



大家好,我是飞哥!
今天我们分享英伟达 GPU 系列的第三篇文章。
在《NVIDIA通用计算首代架构 Tesla 与 CUDA 1.0 剖析》一文中我们提到了英伟达第一代 Tesla G80 通过统一着色架构设计出可编程的流处理器 SP,为通用计算奠定了基础。
在《聊聊英伟达于2010年发布的第一个完整 GPU 计算架构!》第二代 Fermi 架构 GF100 其中 SP 中的 FP Unit 进行了升级,使之可以高效地计算双精度浮点数 FP 64,并开始将 SP 称之为 CUDA Core。另外也开始支持 ECC DRAM。
到了 2012 年的时候,英伟达又推出了第三代通用计算 GPU。这一代架构同样还是以著名科学家的名字来命名,选用的名字是天文学家、数学家 Kepler。我们来看下这一代的 GPU 都带来了哪些改进。
一、Kepler 架构提升
1.1 制程工艺
英伟达 2006 年 Tesla 架构的 G80 核心采用的是台积电(TSMC) 的 90 nm 工艺。2010 年的 Fermi GF100 采用的是 40 nm 工艺。
到了 2012 年开始的 Kepler,制程工艺又有进一步提升,到了 28 nm。更精细的制程意味着在芯片中可以放入更多的晶体管,设计更多的模块进去。
在第三代 Kepler 架构下有 GK 104、GK110、GK206、GK210 等代号。为了方便描述,我们选择以 GK 110 为例,来看下 Kepler 带来多大的提升。
G80(Tesla,2006) | GT200(Tesla,2008) | GF100(Fermi,2010) | GK110(Kepler,2012) | |
|---|---|---|---|---|
制程工艺 | TSMC 90nm | TSMC 55nm | TSMC 40nm | TSMC 28nm |
晶体管数量 | ~ 7 亿 | ~14 亿 | ~30 亿 | ~71 亿 |
SM 数量 | 16 | 30 | 16 | 15 个SMX |
