







 本文介绍了YOLO(You Only Look Once)实时目标检测算法的原理,它通过将图像划分为多个网格,每个网格预测物体边界框和类别概率,实现快速准确的目标检测,适用于实时视频处理。
本文介绍了YOLO(You Only Look Once)实时目标检测算法的原理,它通过将图像划分为多个网格,每个网格预测物体边界框和类别概率,实现快速准确的目标检测,适用于实时视频处理。
YOLO原理:《You Only Look Once:Unified, Real-Time Object Detection》
引用: https://ziyubiti.github.io/2016/12/25/yolopaper/
对与YOLO原理的介绍,该文章简短明了,在此引用。
YOLO对实时视频的目标检测非常快,可达45FPS。这主要得益于其精妙的设计,对整体图片进行操作,相比R-CNN等大大降低了运算量。
YOLO的设计思想:
1、将图片划分为S ✖️S的grid cell小网格,每个小网格给出B个bounding box判决,每个边界盒判决包括5个信息,(x,y,w,h,object_prb),x/y为box的中心坐标,w、h为box的长宽,object_prob为box内存在物体的概率Pr(Object)。
2、每个小网格给出有物体存在时的C个分类的条件概率,Pr(Class|Object),从而可以得到整体图片中各个小网格内的各分类概率,Pr(Class)=Pr(Class|Object)* Pr(Object),设置合适判决门限,高于判决门限的就是识别出的目标分类。
3、根据各个小网格中的已识别目标分类,及对应的边界盒信息,可以计算出各个目标的整个分割区域位置信息,坐标、长宽等,从而在图像或视频中标记出来。
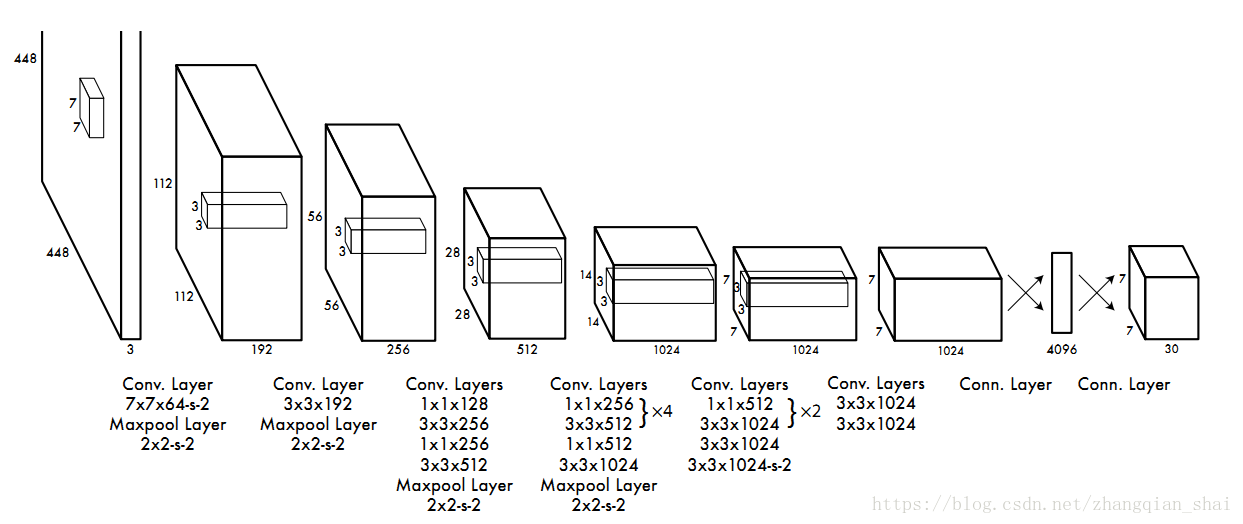
YOLO demo中,S=7,B=2,C=20,则网络最终输出7✖️7✖️(2✖️5+20)=1470,如下图:

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









