



大家好,我是飞哥!
在内核是如何给容器中的进程分配CPU资源的? 这篇文章中我们介绍了Linux内核给容器分配CPU资源的第一种方式,通过 period 和 quota 的组合来限制容器使用的CPU时间上限。但其实内核给实现CPU资源分配还存在第二种方式,那就是按权重分配。我们来看看这种分配方式是如何使用的,底层实现原理又是怎样的。
一、Linux的完全公平调度器
在讲容器权重分配之前,我们得先来回顾一下内核的完全公平调度器的实现。
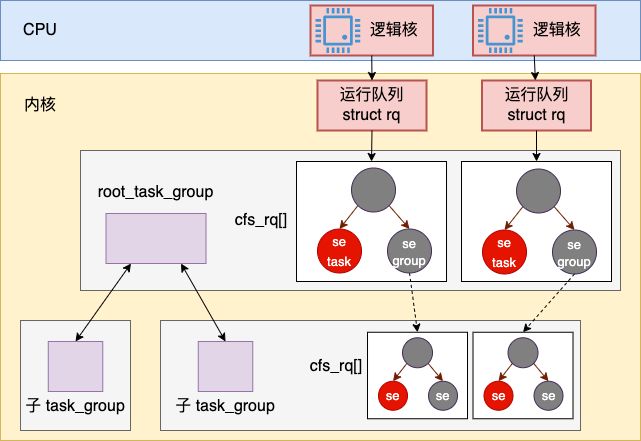
Linux 内核中的完全公平调度器中每个逻辑核都有一个调度队列 struct cfs_rq。每个调度队列中都是用红黑树来组织的。红黑树的节点是 struct sched_entity, sched_entity 中既可以关联具体的进程 struct task_struct 也可以关联容器的 struct cfs_rq。
以下是完全公平调度器 cfs_rq 内核对象的定义。
// file:kernel/sched/sched.h
struct cfs_rq {
...
// 当前队列中所有进程vruntime中的最小值
u64 min_vruntime;
// 保存就绪任务的红黑树
struct rb_root_cached tasks_timeline;
...
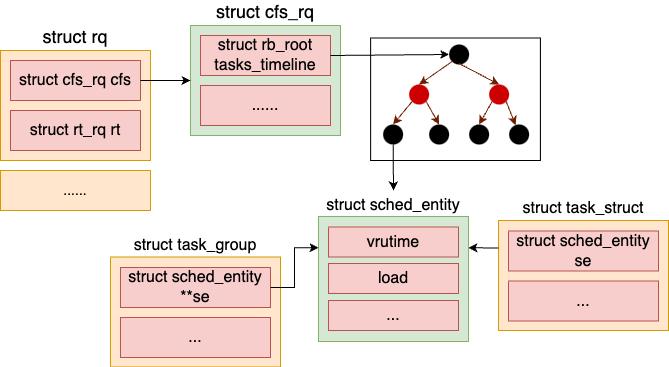
}在该对象中,最核心的是这个 rb_root_cached 类型的对象,这个对象的数据结构就是以红黑树来组织的。在红黑树的节点中,放是一个调度实体 sched_entity 对象。这个对象有可能是属于普通进程 task_struct 的,也有可能是属于容器进程组 task_group。
//file:kernel/sched/sched.h
struct task_group {
...
struct sched_entity **se;
struct cfs_rq **cfs_rq;
unsigned long shares;
}//file:include/linux/sched.h
struct task_struct {
...
struct sched_entity se;
}不管 sched_entity 是对应的进程也好,还是容器也罢,都会包含一个虚拟运行时间 vruntime 字段,和一个用来存权重数据的 load 字段。
在进程调度的过程中,每个逻辑核上有一个定时器,节拍性地触发调度从红黑树上判断是否要用最左侧调度实体替换调当前正在运行的进程。在选择进程进行切换时,虽然都多种策略,但最核心的是要保持所有调度实体的 vruntime 的公平。换句话说,不管 Linux 系统上有多少个使用完全公平调度器的进程(使用实时调度策略的进程除外),他们最终的 vruntime 基本会保持一致。
二、权重的设置
上节我们讲到完全公平调度器运转是基于 vruntime 的来维持所有调度实体公平地使用 CPU 资源的。但现实情况是,有的服务确实是需要多使用一些CPU 资源,另一些服务只需要少使用一点就可以。例如说某台服务机是云上的一台服务器,有的用户购买了 8 核套餐,有的用户只购买的 1 核。在计算 vruntime 的时候必然需要一些策略。
为了实现这个需求,每个调度实体中的都有一个权重就非常地有用了。
//file:include/linux/sched.h
struct sched_entity {
struct load_weight load;
u64 vruntime;
...
}
struct load_weight {
unsigned long weight;
u32 inv_weight;
};对于普通进程来说,这个权重可以使用 nice 命令来间接地修改。在容器中,在 cgroup v1 下可以通过 cgroupfs 下的 cpu.shares 文件来修改,在cgroup v2 下通过 cpu.weight / cpu.weight.nice 来修改。
在 cgroup v1 中,对 cpu.shares 的修改会执行到 cpu_shares_write_u64 这个函数中。
//file:kernel/sched/core.c
static struct cftype cpu_legacy_files[] = {
{
.name = "shares",
.read_u64 = cpu_shares_read_u64,
.write_u64 = cpu_shares_write_u64,
},
...
}在 cgroup v2 中,对 cpu.weight 的修改会执行到 cpu_weight_write_u64 函数中。
//file:kernel/sched/core.c
static struct cftype cpu_files[] = {
{
.name = "weight",
.flags = CFTYPE_NOT_ON_ROOT,
.read_u64 = cpu_weight_read_u64,
.write_u64 = cpu_weight_write_u64,
},
...