CUDA核心数 | 128 (8/SM) | 240 (8/SM) | 512 (32/SM) | 2880 (192/SM) |
从上表中可以看出,第三代的 Kepler 架构中,因为制程的提升,晶体管数量进一步提升到了 71 亿。
SM 数量没有太大的变化,GF 110 还是 15 个。但是 SM 内部有了大幅度提升,单 SM CUDA Core 数量从 GF 100 时代的 32 个提升到了 192 个。由于提升幅度巨大,所以英伟达把 GK 110 中的 SM 后面加了个 X,主要是作为一个标识,用于区分不同架构下的流式多处理器。
总体上来看,CUDA 核心数从 GF 100 的 512(32 * 16),直接提升到了 2880(192 * 15)。提升幅度有 5 倍之多。
1.2 外部互联
GPU 在计算的过程中,需要频繁地与主机(CPU)进行数据交互。计算数据需要从主机内存传输到 GPU 显存中进行计算,计算结果又需传回主机。这个交互过程是通过 PCI Express 总线来进行的。
在第二代 Fermi 架构中支持的是 PCI Express 2.0 标准,单向带宽是 5GT/s 。但随着时间推移和技术发展,数据量的爆炸式增长以及对实时性要求的不断提高,PCI Express 2.0 的带宽逐渐难以满足需求。
Kepler 架构支持 PCI Express 3.0 标准,相比 Fermi 架构所支持的标准,PCI Express 3.0 提供了更高的带宽。从而提升整个系统的运行性能。PCI Express 3.0 在 x16 模式下,单向带宽提升到了 8GT/s。这样使得 GPU 能够更快地获取所需数据进行计算,并将计算结果及时返回给主机,从而提升整个系统的运行性能。
到了后面先进的架构,又将会实现对 PCI Express 4.0 等更高版本的支持,这个后面我们再说。
1.3 存储体系
GK 110 的存储体系大体上和上一代保持相同,保持了原来的共享内存、L1缓存、L2缓存、DRAM的存储体系。一个改进点在于新引入了只读数据缓存。
