs(rc) {}
constexpr QCHAR_MAYBE_IMPLICIT
QChar(uchar c, uchar r) noexcept : ucs(char16_t((r << 8) | c)) {}
constexpr Q_IMPLICIT //这些构造函数说明,QChar接受一个整数数字作为形参来构造 unicode字符
QChar(short rc) noexcept : ucs(char16_t(rc)) {}
//Constructs a QChar for the character with Unicode code point rc.
constexpr QCHAR_MAYBE_IMPLICIT
QChar(uint rc) noexcept : ucs((Q_ASSERT(rc <= 0xffff), char16_t(rc))) {}
constexpr QCHAR_MAYBE_IMPLICIT
QChar(int rc) noexcept : QChar(uint(rc)) {}
constexpr Q_IMPLICIT
QChar(SpecialCharacter s) noexcept : ucs(char16_t(s)) {}
constexpr Q_IMPLICIT
QChar(QLatin1Char ch) noexcept : ucs(ch.unicode()) {}
constexpr Q_IMPLICIT
QChar(char16_t ch) noexcept : ucs(ch) {} //char16_t = u_short
#if defined(Q_OS_WIN) || defined(Q_CLANG_QDOC)
constexpr Q_IMPLICIT
QChar(wchar_t ch) noexcept : ucs(char16_t(ch)) {}
#endif
#ifndef QT_NO_CAST_FROM_ASCII //确实无此宏定义
// Always implicit -- allow for 'x' => QChar conversions
QT_ASCII_CAST_WARN constexpr Q_IMPLICIT
QChar(char c) noexcept : ucs(uchar(c)) { } //这个构造函数是允许的
#ifndef QT_RESTRICTED_CAST_FROM_ASCII
QT_ASCII_CAST_WARN constexpr QCHAR_MAYBE_IMPLICIT
QChar(uchar c) noexcept : ucs(c) { }
#endif
#endif
#undef QCHAR_MAYBE_IMPLICIT //取消了一个宏定义
//Constructs a QChar from UTF-16 character c.
static constexpr QChar fromUcs2(char16_t c) noexcept { return QChar{c}; }
static constexpr inline auto fromUcs4(char32_t c) noexcept; //返回值不固定哦
// Unicode information 以下是 300 行,共 7 个枚举量,不必阅读与注释。挪到了后面
// 7 个枚举量类:Category、Script、Direction、Decomposition
// 7 个枚举量类:JoiningType、CombiningClass、UnicodeVersion
//Returns the numeric value of the digit, or -1 if the character is not a digit.
inline int digitValue() const noexcept
{ return QChar::digitValue(ucs); }
inline QChar toLower() const noexcept
{ return QChar(QChar::toLower(ucs)); }
inline QChar toUpper() const noexcept
{ return QChar(QChar::toUpper(ucs)); }
//如果字符是小写或大写字母,则返回标题大小写的等效值;否则返回字符本身。
inline QChar toTitleCase() const noexcept
{ return QChar(QChar::toTitleCase(ucs)); }
inline QChar toCaseFolded() const noexcept
{ return QChar(QChar::toCaseFolded(ucs)); }
//返回该字符的大写等效值。对于大多数 Unicode 字符,这与 toLower() 相同。
constexpr inline char toLatin1() const noexcept //所以无法确定 char 的取值范围
{ return ucs > 0xff ? '\0' : char(ucs); } // signed char 或 unsigned char
static constexpr QChar fromLatin1(char c) noexcept //静态成员函数
{ return QLatin1Char(c); }
constexpr inline char16_t unicode() const noexcept { return ucs; }
constexpr inline char16_t & unicode() noexcept { return ucs; }
constexpr inline
bool isNull () const noexcept { return ucs == 0; }
inline
bool isPrint() const noexcept { return QChar::isPrint(ucs); }
constexpr inline
bool isSpace() const noexcept { return QChar::isSpace(ucs); }
inline
bool isMark () const noexcept { return QChar::isMark(ucs); }
inline
bool isPunct() const noexcept { return QChar::isPunct(ucs); }
inline
bool isSymbol() const noexcept { return QChar::isSymbol(ucs); }
//Returns true if the character is a symbol (Symbol_* categories);
//otherwise returns false.
