



特别说明:参考官方开源的 yoloworld 代码、瑞芯微官方文档、地平线的官方文档,如有侵权告知删,谢谢。
模型和完整仿真测试代码,放在github上参考链接 模型和代码。
yoloworld出来的有一段时间了,还没有盘到板端上玩一玩,不把这个给整落地工作都干不起劲。落地过程也是一波三折多次想放弃,起早赶晚的抽时间干,再试一次,再试最后一次,再试最最后一次 。。。yoloworld 环境(MMDet)搭建都折腾了三次,转onnx也折腾了三次,上rknn板子又是三次(尝试rknn_toolkit2-1.3.0、rknn_toolkit2-1.6.0运行报错,最终用的rknn_toolkit2-2.0.0运行成功),都快折腾废了。
1 模型训练
训练就不多说,也没有尝试过,训练参考官方代码,本示例直接用yolov8提供的yoloworld模型(本想用腾讯提供的模型,奈何搭建环境太折腾;尝试过Huggingface导出的onnx模型,奈何规避不掉板端不支持的操作),进行板端部署。
1 导出 yolo_world onnx (yolo_world_v2_s)
尝试过用 huggingface 提供的demo导出onnx,但其中有操作(torch.einsum)板端支持不了,只能放弃作罢。本示例使用的是yolov8提供的yoloworld代码,进行onnx导出,规避 torch.einsum 操作,得到可以上板子的onnx模型。导出时进行调整,导出模型示意图如下,导出的类别使用的是80类。本示例对应提供的代码只用于适用六个输出头。
指定导出类别、以及导出六个输出头参考:(特别说明:本示例以yolov8提供的yoloworld代码为示例)
使用的yolov8提供的权重文件:权重文件
由于yolov8官方代码在不断修改,博客中使用的版本已打包:转onnx时使用的yolov8版本
第一步:保存指定类别的权重文件
from ultralytics import YOLO
model = YOLO("./yolov8s-world.pt")
model.set_classes(["person", "bus"]) # 指定导出类别(以两个类别为例)
model.save("./custom_yolov8s-world.pt") # 保存指定类别的权重文件
第二步:修改输出头