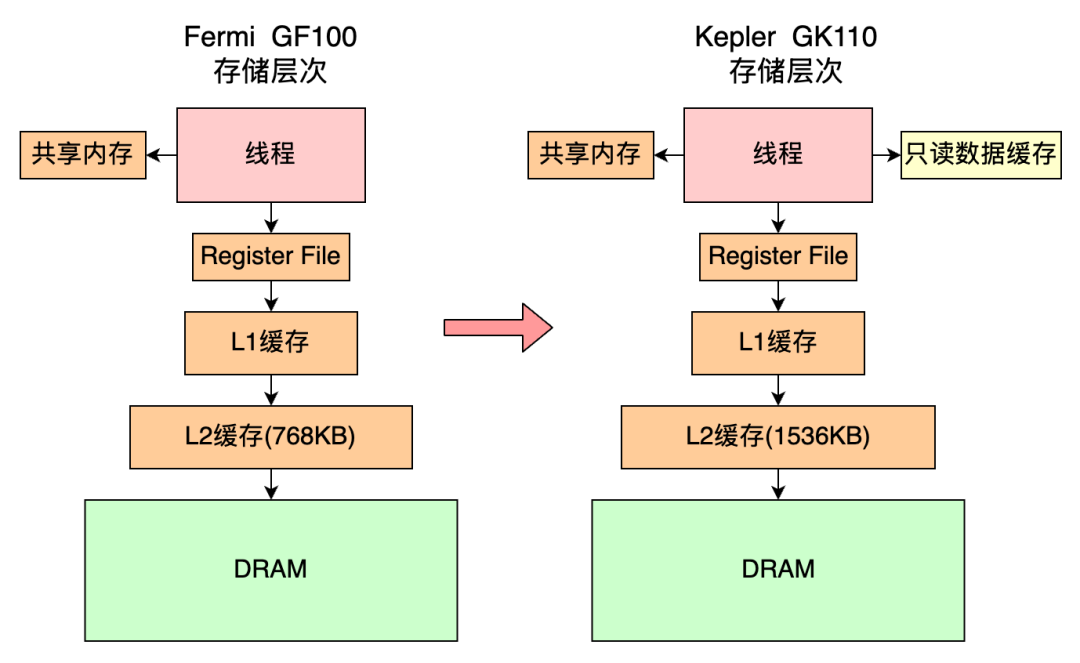
下面是 GK 110 的 Die 结构。 L2 缓存位于芯片中央,用于加速对显存的访问。容量从上一代的 768 KB 提升到了 1536 KB。6 个内存控制器位于芯片的两侧和 DRAM 相连。

上一代 GF 100 一样,在 SMX 内部包含了 64 KB 的共享内存和L1缓存模块。
共享内存/L1缓存模块和上一代 GF 100 一样,是通过配置的方式使用的。
48KB 共享内存 + 16KB L1 缓存
16KB 共享内存 + 48KB L1 缓存
32KB 共享内存 + 32KB L1 缓存 (新增配置方案)
在 Kepler 架构下的一个优化点是增加了 48 KB 的只读数据缓存,用于缓存全局内存中的只读数据,以提高数据读取性能。
1.3 运算单元
在 GPU 中,SM 流多处理器是并行计算的核心。
在 Tesla 架构中,每个 SM 中包含 8 个 SP(相当于后面的 CUDA Core)
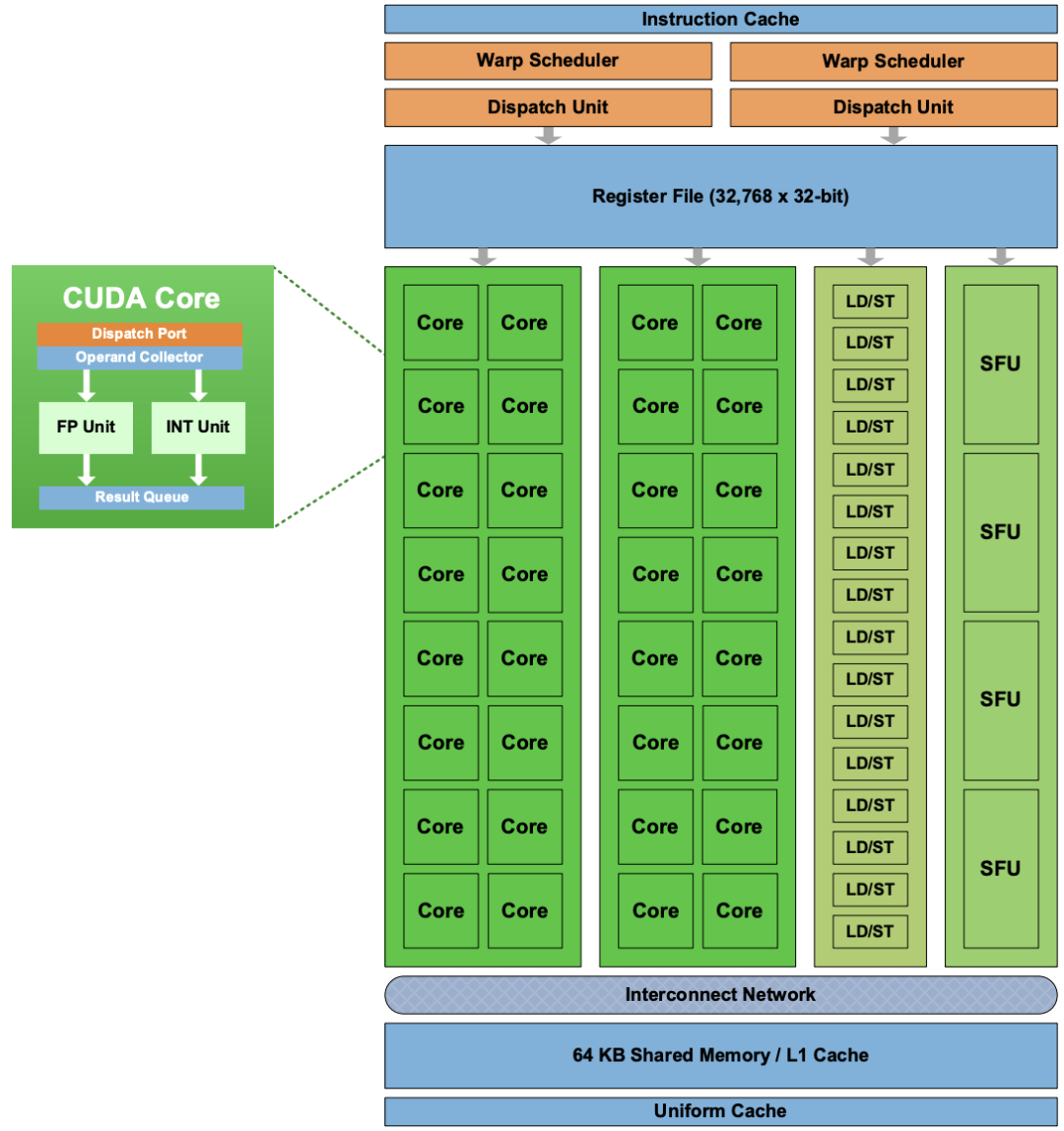
在 Fermi 架构中,每个 SM 中 CUDA Core 的数量提升到了 32 个
下图是我们之前介绍过的 Fermi GF 100 中的 SM 内部结构。
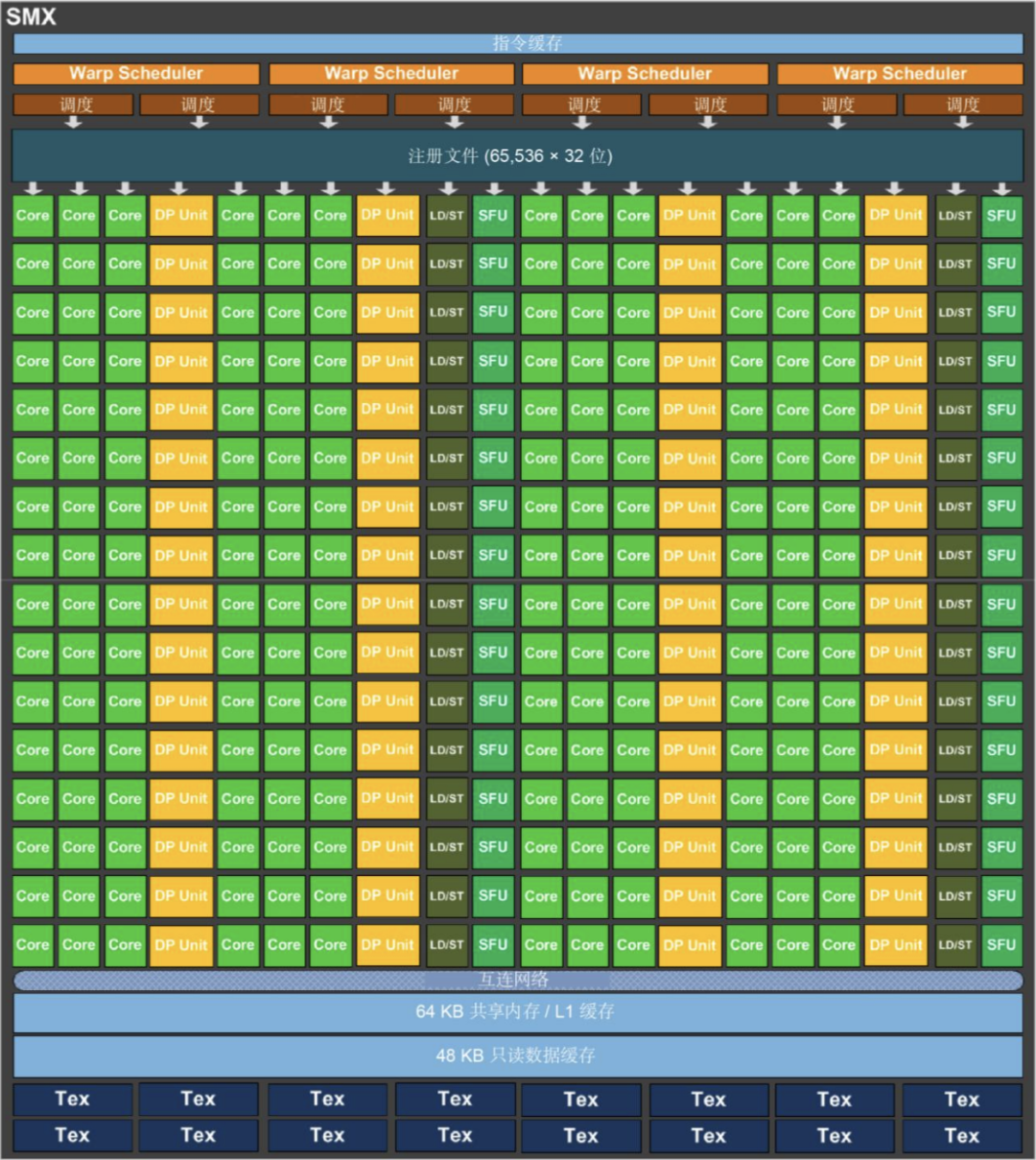
到了 Kepler 架构下,由于制程工艺的提升,一个 SM 中就可以设计装下更多的 CUDA Core 了。以下是 GK 110 中的 SMX 的内部结构。
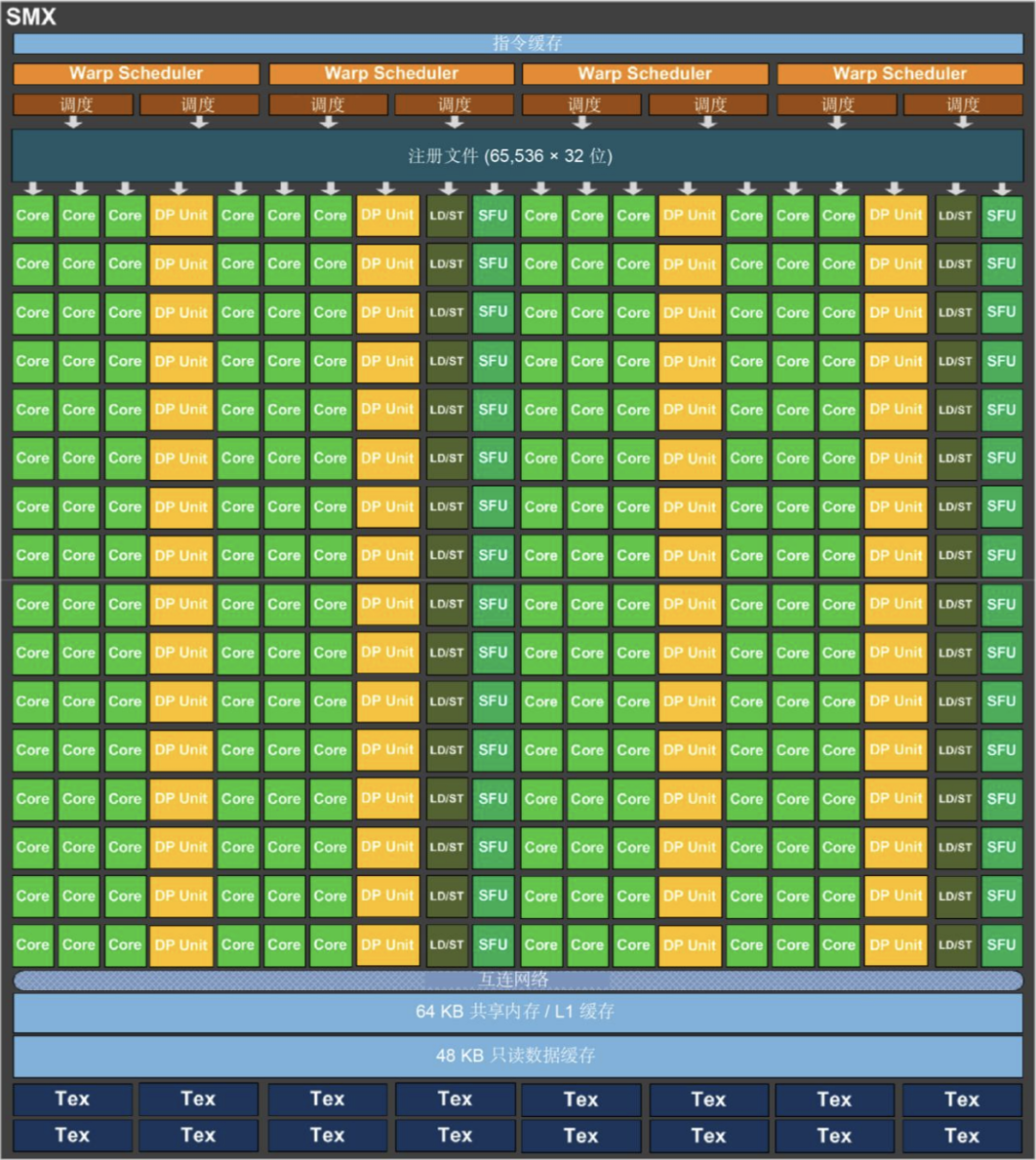
相比上一代的 Fermi 架构的 SM, SMX 的计算能力和访存能力得到了大幅度的提升。在 GK110 的 SMX 中我们可以看到 SMX 中包含有:
192 个单精度计算单元 CUDA 核心
64 个双精度计算单元 DP Unit
32 个超越函数计算单元 SFU
32 个加载 / 存储单元 LD/ST