constexpr inline
bool isLetter() const noexcept { return QChar::isLetter(ucs); }
//Returns true if the character is a number (Number_* categories, not just 0-9);
//otherwise returns false.
constexpr inline
bool isNumber() const noexcept { return QChar::isNumber(ucs); }
constexpr inline
bool isDigit() const noexcept { return QChar::isDigit(ucs); }
//Returns true if the character is a decimal digit (Number_DecimalDigit);
//otherwise returns false.
constexpr inline
bool isLetterOrNumber() const noexcept { return QChar::isLetterOrNumber(ucs); }
constexpr inline
bool isLower() const noexcept { return QChar::isLower(ucs); }
constexpr inline
bool isUpper() const noexcept { return QChar::isUpper(ucs); }
constexpr inline
bool isTitleCase() const noexcept { return QChar::isTitleCase(ucs); }
constexpr inline
bool isNonCharacter() const noexcept { return QChar::isNonCharacter(ucs); }
//Returns true if the QChar is a non-character; false otherwise.
//Unicode has a certain number of code points that are classified as
//"non-characters:" that is,
//they can be used for internal purposes in applications
//but cannot be used for text interchange.
//Those are the last two entries each Unicode Plane
//([0xfffe..0xffff], [0x1fffe..0x1ffff], etc.) as well as the entries in
//range [0xfdd0..0xfdef].
static constexpr inline
bool isNonCharacter(char32_t ucs4) noexcept
{
return ucs4 >= 0xfdd0 && (ucs4 <= 0xfdef || (ucs4 & 0xfffe) == 0xfffe);
}
//Returns the numeric value of the digit specified by the UCS-4-encoded character,
//ucs4, or -1 if the character is not a digit.
static int QT_FASTCALL digitValue(char32_t ucs4) //注意其形参
noexcept Q_DECL_CONST_FUNCTION;
static char32_t QT_FASTCALL toLower(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static char32_t QT_FASTCALL toUpper(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static char32_t QT_FASTCALL toTitleCase(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static char32_t QT_FASTCALL toCaseFolded(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static bool QT_FASTCALL isPrint(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static constexpr inline
bool isSpace(char32_t ucs4) noexcept Q_DECL_CONST_FUNCTION
{
// note that [0x09..0x0d] + 0x85 are exceptional Cc-s and must be handled explicitly
return ucs4 == 0x20 || (ucs4 <= 0x0d && ucs4 >= 0x09)
|| (ucs4 > 127 && (ucs4 == 0x85 || ucs4 == 0xa0 || QChar::isSpace_helper(ucs4)));
}
static bool QT_FASTCALL isMark(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static bool QT_FASTCALL isPunct(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static bool QT_FASTCALL isSymbol(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static constexpr inline bool isLetter(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION
{
return (ucs4 >= 'A' && ucs4 <= 'z' && (ucs4 >= 'a' || ucs4 <= 'Z'))
|| (ucs4 > 127 && QChar::isLetter_helper(ucs4));
}
static constexpr inline bool isNumber(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION
{ return (ucs4 <= '9' && ucs4 >= '0') ||
(ucs4 > 127 && QChar::isNumber_helper(ucs4));
}
static constexpr inline bool isLetterOrNumber(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION
{
return (ucs4 >= 'A' && ucs4 <= 'z' && (ucs4 >= 'a' || ucs4 <= 'Z'))
|| (ucs4 >= '0' && ucs4 <= '9')
|| (ucs4 > 127 && QChar::isLetterOrNumber_helper(ucs4));
}
static constexpr inline bool isDigit(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION
{ return (ucs4 <= '9' && ucs4 >= '0') ||
(ucs4 > 127 && QChar::category(ucs4) == Number_DecimalDigit);
}
