



大家好,我是飞哥!
现在业界基本都在大规模地使用容器云了。绝大部分的云厂商,甚至可能包括你自己公司的内部云,一般都会“超售”。所谓“超售”就是将一台物理机售卖出超过自己本身核数。比如将一台拥有 100 核的物理机卖出 150 核容器。
这种超售虽然大部分情况下不影响你业务的运行,但是某些情况下却是你程序运行性能低下,甚至 SLA 稳定性出问题的元凶。所以作为开发的我们,理应对这种超售原理有深入的理解。这样才能知道自己的服务什么时候能获得 CPU 资源。
K8s 对容器进行 CPU 资源售卖是通过 CPU Limits 与 Requests 这两个参数配置的。单纯地从这两个单词的字面含义来很难对这两个字段理解清楚。我本人在刚接触到这两个概念之后很长的一段时间里都是一头雾水,直到我看了内核相关的源码后才真正理解。
在前面我铺垫了两篇文章,分别是 内核是如何给容器中的进程分配CPU资源的? 和 聊聊 Linux 分配 CPU 资源的第二种能力,对各个容器按照权重进行分配! 。这两篇文章介绍了内核中相关的 CPU 资源分配管控机制。
K8s 就是基于上述两种内核机制来实现超售的。今天飞哥再从 K8s 视角来带大家整体理解一下“超售”原理。
学习完本文,你也将能对以下三个问题有深入的理解。
为什么 K8s 需要同时用两个字段来限制 CPU 的使用 ?
假如我们申请了一个 8 核的容器,那 8 核指的到底是啥?
如果你是容器云的 SRE 需要配置超卖,你应该如何设置 requests.cpu 和 limits.cpu?
让我们带着疑问来进入今天的分享!对了,还没关注【开发内功修炼】公众号的同学一定要关注一下!
一、容器云技术栈
目前主流的容器编排调度是 Kubernetes,又称 K8s。K8s 支持包括 Docker 在内的各种容器引擎。
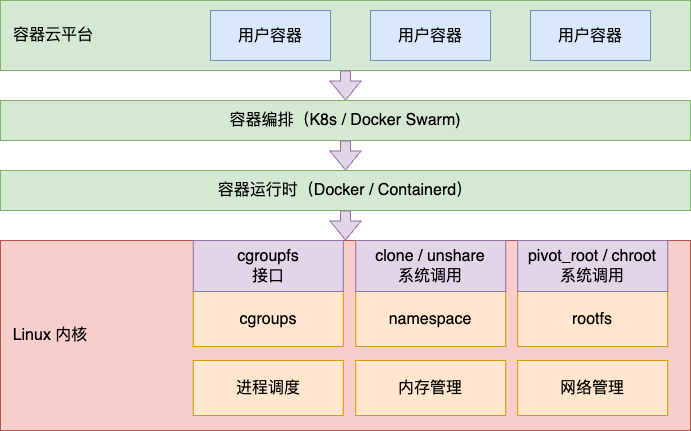
而这个技术栈的根源还是源自于 Linux 操作系统底层的 cgroups、 namespace 和 rootfs 等模块的支持。其中在对容器的 CPU 资源限制上,是通过 cgroups 来实现的。所以要探索 Limits 和 Requests 还要从 Linux 底层的控制组 cgroups 说起。
二、容器 CPU 资源控制
2.1 容器 CPU 带宽限制
Linux 内核在 cgroups 中包括了对 CPU、内存等多种资源限制的控制组。其中对 CPU 资源进行限制的是 cpu cgroup 来实现的。其中第一种限制方式是对 cgroup 可使用的 CPU 资源进行上限限制。
这种资源限制是通过 cgroupfs 进行配置的。比如以 cgroup v1 为例,想实现让某个进程只使用两个核,我们可以通过 cgroupfs 接口这样来实现,如下:
# cd /sys/fs/cgroup/cpu,cpuacct
# mkdir test
# cd test
# echo 100000 > cpu.cfs_period_us // 100ms
# echo 200000 > cpu.cfs_quota_us //200ms
# echo {$pid} > cgroup.procs其中 cfs_period_us 用来配置时间周期长度,cfs_quota_us 用来配置当前 cgroup 在设置的周期长度内所能使用的 CPU 时间。这两个文件配合起来就可以设置 CPU 的使用上限。
上面的配置就是设置改 cgroup 下的进程每 100 ms 内只能使用 200 ms 的 CPU 周期,也就是说限制使用最多两个“核”。 要注意的是这种方式只限制的是 CPU 使用时间,具体调度的时候是可能会调度到任意 CPU 上执行的。如果想限制进程使用的 CPU 核,可以使用 cpuset 子系统。
Linux 内核在调度器工作的时候,会通过定时器来周期性地给所有的容器发放可运行的 CPU 时间,这个时间会记录到控制组内核对象 task_group 下的 cfs_b->runtime 字段中。负责给 task_group 分配运行时间的定时器包括两个,一个是 period_timer,另一个是 slack_timer。 简单起见,我们只看 period_timer。