# 导出 onnx 增加
y = []
for i in range(self.nl):
t1 = self.cv2[i](x[i])
t2 = self.cv4[i](self.cv3[i](x[i]), text)
y.append(t1)
y.append(t2)
return y
第三步:增加保存onnx代码
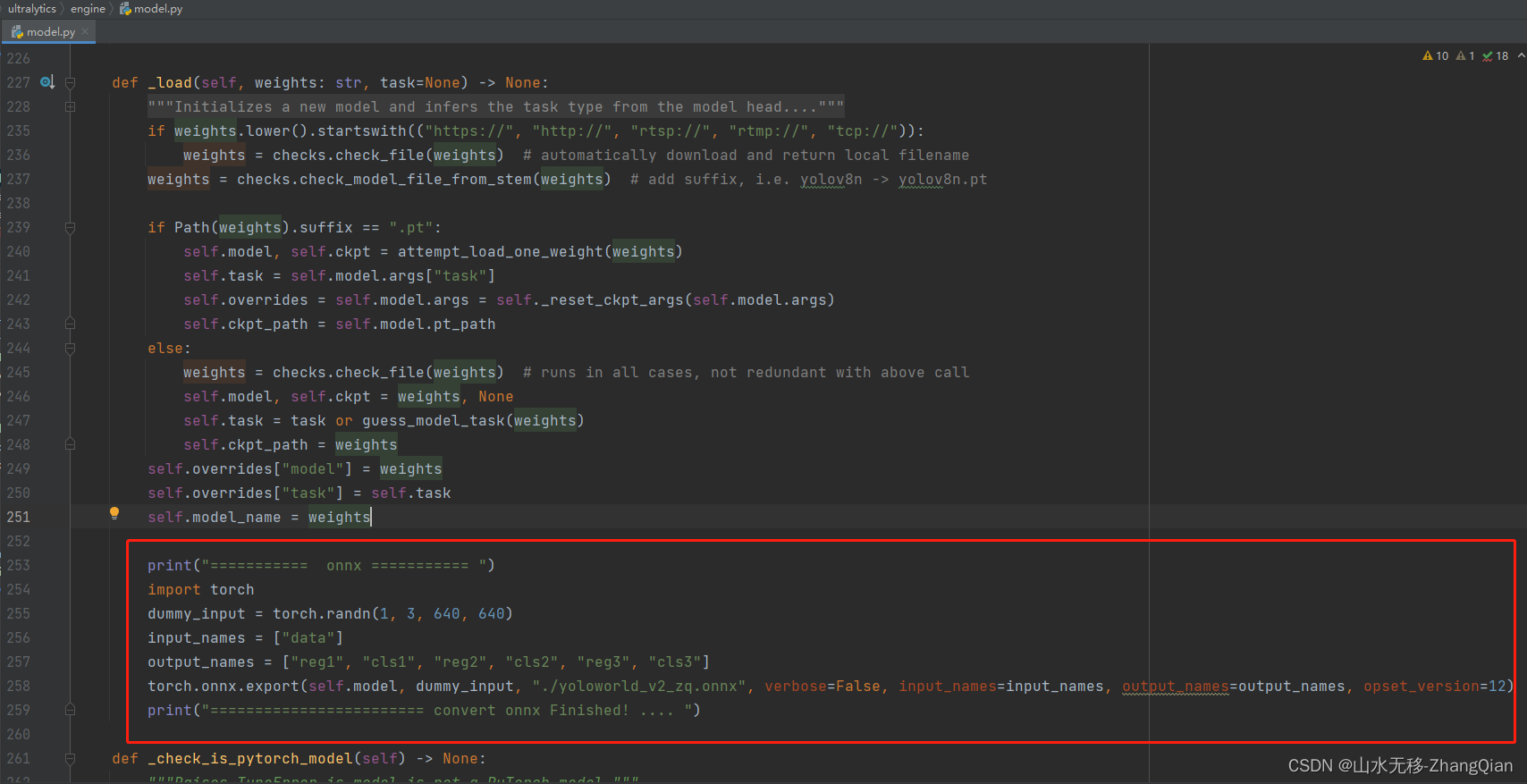
print("=========== onnx =========== ")
import torch
dummy_input = torch.randn(1, 3, 640, 640)
input_names = ["data"]
output_names = ["reg1", "cls1", "reg2", "cls2", "reg3", "cls3"]
torch.onnx.export(self.model, dummy_input, "./yoloworld_v2_zq.onnx", verbose=False, input_names=input_names, output_names=output_names, opset_version=12)
print("======================== convert onnx Finished! .... ")
