



前言
pytorch是一个深度学习的框架,里面主要集成了深度学习的常用的函数,主要的数据结构为tensor(张量)。张量和矩阵不一样,矩阵都是二维的,张量可以表示任意维度,0维度就是一个标量。
-
0阶张量:标量(单个数字,如
3.14) -
1阶张量:向量(一维数组,如
[1, 2, 3]) -
2阶张量:矩阵(二维数组,如
[[1, 2], [3, 4]]) -
更高阶:三维及以上数组(如RGB图像是3阶张量,形状为
[高度, 宽度, 通道])
示例
1、 新建工程,创建虚拟环境(pytorch),选择python解释器。
如果新建工程时,忘记建立环境,选择 文件-设置-项目名-添加解释器
2 、工程名右键新建-python文件,新建一个py文件
import torch # 创建一个张量 x = torch.tensor([1.0, 2.0, 3.0]) y = torch.tensor([4.0, 5.0, 6.0]) # 张量加法 z = x + y print(z)
3 、环境中没有torch,安装pytorch
在pycharm左下角,点击终端按钮,打开终端,先conda进入新建得虚拟环境,然后输入
(pytorch) PS F:\pytorch> pip install torch torchvision torchaudio
等待下载完成后,上面的torch就可以导入了。
4 、走一个简单的神经网络示例(从网上下载的)
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
# 1. 生成模拟数据
torch.manual_seed(42) # 固定随机种子(确保可重复性)
# 创建两类数据点(二维特征)
num_samples = 100
X = torch.randn(num_samples, 2) # 100个样本,每个样本2个特征 ,x为100个1阶张量,100个一维数组,每个数组两个成员
y = (X[:, 0] + X[:, 1] > 0).float() # 简单线性边界划分两类(0或1),必须转float,这个是作为结果和神经网络的输出做比较求 损失函数,要求必须是float
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='bwr') #散点图查看x分布
plt.show()
# 2. 定义神经网络模型
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(2, 4) # 输入层(2维)→ 隐藏层(4维),输入层的2 必须和特征数对应,
self.fc2 = nn.Linear(4, 1) # 隐藏层 → 输出层(1维,二分类)