static constexpr inline bool isLower(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION
{ return (ucs4 <= 'z' && ucs4 >= 'a') ||
(ucs4 > 127 && QChar::category(ucs4) == Letter_Lowercase);
}
static constexpr inline bool isUpper(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION
{ return (ucs4 <= 'Z' && ucs4 >= 'A') ||
(ucs4 > 127 && QChar::category(ucs4) == Letter_Uppercase);
}
static constexpr inline bool isTitleCase(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION
{ return ucs4 > 127 && QChar::category(ucs4) == Letter_Titlecase; }
friend constexpr inline
bool operator==(QChar c1, QChar c2) noexcept { return c1.ucs == c2.ucs; }
friend constexpr inline
bool operator< (QChar c1, QChar c2) noexcept { return c1.ucs < c2.ucs; }
friend constexpr inline
bool operator!=(QChar c1, QChar c2) noexcept { return !operator==(c1, c2); }
friend constexpr inline
bool operator>=(QChar c1, QChar c2) noexcept { return !operator< (c1, c2); }
friend constexpr inline
bool operator> (QChar c1, QChar c2) noexcept { return operator< (c2, c1); }
friend constexpr inline
bool operator<=(QChar c1, QChar c2) noexcept { return !operator< (c2, c1); }
friend constexpr inline
bool operator==(QChar lhs, std::nullptr_t) noexcept { return lhs.isNull(); }
friend constexpr inline
bool operator< (QChar, std::nullptr_t) noexcept { return false; }
friend constexpr inline
bool operator==(std::nullptr_t, QChar rhs) noexcept { return rhs.isNull(); }
friend constexpr inline
bool operator< (std::nullptr_t, QChar rhs) noexcept { return !rhs.isNull(); }
friend constexpr inline
bool operator!=(QChar lhs, std::nullptr_t) noexcept
{ return !operator==(lhs, nullptr); }
friend constexpr inline
bool operator>=(QChar lhs, std::nullptr_t) noexcept
{ return !operator< (lhs, nullptr); }
friend constexpr inline
bool operator> (QChar lhs, std::nullptr_t) noexcept
{ return operator< (nullptr, lhs); }
friend constexpr inline
bool operator<=(QChar lhs, std::nullptr_t) noexcept
{ return !operator< (nullptr, lhs); }
friend constexpr inline
bool operator!=(std::nullptr_t, QChar rhs) noexcept
{ return !operator==(nullptr, rhs); }
friend constexpr inline
bool operator>=(std::nullptr_t, QChar rhs) noexcept
{ return !operator< (nullptr, rhs); }
friend constexpr inline
bool operator> (std::nullptr_t, QChar rhs) noexcept
{ return operator< (rhs, nullptr); }
friend constexpr inline
bool operator<=(std::nullptr_t, QChar rhs) noexcept
{ return !operator< (rhs, nullptr); }
//********************************************************************
//************以下就是不常用的内容,不必看了,或者以后再看********************
//********************************************************************
static Script QT_FASTCALL script(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static UnicodeVersion QT_FASTCALL unicodeVersion(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static UnicodeVersion QT_FASTCALL currentUnicodeVersion()
noexcept Q_DECL_CONST_FUNCTION;
static constexpr inline
bool isHighSurrogate(char32_t ucs4) noexcept
{
return (ucs4 & 0xfffffc00) == 0xd800; // 0xd800 + up to 1023 (0x3ff)
}
static constexpr inline
bool isLowSurrogate(char32_t ucs4) noexcept
{
return (ucs4 & 0xfffffc00) == 0xdc00; // 0xdc00 + up to 1023 (0x3ff)
}
static constexpr inline
bool isSurrogate(char32_t ucs4) noexcept
{
return (ucs4 - 0xd800u < 2048u);
}
static constexpr inline
bool requiresSurrogates(char32_t ucs4) noexcept
{
return (ucs4 >= 0x10000);
}
static constexpr inline
char32_t surrogateToUcs4(char16_t high, char16_t low) noexcept
{
// 0x010000 through 0x10ffff, provided params are actual high, low surrogates.
