






目录
背景
CL可以很好解决推荐系统中的数据稀疏性。基于CL的推荐模型的典型流程是首先对用user-item二部图进行结构扰动(一定比例丢弃edge/node)的增强,然后使用graph encoder学习最大化不同增强同样之间节点表示的一致性。这种模式被证明有效,但提升的原因在哪里?
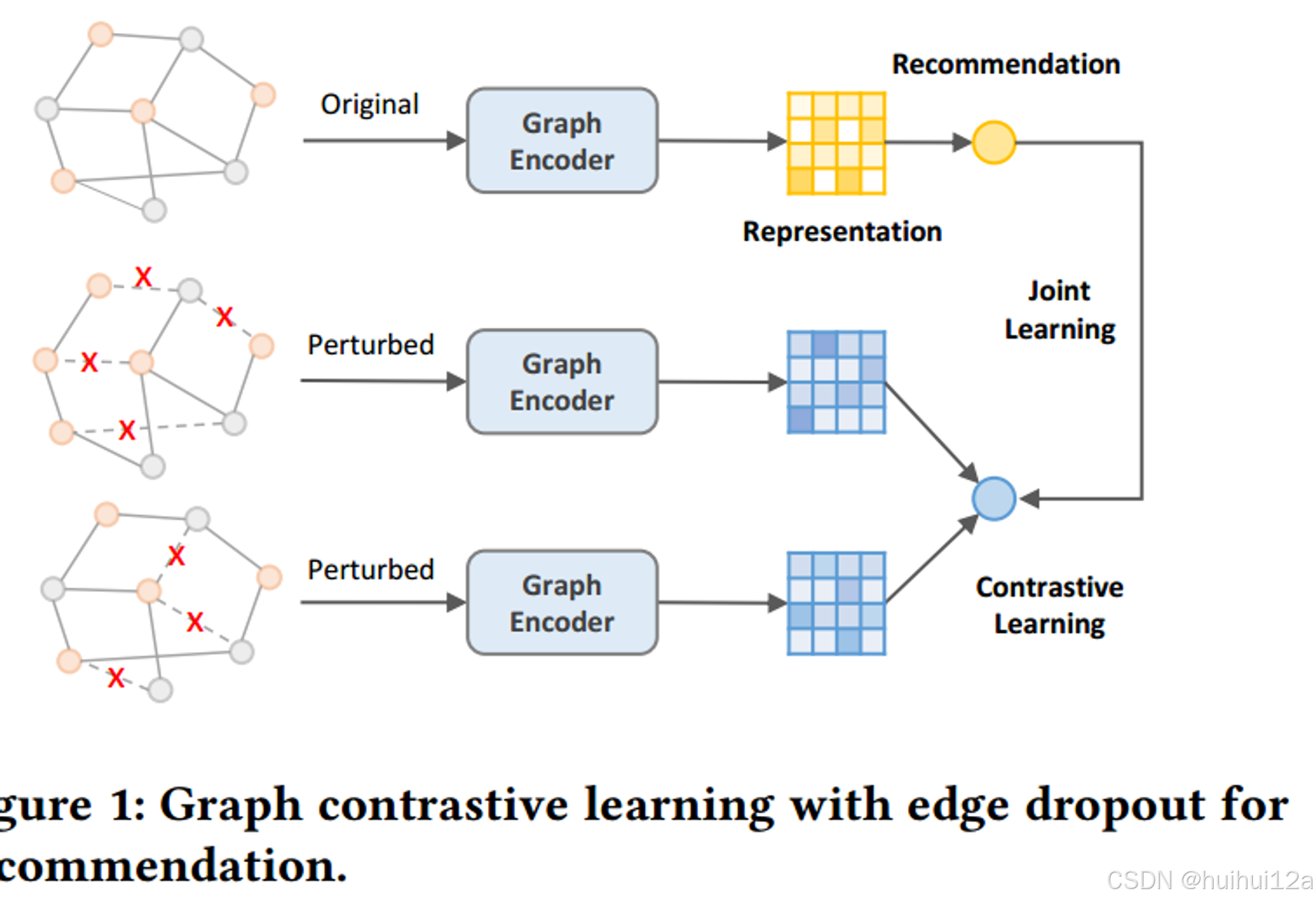
贡献
作者通过实验发现:在基于CL的推荐模型中,CL通过学习更均匀分布的user/item 表征,隐式减轻popularity bias;并发现被认为必要的图的增强,发挥的作用很小。