第四步:运行,生成六个头的onnx文件
from ultralytics import YOLO
model = YOLO("./custom_yolov8s-world.pt") # 加载第一步生成的指定类别的权重文件(生成onnx)
本示例生成的onnx如下(6个输出头,2个检测类别):
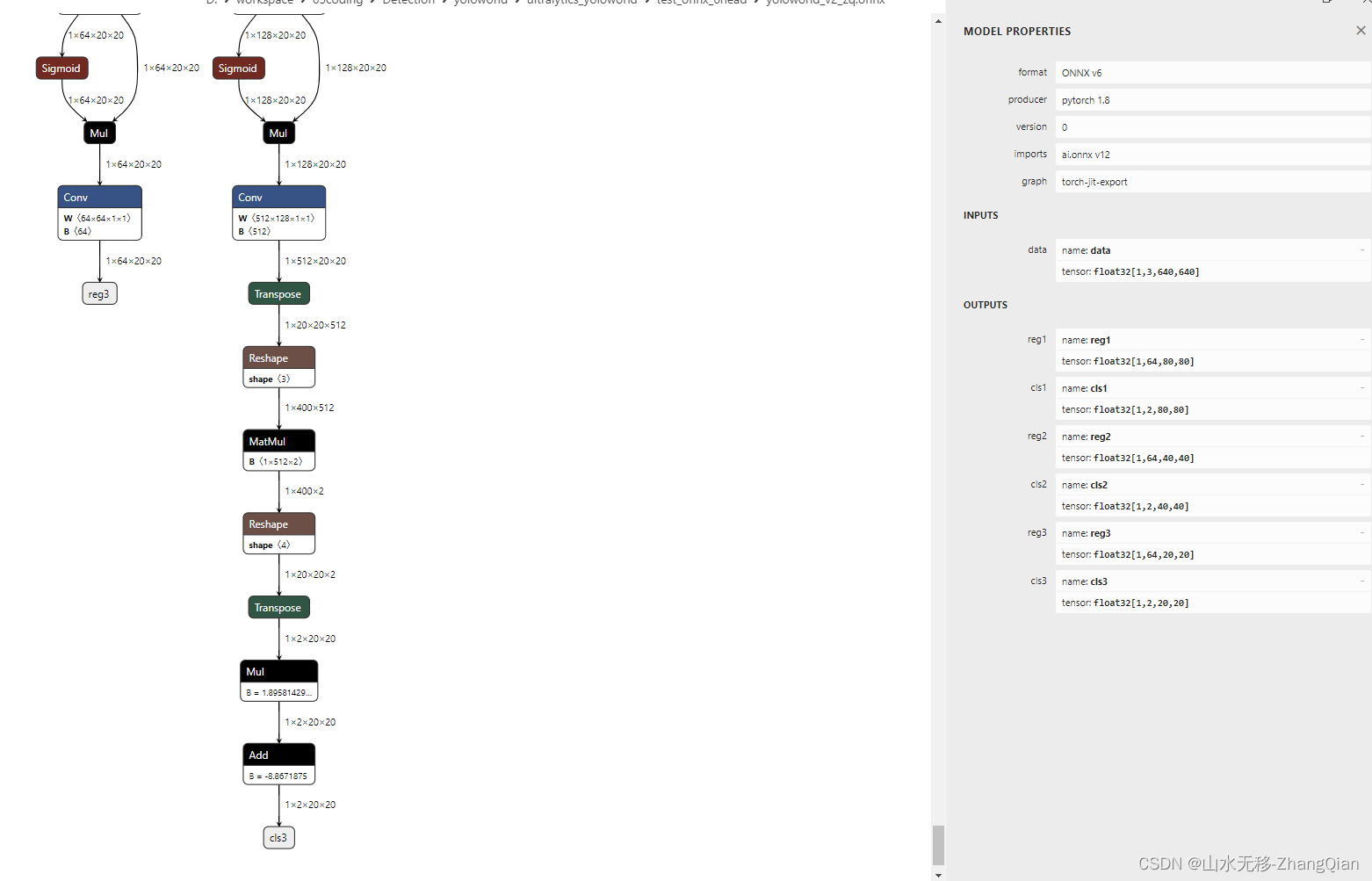
2 pytorch测试效果

onnx测试效果

3 tensorRT 时耗
模型yolo_world_v2_s,导出类别80类,输入分辨率是640x640,转trt使用的fp16_mode,显卡Tesla V100,cuda_11.0。
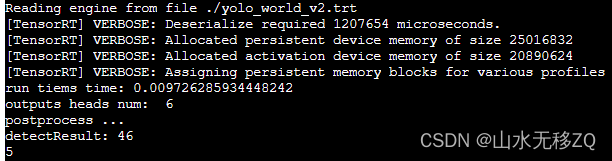
5 rknn 板端C++部署
模型yolo_world_v2_s,导出类别80类,输入分辨率是640x640,芯片rk3588.

把在rk3588板子上测试的模特推理时耗,和用C++代码写的后处理时耗,都给贴出来供大家参考。【rk3588的C++代码参考链接】。


















 1601
1601







 到【灌水乐园】发言
到【灌水乐园】发言







