






1、自然语言处理
一门计算机科学、人工智能以及语言学的交叉学科。虽然语言只是人工智能的一部分(人工智能还包括计算机视觉等),但它是非常独特的一部分。这个星球上有许多生物拥有超过人类的视觉系统,但只有人类才拥有这么高级的语言。
自然语言处理的目标是让计算机处理或说“理解”自然语言,来完成有意义的任务,比如订机票、购物或QA等。完全理解和表达语言是极其困难的,完美的语言理解等效于实现人工智能。
2.如何表达一个词得意思

3.如何在计算机中得到一个可用得词
3.1WordNet
一个包含同义词(synonym)和上下位词(hypernym)列表的词典。
代码:调用wordnet
from nltk.corpus import wordnet as wnlemma 词根
synonym 同义词
hypernym 上位词
hyponym 下位词
poses = {'n':'noun','v':'verb','s':'adj(s)', 'a':'adj', 'r':'adv'}
for synset in wn.synsets('good'):
print('{}:{}'.format(poses[synset.pos()], ','.join([l.name() for l in synset.lemmas()])))synsets()查看一个单词的同义词集合,synonym sets
pos()查看单词的词性,可以为(n|v|s|a|r),分别表示(名词|动词|形容词|副词)
hypernyms()查看单词的上位词
一个 synset 被一个三元组描述:(单词.词性.序号)
如 ’dog.n.01’ 指:dog 的第一个名词意思;’chase.v.01’ 指:chase 的第一个动词意思。

3.2wordnet存在的问题
(1)缺少细微差别
如:proficient与good是同义词,这只是在某些特定的上下文关系中成立。
(2)缺少单词的新含义
某些词会在上下文中有新的含义
(3)依靠经验
(4)需要人力劳动来创造和适应
(5)不能准确计算单词相似度
3.3用离散符号表示词
(1)one—hot
用R∣V∣×1{R}^{|V| \times 1}R∣V∣×1 维度的词向量代表每个单词,词向量只由 0 和 1 表示,给出一个很大的词汇表 V,词汇表中的单词是排序的,然后用这个词汇表中的序号代表每个单词中 1 出现的位置。

向量维数=词汇表中单词的数量
缺点:a)所有词向量都是正交的,无法表示单词之间的相似度关系
b)向量的维度一般会很大
4.根据上下文来表示词
分布语义:一个词的意义是由经常出现在附近的词所赋予的
当单词w出现在文本中,它的上下文是出现在附近的一组单词(在一个固定大小的窗口中)。使用w的许多上下文可以建立w的表示。

4.1词向量word vector
我们将把某个词的含义用一个数字向量来表示。我们将为每个单词构建一个密集向量,以便它与出现在类似上下文中的单词的向量相似。
又称词的分布式表示或者词嵌入表示
词向量的可视化(作为一种神经词向量)

5.word2vec
5.1word2vec 概述
思想:
•我们有大量的文本
•固定词汇表中的每个单词都用一个向量表示
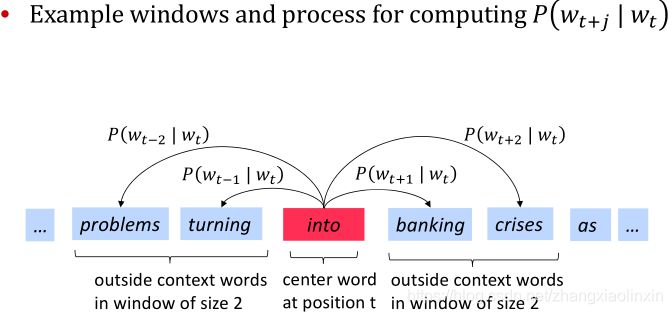
•检查文本中的每个位置t,其中有一个中心单词c和上下文(“outside”)单词o
•使用c和o的单词向量的相似性来计算给定c时o的概率(反之亦然)
•不断调整单词向量以最大化这种可能性