GK 110 中的 CUDA Core 完全保留 Fermi 引入的 IEEE 754-2008 标准的单精度和双精度算术,包括积和熔加 (FMA) 运算。 在数量提升非常大(32->192),使得并行计算能力大幅度增强。
在 Kepler 之前,Fermi 架构(2010 年)的双精度计算依赖共享资源,缺乏独立的 DPUnit。其每个 SM 单元的双精度运算需通过共享 FP32 核心实现。Kepler 架构通过引入独立的 DPUnit,将双精度计算从共享资源中分离出来,显著提升了效率。在每个 SM 中设计了 64 个双精度 FP64 计算单元 DP Unit。
在每个 SMX 内部的超越函数计算单元 SFU 数量也从上一代的 4 个提升到了 32 个,提升了 8 倍。
1.4 调度能力
由于 CUDA Core 数量增多,所以线程调度能力也得跟上。在调度能力上 Kepler 架构做了两个改进。
第一、更多的 warp 调度器和指令调度单元
所以每个 SMX 拥有四个 warp 调度器和八个指令调度单元,允许同时发出和执行四个 warp,相比 Fermi 架构的两个 warp 调度器和两个指令调度单元,指令执行的并行度更高。
这种优化使得 SMX 在处理复杂指令流时更加高效,能够充分发挥出众多 CUDA 核心的计算能力,避免了指令执行的延迟和等待。
第二、Hyper -Q 技术引入
在以前的架构中,CPU 与 GPU 之间通常只有一个工作队列,这容易导致任务阻塞,使得 GPU 不能充分发挥性能。
而 Hyper - Q 技术在主机与 GPU 之间提供了 32 个硬件工作队列。多个 CPU 核心可以分别将任务发送到不同的队列,从而让 GPU 能够同时处理来自多个 CPU 核心的工作请求,减少任务在队列中阻塞的可能性,实现多个内核的并发执行。
Hyper - Q 技术的引入多个 CPU 核可同时向 GPU 发送工作指令,使 GPU 有更多机会处于忙碌状态,避免因等待 CPU 任务而闲置,充分发挥其并行计算能力
二、Tesla K20X 算力