在 period_timer 的回调函数 sched_cfs_period_timer 中,周期性地为任务组分配带宽时间,并且解挂当前任务组中所有挂起的队列。分配带宽时间是在 __refill_cfs_bandwidth_runtime 中执行的,它的调用堆栈如下。
sched_cfs_period_timer
->do_sched_cfs_period_timer
->__refill_cfs_bandwidth_runtime来看它的源码。
//file:kernel/sched/fair.c
void __refill_cfs_bandwidth_runtime(struct cfs_bandwidth *cfs_b)
{
if (cfs_b->quota != RUNTIME_INF)
cfs_b->runtime = cfs_b->quota;
}可见,这里直接给 cfs_b->runtime 增加了 cfs_b->quota 这么多的时间。其中 cfs_b->quota 你就可以认为是在 cgroupfs 目录下,我们配置的值。
回顾我们上面的例子,就是每隔 100 ms 给分配 200 ms 的可运行时间。总之就是,每隔 period 这么长时间会分配 quota 这么多的可用时间。
# echo 100000 > cpu.cfs_period_us // 100ms
# echo 200000 > cpu.cfs_quota_us //200ms在内核进行进程调度的时候,会在运行队列上记录已经给容器分配的 CPU 时间,会更新 cfs_rq 队列中的 runtime_remaining。
//file:kernel/sched/fair.c
static void update_curr(struct cfs_rq *cfs_rq)
{
//计算一下运行了多久
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
delta_exec = now - curr->exec_start;
...
//更新带宽限制
account_cfs_rq_runtime(cfs_rq, delta_exec);
}先计算当前执行了多少时间。然后在 cfs_rq 的 runtime_remaining 减去该时间值。如果相减后发现是负数,表示当前 cfs_rq 的时间余额已经耗尽,则会立即尝试从容器任务组中申请。
这里要注意的是一个容器 task_group 只有一个内核对象,但是有多少个逻辑核就会有多少个 cfs_rq。
前面我们说过整个 task_group 下可用的时间是保存在 cfs_b->runtime 下的。容器运行队列 cfs_rq 会在 __assign_cfs_rq_runtime 下会向容器组申请可运行时间。
//file:kernel/sched/fair.c
staticint __assign_cfs_rq_runtime(struct cfs_bandwidth *cfs_b,
struct cfs_rq *cfs_rq, u64 target_runtime)
{
// 申请时间数量
min_amount = target_runtime - cfs_rq->runtime_remaining;
// 如果没有限制,则要多少给多少
if (cfs_b->quota == RUNTIME_INF)
amount = min_amount;
else {
// 如果本周期内还有时间,则可以分配
if (cfs_b->runtime > 0) {
// 确保不要透支
amount = min(cfs_b->runtime, min_amount);
cfs_b->runtime -= amount;
cfs_b->idle = 0;
}
}
cfs_rq->runtime_remaining += amount;
return cfs_rq->runtime_remaining > 0;
}如果申请时间失败的话,会触发 throttle 限流。
// file: kernel/sched/fair.c
static bool check_cfs_rq_runtime(struct cfs_rq *cfs_rq)
{
// 判断是不是时间余额已用尽
if (likely(!cfs_rq->runtime_enabled || cfs_rq->runtime_remaining > 0))
returnfalse;
...