}不管是 cgroup v1 修改 cpu.shares 时执行 cpu_shares_write_u64,还是 cgroup v2 修改 cpu.weight 是执行 cpu_weight_write_u64,最终都会调用到 __sched_group_set_shares 来把权重信息 shares 记录到调度实体 se 上去的。
//file:kernel/sched/fair.c
static int __sched_group_set_shares(struct task_group *tg, unsigned long shares)
{
......
tg->shares = shares;
for_each_possible_cpu(i) {
struct sched_entity *se = tg->se[i];
for_each_sched_entity(se)
update_cfs_group(se);
}
}
}具体的设置是在 update_cfs_group 中完成的,它依次调用 reweight_entity、update_load_set 来把权重值记录到调度实体上。这样后面就可以通过调度实体 se->load->weight 找到进程或容器的权重信息了。
//file:kernel/sched/fair.c
static inline void update_load_set(struct load_weight *lw, unsigned long w)
{
lw->weight = w;
lw->inv_weight = 0;
}三、容器 CPU 权重分配实现
完全公平调度器是维持的所有调度实体的 vruntime 的公平。但是 vruntime 会根据权重来进行缩放,vruntime 的实现是 calc_delta_fair 函数。
// file:kernel/sched/fair.c
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
if (unlikely(se->load.weight != NICE_0_LOAD))
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}在这个函数中,NICE_0_LOAD 宏对应的是 1024。如果权重是 1024,那么 vruntime 就正好等于实际运行时间。否则会进入到 __calc_delta 中来根据权重和实际运行时间来折算一个 vruntime 增量来。__calc_delta 函数为了追求极致的性能,实现上比较复杂一些,源码就不给大家展示了。我们只把它用到的缩放算法展示如下:
vruntime = (实际运行时间 * ((NICE_0_LOAD * 2^32) / weight)) >> 32如果权重 weight 较高,那同样的实际运行时间算出来的 vruntime 就会偏小,这样它就会在调度中获得更多的 CPU。如果权重 weight 较低,那算出来的 vruntime 就会比实际运行时间偏大。这样它就会在调度的过程中获得的 CPU 时间就会较少。完全公平调度器就是这样简单地实现了 CPU 资源的按权重分配。
我们再举个例子,假如有一个 8 核的物理上,上面运行着 A 服务、B 服务、C 服务的一些容器。
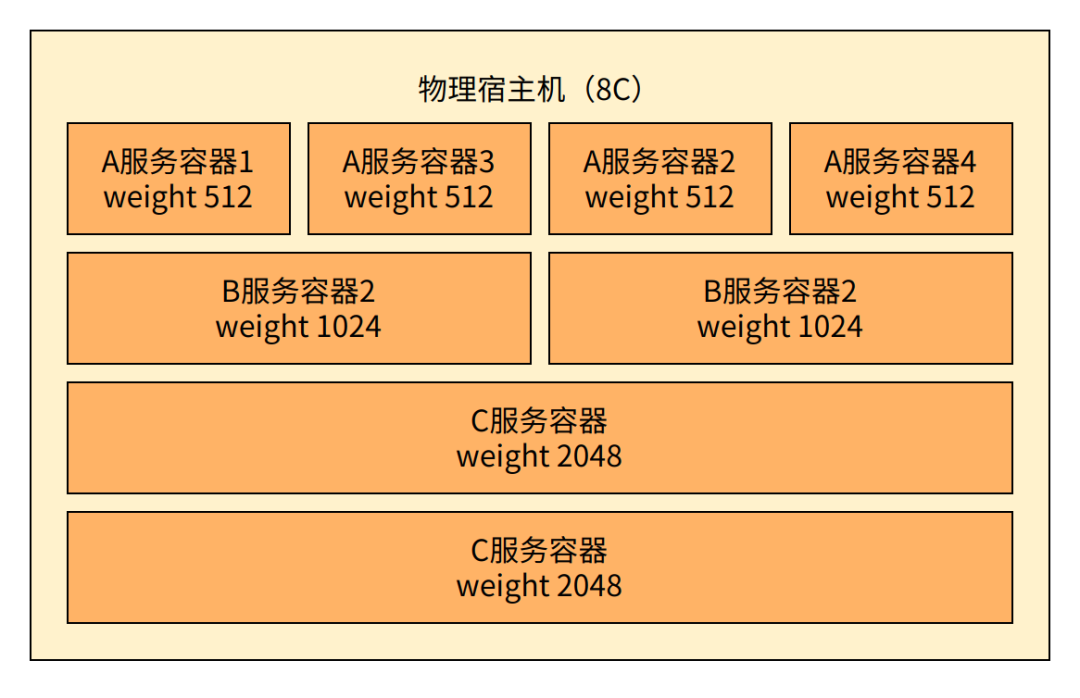
整台机器上所有容器的总权重是 8192。假设这些服务都是从不主动放弃 CPU 资源,则
A 服务一个容器的权重是 512,则它可以分得 512 / 8192 份时间,相当于 0.5 核
B 服务一个容器的权重是 1024,则它可以分得 1024 / 8192 份时间,相当于 1 核
C 服务一个容器的权重是 2048,则它可以分得 2048 / 8192 份时间,相当于 2 核
就这样,Linux 内核又具备了对容器分配CPU资源的第二种能力,按权重分配!


















 556
556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