5.2word2vec 目标函数
对于每个未知t= 1…T,预测一个窗口内的上下文词,该窗口大小为m,给定中心词wj,其似然概率为:
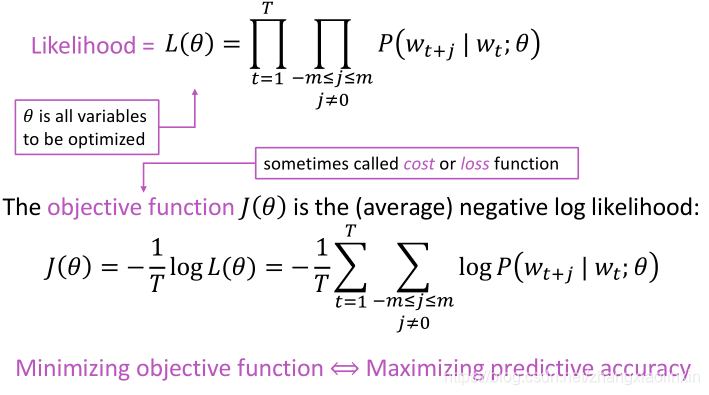 使用log函数的意义在于,将求累乘改为求累加;使用负号的意义在于,将极大化似然概率率转化为求损失函数最小化的问题
使用log函数的意义在于,将求累乘改为求累加;使用负号的意义在于,将极大化似然概率率转化为求损失函数最小化的问题
为了最小化目标函数,实际上是要计算
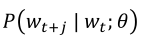
此时每个词W用到两个向量
对于每个单词w,都有两个向量表示,当w为中心词时,其词向量为v_w;当w为上下文词时,其词向量为u_w。于是,对于一个中心词c和它的一个上下文词o,得到了Word2vec 预测函数。

其中,点积操作用来比较u和v之间词向量的相似性,取幂操作用来保证点积的结果为正
5.3word2vec 预测函数
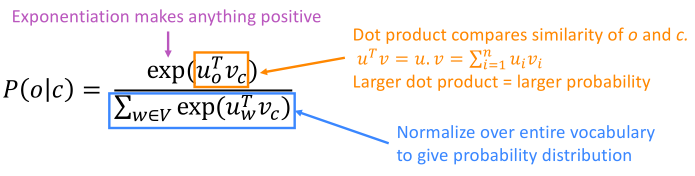
预测函数类似于机器学习中经常用到的softmax function,softmax函数可以放大最大概率,同时也可以避免将很低的概率变成0。
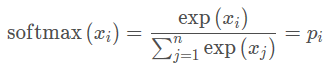
为了优化模型,我们采用随机梯度算法进行参数更新
每个单词由两个维度为1d×1的向量表示,常见的办法是将二者拼接,这样我们就可以得到一个非常庞大的向量参数,即
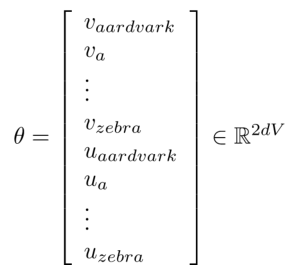
每个单词都有作为中心词和上下文的情况, 所以会有两个词向量 v_w和u_w。
优化目函数就是优化p(o|c)。
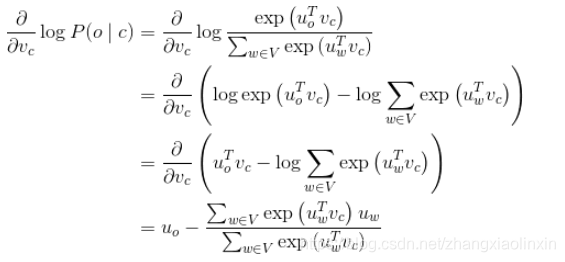
可知:第一项是真正的上下文单词,第二项是预测的上下文单词。使用梯度下降法,模型的预测上下文将逐步接近真正的上下文。
上式进一步改写为:
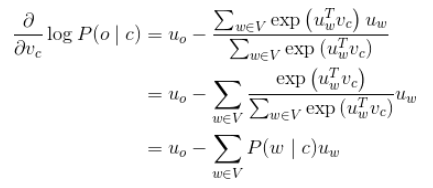
对u_o进行偏导计算
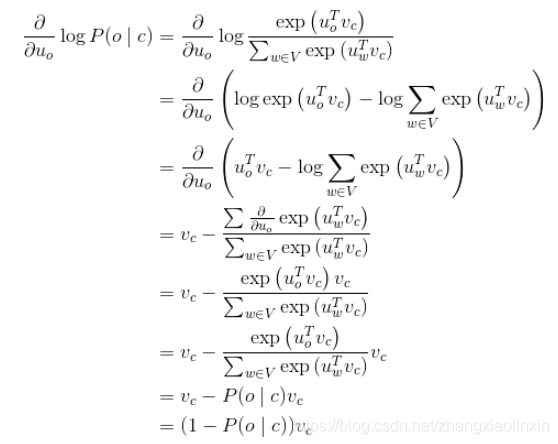
这个公式的含义是当P(o∣c)→1,即通过中心词c我们可以正确预测上下文词o了, 这时候我们就不需要调整u_o了, 否则我们相应的调整u_o。


















 1447
1447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