并揭示了CL提高推荐性能的关键是CL的损失
因此,本文提出了简单的CL方法,作者放弃基于Dropout的图增强,在embedding space中添加随机均匀噪声来进行数据增强,可以平滑地调节均匀性。
实验验证CL的作用
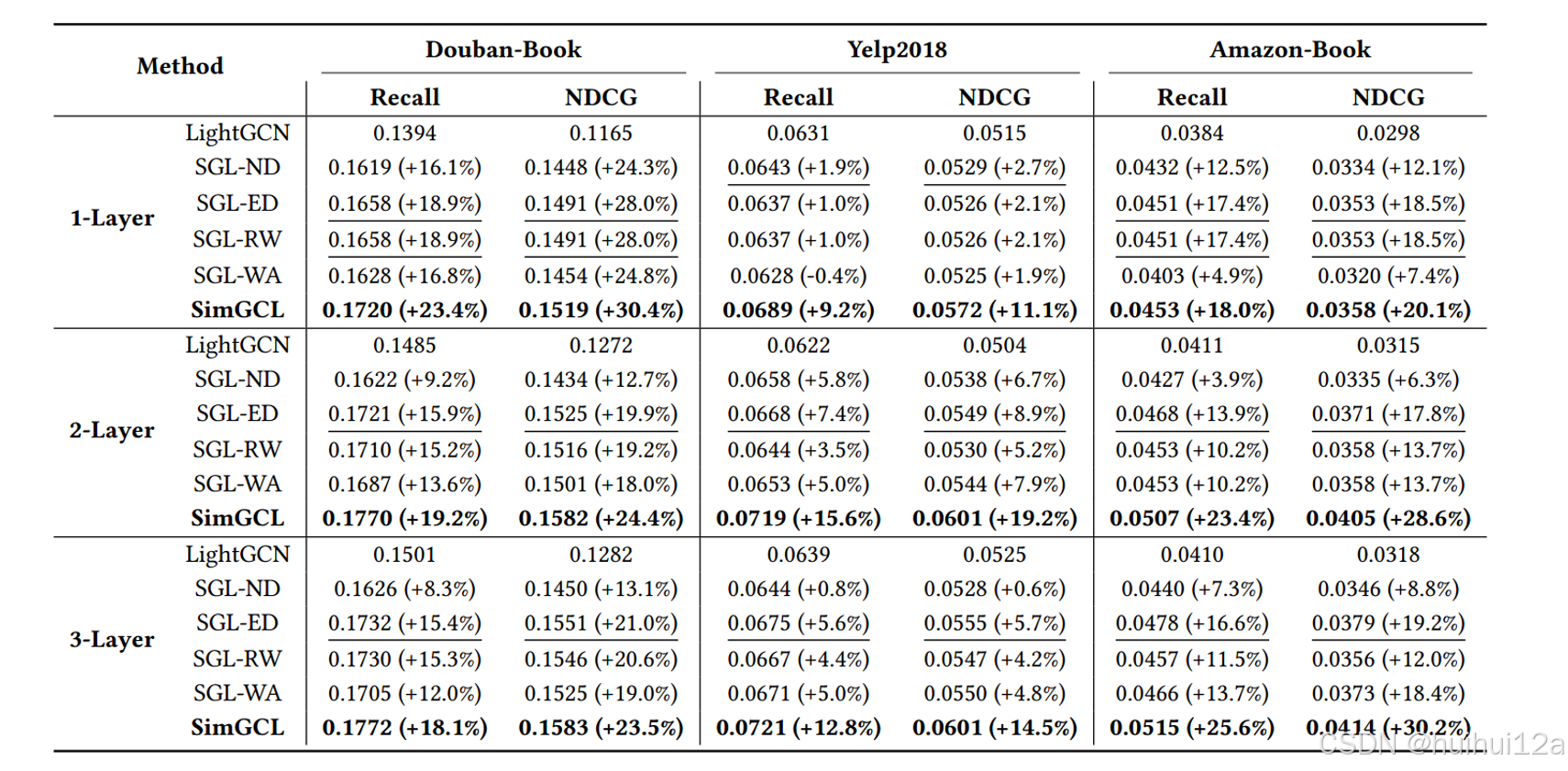
(1)性能对比

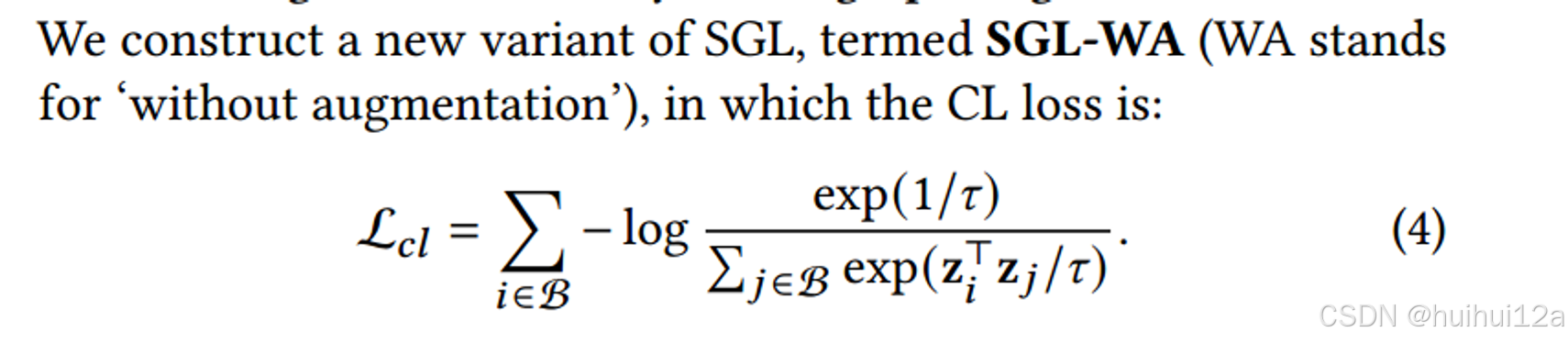
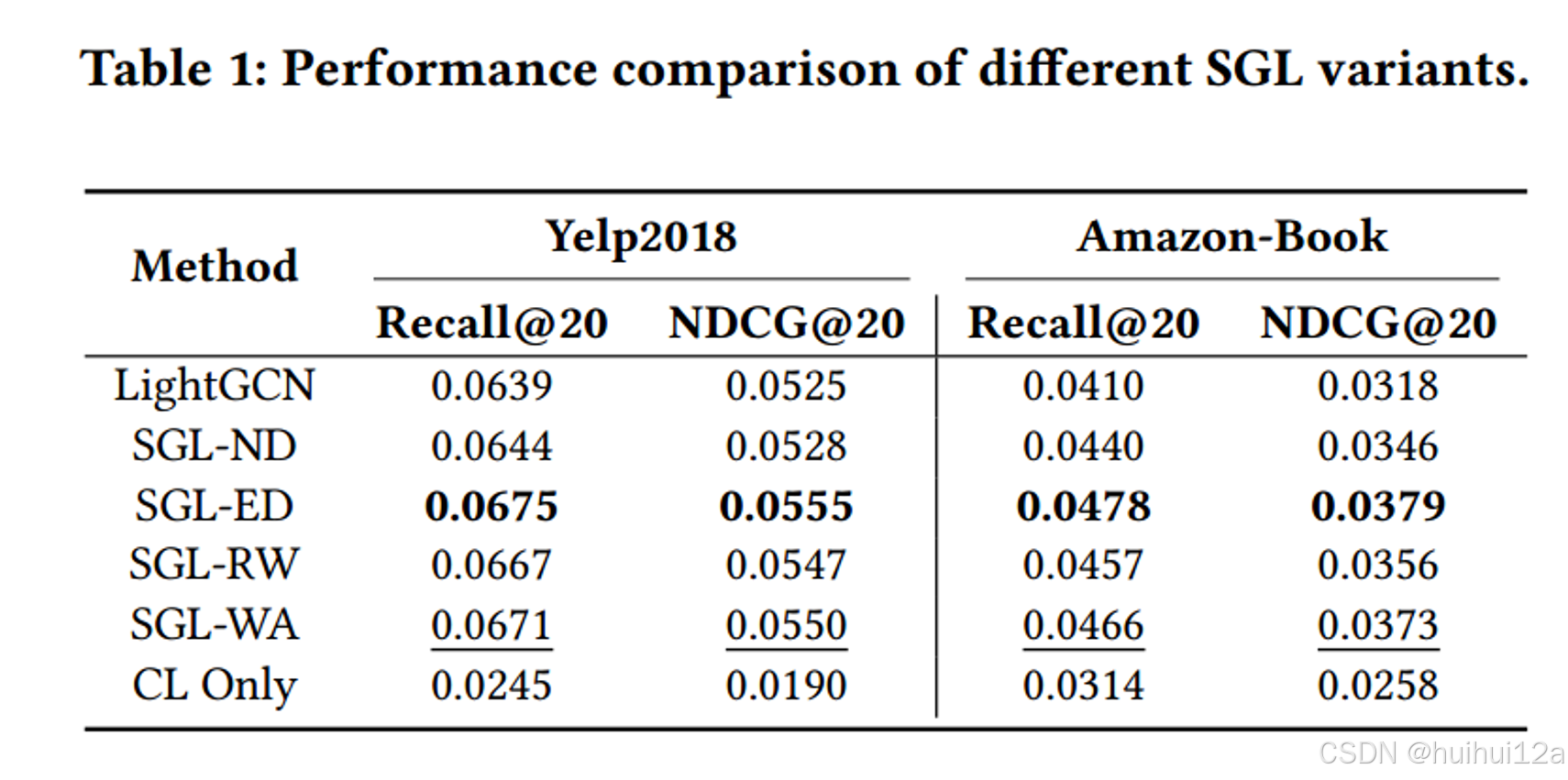
