




一、购买阿里云服务器
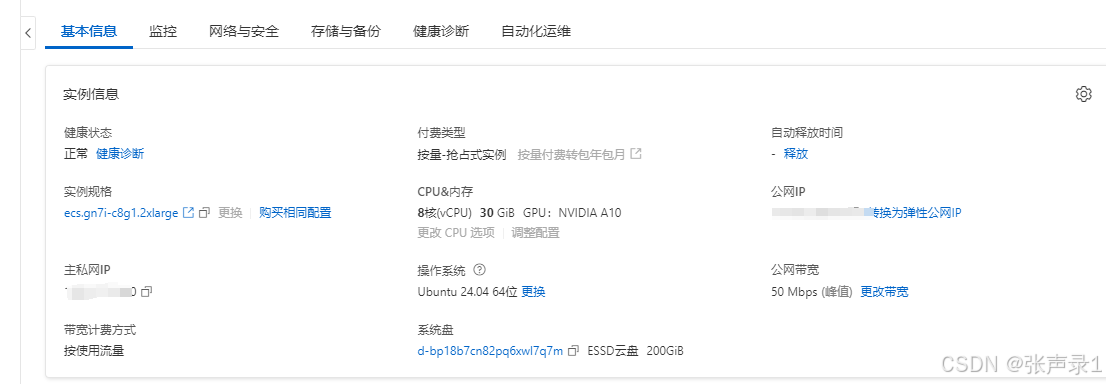
购买上面规格实例即可。
二、安装VLLM
sudo apt-get update
sudo apt-get install python3-venv
创建虚拟环境
python3 -m venv vllm # vllm 是虚拟环境名称,可自定义
激活虚拟环境
source vllm/bin/activate
在虚拟环境中安装 vllm
pip install --upgrade pip # 更新 pip(可选)
pip install vllm
三、运行DeepSeek-R1-Distill-Qwen-1.5B
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --tensor-parallel-size 1 --max-model-len 4096 --enforce-eager
这里直接运行会报错,报找不到显卡的错误。按照下面的方法来进行解决
# 卸载原来的显卡驱动
sudo apt-get purge nvidia*
# 添加源
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update
# 查看可以安装的驱动版本
sudo ubuntu-drivers devices
driver : nvidia-driver-560 - third-party non-free recommended
# 安装对应的版本
apt-get install nvidia-driver-560 -y
#验证安装是否Ok
(vllm) root@iZbp13dby3bc92091yih5zZ:~/vllm# nvidia-smi
Fri Mar  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