throttle_cfs_rq(cfs_rq);
returntrue;
}throttle 限流的实现过程是把当前容器 task_group 在所有的运行队列中把红黑树节点都删掉。这样在直到下一次分配运行时间之前,容器中的所有进程都不会再得到 CPU 资源来运行了。
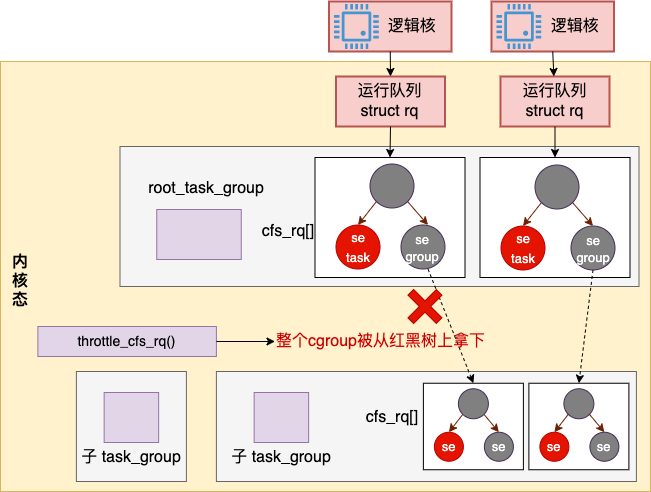
2.2 容器 CPU 权重分配
Linux 内核还有第二个对容器 CPU 资源进行分配的策略,那就是按权重分配。
这个容器权重,在 cgroup v1 下可以通过 cgroupfs 下的 cpu.shares 文件来修改,在cgroup v2 下通过 cpu.weight / cpu.weight.nice 来修改。
不管是 cgroup v1 还是 cgroup v2,在内核中执行的最后逻辑都是把权重记录到控制组 task_group 下调度实体中相关的权重字段上了。
//file:kernel/sched/sched.h
struct task_group {
...
struct sched_entity **se;
struct cfs_rq **cfs_rq;
unsigned long shares;
}一个容器 task_group 会有多个调度实体对象。这是因为容器要在多个逻辑核上参与调度。调度实体 struct sched_entity 中包含了权重字段。
//file:include/linux/sched.h
struct sched_entity {
struct load_weight load;
...
}
struct load_weight {
unsigned long weight;
};调度器在运行的时候,会保证所有的调度实体的 vruntime 是完全公平的。但是 vruntime 在计算的时候,会根据每个容器的 weight 不同来进行缩放。
vruntime = (实际运行时间 * ((NICE_0_LOAD * 2^32) / weight)) >> 32如果权重 weight 较高,那同样的实际运行时间算出来的 vruntime 就会偏小,这样它就会在调度中获得更多的CPU。如果权重 weight 较低,那算出来的 vruntime 就会比实际运行时间偏大。这样它就会在调度的过程中获得的 CPU 资源就会较少。这样,完全公平调度器就实现了按权重值为比例对所有的容器分配 CPU 资源的效果。
举个例子,假如有一个 8 核的物理上,上面运行着 A 服务、B 服务、C 服务的一些容器。
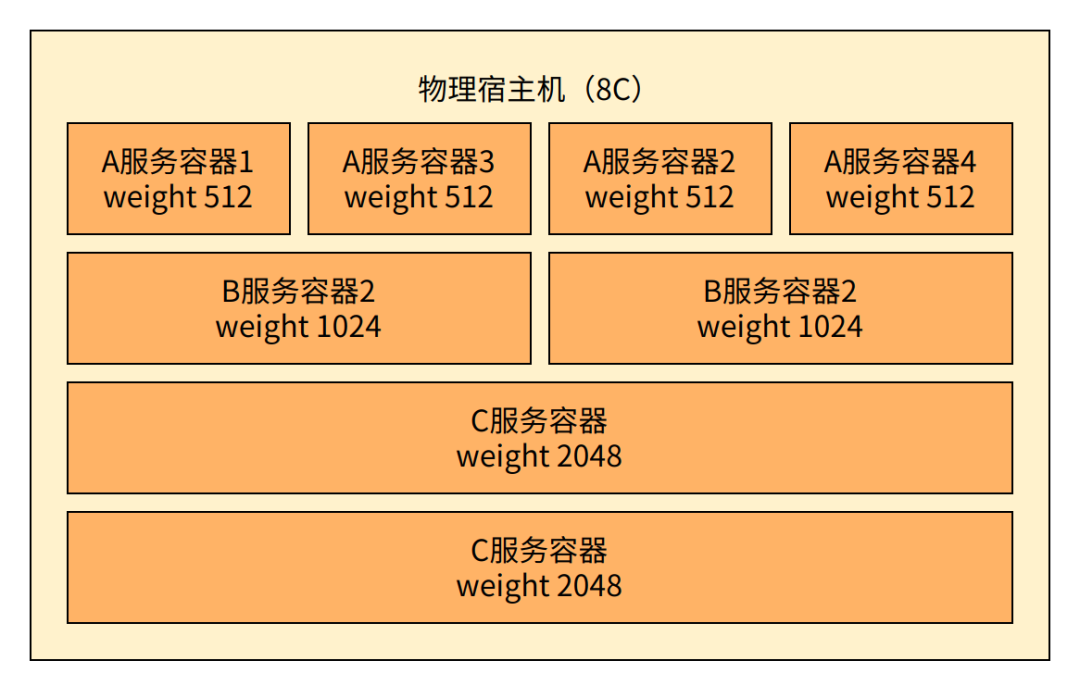
整台机器上所有容器的总权重是 8192。假设这些服务都是从不主动放弃 CPU 资源,则
A 服务一个容器的权重是 512,则它可以分得 512 / 8192 份时间,相当于 0.5 核
B 服务一个容器的权重是 1024,则它可以分得 1024 / 8192 份时间,相当于 1 核
C 服务一个容器的权重是 2048,则它可以分得 2048 / 8192 份时间,相当于 2 核
三、K8s 中的 Requests 和 Limits 语义
例如在 K8s 中使用原生的 kubectl 创建一个容器的时候,其 yaml 定义的一个例子如下。