// 0x010000 + ((high - 0xd800) << 10) + (low - 0xdc00), optimized:
return (char32_t(high)<<10) + low - 0x35fdc00;
}
static constexpr inline
char32_t surrogateToUcs4(QChar high, QChar low) noexcept
{
return surrogateToUcs4(high.ucs, low.ucs);
}
static constexpr inline
char16_t highSurrogate(char32_t ucs4) noexcept
{
return char16_t((ucs4>>10) + 0xd7c0);
}
static constexpr inline
char16_t lowSurrogate(char32_t ucs4) noexcept
{
return char16_t(ucs4%0x400 + 0xdc00);
}
static Category QT_FASTCALL category(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static Direction QT_FASTCALL direction(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static JoiningType QT_FASTCALL joiningType(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static unsigned char QT_FASTCALL combiningClass(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static char32_t QT_FASTCALL mirroredChar(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static bool QT_FASTCALL hasMirrored(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
static QString QT_FASTCALL decomposition(char32_t ucs4);
static Decomposition QT_FASTCALL decompositionTag(char32_t ucs4)
noexcept Q_DECL_CONST_FUNCTION;
//Returns the cell (least significant byte) of the Unicode character.
constexpr inline uchar cell() const noexcept { return uchar(ucs & 0xff); }
constexpr inline uchar row() const noexcept { return uchar((ucs>>8)&0xff); }
//Returns the row (most significant byte) of the Unicode character.
constexpr inline void setCell(uchar acell) noexcept
{ ucs = char16_t((ucs & 0xff00) + acell); }
constexpr inline void setRow(uchar arow) noexcept
{ ucs = char16_t((char16_t(arow)<<8) + (ucs&0xff)); }
constexpr inline
bool isHighSurrogate() const noexcept { return QChar::isHighSurrogate(ucs); }
constexpr inline
bool isLowSurrogate() const noexcept { return QChar::isLowSurrogate(ucs); }
constexpr inline
bool isSurrogate() const noexcept { return QChar::isSurrogate(ucs); }
inline Script script() const noexcept
{ return QChar::script(ucs); }
inline UnicodeVersion unicodeVersion() const noexcept
{ return QChar::unicodeVersion(ucs); }
// 7 个枚举量类:Category、Script、Direction、Decomposition
// 7 个枚举量类:JoiningType、CombiningClass、UnicodeVersion
inline Category category () const noexcept
{ return QChar::category(ucs); }
inline Direction direction () const noexcept
{ return QChar::direction(ucs); }
inline JoiningType joiningType () const noexcept
{ return QChar::joiningType(ucs); }
inline unsigned char combiningClass() const noexcept
{ return QChar::combiningClass(ucs); }
inline QChar mirroredChar() const noexcept
{ return QChar(QChar::mirroredChar(ucs)); }
inline bool hasMirrored() const noexcept
{ return QChar::hasMirrored(ucs); }
QString decomposition() const;
inline Decomposition decompositionTag() const noexcept
{ return QChar::decompositionTag(ucs); }
enum Category
{
Mark_NonSpacing, // Mn
Mark_SpacingCombining, // Mc
Mark_Enclosing, // Me
Number_DecimalDigit, // Nd
