




(36)函 _Atomic_wait_compare_non_lock_free (),该函数可以原子性的完成内存复制,并判断复制的字节是否为 0 ,源代码如下:
// 本函数在获取锁 _Spinlock_raw 以后,原子性的比较地址 _Storage 与地址 _Comparand 处
// 开始的 _Size 个字节的数据是否相等。是则返回 true,不等返回 fasle。
// 本函数的功能是给普通的比较函数 memcmp(..) 加上了原子保护。
template <class _Spinlock_t>
bool __stdcall _Atomic_wait_compare_non_lock_free // 本函数调用了上面的俩锁等待与锁释放函数
( const void* _Storage, void* _Comparand, size_t _Size, void* _Spinlock_raw) noexcept
{
_Spinlock_t& _Spinlock = *static_cast<_Spinlock_t*>(_Spinlock_raw); // 转换成模板参数的类型
_Atomic_lock_acquire(_Spinlock); // 忙等待,以获得自旋锁的使用权
const auto _Cmp_result = _CSTD memcmp(_Storage, _Comparand, _Size); // 内存中的数据比较
//int memcmp( void const* _Buf1, void const* _Buf2, size_t _Size );相等返回 0
_Atomic_lock_release(_Spinlock); // 释放自旋锁
return _Cmp_result == 0; // 形参 1 和 2 相等则返回 true 。
}
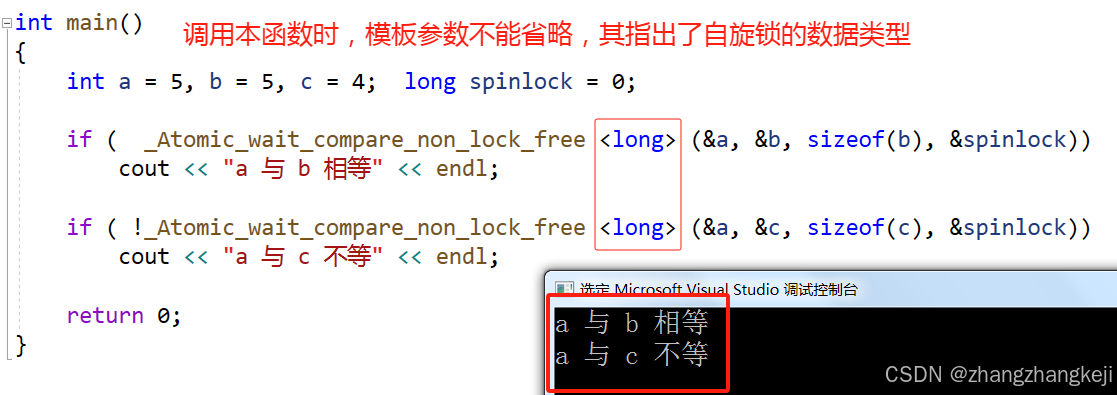
++ 举例测试一下:
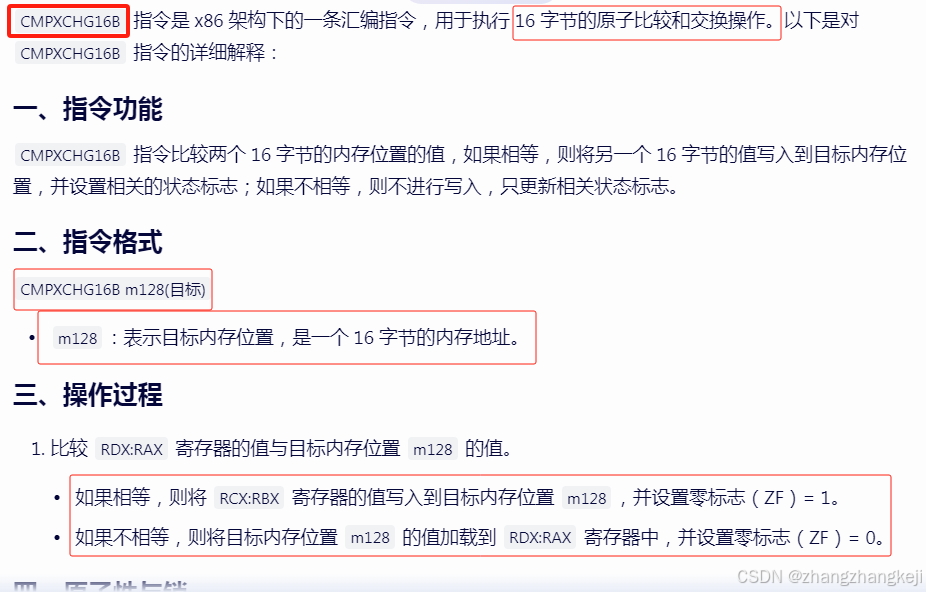
(37)函数 _Atomic_wait_compare_16_bytes () 与指令 CMPXCHG16B,先介绍这个指令。但在旧版本的 x64 CPU 上没有这个指令,所以本 STL 库代码创造了这个函数来实现同样的功能:
++ 该函数的代码如下。如果理解了 atomic 对少字节的操作。 16 字节的数据操作可以类比着来理解,本函数因为调用链里缺乏源代码,所以目前还不能完全理解。只记录一下代码:
// 本函数适用于低版本的 x64 CPU 上运行 win64 系统,而没有 cmpxchg16b 指令的情形。
// 本函把 16 字节的形参1 与形参 2 交换,交换成功则返回 true。
inline bool __stdcall _Atomic_wait_compare_16_bytes
(const void* _Storage, void* _Comparand, size_t, void*) noexcept
{
const auto _Dest = static_cast<long long*>(const_cast<void*>(_Storage));
const auto _Cmp = static_cast<const long long*>(_Comparand);
alignas(16) long long _Tmp[2] = {_Cmp[0], _Cmp[1]};
return _STD_COMPARE_EXCHANGE_128(_Dest, _Tmp[1], _Tmp[0], _Tmp) != 0;
/*
// 看起来是旧主机用一个函数来完成 16 字节的原子交换操作,以替换和实现 cmpxchg16b 指令的功能。
u_char __std_atomic_compare_exchange_128
( long long* Destination, long long ExchangeHigh, long long ExchangeLow , long long* ComparandResult);
#define _STD_COMPARE_EXCHANGE_128 __std_atomic_compare_exchange_128
*/
}
(38)
谢谢


















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