self.sigmoid = nn.Sigmoid() # 输出层激活函数(将值映射到0~1)
def forward(self, x):
x = torch.relu(self.fc1(x)) # 隐藏层用ReLU激活
x = self.sigmoid(self.fc2(x))
return x
model = SimpleNN()
# 3. 定义损失函数和优化器
criterion = nn.BCELoss() # 二分类交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.1) # 优化器:随机梯度下降
# 4. 训练模型
epochs = 500
losses = []
for epoch in range(epochs):
# 前向传播
outputs = model(X)
loss = criterion(outputs.squeeze(), y) # 计算损失
# 反向传播和优化
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 更新权重
losses.append(loss.item())
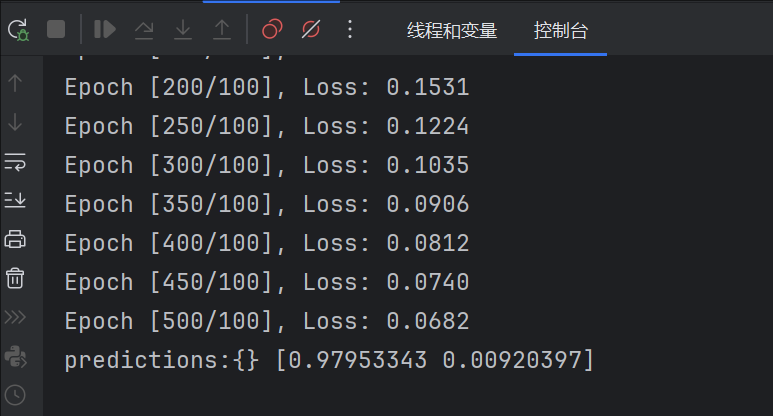
if (epoch + 1) % 50 == 0:
print(f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}')
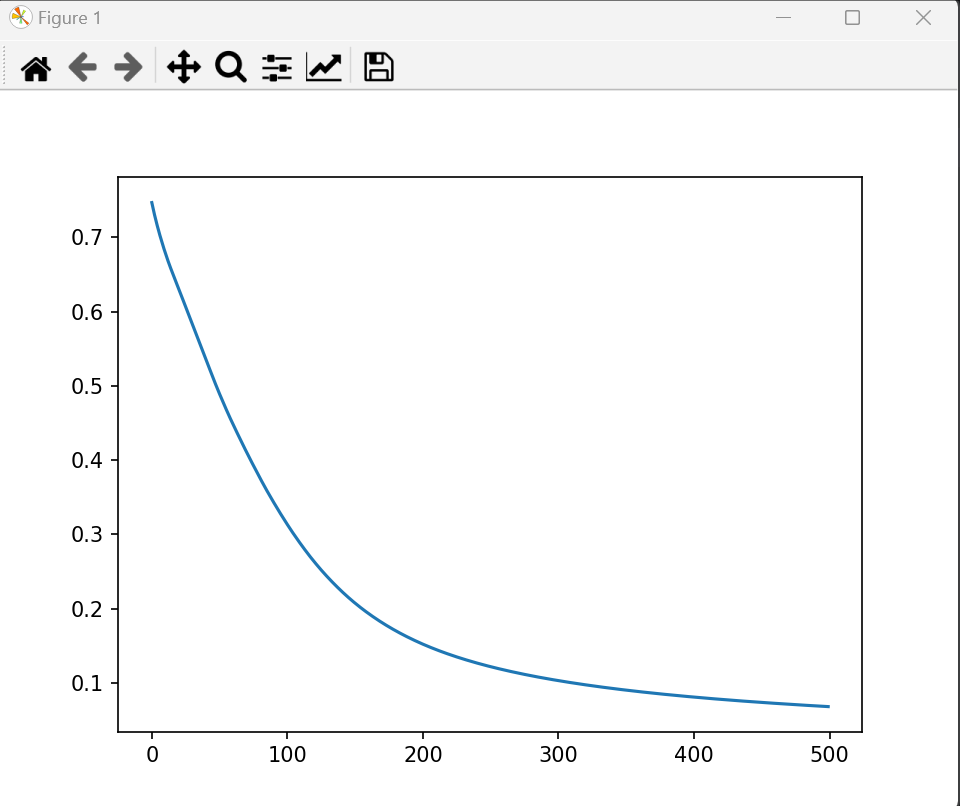
# 5. 可视化训练过程
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.show()
# 6. 测试模型
with torch.no_grad(): # 关闭梯度计算(测试阶段)
test_data = torch.tensor([[0.5, 0.1], [-0.1, -0.5]]) # 两个测试点
predictions = model(test_data)
print(f"Predictions: {predictions.squeeze().numpy()}") # 输出概率值
torch函数
1、randn :num_samples行2列的张量。常用:行数为样本数,列数为特征数,0-1之间,符合正太分布,均值为0
num_samples = 100 X = torch.randn(num_samples, 2) # 100个样本,每个样本2个特征
运行中错误
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