前面我们看到,Kepler 架构中的 CUDA 核数得到了非常大的提升,那么我们找一款具体的产品 Tesla K20X 来看下它的算力情况究竟怎么样。
2.1 FP32算力
FP32 峰值算力公式如下:
FP32 算力 = 核心频率 × CUDA核数量 × 每个时钟周期执行的操作数我们找到 Tesla K20X 的核工作频率是 732 MHz。
该芯片中实际启用的 SM 数量是 14 个,总共 CUDA 核数是 2688 个。每个 CUDA 核每个时钟周期一次 FMA 操作算两次 FP32 运算。
所以,我们可以算得 Tesla K20X 的 FP32 峰值算力是
FP32 算力 = 核心频率 × CUDA核数量 × 每个时钟周期执行的操作数
= 0.732 GHz * 2688 * 2
= 3935.232 GFLOPS
= 3.935 TFLOPS回想前面的分享中
基于 Tesla G80 的 GeForce 8800 Ultra FP32 算力 387.1 GFLOPS
Fermi 架构下的 M2070 的 FP32 算力是 1,030.4 GFLOPS
在 Kepler 架构下,由于CUDA 核数的大幅度提升,使得 GPU 的峰值算力又翻了 3 倍还多,达到了 3.935 TFLOPS。
2.2 FP64算力
Kepler 架构(GK110)的 SMX 单元中,双精度浮点(FP64)单元与单精度(FP32)单元的硬件配置比例为 1:3(每 3 个 FP32 核心对应 1 个 FP64 核心)。每个 SM 中包含的 DP Unit 的数量是 64 个
Tesla K20X 的芯片中实际启用的 SM 数量是 14 个,所以其用于计算 FP64 的 DP Unit 总量是 = 14 * 64 = 896 个。
那么 Tesla K20X 的 FP64 运算峰值算力是
FP64 算力 = 核心频率 × 核心数量 × 每个时钟周期执行的操作数
= 0.732 GHz * 896 * 2
= 1311.744 GFLOPS显存带宽