apiVersion: v1
kind: Pod
metadata:
name: cpu-demo
namespace: cpu-example
spec:
containers:
- name: cpu-demo-ctr
image: vish/stress
resources:
limits:
cpu: "1"
requests:
cpu: "0.5"其中 limits 在底层使用的是 cgroup的 period + quota 来进行使用时限制。这个限制的语义是限制容器最多只能使用这么多的 CPU 时间,是一个最大值。另外 K8s 在进行编排调度的时候,不会对一个节点上所有容器的 sum(limits) 做任何限制。总的 limits 可能会超过逻辑核数量,也就是我们常说的超售。
requests 在底层使用的是 cgroup 的 weight,强调的是按权重比例来进行分配。K8s 在创建容器的时候,会将用户输入的 requests 核数转化成相应的权重值。在 cgroup v1 下,每 1 核对应的权重是 1024,在 cgroup v2 下每一核对应的权重值大约是 39。然后把计算出来的权重通过 cpu.shares 或 cpu.weight 文件接口来设置到内核中。
另外 K8s 在进行编排调度的时候,会保证一个节点上所有容器的 sum(requests) 不会超过总的逻辑核数。相当于给容器了一个最低保障,不管宿主机 CPU 使用有多繁忙。用户指定的 requests 对应的核数是能够保障的。如果说同一个宿主机上的其他容器不使用 CPU 资源的时候,那么容器使用的 CPU 资源就可以超过 requests 指定的数量。
所以汇总来说,容器在宿主机上可使用的 CPU 资源其实一个区间 [requests, limits]。
容器在物理机上申请的 requests 是个下限制,不管宿主机多忙,这个核数是有保证的
如果宿主机比较空闲,那么容器实际使用的 CPU 资源可以超过 requests 对应的核数。但是最大也不能突破 limits。
这就是 K8s 中 requests 和 limits 的底层语义。我们举一个例子,假如有一个 8 核的物理机,它上面部署了 4 个容器。为了简单期间,我们假设这四个容器的规格都一样。
request 是 2 核,通过 cpu.shares 设置权重值为 2048 来实现
limits 是 3 核,通过设置 period 为 100 ms、quota 为 300 ms 来实现
前面我们说过 k8s 在编排调度时会保证 sum(requests) 不超过总逻辑核,但 sum(limits) 是被无视的。所以这台宿主机的 sum(requests) 已经达到了最大的 8 核,此时的 sum(limits) 已经高达 12 核。

这样每个容器可以使用的 CPU 资源范围是个区间,是[2,3]。不管物理机多忙,每个容器分配的两核的时间是可以保证的。如果其它进程没有使用 CPU 的时候,由于竞争者变少,所以容器可以使用超过 2 核的时间,但最大也不能超过 3 核。
四、总结
在本文我们深入介绍了 K8s 中 requests 和 limits 的底层实现原理。我们此时再回头来看开篇我们提到的 3 个问题。
1)为什么K8s 需要同时用两个字段来限制 CPU 的使用 ?