Number_Letter, // Nl
Number_Other, // No
Separator_Space, // Zs
Separator_Line, // Zl
Separator_Paragraph, // Zp
Other_Control, // Cc
Other_Format, // Cf
Other_Surrogate, // Cs
Other_PrivateUse, // Co
Other_NotAssigned, // Cn
Letter_Uppercase, // Lu
Letter_Lowercase, // Ll
Letter_Titlecase, // Lt
Letter_Modifier, // Lm
Letter_Other, // Lo
Punctuation_Connector, // Pc
Punctuation_Dash, // Pd
Punctuation_Open, // Ps
Punctuation_Close, // Pe
Punctuation_InitialQuote, // Pi
Punctuation_FinalQuote, // Pf
Punctuation_Other, // Po
Symbol_Math, // Sm
Symbol_Currency, // Sc
Symbol_Modifier, // Sk
Symbol_Other // So
};
enum Script
{
Script_Unknown,
Script_Inherited,
Script_Common,
Script_Latin,
Script_Greek,
Script_Cyrillic,
Script_Armenian,
Script_Hebrew,
Script_Arabic,
Script_Syriac,
Script_Thaana,
Script_Devanagari,
Script_Bengali,
Script_Gurmukhi,
Script_Gujarati,
Script_Oriya,
Script_Tamil,
Script_Telugu,
Script_Kannada,
Script_Malayalam,
Script_Sinhala,
Script_Thai,
Script_Lao,
Script_Tibetan,
Script_Myanmar,
Script_Georgian,
Script_Hangul,
Script_Ethiopic,
Script_Cherokee,
Script_CanadianAboriginal,
Script_Ogham,
Script_Runic,
Script_Khmer,
Script_Mongolian,
Script_Hiragana,
Script_Katakana,
Script_Bopomofo,
Script_Han,
Script_Yi,
Script_OldItalic,
Script_Gothic,
Script_Deseret,
Script_Tagalog,
Script_Hanunoo,
Script_Buhid,
Script_Tagbanwa,
Script_Coptic,
// Unicode 4.0 additions
Script_Limbu,
Script_TaiLe,
Script_LinearB,
Script_Ugaritic,
Script_Shavian,
Script_Osmanya,
Script_Cypriot,
Script_Braille,
// Unicode 4.1 additions
Script_Buginese,
Script_NewTaiLue,
Script_Glagolitic,
Script_Tifinagh,
Script_SylotiNagri,
Script_OldPersian,
Script_Kharoshthi,
// Unicode 5.0 additions
Script_Balinese,
Script_Cuneiform,
Script_Phoenician,
Script_PhagsPa,
Script_Nko,
// Unicode 5.1 additions
Script_Sundanese,
Script_Lepcha,
Script_OlChiki,
Script_Vai,
Script_Saurashtra,
Script_KayahLi,
Script_Rejang,
Script_Lycian,
Script_Carian,
Script_Lydian,
Script_Cham,
// Unicode 5.2 additions
Script_TaiTham,
Script_TaiViet,
Script_Avestan,
Script_EgyptianHieroglyphs,
Script_Samaritan,
Script_Lisu,
Script_Bamum,
Script_Javanese,
Script_MeeteiMayek,
Script_ImperialAramaic,
Script_OldSouthArabian,
Script_InscriptionalParthian,
Script_InscriptionalPahlavi,
Script_OldTurkic,
Script_Kaithi,
// Unicode 6.0 additions
Script_Batak,
Script_Brahmi,
Script_Mandaic,
// Unicode 6.1 additions
Script_Chakma,
Script_MeroiticCursive,
Script_MeroiticHieroglyphs,
Script_Miao,
Script_Sharada,
Script_SoraSompeng,
Script_Takri,
// Unicode 7.0 additions
Script_CaucasianAlbanian,
Script_BassaVah,
Script_Duployan,
Script_Elbasan,
Script_Grantha,
Script_PahawhHmong,
Script_Khojki,
Script_LinearA,
Script_Mahajani,
Script_Manichaean,
Script_MendeKikakui,
Script_Modi,
Script_Mro,
Script_OldNorthArabian,
Script_Nabataean,
Script_Palmyrene,
Script_PauCinHau,
Script_OldPermic,
Script_PsalterPahlavi,
Script_Siddham,
Script_Khudawadi,