实验发现:
- SGL所有变体都优于LightGCN,证明了CL在提高推荐性能方面的有效性.
- 当没有图形增强时,性能优化依然很高。
- SGL node drop没SGL-WA效果好。这可能因为node drop丢失一些关键节点或边后,产生一些孤立的子图。
- 相比下,edge-drop这样的风险低一些,SGL edge drop相对于SGL 无图增强有些优势,但考虑到邻接矩阵在每个epoch的重建时间,我们应该重新考虑图增强的必要性。
(2)embedding分布对比
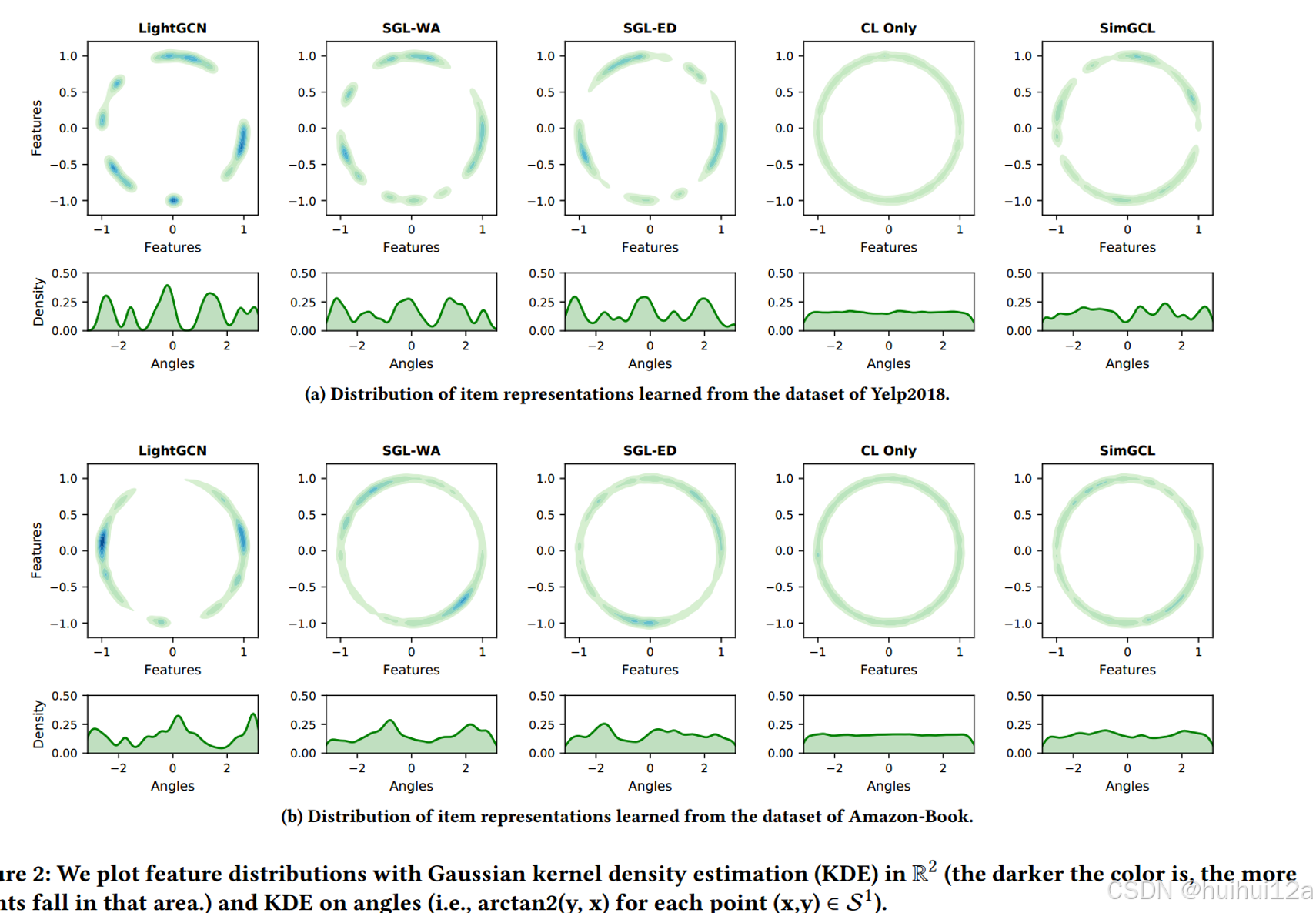
实验现象:
- LightGCN显示了高度聚集的特征,这些特征主要存在于一些狭窄的弧线上。
- 而在第二列和第三列中,无论是否应用图增广,分布都变得更加均匀,密度估计曲线也不那么清晰。在第四列中,我们绘制了仅通过的对比损失学习的特征。分布几乎是完全均匀的。
现象的原因:
- 首先是LightGCN中的消息传递机制。随着层数的增加,节点嵌入变得局部相似。二是推荐数据中的popularity bias使学习到的embedding往热门user/item偏移。