这是为了能更高效地分配物理机上的 CPU 资源。 1)limits 设置的是容器可用的资源上限。定义的是一个容器最多可以使用的 CPU 资源。这样可以避免个别容器过度侵占宿主机上的资源。 2)requests 按照权重的方式进行分配。一般来说售卖时保证总的 request 核数不超过实际核数。K8s 下 request 核数是有保证的,无论宿主机多忙都能获得这么多 CPU 资源。
这两个字段搭配来使用,可以实现超售。比如在一个 8 核的物理机,它上面售卖了 4 个容器。

每个容器的 limit 都是 3 核。这样整体上就卖出去了 12 核。另外 request 中的 2 核由于只是一个权重的概念。如果宿主机的其它容器不忙,当前容器使用的资源确实是可以使用超过 requests 的这个 2 的限制的。只要不是所有的容器都在大量使用 CPU,那么单个容器视角看起来就真的能使用到 3 核。
从物理机的视角来看,CPU 资源就可以被使用的更充分。不会因为某些容器闲置而导致浪费。
2)假如我们申请了一个 8 核的容器,那 8 核指的到底是啥?
首先我们容器视角看到的几核,一般都指的是 K8s 中的 limits 定义。我们使用的 8 核的容器,一般就是它的 resources.limits.cpu 被设置成了 8 核。(当然,如果你的容器云没超售的话,requests 也是 8)。requests 一般是对用户不可见的。
但是为了避免新读者误会,还是要提一下的是,Linux 内核中并不会真的给我们的容器分配 8 个核出来。而是在调度器调用的时候给我们分配等量的 CPU 运行时间。至于是在哪个核上运行的,Linux 并不会保证。
3)如果你是容器云的 SRE 需要配置超卖,你应该如何设置 requests.cpu 和 limits.cpu?
学习完本文,这个问题我想非常的简单了。你一般只需要保证当前这台物理机上售卖出去的 requests 之和不超过该机的核数就行。
至于用户可见的 limits,理论上来说,你想设置多大都可以。但一般你还是需要凭良心设置一个合理的系数。比如超卖率是 1.5 倍,你把 limits 设置成该容器的 requests * 1.5 就行。
操作上来讲,就是设置 K8s 接口中的如下两个字段。
apiVersion: v1
kind: Pod
metadata:
name: cpu-demo
namespace: cpu-example
spec:
containers:
- name: cpu-demo-ctr
image: vish/stress
resources:
limits:
cpu: "12"
requests:
cpu: "8"上面就是一个用户视角看起来是 12 核的容器,但实际内部是 1.5 倍的超售。
最后,如果你作为用户看到你的容器被超卖了,也不用紧张。只要你的邻居不和你同时抢用 CPU,你是真的能用到 limits 对应的核的。但万一如果真出现了邻居和你同时抢用 CPU 的情况,从你的视角来看就是容器 CPU 利用率并不高,但是 SLA 出问题了。这时候你就该去和你的容器云厂商 PK 去了!


















 1375
1375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