在代码开头添加以下环境变量设置,强制使用单个 OpenMP 实例:
python
import os os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # 允许重复加载 OpenMP 库
神经网络基础知识
1、损失函数
样本的预测目标为yp,真实目标为y。那么,定义一个值loss,计算公式如下。
损失函数 loss = (yp - y)2
通过研究发现,在参数数量一样的情况下,更深的网络往往具有比浅层的网络更好的识别效率。
2、Sigmoid 函数(S型函数)是一类具有 S形曲线 的数学函数,常用于将实数映射到 (0,1) 区间,在机器学习、神经网络和逻辑回归中广泛应用。
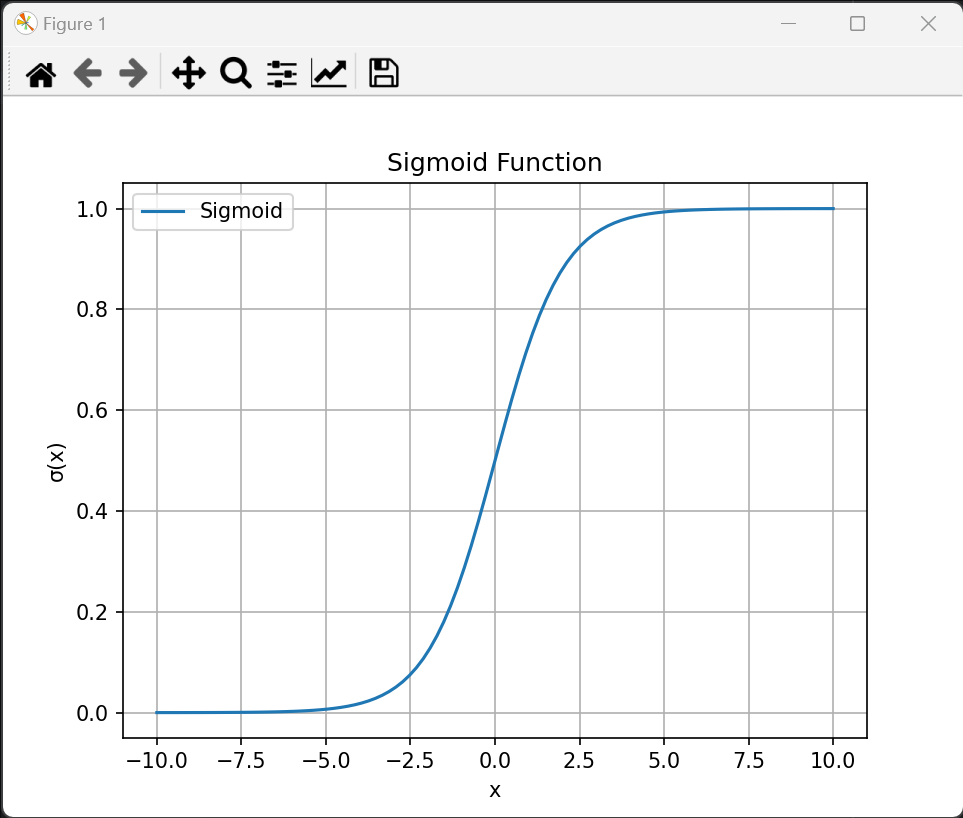
在单层神经网络时,我们使用的激活函数是sgn函数。到了两层神经网络时,我们使用的最多的是sigmoid函数。而到了多层神经网络时,通过一系列的研究发现,ReLU函数在训练多层神经网络时,更容易收敛,并且预测性能更好。因此,目前在深度学习中,最流行的非线性函数是ReLU函数。
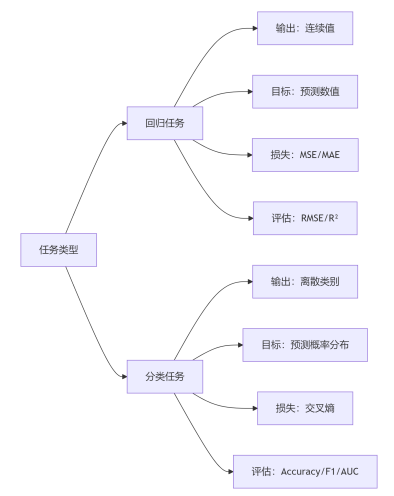
3、回归预测“多少”,分类判断“是否” —— 连续值是回归的战场,离散类别是分类的舞台!
4、sklearn库
scikit-learn(简称 sklearn)是 Python 中最流行、最强大的机器学习库之一,主要用于传统机器学习(非深度学习)任务。它提供了丰富的工具,涵盖数据预处理、特征工程、模型训练、评估和模型选择等整个机器学习流程。
sklearn 与深度学习框架的区别
| 特性 | scikit-learn (sklearn) | PyTorch/TensorFlow |
|---|---|---|
| 主要领域 | 传统机器学习(浅层模型) | 深度学习(神经网络) |
| GPU 支持 | 不支持 | 支持 |
| 自动求导 | 不支持 | 支持(如 autograd) |
| 适用场景 | 小规模结构化数据 | 大规模非结构化数据(图像、文本等) |
何时选择 sklearn?
-
数据是结构化表格(如 CSV)。
-
需要快速实现经典算法(如随机森林、SVM)。
-
数据量适中(内存可加载)。
-
不需要深度学习(如 CNN、RNN)。
如果任务涉及图像、文本、时序数据或需要 GPU 加速,建议转向 PyTorch/TensorFlow。
安装命令 :pip install scikit-learn


















 8651
8651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