在 Kepler 架构中,虽然仍然采用的是 GDDR5 代内存,但是采用的内存工作频率有了极大的提升。在 Fermi 的 M2070 中的 783 MHz 提升到了1300 MHz。所以存储的有效数据频率也从 3.1 Gbps 提升到了 5.2 Gbps。
所以 Tesla K20X 的内存带宽提升到了 249.6 GB/s。
内存带宽 = 内存位宽 * 数据频率 / 8(换算成字节数)
= 384 bit * 5.2 Gbps / 8
= 249.6 GB/s总结
好了,我们来总结下今天的分享。英伟达 Kepler 架构 GPU 相较于前代的显著进步,具体体现在如下几个方面
制程工艺上,从 Fermi 架构的 40nm 升级到 28nm,以 GK110 为例,晶体管数量提升至 71 亿。
外部互联方面,支持 PCI Express 3.0 标准,x16 模式下单向带宽从 5GT/s 提升到 8GT/s,加快数据传输。
存储体系中,GK110 的 L2 缓存容量翻倍至 1536KB,SMX 内新增 48KB 只读数据缓存,共享内存 / L1 缓存模块增加新配置方案。
运算单元上,SMX 包含 192 个单精度 CUDA 核心等多种单元,相比前代计算与访存能力大幅增强,指令执行并行度更高。单独提供了用于 FP64 计算的 DP Unit 单元。整体上FP32 和 FP64 运算能力显著提升。
调度能力上,通过增加warp 调度器和指令调度单元和引入 Hyper - Q 技术,通过 32 个硬件工作队列减少 CPU 与 GPU 间任务阻塞,提升 GPU 利用率与并行计算能力
在算力上,相比较上一代的 Fermi 架构 FP32 算力从 1.03 TFLOPS 提升到了 3.935 TFLOPS。显存带宽从 148.8 GB/s 提升到了 249.6 GB/s。
下一篇中,飞哥将给大家介绍英伟达的 Maxwell 架构,敬请期待!!


















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









