 YOLO检测原理
YOLO检测原理





 YOLO将目标检测问题转化为回归问题,直接从图像映射得到边界框和类别概率。其模型将输入图像划分为S*S网格,每个网格预测B个边界框及置信度和类别概率。采用GoogLeNet结构,训练时对权重进行了正则化并调整了损失函数以提高小物体检测性能。
YOLO将目标检测问题转化为回归问题,直接从图像映射得到边界框和类别概率。其模型将输入图像划分为S*S网格,每个网格预测B个边界框及置信度和类别概率。采用GoogLeNet结构,训练时对权重进行了正则化并调整了损失函数以提高小物体检测性能。
一、简介
在YOLO之前所采用得方法,通常是两个阶段(two-stage)的检测方法,首先生成大量的bbox(bounding box),之后根据bbox在特征层上的映射来进行分类(classification)以及进一步的bbox位置修正(regression)。而YOLO将目标检测问题化为了一个回归问题,直接从图像映射得到bbox和类别概率。它相比two-stage的方法有两个有点:1.快。2.利用到了全局的信息,因为之前的方法(faser rcnn)是将特征图裁剪下来。
二、模型
文中将输入图形划分为了S*S个格子,我们以格子为基础,对于每个格子给出B个b-box,每个b-box由四个参数(x,y,w,h)表示,(x,y)为b-box中心相对于格子中心的位置,(w,h)为b-box的大小,对于每个b-box,还给出了一个 confidence scores, = p(obj) * IoU(truth, predict),p(obj)衡量的是b-box包含这个物体的可能性,IoU是对于b-box准确性的预测。另外,还要预测P(C | Obj),是这个grid包含物体的概率。我们取B=2,S=7, C=20。所以有7*7*(2*5+20)个输出。
网络的结构:
GoogLeNet,24个卷积层,2个FC,有reduction layer。
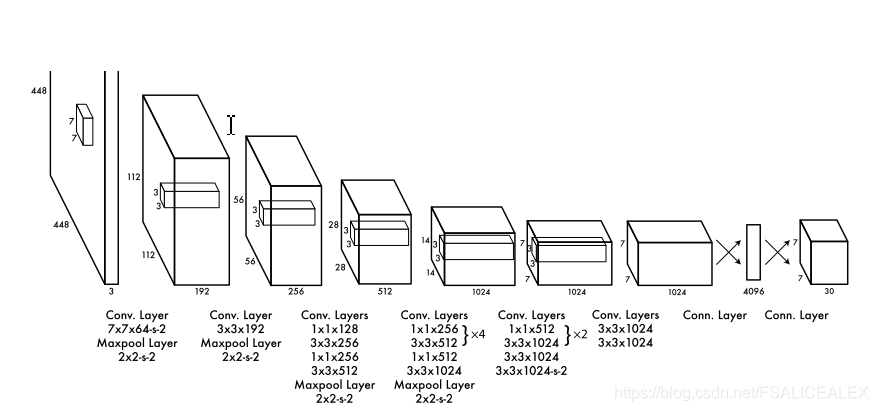
三、训练
在1000类上预训练,取前20层,分辨率为448*448,正则化w,h,x,y到[0,1]。使用leaky Relu。采用均方误差,但是由于在大量的grid中是不含物体的,大量的负样本会将confidence推向0。增加了定位的权重(5),降低了识别的权重(0.5)。误差要反映出对于同一小偏差,大物体定位的影响要小于小物体的影响,这时因为大物体的IoU影响相较于小物体来说更不明显,因此,采用了直接预测物体的sqrt(w)和sqrt(h)而非直接预测,降低了w的尺度影响。YOLO的每个grid会输出2个b-box,最终产生大量b-box,而对于一个物体,我们只想要一个b-box,因此,我们把和GT IOU最大的那个设置为responsible,loss如下:

分为3个部分,第一个部分是关于(x,y,w,h)的预测,如果第i个cell,第j个b-box中包含物体obj的话(通过是否是最大IOU来判断),则这部分有损失,要学习GT的b-box。第二个部分是对于confidence的预测,同上,如果有b-box是最大IOU,就有损失,要学习GT与该b-box的IOU,对于没有达到最大IOU的b-box,需要学习到0,表示b-box没有包含物体,第三部分是对于每个grid来判断的,如果grid中有GT的中心的话,那么需要学习到p(class of obj) = 1,p(class of others) = 0。
loss只对含有物体中心的grid进行分类惩罚,只对reposible(最大IOU)的b-box进行定位惩罚。
我们训练了135轮,在VOC 2007和2012。batch size 64,momentum0.9,decay0.0005。
第一个epoch:lr = 10^-3 to 10^-2
1-75 epoch: 10^-2
之后30个10^-3,30个10^-4
数据增强:dropout 0.5在第一个FC后面,随机变化,随机调整饱和度。
最终,网络的输出使用confidence的阈值来评估是否是某一类别的检测框,使用下式:
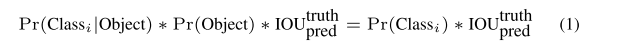
。使用NMS能够好一些。
限制:主要是定位,对于小物体判断不好:
YOLO imposes strong spatial constraints on bounding
box predictions since each grid cell only predicts two boxes
and can only have one class. This spatial constraint lim-
its the number of nearby objects that our model can pre-
dict. Our model struggles with small objects that appear in
groups, such as flocks of birds.
Since our model learns to predict bounding boxes from
data, it struggles to generalize to objects in new or unusual
aspect ratios or configurations. Our model also uses rela-
tively coarse features for predicting bounding boxes since
our architecture has multiple downsampling layers from the
input image.
Finally, while we train on a loss function that approxi-
mates detection performance, our loss function treats errors
the same in small bounding boxes versus large bounding
boxes. A small error in a large box is generally benign but a
small error in a small box has a much greater effect on IOU.
Our main source of error is incorrect localizations.
错误分析:
• Correct: correct class and IOU > .5
• Localization: correct class, .1 < IOU < .5
• Similar: class is similar, IOU > . 1
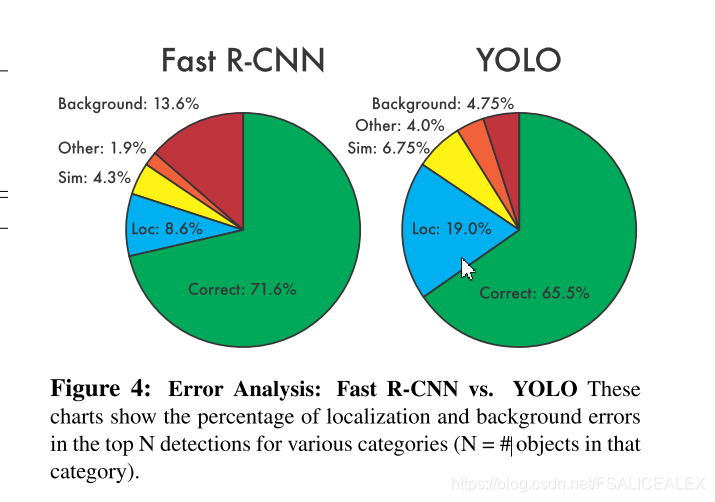
Other: class is wrong, IOU > .1
• Background: IOU < .1 for any object
很大一部分是定位错误,而faster rcnn更多的是背景错误


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