Script_Tirhuta,
Script_WarangCiti,
// Unicode 8.0 additions
Script_Ahom,
Script_AnatolianHieroglyphs,
Script_Hatran,
Script_Multani,
Script_OldHungarian,
Script_SignWriting,
// Unicode 9.0 additions
Script_Adlam,
Script_Bhaiksuki,
Script_Marchen,
Script_Newa,
Script_Osage,
Script_Tangut,
// Unicode 10.0 additions
Script_MasaramGondi,
Script_Nushu,
Script_Soyombo,
Script_ZanabazarSquare,
// Unicode 12.1 additions
Script_Dogra,
Script_GunjalaGondi,
Script_HanifiRohingya,
Script_Makasar,
Script_Medefaidrin,
Script_OldSogdian,
Script_Sogdian,
Script_Elymaic,
Script_Nandinagari,
Script_NyiakengPuachueHmong,
Script_Wancho,
// Unicode 13.0 additions
Script_Chorasmian,
Script_DivesAkuru,
Script_KhitanSmallScript,
Script_Yezidi,
ScriptCount
};
enum Direction
{
DirL, DirR, DirEN, DirES, DirET, DirAN, DirCS, DirB, DirS, DirWS, DirON,
DirLRE, DirLRO, DirAL, DirRLE, DirRLO, DirPDF, DirNSM, DirBN,
DirLRI, DirRLI, DirFSI, DirPDI
};
enum Decomposition
{
NoDecomposition,
Canonical,
Font,
NoBreak,
Initial,
Medial,
Final,
Isolated,
Circle,
Super,
Sub,
Vertical,
Wide,
Narrow,
Small,
Square,
Compat,
Fraction
};
enum JoiningType {
Joining_None,
Joining_Causing,
Joining_Dual,
Joining_Right,
Joining_Left,
Joining_Transparent
};
enum CombiningClass
{
Combining_BelowLeftAttached = 200,
Combining_BelowAttached = 202,
Combining_BelowRightAttached = 204,
Combining_LeftAttached = 208,
Combining_RightAttached = 210,
Combining_AboveLeftAttached = 212,
Combining_AboveAttached = 214,
Combining_AboveRightAttached = 216,
Combining_BelowLeft = 218,
Combining_Below = 220,
Combining_BelowRight = 222,
Combining_Left = 224,
Combining_Right = 226,
Combining_AboveLeft = 228,
Combining_Above = 230,
Combining_AboveRight = 232,
Combining_DoubleBelow = 233,
Combining_DoubleAbove = 234,
Combining_IotaSubscript = 240
};
enum UnicodeVersion {
Unicode_Unassigned,
Unicode_1_1,
Unicode_2_0,
Unicode_2_1_2,
Unicode_3_0,
Unicode_3_1,
Unicode_3_2,
Unicode_4_0,
Unicode_4_1,
Unicode_5_0,
Unicode_5_1,
Unicode_5_2,
Unicode_6_0,
Unicode_6_1,
Unicode_6_2,
Unicode_6_3,
Unicode_7_0,
Unicode_8_0,
Unicode_9_0,
Unicode_10_0,
Unicode_11_0,
Unicode_12_0,
Unicode_12_1,
Unicode_13_0
};
};
Q_DECLARE_TYPEINFO(QChar, Q_PRIMITIVE_TYPE);
#ifndef QT_NO_DATASTREAM //为本 QChar 类型适用于 << 、 >> 运算符
Q_CORE_EXPORT QDataStream & operator<<(QDataStream &, QChar);
Q_CORE_EXPORT QDataStream & operator>>(QDataStream &, QChar &);
#endif
QT_END_NAMESPACE //说明以上内容定义域 QT 的全局空间
namespace std { //扩充了 std 命名空间
template <>
struct hash<QT_PREPEND_NAMESPACE(QChar)>
{
template <typename = void> // for transparent constexpr tracking
constexpr size_t operator()(QT_PREPEND_NAMESPACE(QChar) c) const
noexcept(noexcept(std::hash<char16_t>{}(u' ')))
{
return std::hash<char16_t>{}(c.unicode());
}
};
} // namespace std
#endif // QCHAR_H
#include <QtCore/qstringview.h> // for QChar::fromUcs4() definition
(3)
谢谢


















 1680
1680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