- 为什么SCL有效,而没有图增强的SCL-WA也有效。SCL对推荐的影响使让学习到的表征分布更加均匀,从而隐式消除偏差;真正有效的是优化CL损失,而不是基于dropout的图增强。

- 仅通过最小化CL损失,将会得到较差的性能,这意味着均匀性与性能之间的正相关关系仅在有限的范围内成立。过分追求一致性会忽略交互对和相似用户/物品的紧密性。
Simgcl:用于推荐的简单图对比学习
根据上面的发现,作者直接向表示中添加随机噪声实现高效有效的增强。
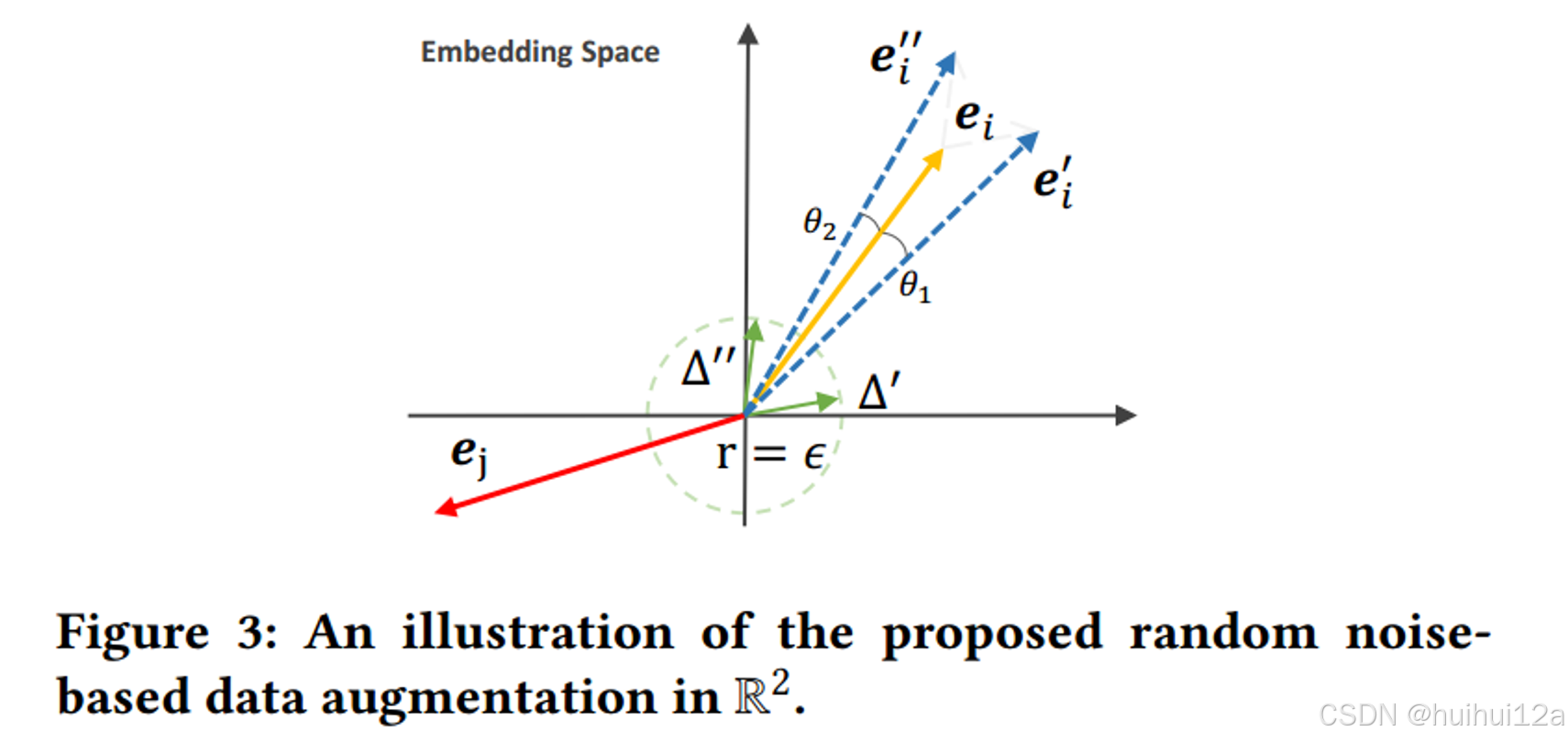
由于旋转足够小,增强表示保留了原始表示的大部分信息,同时也保留了一些方差。
采用LightGCN作为graph Encoder,在每一层对当前节点嵌入加上随机噪声。最终的节点可以表示为如下:

作者跳过了初始的节点嵌入E^0,发现实验中这样效果好些。但是如果没有CL任务的话,这样做效果会下降。
最后作者进行实验发现SimGCL在性能和时间上都有优势。


















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









